

Docker を使用して AWS Lambda に機械学習モデルをデプロイする方法

このチュートリアルでは、ML モデルを Docker コンテナとしてパッケージ化し、サーバーレス コンピューティング サービス AWS Lambda にデプロイするプロセスについて説明します。
このチュートリアルの最後には、API を通じて呼び出すことができる機能する ML モデルが作成され、クラウド上に ML モデルをデプロイする方法についてより深く理解できるようになります。機械学習エンジニア、データ サイエンティスト、開発者を問わず、このチュートリアルは、ML と Docker の基本を理解している人であれば誰でもアクセスできるように設計されています。それでは、始めましょう!
Docker とは何ですか?
Docker は、コンテナーを使用してアプリケーションを簡単に作成、デプロイ、実行できるように設計されたツールです。コンテナを使用すると、開発者はアプリケーションを、ライブラリやその他の依存関係など、必要なすべての部分とともにパッケージ化し、1 つのパッケージとして送信できます。コンテナーを使用すると、開発者は、コードの作成とテストに使用したマシンとは異なるカスタム設定がマシンに存在するかどうかに関係なく、アプリケーションが他のマシン上で実行されることを保証できます。 Docker は、アプリケーションとその依存関係を、ある環境から別の環境に簡単に移動できる軽量でポータブルなコンテナにパッケージ化する方法を提供します。これにより、一貫した開発、テスト、運用環境の作成が容易になり、アプリケーションをより迅速かつ確実にデプロイできるようになります。ここから Docker をインストールします: https://docs.docker.com/get-docker/。
AWS Lambda とは何ですか?
アマゾン ウェブ サービス (AWS) Lambda は、イベントに応じてコードを実行し、基盤となるコンピューティング リソースを自動的に管理するサーバーレス コンピューティング プラットフォームです。これは AWS が提供するサービスで、開発者はコードの実行に必要なインフラストラクチャを気にすることなく、クラウドでコードを実行できます。 AWS Lambda は、受信リクエスト トラフィックに応じてアプリケーションを自動的にスケールし、消費したコンピューティング時間に対してのみ料金を支払います。このため、マイクロサービス、リアルタイム データ処理、イベント駆動型アプリケーションの構築と実行にとって魅力的な選択肢となります。
AWS ECR とは何ですか?
アマゾン ウェブ サービス (AWS) Elastic Container Registry (ECR) は、開発者が Docker コンテナ イメージを簡単に保存、管理、デプロイできるようにするフルマネージドの Docker コンテナ レジストリです。これは、開発者が AWS クラウドに Docker イメージを保存および管理し、それらを Amazon Elastic Container Service (ECS) またはその他のクラウドベースのコンテナ オーケストレーション プラットフォームに簡単にデプロイできる、安全でスケーラブルなサービスです。 ECR は、Amazon ECS や Amazon EKS などの他の AWS サービスと統合し、Docker コマンドライン インターフェイス (CLI) のネイティブ サポートを提供します。これにより、使い慣れた Docker コマンドを使用して ECR から Docker イメージをプッシュおよびプルし、コンテナ化されたアプリケーションの構築、テスト、デプロイのプロセスを自動化することが簡単になります。
AWS CLI のインストール
これを使用して、システムに AWS CLI をインストールします。 AWS アカウントに IAM ユーザーを作成して、AWS アクセス キー ID と AWS シークレット アクセス キーを取得します。インストール後、次のコマンドを実行して AWS CLI を設定し、必要なフィールドを挿入します。
aws configure
Docker を使用した Lambda 関数のデプロイ
このチュートリアルでは、OpenAI クリップ モデルをデプロイして入力テキストをベクトル化します。 Lambda 関数には Docker コンテナ内の amazon Linux 2 が必要なので、
public.ecr.aws/lambda/python:3.8 を使用します。さらに、Lambda には読み取り専用のファイル システムがあるため、内部でモデルをダウンロードすることができないため、イメージの作成時にモデルをダウンロードしてコピーする必要があります。
ここから動作するコードを取得して抽出します。
Dockerfile が配置されている作業ディレクトリを変更し、次のコマンドを実行します。
docker build -t lambda_image .
これで、イメージを Lambda にデプロイする準備ができました。ローカルで確認するには、次のコマンドを実行します。
docker run -p 9000:8080 lambda_image
これを確認するには、curl リクエストを送信します。入力テキストのベクトルが返されます。
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"text": "This is a test for text encoding"}'Output
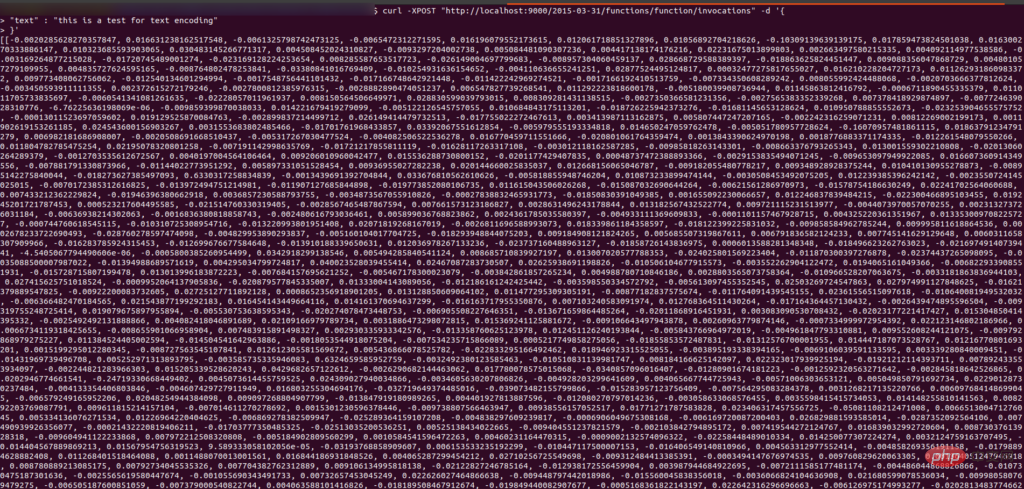
最初にイメージを Lambda にデプロイし、それを ECR にプッシュする必要があるため、AWS アカウントにログインし、ECR にウェアハウス lambda_image を作成します。リポジトリを作成した後、作成したリポジトリに移動すると、ビュー プッシュ コマンド オプションが表示され、それをクリックすると、イメージをリポジトリにプッシュするコマンドが表示されます。
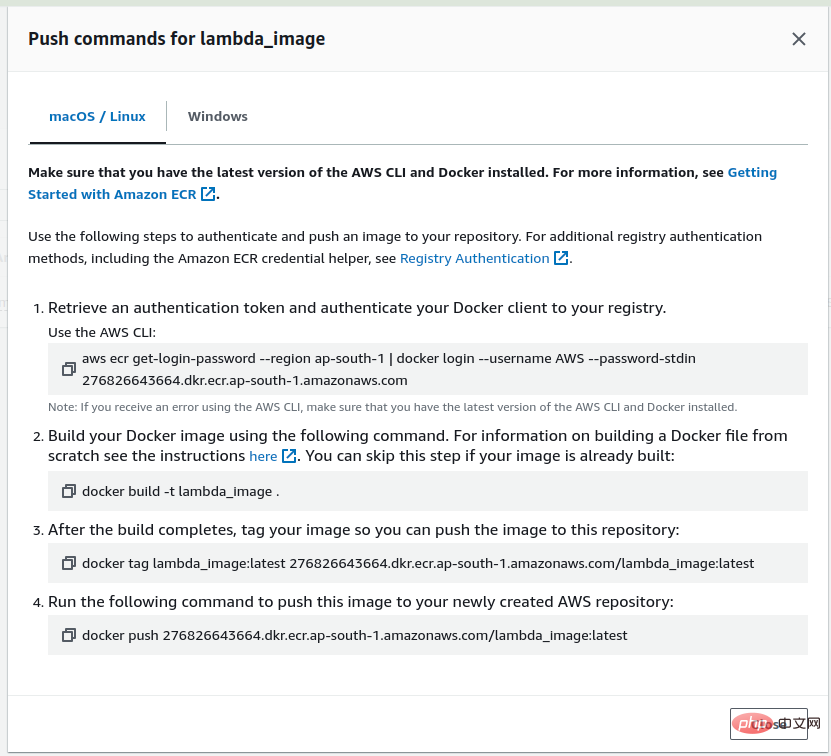
次に、最初のコマンドを実行して、AWS CLI を使用して Docker クライアントを認証します。
Docker イメージはすでに作成しているので、2 番目の手順をスキップし、3 番目のコマンドを実行して、作成したイメージをマークします。
运行最后一条命令将镜像推送到 ECR 中。运行后你会看到界面是这样的:
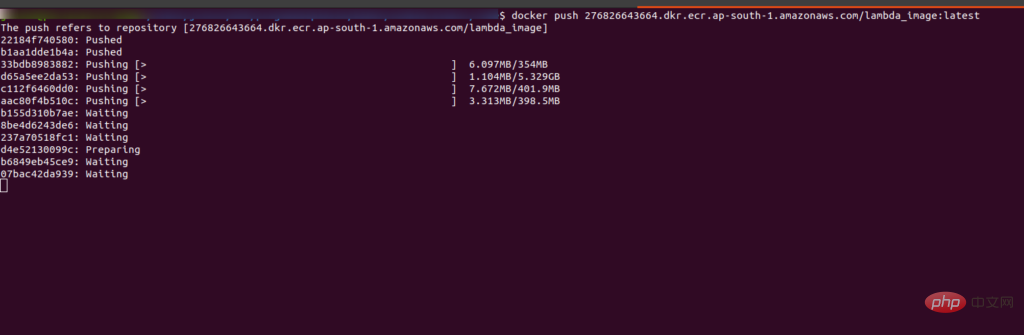
推送完成后,您将在 ECR 的存储库中看到带有“:latest”标签的图像。
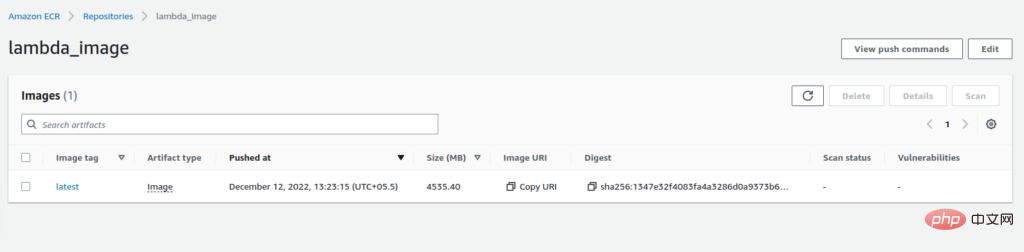
复制图像的 URI。我们在创建 Lambda 函数时需要它。
现在转到 Lambda 函数并单击“创建函数”选项。我们正在从图像创建一个函数,因此选择容器图像的选项。添加函数名称并粘贴我们从 ECR 复制的 URI,或者您也可以浏览图像。选择architecture x84_64,最后点击create_image选项。
构建 Lambda 函数可能需要一些时间,请耐心等待。执行成功后,你会看到如下界面:

Lambda 函数默认有 3 秒的超时限制和 128 MB 的 RAM,所以我们需要增加它,否则它会抛出错误。为此,请转到配置选项卡并单击“编辑”。
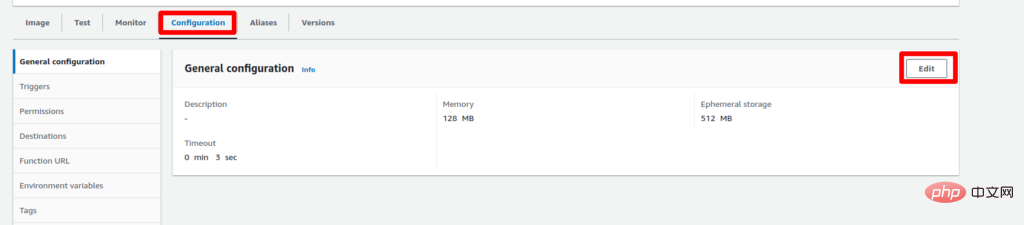
现在将超时设置为 5-10 分钟(最大限制为 15 分钟)并将 RAM 设置为 2-3 GB,然后单击保存按钮。更新 Lambda 函数的配置需要一些时间。
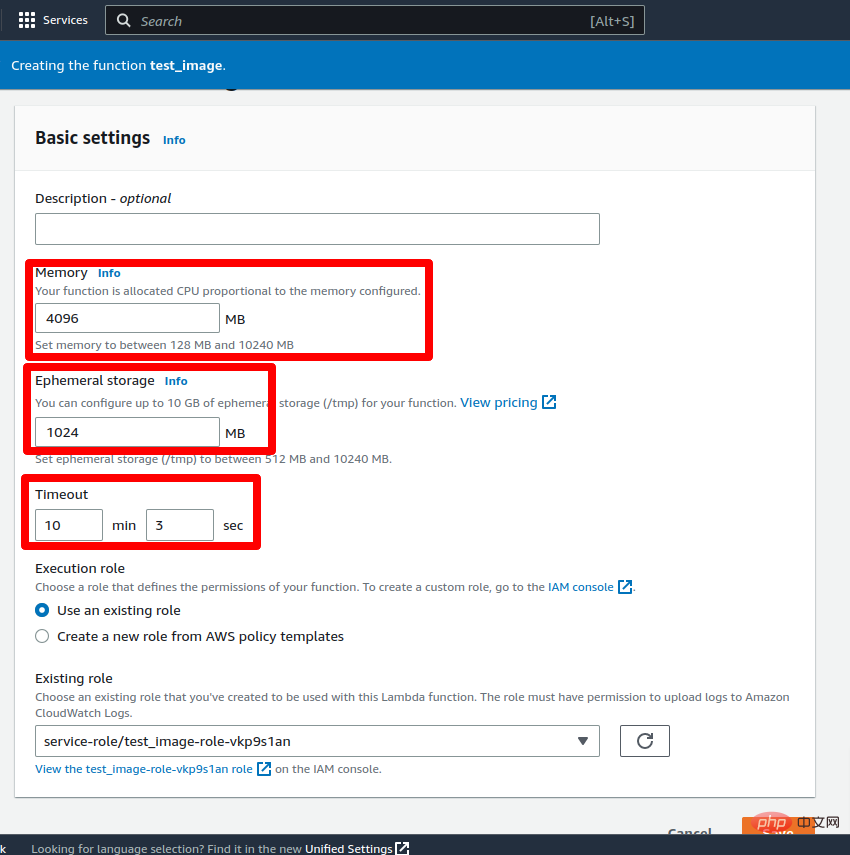
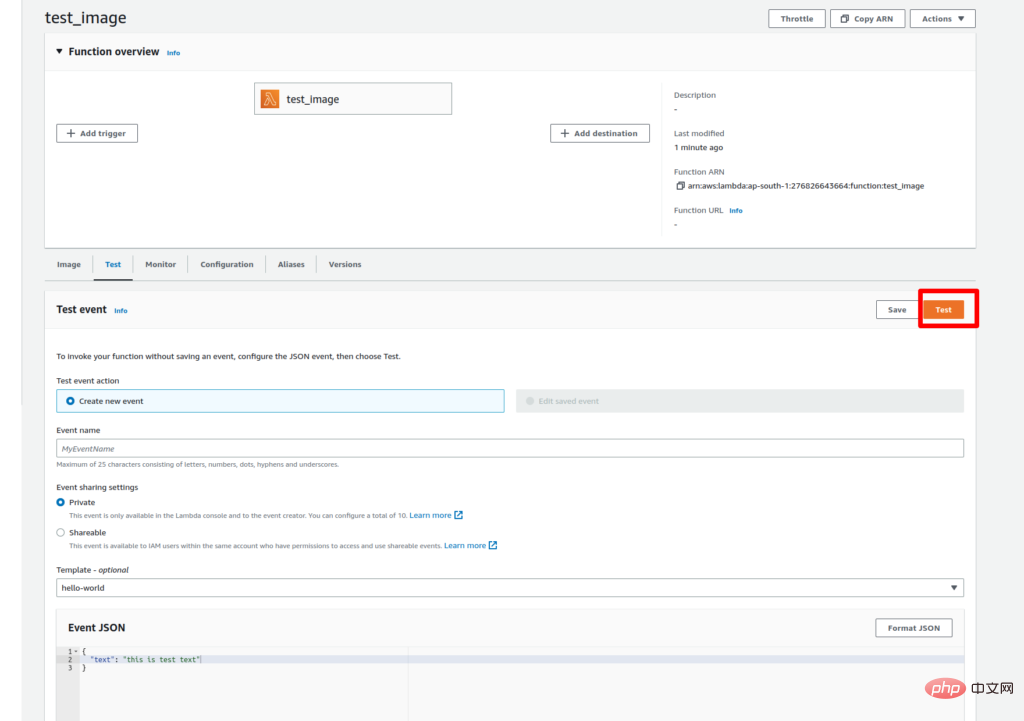
更新更改后,该功能就可以进行测试了。要测试 lambda 函数,请转到“测试”选项卡并将键值添加到事件 JSON 中作为文本:“这是文本编码测试。” 然后点击测试按钮。
由于我们是第一次执行 Lambda 函数,因此执行可能需要一些时间。成功执行后,您将在执行日志中看到输入文本的向量。
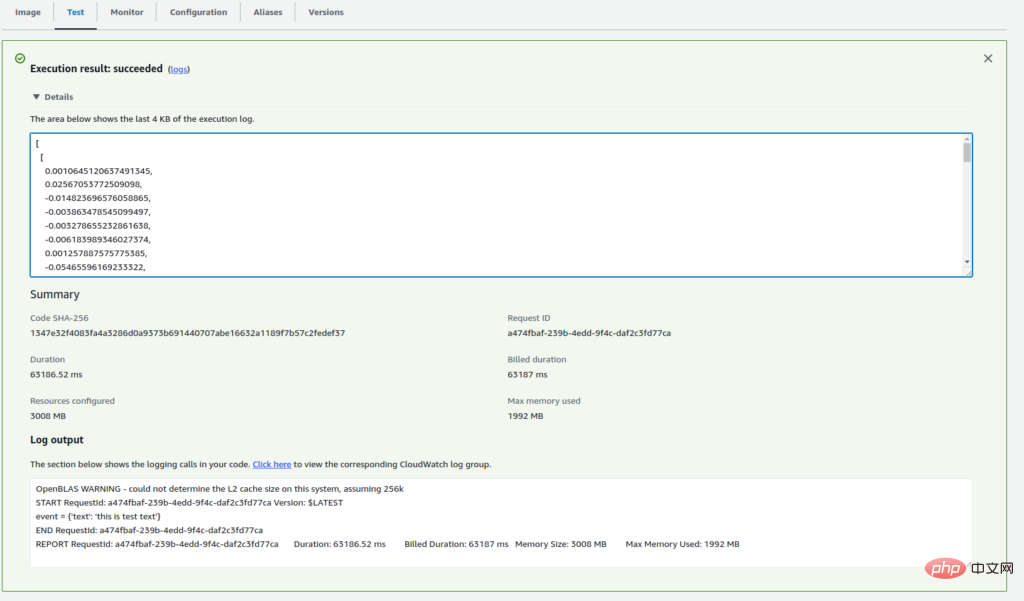
现在我们的 Lambda 函数已部署并正常工作。要通过 API 访问它,我们需要创建一个函数 URL。
要为 Lambda 函数创建 URL,请转到 Configuration 选项卡并选择 Function URL 选项。然后单击创建函数 URL 选项。

现在,保留身份验证 None 并单击 Save。
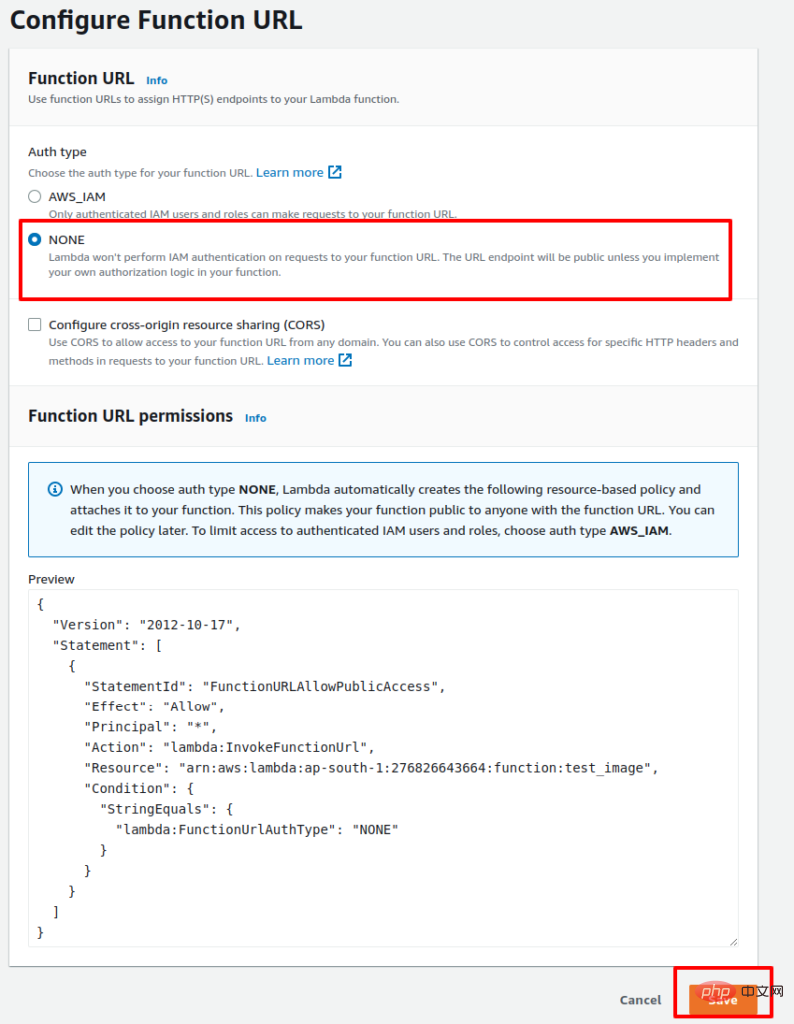
该过程完成后,您将获得用于通过 API 访问 Lambda 函数的 URL。以下是使用 API 访问 Lambda 函数的示例 Python 代码:
import requests function_url = ""url = f"{function_url}?text=this is test text" payload={}headers = {} response = requests.request("GET", url, headers=headers, data=payload) print(response.text)成功执行代码后,您将获得输入文本的向量。

所以这是一个如何使用 Docker 在 AWS Lambda 上部署 ML 模型的示例。如果您有任何疑问,请告诉我们。
以上がDocker を使用して AWS Lambda に機械学習モデルをデプロイする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
ピン張りのノードの詳細な説明とインストールガイドこの記事では、ピネットワークのエコシステムを詳細に紹介します - PIノードは、ピン系生態系における重要な役割であり、設置と構成の完全な手順を提供します。 Pinetworkブロックチェーンテストネットワークの発売後、PIノードは多くの先駆者の重要な部分になり、テストに積極的に参加し、今後のメインネットワークリリースの準備をしています。まだピン張りのものがわからない場合は、ピコインとは何かを参照してください。リストの価格はいくらですか? PIの使用、マイニング、セキュリティ分析。パインワークとは何ですか?ピン競技プロジェクトは2019年に開始され、独占的な暗号通貨PIコインを所有しています。このプロジェクトは、誰もが参加できるものを作成することを目指しています
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールするには、Dockerコンテナ(最も便利な場合は、互換性について心配する必要はありません)を使用して、事前コンパイルパッケージ(Windowsユーザー向け)を使用してソースからコンパイル(経験豊富な開発者向け)を含む多くの方法があります。公式文書は慎重に文書化され、不必要なトラブルを避けるために完全に準備します。
