

この記事では主に、Python コレクション モジュールの辞書クラス (dict) のいくつかの組み込み拡張サブクラスの適用シナリオと使用例を紹介します。これらを「短くて素早い方法」で習得できます。 dict に直接関連するサブクラス - OrderedDict、defaultdict、userDict。
Python コレクション モジュールの順序付き辞書 (OrderedDict) は通常の辞書とまったく同じですが、並べ替え操作に関連する追加機能がいくつかあります。 OrderedDict は、キーが挿入された順序を記憶します。組み込みの dict クラスが挿入順序を記憶する機能を獲得したため、それらの重要性は低くなりました (この新しい動作は Python 3.7 で保証されたため、OrderedDict の重要性は現在ではそれほど重要ではないようです)。順序付き辞書を作成するための一般的な形式:
import collections ordDict = collections.OrderedDict([items]):
または
from collections import OrderedDict ordDict = OrderedDict([items]):
これは、辞書の順序を並べ替えるための特別なメソッドを持つ dict サブクラスのインスタンスである OrderedDict オブジェクトを作成して返します。この記事では、これらの方法を簡単に紹介します。
順序付けされた辞書の Popitem() メソッドは、(キー, 値) ペアを返し、削除します。 last が True の場合、対応するキーと値のペアは LIFO (後入れ先出し) モードで返され、それ以外の場合は FIFO (先入れ先出し) 順序で返されます。
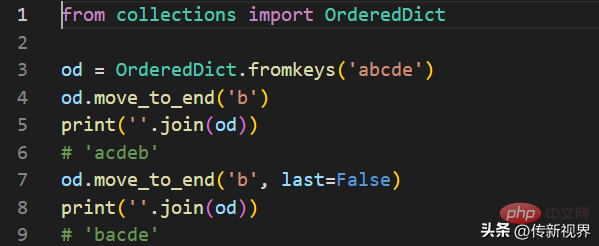
既存のキーを順序付けられた辞書のいずれかの端に移動します。 last が True (デフォルト) の場合、項目は右に移動し、last が False の場合、項目は先頭に移動します。キーが存在しない場合は KeyError が発生します。
コードを参照してください:
同じキーを削除して OrderedDict に再挿入するとします。キーの挿入順序を維持するために、このキーを最後に置きます。例は次のとおりです。
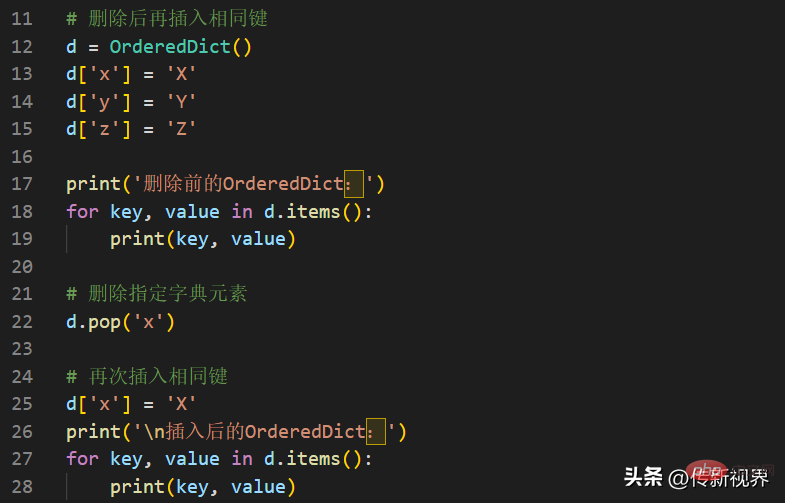
実行結果は次のとおりです。
删除前的OrderedDict: x X y Y z Z 插入后的OrderedDict: y Y z Z x X
UserDict クラスはラッパーとして使用されます。 Python の組み込み辞書 (dict) オブジェクトの場合。このクラスの必要性は、辞書から直接サブクラス化できる機能によって部分的に置き換えられましたが、基になる辞書に属性としてアクセスできるため、このクラスはより使いやすくなっています。いくつかの変更または新しい機能を備えた独自の辞書を作成する場合は、UserDict を使用します。その使用形式は次のとおりです:
import collections userDict = collections.UserDict([initialdata])
または
import collections userDict = collections.UserDict([initialdata])
このタイプのシミュレートされた辞書には、そのインスタンスのコンテンツが通常の辞書に格納されており、UserDict のデータ属性を通じてアクセスできます。実例。 Initialdata が提供される場合、データ コンテンツはこれで初期化されます。インスタンス自体は、initialdata への別個の (非排他的) 参照を保持しないため、他の目的に使用できることに注意してください。
UserDict インスタンスは、マッピング メソッドと操作のサポートに加えて、次の属性を提供します。
UserDict クラスのコンテンツを格納するために使用される実際の辞書。例は次のとおりです。
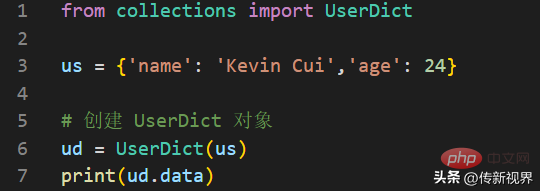
出力は次のとおりです。
{'name': 'Kevin Cui', 'age': 24}加算演算 (2 つの演算をマージする) をサポートするカスタム辞書オブジェクトを定義するとします。辞書)。カスタム辞書の 2 つのインスタンスを追加すると、両方の辞書のすべての要素を含む新しい辞書が取得されることが期待されます。 Python で通常の辞書に追加しようとすると、TypeError が発生することに注意してください。 UserDict を使用して実装してみましょう:
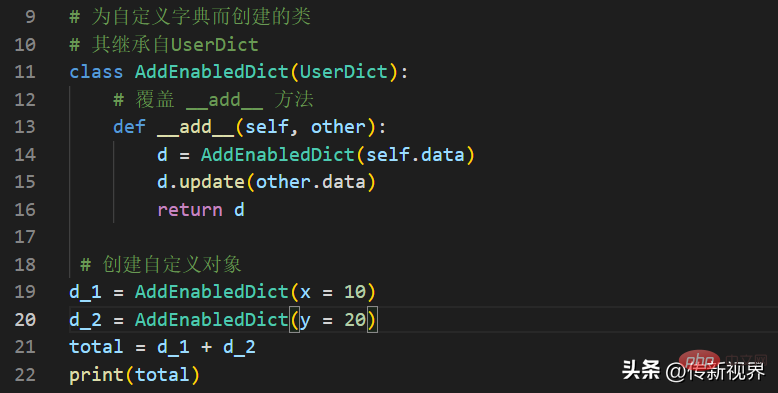
#実行中の出力は次のとおりです:
{'x': 10, 'y': 20}もちろん、他の関連するカスタムを実装することもできます。操作はご自身で行ってください。
Python の Dictionary クラスでよくある問題は、キーが欠落していることです。辞書に存在しないキーにアクセスしようとすると、KeyError 例外が発生します。したがって、辞書内の要素にアクセスする必要があるときは常に、この状況に対処する必要があります。幸いなことに、Python には DefaultDict クラスが用意されています。これは、KeyError を発生させずに、存在しないキーに何らかのデフォルト値を提供するために使用されます。
DefaultDict は、組み込みの dict クラスのサブクラスです。メソッドをオーバーライドし、書き込み可能なインスタンス変数を追加します。残りの機能は dict と同じです。使用形式は次のとおりです。
import colloections defaultDict = collections.defaultdict(default_factory=None, /[,…])
上記のコードは、組み込みの dict クラスのサブクラスである、新しい辞書のようなオブジェクト DefaultDict を返します。
最初のパラメータは、default_factory 属性の初期値を指定します。デフォルトは None です。キーワード引数を含め、残りのすべての引数は dict コンストラクターに渡されたかのように扱われます。理解する必要があるのは、このパラメーターが提供される場合、呼び出し可能でなければならないということです。
標準の dict 操作のサポートに加えて、DefaultDict オブジェクトは次のメソッド属性もサポートします:
default_factory 属性が None の場合、キーを次のように使用します。このパラメータにより KeyError 例外が発生します。
default_factory が None でない場合、引数なしで呼び出すと、指定されたキーのデフォルト値が提供され、その値がキーのディクショナリに挿入されて返されます。
DefaultDict对象支持default_factory实例变量。该属性由__missing__()方法使用。如果存在,则从构造函数的第一个参数开始初始化;如果不存在,则初始化为None。
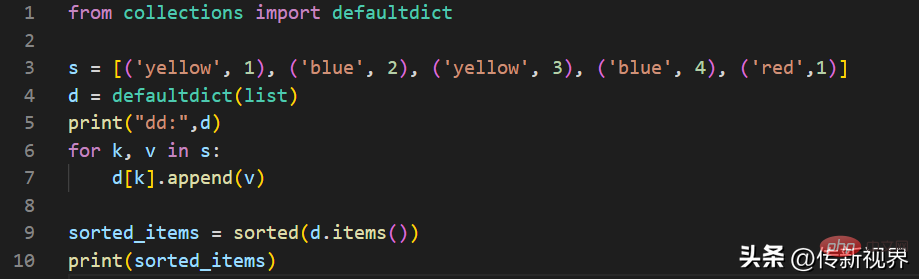
运行程序输出结果为:
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
在上述代码中,我们使用列表类型作为default_factory,更易于将包含键值序列对的列表组成字典。当第一次遇到每个键时,它还不在映射中,因此使用default_factory函数自动创建一个条目,该函数返回一个空列表。然后list.append()操作将值连接到新列表。当再次遇到键时,查找正常进行(返回该键的列表),然后list.append()操作将另一个值添加到列表中。这种技术比使用dict.setdefault()的等效技术要简单得多。
我们再看一个示例:
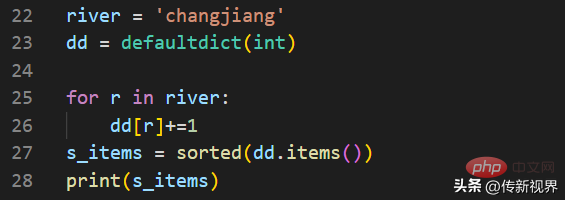
输出结果如下:
[('a', 2), ('c', 1), ('g', 2), ('h', 1), ('i', 1), ('j', 1), ('n', 2)]在上面代码中,我们将default_factory设置为int。这使得defaultdict用于计数(就像其他语言中的bag或multiset)。
当第一次遇到某个字母时,它就在映射中是不存在的,因此default_factory函数调用int()来提供一个默认的0计数。然后递增操作为每个字母建立计数。
提示:这里传递的int()函数默认返回的是整数0。若想返回任意值,可以自定义个一个基于lambda的常量函数。示例代码如下:
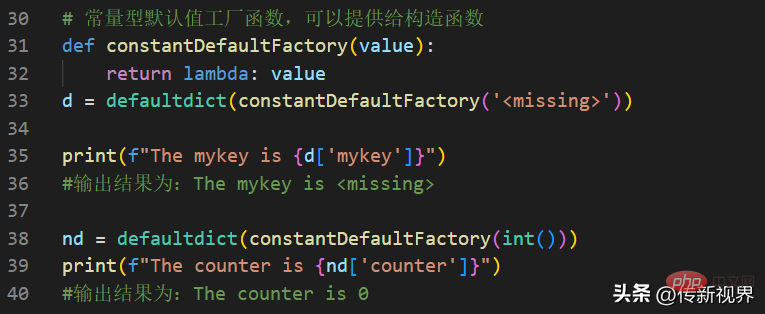
一言以蔽之:使用DefaultDict的好处就是可以避免KeyError异常,并进行一些可能的特定处理。
本文主要介绍了Python字典(dict)类相关的几个内置子类的应用。这些直接相关的子类分别是OrderedDict、defaultdict、userDict等内置子类。通过示例代码和关联描述,让你更轻松掌握它们的应用和基本规则。
以上がPython プログラミング: 組み込み辞書 (dict) のサブクラスとアプリケーションの詳細な説明 (すべて 1 か所で)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



