

CMU、日常的な家具の操作方法を正確に学習する新しい器用なロボット アルゴリズムを公開

人々が日常生活で接触する家具のほとんどは、引き出しレール付きの引き出し、垂直回転軸付きのドア、水平回転軸付きのドアなどの「関節のある物体」です。これらのオブジェクトの一部はさまざまなジョイントによって接続されています。
これらのジョイントの存在により、接続されたオブジェクトのパーツのさまざまな部分がジョイントによって運動学的に拘束されるため、これらのパーツの自由度は 1 つだけ (1 DoF) になります。 。これらのアイテムは、私たちの生活のあらゆるところ、特に毎日の家庭にあり、私たちの日常生活の重要な一部となっています。私たち人間は、どんな種類の家具を持っていても、それを操作し制御する方法をすぐに理解できると考えています。あたかもこれらの物体のすべての関節がどのように動くかを知っているかのようです。
では、ロボットは人間のように家具がどのように動くかを予測できるのでしょうか?この種の予測能力を獲得することは困難であり、ロボットがこの能力を学習できれば、家庭用ロボットにとって大きな後押しとなるでしょう。
最近、CMU ロボット工学大学院のデビッド ヘルド教授の R-PAD 研究室の 2 人の学生、ベン アイズナーとハリー チャンは、複雑な関節オブジェクトの操作で画期的な進歩を遂げ、ニューラル ネットワーク用の 3D ベースの FlowBot 3D は、日常的な家具などの関節オブジェクトの一部の動作軌跡を効果的に表現および予測するアルゴリズムです。アルゴリズムには 2 つの部分が含まれています。
最初の部分は知覚部分で、3D ディープ ニューラル ネットワークを使用して、操作された家具オブジェクトの点群データから 3 次元の瞬間的な動きの軌跡を予測します (3D 多関節フロー) )。
アルゴリズムの 2 番目の部分はポリシー部分で、予測された 3D 多関節フローを使用してロボットの次のアクションを選択します。どちらもシミュレーターで完全に学習され、再トレーニングや調整を行わずに現実世界に直接実装できます。 FlowBot 3D アルゴリズムの助けを借りて、ロボットは人間と同じように日常の家具などの多関節オブジェクトを自由に操作できます。


この論文は現在、世界トップクラスのロボット工学カンファレンスである Robotics Science およびSystems (RSS) 2022 の最優秀論文候補 (上位 3%) であり、7 月に米国ニューヨークで展示され、他の 7 つの優れた論文とともに最優秀論文の栄誉を競います。
- 論文アドレス: https://arxiv.org/pdf/2205.04382.pdf
- プロジェクト ホームページ: https:// sites.google.com/view/articulated-flowbot-3d
FlowBot 3D はシミュレーターのみに依存し、シミュレートされたデータに対して教師あり学習を実行して、日常の家具などの関節のあるオブジェクトを学習します。部品の瞬間的な運動軌跡 (3D 関節流)。 3D Articulated Flow は、ロボットの次の戦略の複雑さを大幅に簡素化し、一般化と効率を向上させることができる視覚的な点群の軌道表現方法です。ロボットは、この瞬間的な軌道をたどり、この軌道を閉ループで再予測するだけで、関節オブジェクトを操作するタスクを完了できます。
これまで、家具などの関節物体を操作する学術界における従来の手法は、操作対象物の幾何学的特性(位置や方向など)から部品の移動方向を計算することでした。または、専門家の戦略 (通常は人間の) を模倣して、特定のオブジェクトの操作を学習し、ジョイント オブジェクト操作の複雑なアクションを完了します。これらのアカデミアにおける従来の手法は一般化が不十分であり、データの活用効率も低く、トレーニングには人間による大量の実証データの収集が必要です。これらとは異なり、FlowBot 3D は人間によるデモンストレーション データの提供を必要としない初の純粋なシミュレーター ベースの学習であり、アルゴリズムによりロボットは各パーツの瞬間的な動作軌跡を学習することで最適なオブジェクト操作パスを計算できます。アルゴリズムは汎用性が高い。この機能により、FlowBot 3D はシミュレーター トレーニング中に目に見えないオブジェクトに一般化し、実際の日常的な家具アイテムを現実世界で直接操作することができます。
次のアニメーションは、FlowBot 3D の操作プロセスを示しています。左側は操作されたビデオ、右側は点群 3D Articulated Flow の予測された瞬間運動軌跡です。 FlowBot 3D アルゴリズムにより、ロボットはまずオブジェクト上のどの部分を操作できるかを特定し、その部分の移動方向を予測できます。
冷蔵庫のドアを開けます:


便座を開けます:

##引き出しを開けてください:


人間がドアなどの新しい家具を見るとき、ドアがドア軸を中心に回転することがわかり、ドア軸の制約もわかります。このドアは、一方向に回転するので、頭の中で想像した方向に従ってドアを開けることができます。したがって、ロボットに家具などの関節オブジェクトの操作方法や動作軌道を本当に器用に予測できるようにしたい場合、効果的な方法は、ロボットにこれらの部品の運動学的制約を理解させ、これらのオブジェクトの動き、軌道。
FlowBot 3D の具体的な方法は複雑ではなく、複雑な実際の人間のデータを必要とせず、シミュレーターのみに依存します。さらに、シミュレータのもう 1 つの利点は、シミュレータでは、これらの家庭用オブジェクトの 3D データ ファイル (URDF) に各部品の運動学的制約とその制約の特定のパラメータが含まれているため、各部品の運動軌跡がシミュレーターで正確に計算できます。
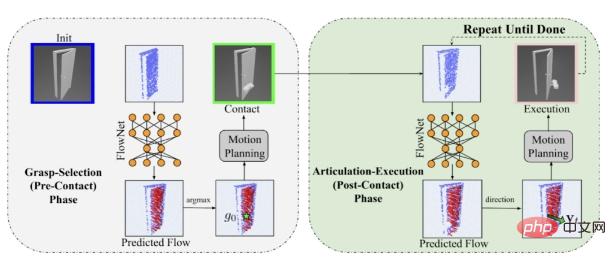

シミュレータのトレーニング中に、ロボットは操作対象の 3 次元点群データをロボット ビジョン モジュールへの入力データとして観察します。ビジョンモジュール (知覚モジュール) は、PointNet を使用して、外力の作用下で入力点群内の各点の瞬間的な運動軌跡の 3D 多関節フローを予測します (たとえば、引き出しが 1 cm 開いた後、ドアが外側に開きます 5度)、貧弱な形で表現された 3 次元座標ベクトルを使用します。この運動軌跡の実際のデータは、順運動学によって正確に計算できます。次の3次元ベクトル座標から現在の3次元ベクトル座標を減算することで、操作対象部位の動作軌跡を求めることができる。したがって、教師あり学習では、トレーニング中に、予測された 3D 多関節フローの L2 損失のみを最小限に抑える必要があります。
 #この図では、青い点は観測された点群データであり、赤い矢印は予測されたファサードを表します。明確なフロー。
#この図では、青い点は観測された点群データであり、赤い矢印は予測されたファサードを表します。明確なフロー。
このように学習することで、FlowBot 3D は運動学的制約下での各部品の移動方向と、部品上の各点が同じ力を受ける状況を学習できます。相対速度と相対運動方向 (速度)。一般的な家庭用ジョイントアイテムは、角柱状で回転したものです。引き出しなどのトゥイッチ部品は、同じ外力を受けたとき、引き出し表面の各点の移動方向と速度は同じです。ドアなどの回転部品は、同じ外力を受けた場合、ドア表面の各点の移動方向は同じですが、回転軸から離れるほど速度が速くなります。研究者らは、ロボット工学の物理法則 (ネジ理論) を使用して、最長の 3D 関節流が物体の加速度を最大化できることを証明しました。ニュートンの第 2 法則によれば、この戦略は最適解です。



#理論的根拠に基づいて、実際の運用ではどうなるのかロボットが行う必要があるのは、FlowBot 3D のビジョン モジュールを通じて各点の移動軌跡を予測することです。各点の軌跡の中で、最も長い 3D 多関節流れ方向に対応する点を操作点として見つけ、この操作を閉じた状態で予測します。ループ ポイントの移動軌跡。選択した操作点がうまく掴めない場合(ロボットハンドの掴み条件を満たさない面など)、FlowBot 3D は掴み条件を満たす 2 番目に長い点を選択します。
また、FlowBot 3D は、PointNet の特性により、オブジェクト自体の幾何学的特性に依存せず、各点の運動軌跡を予測します。ロボットによるオブジェクトの遮蔽の可能性。さらに、このアルゴリズムは閉ループであるため、ロボットは予測の次のステップで考えられるエラーを修正できます。
実世界における FlowBot 3D のパフォーマンスFlowBot 3D は、実世界における一般化の課題を克服する能力を備えています。 FlowBot 3D の設計コンセプトは、操作対象の 3D 多関節フローの移動軌跡を正確に予測できる限り、次のステップはこの軌跡に従ってタスクを完了することです。
もう 1 つの重要な点は、FlowBot 3D が単一のトレーニング モデルを使用して、トレーニングで表示されなかったカテゴリを含む複数のアイテム カテゴリを操作することです。そして現実の世界では、ロボットはこの純粋なシミュレーターのトレーニングを通じて取得したモデルを使用するだけで、さまざまな現実のオブジェクトを操作できます。したがって、現実世界では、家庭内のオブジェクトの運動学的制約はシミュレータ内と圧倒的に同じであるため、FlowBot 3D を現実世界に直接一般化できます。

実世界の実験で FlowBot3D によって使用される家庭用品 (ゴミ箱、冷蔵庫、便座、ボックス、金庫などを含む)
シミュレータでは、ロボットは、ホッチキス、ゴミ箱、引き出し、窓、冷蔵庫などのいくつかのカテゴリの家庭用品を使用してトレーニングされます。シミュレータと実際のテストでは、テスト データ 新しいオブジェクトトレーニング カテゴリとトレーニング中に表示されなかったカテゴリから。





これに比べ、学術界で一般的に見られる模倣ベースのシミュレーションでは、新しい操作方法を学習するには手動のガイダンスが必要です。オブジェクトが多く、これらのロボットを現実世界、特に家庭用ロボットのシナリオに実装するのは非現実的です。さらに、3D 点群データは、他の方法で使用される 2D RGB データよりも強力です。点群によりロボットはそれぞれのオブジェクトを理解できるため、関節と関節間の関係をより高いレベルで理解および予測できるため、一般化が大幅に強化されます。
実験結果によると、FlowBot 3D は、ほとんどのオブジェクト (トレーニング中に表示されるカテゴリであるかどうかにかかわらず) を操作するときに「全開」までの距離が 10% 未満に達し、Success Ridge はそれ以上に到達できることが示されています。 90.比較すると、模倣学習 (DAgger) や強化学習 (SAC) に基づく他の方法は大きく遅れており、一般化が欠けています。

つまり、FlowBot 3D は大きな可能性を秘めた仕事です。微調整を必要とせずに、現実世界に効率的に導入できます。この研究は、コンピューター ビジョンの進歩がロボット工学の分野、特に 3D 多関節フローと呼ばれる動作軌跡の視覚的表現を変える可能性があることも示しています。これは、ロボット戦略の選択と意思決定のプロセスを簡素化するために複数のタスクに適用できます。この一般化可能な表現により、シミュレータ学習方法は現実世界に直接展開できる可能性があり、将来の家庭用ロボットのトレーニングと学習のコストが大幅に削減されます。
FlowBot 3Dの次の計画現在研究チームは、流れの使い方など、関節物体以外の物体にも流れの理解と予測手法を適用しようとしています。 6 自由度で物体の軌道を予測します。同時に、著者はフローを一般的な視覚表現として使用して、強化学習などの他のロボット学習タスクに適用し、それによって学習効率、ロバスト性、一般化性を高めようとしています。
David Held 准教授のホームページ: https://davheld.github.io/Ben Aisner のホームページ: https://beisner.me/Harry Zhang のホームページ: https://harryzhangog。 github.io/
以上がCMU、日常的な家具の操作方法を正確に学習する新しい器用なロボット アルゴリズムを公開の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
39
15
1377
52
77
11
19
39

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
産業オートメーション技術の分野では、人工知能 (AI) と Nvidia という無視できない 2 つの最近のホットスポットがあります。元のコンテンツの意味を変更したり、コンテンツを微調整したり、コンテンツを書き換えたり、続行しないでください。「それだけでなく、Nvidia はオリジナルのグラフィックス プロセッシング ユニット (GPU) に限定されていないため、この 2 つは密接に関連しています。」このテクノロジーはデジタル ツインの分野にまで広がり、新たな AI テクノロジーと密接に関係しています。「最近、NVIDIA は、Aveva、Rockwell Automation、Siemens などの大手産業オートメーション企業を含む多くの産業企業と提携に至りました。シュナイダーエレクトリック、Teradyne Robotics とその MiR および Universal Robots 企業も含まれます。最近、Nvidiahascoll
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
