

超大型モデルの登場でAIゲームは終わったのか?ゲイリー・マーカス「道は狭い」

最近、人工知能技術は大規模なモデルで画期的な進歩を遂げており、昨日 Google が提案した Imagen は再び AI 機能に関する議論を引き起こしました。このアルゴリズムは、大量のデータからの事前トレーニング学習を通じて、リアルな画像の構築と言語の理解において前例のない機能を備えています。
多くの人の目から見ると、私たちは一般的な人工知能に近づいていますが、著名な学者でありニューヨーク大学の教授でもあるゲイリー・マーカス氏はそうは考えていません。
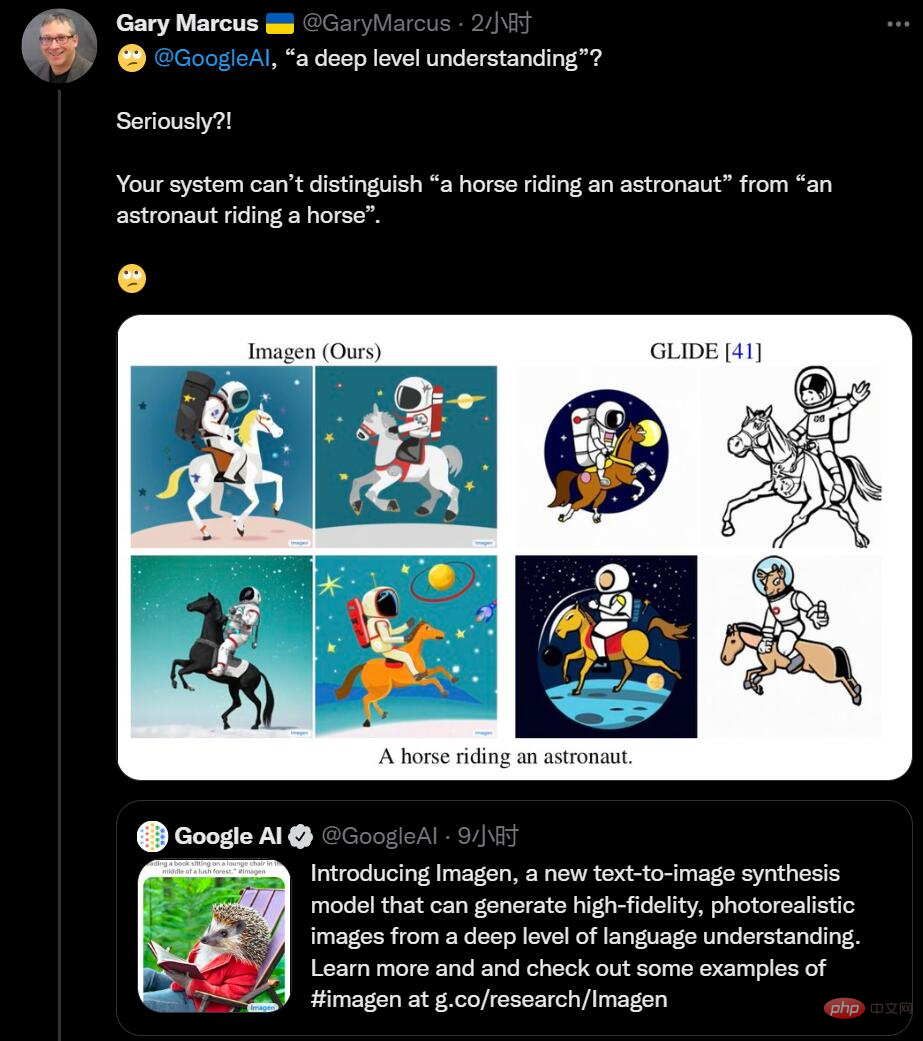
最近、彼の記事「オルト・インテリジェンスの新しい科学」は、DeepMind リサーチディレクターのナンド・デ・フレイタス氏の「大規模な勝利」についての見解に反論しました。それを言うこと。
以下は Gary Marcus の原文です:
何十年もの間、AI の分野では、人工知能は自然知能からインスピレーションを得るべきであるという仮定がありました。ジョン・マッカーシーは、AI に常識が必要な理由について独創的な論文「常識を備えたプログラム」を書き、マービン・ミンスキーは人間の思考からインスピレーションを得ようとして有名な本「心の社会」を書きました。その貢献によりノーベル経済学賞を受賞した彼は、「コンピューターが人間の予測された行動をシミュレートできるように、新たに開発されたコンピューター言語がどのようにして心理的プロセスの理論を表現できるのか」を説明することを目的とした有名な「思考のモデル」を執筆しました。 #私の知る限り、現在のAI研究者の大部分(少なくともより影響力のある研究者)はまったく気にしていません。代わりに、彼らは私が「オルト・インテリジェンス」と呼ぶものにもっと焦点を当てています(この用語への貢献については Naveen Rao に感謝します)。
オルト・インテリジェンスとは、人間の知能と同じ方法で問題を解決できる機械を構築することを意味するのではなく、人間の行動から得られる大量のデータを知能の代わりに使用することを意味します。現在、Alt Intelligence の主な焦点はスケーリングです。このようなシステムの支持者は、システムが大きければ大きいほど、真の知性、さらには意識に近づくことができると主張しています。
勉強してください オルト・インテリジェンス自体は新しいものではありませんが、それに伴う傲慢さは新しいものです。
私はしばらくの間、現在の人工知能のスーパースターたち、そして人工知能の全分野に携わるほとんどの人々でさえ、人間の認知を軽視し、言語学や認知心理学を無視、あるいは嘲笑しているという兆候をいくつか見てきました。科学、人類学、哲学の分野で。
しかし今朝、オルト・インテリジェンスに関する新しいツイートを発見しました。このツイートの投稿者でディープマインド社の研究ディレクターであるナンド・デ・フレイタス氏は、AIは「今や規模がすべてだ」と宣言した。実際、彼の見解では(おそらく激しいレトリックで意図的に挑発しているのでしょうが)、AI におけるより困難な課題はすでに解決されています。 「ゲームオーバーだ!」と彼は言った。
 本質的には、オルト・インテリジェンスを追求することに何も問題はありません。
本質的には、オルト・インテリジェンスを追求することに何も問題はありません。
Alt Intelligence は、インテリジェント システムの構築方法に関する直観 (または一連の直観) を表します。人間の知性の柔軟性と知性に匹敵するシステムを構築する方法をまだ誰も知らないため、これを達成する方法について人々がさまざまな仮説を追求するのは当然のことです。 Nando de Freitas はこの仮説を可能な限り率直に擁護しており、私はそれを Scaling-Uber-Alles と呼んでいます。
もちろん、名前だけですべてがわかるわけではありません。デ・フレイタス氏は、モデルを大きくするだけで成功を期待することはできないことを明確にしています。最近、人々は多くのスケーリングを行っており、いくつかの大きな成功を収めていますが、いくつかの障害にも遭遇しています。デ・フレイタスが現状にどのように直面しているかについて詳しく説明する前に、現状がどのようなものかを見てみましょう。
現状DALL-E 2、GPT-3、Flamingo、
Gato などのシステムはわかりにくいようです。 、しかし、これらのモデルを注意深く研究したことのある人は、それを人間の知性と混同する人はいないでしょう。 たとえば、DALL-E 2 は、「馬に乗った宇宙飛行士」など、テキストの説明に基づいてリアルな芸術作品を作成できます。また、意外な間違いも犯しやすいもので、例えば、テキスト説明が「青い四角の上に赤い四角」である場合、DALL-E の生成結果は左の図のようになり、右の図は DALL-E によって生成されます。前モデルの結果です。明らかに、DALL-E の生成結果は以前のモデルより劣っています。
アーネスト デイビス、スコット アーロンソン、そして私がこの問題を詳しく調べたところ、多くの同様の例が見つかりました:
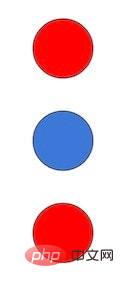
さらに、表面的には素晴らしく見える Flamingo にも独自のバグがあります。ディープマインドの上級研究科学者マレー・シャナハン氏はツイートで指摘し、フラミンゴの主著者ジャン・バティスト・アライラック氏は後にいくつかの例を追加した。たとえば、シャナハンはフラミンゴに次の画像を見せました:


Scaling-Uber-Alles
では、デ・フレイタスは現実と野心をどのように調和させているのでしょうか?実際、今では Transformer や他の多くの関連分野に数十億ドルが投資されており、トレーニング データ セットはメガバイトからギガバイトに拡大し、パラメータのサイズは数百万から数兆に拡大しています。しかし、1988 年以来、数多くの著作で詳細に文書化されてきた不可解な誤りが依然として残っています。 一部の人々 (私のような) にとって、これらの問題の存在は、デイビスと私が「AI の再起動」で指摘したような根本的な再考が必要であることを意味するかもしれません。しかし、デ・フレイタス氏の場合、これは当てはまらない(他の多くの人も彼と同じ考えを持っているかもしれないが、私は彼を特別視するつもりはない。ただ彼の発言がより代表的だと思うだけだ)。 ツイートの中で、彼は現実と現在の問題を調和させることについての見解を詳しく述べ、「(私たちは)モデルをより大きく、より安全に、より計算効率を高め、より速くサンプリングし、より効率的に保存する必要があります。重要なのは、どの単語も認知心理学、言語学、哲学から来ているわけではないということです(記憶力が優れている人はほとんど数えられないかもしれません)。 デ・フレイタス氏は、フォローアップの投稿で次のようにも述べています:
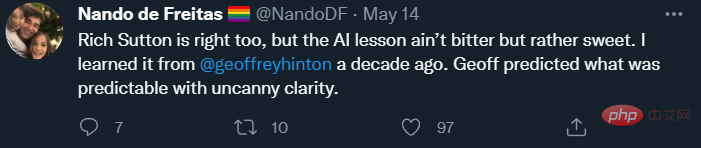
サットン氏の主張は、人工知能の進歩につながる唯一のものは、より多くのデータとより効率的な計算である、というものです。私の意見では、サットンは半分しか正しくなく、過去に関する彼の説明はほぼ正しいですが、彼の帰納的な未来予測には説得力がありません。
これまでのところ、ビッグデータは、ほとんどの分野 (もちろんすべての分野ではありません) で、適切に設計された知識エンジニアリングを (一時的に) 打ち負かしています。
しかし、Web ブラウザからスプレッドシート、ワード プロセッサに至るまで、世界中のほぼすべてのソフトウェアは依然としてナレッジ エンジニアリングに依存しており、サットン氏はこれを無視しました。たとえば、Sumit Gulwani の優れたフラッシュ フィル機能は、ビッグ データをまったく前提とせず、古典的なプログラミング手法に基づいて構築された、非常に便利な 1 回限りの学習システムです。
純粋なディープラーニング/ビッグデータ システムがこれに匹敵するものはないと思います。
実のところ、スティーブ ピンカー、ジューデア パール、ジェリー フォーダー、そして私などの認知科学者たちが何十年も指摘してきた人工知能に関する重要な問題は、実際にはまだ解決されていません。はい、マシンはゲームを非常に上手にプレイでき、ディープラーニングは音声認識などの分野で多大な貢献をしてきました。しかし、現在のところ、あらゆるテキストを認識し、正常に会話してタスクを完了できるモデルを構築するのに十分な理解を備えた人工知能は存在しません。また、映画「スタートレック」のコンピューターのように推論して一貫した応答を生成することもできません。
私たちはまだ人工知能の初期段階にいます。
特定の戦略を使用して一部の問題に成功したとしても、すべての問題を同様の方法で解決できるとは限りません。特に、一部の故障モード (信頼性の低さ、奇妙なバグ、組み合わせの失敗、理解不能) が 1988 年に Fodor と Pinker によって指摘されて以来変わっていない場合には、これに気づかないのはまったく愚かです。 結論
DeepMind においてさえ、Scaling-Über-Alles がまだ完全に合意されていないことがわかってうれしいです:
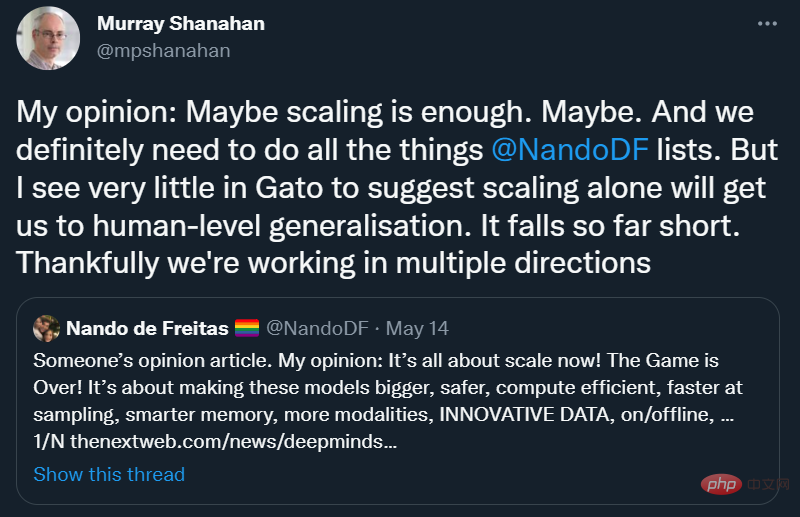
Iマレー・シャナハン氏の意見に完全に同意します。「スケーリングだけで人類レベルの一般化が達成できることを示唆するものは、ガトーにはほとんど見当たりません。」
たまたままだ完全に開発されていないアイデアを時期尚早に破棄することなく、人々が自分の研究をさまざまな方向に進めることができる、十分にオープンな考え方を持つ分野を奨励しましょう。結局のところ、(一般的な)人工知能への最善の道は、代替知能ではない可能性があります。
前に述べたように、私は Gato を「代替インテリジェンス」、つまりインテリジェンスを構築する別の方法の興味深い探求として考えたいと思っていますが、それを大局的に考える必要があります。脳は、子供のように学習せず、言語を理解せず、人間の価値観と一致せず、重要なタスクを完了することを信頼できません。
これは、現在私たちが持っている他のものよりも優れているかもしれませんが、それでも実際には機能せず、多額の投資を行った後でも、一時停止する時期が来ています。
それは私たちを人工知能スタートアップの時代に戻すはずです。人工知能は人間の知能の盲目的なコピーであってはなりませんが、結局のところ、人工知能には、記憶力の低下や認知バイアスに悩まされる独自の欠陥があります。しかし、手がかりとして人間と動物の認知に目を向けるべきだ。ライト兄弟は鳥の真似をしたわけではありませんが、飛行制御については何かを学びました。何を学ぶことができ、何から学ぶことができないかを知ることが、成功の半分以上を占めるかもしれません。
私が思うに、肝心なのは、AI がかつては大切にしていたものの、今は追求していないものであるということです。AGI を構築するつもりなら、人間から何かを学ぶ必要があるでしょう。つまり、人間がどのように物理世界を推論し、理解するのか、そして言語や複雑な概念をどのように表し、獲得するのか。
この考えを否定するのはあまりにも傲慢です。
以上が超大型モデルの登場でAIゲームは終わったのか?ゲイリー・マーカス「道は狭い」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpMyAdminを使用してデータテーブルを作成するには、次の手順が不可欠です。データベースに接続して、[新しいタブ]をクリックします。テーブルに名前を付けて、ストレージエンジンを選択します(InnoDB推奨)。列名、データ型、null値、その他のプロパティを許可するかどうかなど、列の追加ボタンをクリックして列の詳細を追加します。一次キーとして1つ以上の列を選択します。 [保存]ボタンをクリックして、テーブルと列を作成します。
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースを作成するには、一般的な方法はDBCAグラフィカルツールを使用することです。手順は次のとおりです。1。DBCAツールを使用してDBNAMEを設定してデータベース名を指定します。 2. SyspasswordとSystemPassWordを強力なパスワードに設定します。 3.文字セットとNationalCharactersetをAL32UTF8に設定します。 4.実際のニーズに応じて調整するようにMemorySizeとTableSpacesizeを設定します。 5. logfileパスを指定します。 高度な方法は、SQLコマンドを使用して手動で作成されますが、より複雑でエラーが発生しやすいです。 パスワードの強度、キャラクターセットの選択、表空間サイズ、メモリに注意してください
 Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracle SQLステートメントのコアは、さまざまな条項の柔軟なアプリケーションと同様に、選択、挿入、更新、削除です。インデックスの最適化など、ステートメントの背後にある実行メカニズムを理解することが重要です。高度な使用法には、サブクエリ、接続クエリ、分析関数、およびPL/SQLが含まれます。一般的なエラーには、構文エラー、パフォーマンスの問題、およびデータの一貫性の問題が含まれます。パフォーマンス最適化のベストプラクティスには、適切なインデックスの使用、Select *の回避、条項の最適化、およびバインドされた変数の使用が含まれます。 Oracle SQLの習得には、コードライティング、デバッグ、思考、基礎となるメカニズムの理解など、練習が必要です。
 mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
MySQLのフィールド操作ガイド:フィールドを追加、変更、削除します。フィールドを追加:table table_nameを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー] [auto_increment]フィールドの変更:column_name data_typeを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー]
 Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベースの整合性の制約により、以下を含むデータの精度を確保できます。NULL:NULL値は禁止されています。一意:単一のヌル値を許可する一意性を保証します。一次キー:一次キーの制約、一意を強化し、ヌル値を禁止します。外部キー:テーブル間の関係を維持する、外部キーはプライマリテーブルのプライマリキーを参照します。チェック:条件に応じて列の値を制限します。
 MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
ネストされたクエリは、1つのクエリに別のクエリを含める方法です。これらは主に、複雑な条件を満たし、複数のテーブルを関連付け、要約値または統計情報を計算するデータを取得するために使用されます。例には、平均賃金を超える従業員を見つけること、特定のカテゴリの注文を見つけること、各製品の総注文量の計算が含まれます。ネストされたクエリを書くときは、サブ征服を書き、結果を外側のクエリ(エイリアスまたは条項として参照)に書き込み、クエリパフォーマンスを最適化する必要があります(インデックスを使用)。
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
