

機械学習に関する限り、オーディオ自体は、音声認識、音楽分類、サウンドイベント検出など、幅広い用途を持つ完全な分野です。音声分類には従来、スペクトログラム分析や隠れマルコフ モデルなどの手法が使用されてきましたが、これらの手法には効果的であることが証明されていますが、限界もあります。最近、VIT がオーディオ タスクの有望な代替手段として浮上しており、OpenAI の Whisper がその良い例です。

GTZAN データセットは、音楽ジャンル認識 (MGR) 研究で最も一般的に使用される公開データセットです。ファイルは 2000 年から 2001 年にかけて、個人用 CD、ラジオ、マイク録音などのさまざまなソースから収集され、さまざまな録音条件でのサウンドを表しています。
このデータ セットはサブフォルダーで構成されており、各サブフォルダーにはタイプがあります。
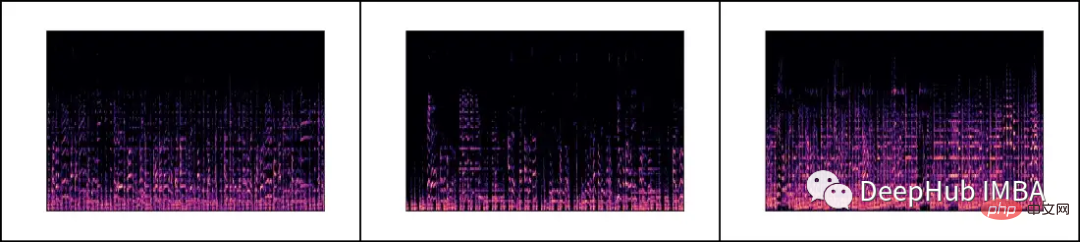
各 .wav ファイルを読み込み、librosa ライブラリを通じて対応するメル スペクトルを生成します。
メル スペクトログラムは、音声信号のスペクトル内容を視覚的に表現したもので、縦軸はメル スケールでの周波数を表し、横軸は時間を表します。これは、オーディオ信号処理、特に音楽情報検索の分野で一般的に使用される表現です。
メルスケール(英語: melscale )は、人間の音程知覚を考慮したスケールです。人間は周波数の線形範囲を知覚しないため、これは、高周波数よりも低周波数の違いを検出する方が優れていることを意味します。たとえば、500 Hz と 1000 Hz の違いは簡単に見分けることができますが、10,000 Hz と 10,500 Hz の違いは、たとえそれらの間の距離が同じであっても見分けるのが困難です。したがって、メルスケールはこの問題を解決します。メルスケールの差が同じであれば、人間が知覚するピッチの違いは同じになることを意味します。
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return img上記の関数は、単純なメル スペクトログラムを生成します。

次に、フォルダーからデータセットをロードし、画像に変換を適用します。
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))ViT をモデルとして使用します。Vision Transformer は最初に 16x16 ワードに等しい画像を論文に導入し、この方法が CNN に依存しないことを実証しました。一連の画像パッチに直接適用される純粋な Transformer は、画像分類タスクを適切に実行できます。
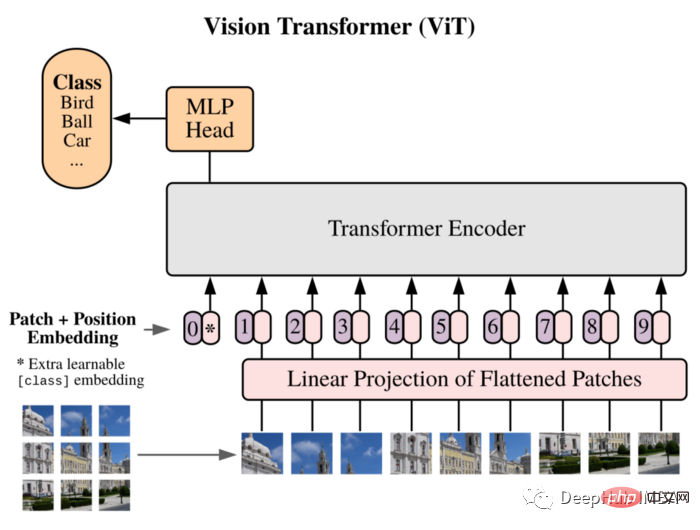
画像をパッチに分割し、これらのパッチの線形埋め込みシーケンスをトランスフォーマーの入力として使用します。パッチは、NLP アプリケーションのトークン (単語) と同じように扱われます。
CNN に固有の帰納的バイアス (局所性など) が存在しないため、トレーニング データの量が不十分な場合、Transformer はうまく一般化できません。しかし、大規模なデータセットでトレーニングすると、複数の画像認識ベンチマークで最先端のベンチマークを満たすか、それを上回ります。
実装された構造は次のとおりです:
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
トレーニング サイクルは従来のトレーニング プロセスでもあります:
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))Usage PyTorch は、Vision Transformer アーキテクチャのこのカスタム実装を最初からトレーニングしました。データセットが非常に小さい (クラスごとにサンプルが 100 個のみ) ため、これはモデルのパフォーマンスに影響し、0.71 の精度しか得られませんでした。
これは単なる単純なデモンストレーションです。モデルのパフォーマンスを向上させる必要がある場合は、より大きなデータ セットを使用するか、アーキテクチャのさまざまなハイパーパラメータをわずかに調整できます!
使用される vit コードこれは出典です:
https://medium.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
以上がビデオからオーディオへ: VIT を使用したオーディオ分類の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



