

11 の一般的な分類特徴エンコード技術

機械学習アルゴリズムは数値入力のみを受け入れるため、カテゴリカルな特徴が見つかった場合は、そのカテゴリカルな特徴をエンコードします。この記事では、11 の一般的なカテゴリカル変数のエンコード方法を要約します。

1. ONE HOT エンコーディング
最も一般的でよく使用されるエンコーディング方法は、One Hot Enoding です。 n 個の観測値と d 個の個別の値を持つ単一の変数は、n 個の観測値を持つ d 個のバイナリ変数に変換され、各バイナリ変数はビット (0, 1) で識別されます。
例:
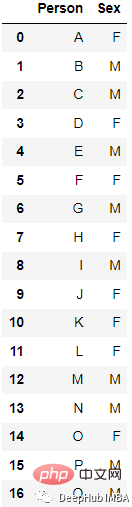
エンコード後

new_df=pd.get_dummies(columns=[‘Sex’], data=df)
2. ラベル エンコーディング
一意に識別された整数をカテゴリ データ変数に割り当てます。この方法は非常に単純ですが、順序付けされていないデータを表すカテゴリ変数では問題が発生する可能性があります。たとえば、高い値を持つタグは、低い値を持つタグよりも高い優先順位を持つことができます。
たとえば、上記のデータでは、エンコード後に次の結果が得られました:
 sklearn の LabelEncoder は直接変換できます:
sklearn の LabelEncoder は直接変換できます:
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
3. Label Binarizer
LabelBinarizer は、複数カテゴリのリストからラベル行列を作成するために使用されるツール クラスです。リストを、一意の値の数とまったく同じ列数の行列に変換します。入力セット内。
たとえば、このデータ
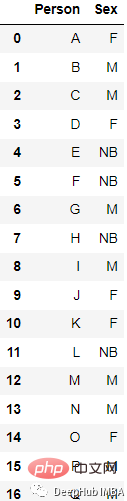 変換結果は
変換結果は
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
4です。1つは省略します。エンコーディング 
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
エンコード後:
これを実証するにはエンコード プロセスでは、データ セットを作成します: 
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
import category_encoders as ce
tenc=ce.TargetEncoder()
df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’])
df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1)
df_new = df.join(df_dep)エンコード後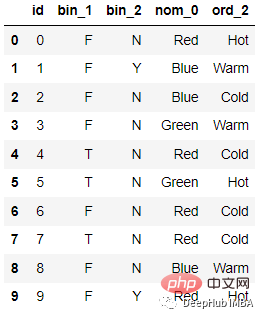
コードは次のとおりです。 :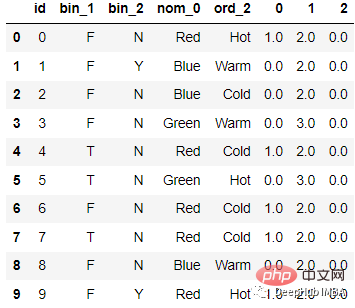
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
P(良い) / P(悪い) = 1 の場合、WoE は 0 です。このグループの結果がランダムである場合、P(Bads) > P(Goods)、オッズ比は 1、証拠の重み (WoE) は 0 になります。グループ内で P(Goods) > P(bad) の場合、WoE は 0 より大きくなります。 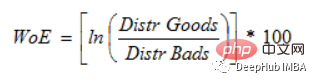
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据

会被编码为:

代码如下:
from category_encoders import WOEEncoder
df = pd.DataFrame({‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]})
woe = WOEEncoder(cols=[‘cat’], random_state=42)
X = df[‘cat’]
y = df.target
encoded_df = woe.fit_transform(X, y)7、Helmert Encoding
Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。

会被编码为

代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
8、Cat Boost Encoding
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。

TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。

编码后的结果如下:

代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
9、James Stein Encoding
James-Stein 为特征值提供以下加权平均值:
- 观察到的特征值的平均目标值。
- 平均期望值(与特征值无关)。
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
10、M Estimator Encoding:
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
11、 Sum Encoder
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
以上が11 の一般的な分類特徴エンコード技術の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7447
7447
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 機械学習における Golang テクノロジーの今後の動向の展望
May 08, 2024 am 10:15 AM
機械学習における Golang テクノロジーの今後の動向の展望
May 08, 2024 am 10:15 AM
機械学習の分野における Go 言語の応用可能性は次のとおりです。 同時実行性: 並列プログラミングをサポートし、機械学習タスクにおける計算量の多い操作に適しています。効率: ガベージ コレクターと言語機能により、大規模なデータ セットを処理する場合でもコードの効率が保証されます。使いやすさ: 構文が簡潔なので、機械学習アプリケーションの学習と作成が簡単です。
