

最も一般的に使用されている機械学習アルゴリズムのトップ 10 の図解!

機械学習の分野では、「世界にフリーランチは存在しない」という格言があります。つまり、あらゆる問題に対して最良の効果をもたらすアルゴリズムは存在しないということです。この理論は特に教師あり学習です。重要。
たとえば、ニューラル ネットワークが常にデシジョン ツリーよりも優れているとは言えず、またその逆も同様です。モデルの実行は、データ セットのサイズや構造など、多くの要因の影響を受けます。
したがって、データのテスト セットを使用してパフォーマンスを評価し、最適なものを選択しながら、問題に基づいてさまざまなアルゴリズムを試す必要があります。
もちろん、試行するアルゴリズムは問題に関連している必要があり、鍵となるのは機械学習の主なタスクです。たとえば、家を掃除したい場合、掃除機、ほうき、またはモップを使用することはできますが、シャベルをつかんで穴を掘り始めることはありません。
機械学習の基礎を理解したいと考えている機械学習の初心者向けに、データ サイエンティストが使用する機械学習アルゴリズムのトップ 10 をここに示します。これにより、誰もがより優れた学習を行えるように、これらのトップ 10 のアルゴリズムの特徴を紹介します。ご理解の上、お申し込みの上、見に来てください。
01 線形回帰
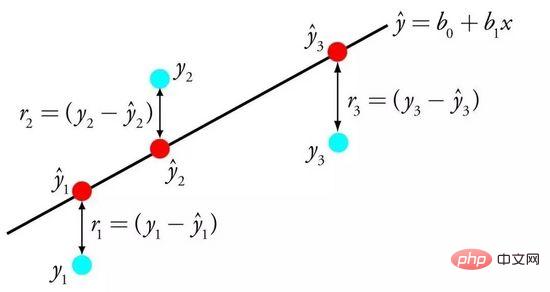
線形回帰は、おそらく統計と機械学習において最もよく知られており、最も理解しやすいアルゴリズムの 1 つです。
予測モデリングは主に、モデルの誤差を最小限に抑えること、または解釈可能性を犠牲にして最も正確な予測を行うことに関係しているためです。私たちはさまざまな分野からアルゴリズムを借用、再利用、盗用しており、ある程度の統計知識が関係しています。
線形回帰は、入力変数の特定の重み (B) を求めることによって、入力変数 (x) と出力変数 (y) の間の線形関係を記述する方程式によって表されます。
 #線形判別分析
#線形判別分析
LDA は、各クラスの判別値を計算し、最大値を持つクラスの予測を行うことによって実行されます。この手法では、データがガウス分布 (釣鐘曲線) であることを前提としているため、最初にデータから外れ値を手動で削除することが最善です。これは、分類予測モデリング問題におけるシンプルかつ強力なアプローチです。
04 分類と回帰ツリー
デシジョン ツリーは機械学習にとって重要なアルゴリズムです。
デシジョン ツリー モデルはバイナリ ツリーで表すことができます。はい、これはアルゴリズムとデータ構造からなるバイナリ ツリーであり、特別なことは何もありません。各ノードは、単一の入力変数 (x) とその変数の左右の子を表します (変数が数値であると仮定します)。
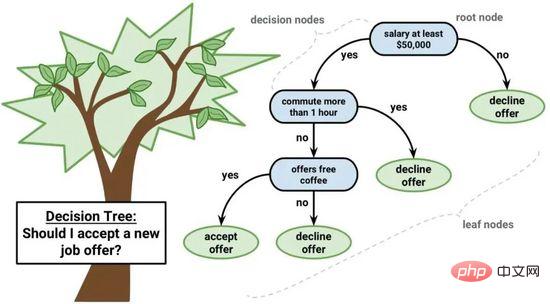
デシジョン ツリー
ツリーのリーフ ノードには、予測を行うために使用される出力変数 (y) が含まれています。予測は、ツリーをトラバースし、特定のリーフ ノードに到達したときに停止し、リーフ ノードのクラス値を出力することによって実行されます。
デシジョン ツリーは学習速度と予測速度が速いです。予測は多くの問題に対して正確であることが多く、データに対して特別な準備を行う必要はありません。
05 Naive Bayes
Naive Bayes は、シンプルですが非常に強力な予測モデリング アルゴリズムです。
モデルは、トレーニング データから直接計算できる 2 種類の確率で構成されます: 1) 各クラスの確率、2) 各 x 値が与えられたクラスの条件付き確率。確率モデルを計算したら、ベイズの定理を使用して新しいデータを予測するために使用できます。データが数値の場合、これらの確率を簡単に推定できるように、ガウス分布 (釣鐘曲線) を仮定するのが一般的です。
ベイズの定理
単純ベイズが素朴と呼ばれる理由は、各入力変数が独立していると仮定しているためです。これは実際のデータでは非現実的な強力な仮定ですが、この手法は大規模な複雑な問題に対して依然として非常に効果的です。
06 K 最近傍
KNN アルゴリズムは非常にシンプルで、非常に効果的です。 KNN のモデルは、トレーニング データ セット全体によって表されます。とても簡単なことではありませんか?
トレーニング セット全体で最も類似した K 個のインスタンス (近傍) を検索し、これらの K 個のインスタンスの出力変数を要約することで、新しいデータ ポイントを予測します。回帰問題の場合、新しい点は平均出力変数である可能性があり、分類問題の場合、新しい点は最頻値カテゴリ値である場合があります。
成功の秘訣は、データ インスタンス間の類似性を判断する方法にあります。属性がすべて同じスケールにある場合、最も簡単な方法は、各入力変数間の差から直接計算できるユークリッド距離を使用することです。
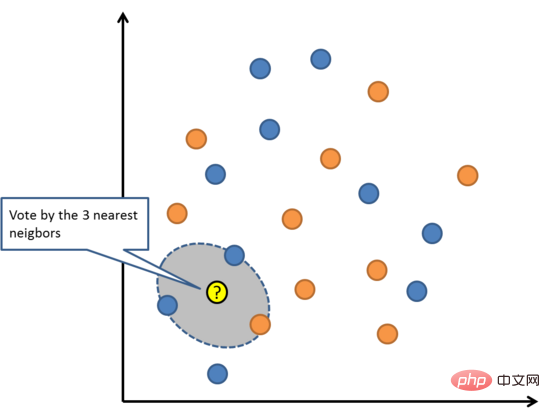
K 最近傍法
KNN は、すべてのデータを保存するために大量のメモリまたはスペースを必要とする可能性がありますが、計算は予測が必要な場合にのみ実行されます (または勉強します)。予測の精度を維持するために、いつでもトレーニング セットを更新および管理することもできます。
高次元環境 (多数の入力変数) では、距離または近さの概念が崩れる可能性があり、アルゴリズムに悪影響を与える可能性があります。このような出来事は次元の呪いとして知られています。また、出力変数の予測に最も関連する入力変数のみを使用する必要があることも意味します。
07 学習ベクトル量子化
K 最近傍法の欠点は、トレーニング データ セット全体を維持する必要があることです。学習ベクトル量子化 (略して LVQ) は、任意の数のトレーニング インスタンスを一時停止して正確に学習できる人工ニューラル ネットワーク アルゴリズムです。
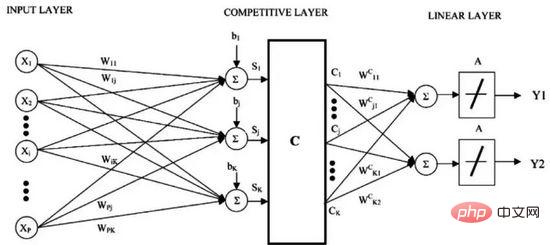
学習ベクトル量子化
LVQ は、コードブック ベクトルのコレクションによって表されます。まずベクトルをランダムに選択し、トレーニング データ セットに適応するために複数回繰り返します。学習後、コードブック ベクトルは K 最近傍法と同様に予測に使用できます。各コードブック ベクトルと新しいデータ インスタンス間の距離を計算して、最も類似した近傍 (最良一致) を見つけ、最も一致するユニットのクラス値、または回帰の場合は実際の値を予測として返します。データを同じ範囲 (0 と 1 の間など) に制限すると、最良の結果が得られます。
KNN がデータセットで良好な結果をもたらすことがわかった場合は、LVQ を使用して、トレーニング データセット全体を保存するためのメモリ要件を削減してみてください。
08 サポート ベクター マシン
サポート ベクター マシンは、おそらく最も人気があり、議論されている機械学習アルゴリズムの 1 つです。
超平面は、入力変数空間を分割する線です。 SVM では、カテゴリ (カテゴリ 0 またはカテゴリ 1) に従って入力変数空間内の点を分離するために超平面が選択されます。これは 2 次元空間内の線とみなすことができ、すべての入力点はこの線によって完全に分離できます。 SVM 学習アルゴリズムは、超平面がカテゴリを最適に分離できるようにする係数を見つけることです。
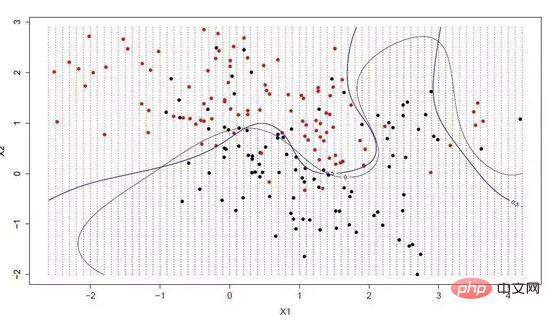
サポート ベクター マシン
超平面と最も近いデータ ポイントの間の距離は境界と呼ばれ、境界が最も大きい超平面が最良の選択です。同時に、これらの近いデータ ポイントのみが超平面の定義と分類器の構築に関連しており、これらの点はサポート ベクトルと呼ばれ、超平面をサポートまたは定義します。具体的な実践では、最適化アルゴリズムを使用して、境界を最大化する係数値を見つけます。
SVM は、おそらく最も強力なすぐに使用できる分類器の 1 つであり、データセットで試してみる価値があります。
09 バギングとランダム フォレスト
ランダム フォレストは、最も人気があり強力な機械学習アルゴリズムの 1 つです。これは、ブートストラップ集約またはバギングと呼ばれる統合機械学習アルゴリズムです。
ブートストラップは、データのサンプルから平均などの量を推定するための強力な統計手法です。多数のサンプル データを取得して平均を計算し、すべての平均を平均して真の平均のより正確な推定値を取得します。
同じ方法がバギングでも使用されますが、統計モデル全体を推定する代わりにデシジョン ツリーが最も一般的に使用されます。トレーニング データをマルチサンプリングし、各データ サンプルのモデルを構築します。新しいデータに対して予測を行う必要がある場合、各モデルは予測を行い、その予測を平均して、真の出力値をより適切に推定します。
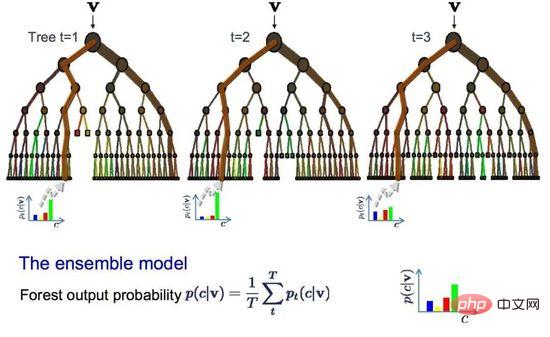
ランダム フォレスト
ランダム フォレストは決定木を調整したものです。最適な分割点を選択するのと比較して、ランダム フォレストはランダム性を導入することによって実現されます。 。
結果として、各データ サンプルに対して作成されたモデルは互いにより異なりますが、それでも独自の意味では正確です。予測結果を組み合わせることで、潜在的な正確な出力値をより適切に推定できます。
高分散アルゴリズム (デシジョン ツリーなど) を使用して良好な結果が得られた場合、このアルゴリズムを追加するとさらに良好な結果が得られます。
10 ブースティングと AdaBoost
ブースティングは、いくつかの弱分類器から強い分類器を作成するアンサンブル手法です。まずトレーニング データからモデルを構築し、次に 2 番目のモデルを作成して、最初のモデルのエラーを修正しようとします。トレーニング セットが完全に予測するか、上限に達するまでモデルを継続的に追加します。
AdaBoost は、バイナリ分類用に開発された初めて真に成功したブースティング アルゴリズムであり、ブースティングを理解するための最良の出発点でもあります。現在、AdaBoost に基づいて構築されている最も有名なアルゴリズムは、確率的勾配ブースティングです。
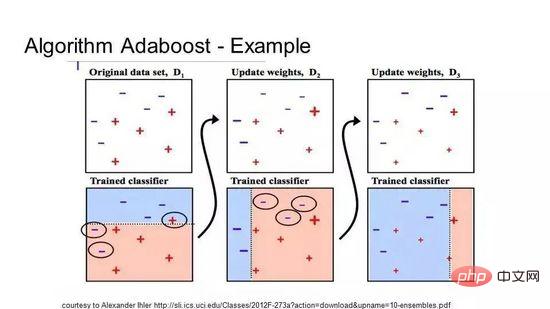
AdaBoost
AdaBoost は、短いデシジョン ツリーでよく使用されます。最初のツリーが作成された後、ツリー上の各トレーニング インスタンスのパフォーマンスによって、次のツリーがそのトレーニング インスタンスにどれだけの注意を払う必要があるかが決まります。予測が難しいトレーニング データにはより大きな重みが与えられ、予測が容易なインスタンスにはより小さな重みが与えられます。モデルは順番に作成され、各モデルの更新はシーケンス内の次のツリーの学習効果に影響を与えます。すべてのツリーが構築された後、アルゴリズムは新しいデータに対して予測を行い、トレーニング データの正確さによって各ツリーのパフォーマンスに重み付けを行います。
アルゴリズムはエラー修正を非常に重視するため、外れ値のないクリーンなデータが非常に重要です。
さまざまな機械学習アルゴリズムに直面したときに初心者が抱く典型的な質問は、「どのアルゴリズムを使用すればよいですか?」です。この質問に対する答えは、次のような多くの要因によって決まります。
- データのサイズ、品質、性質;
- 利用可能なコンピューティング時間;
- タスクの緊急性;
- データを使って何をしたいのか。
経験豊富なデータ サイエンティストでも、さまざまなアルゴリズムを試してみない限り、どのアルゴリズムが最もパフォーマンスが高いかを知る方法はありません。他にも多くの機械学習アルゴリズムがありますが、これらのアルゴリズムが最も人気があります。機械学習を初めて使用する場合は、ここから始めるのが最適です。
以上が最も一般的に使用されている機械学習アルゴリズムのトップ 10 の図解!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7622
7622
 15
1389
52
89
11
31
138
15
1389
52
89
11
31
138

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
