

Python は見事なサンキー図を描画します。学習しましたか?

サンキー ダイアグラムの概要
多くの場合、エンティティ間でデータがどのように流れるかを視覚化する必要がある状況が必要になります。たとえば、住民がある国から別の国に移動する方法を考えてみましょう。これは、イングランドから北アイルランド、スコットランド、ウェールズにどれだけの住民が移住したかを示しています。
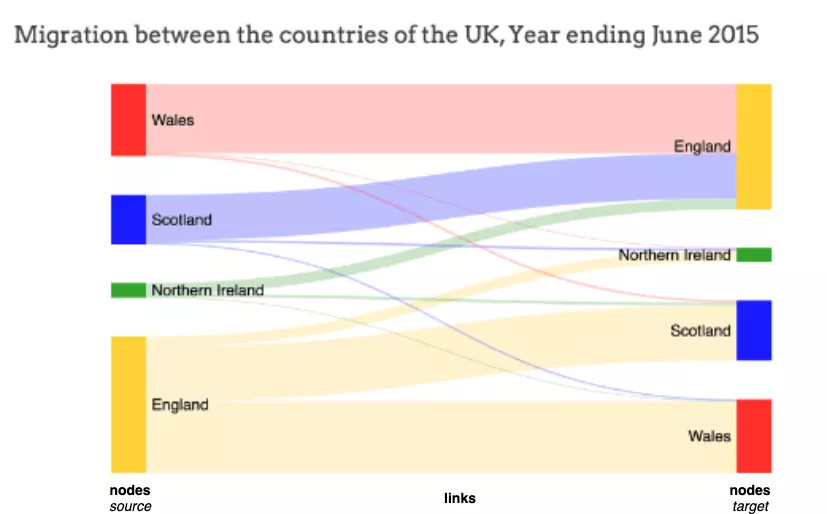
このサンキーの視覚化から、スコットランドや北アイルランドよりもイングランドからウェールズに移住した住民の方が多いことが明らかです。
サンキー ダイアグラムとは何ですか?
サンキー ダイアグラムは通常、あるエンティティ (またはノード) から別のエンティティ (またはノード) へのデータの流れを表します。
データ フローの宛先のエンティティはノードと呼ばれます。データ フローが開始するノードはソース ノード (たとえば、左側のイングランド)、フローが終了するノードはターゲット ノード (たとえば、たとえば、右側はウェールズです)。ソース ノードとターゲット ノードは通常、ラベル付きの四角形として表されます。
フロー自体は、リンクと呼ばれる直線または曲線のパスによって表されます。ストリーム/リンクの幅は、ストリームの量/数に直接比例します。上の例では、イングランドからウェールズへの移動(つまり住民の移動)は、イングランドからスコットランドまたは北アイルランドへの移動(つまり住民の移動)よりも広範囲にわたっており、より多くの住民がいることを示しています。他の国よりもウェールズに移ります。
サンキー ダイアグラムは、エネルギー、お金、コストなど、フローの概念を持つあらゆるものの流れを表すために使用できます。
ナポレオンのロシア侵攻を描いたミナールの古典的なチャートは、おそらくサンキー チャートの最も有名な例です。サンキー図を使用したこの視覚化は、フランス軍がロシアへの往復の途中でどのように進歩 (または減少?) したかを非常に効果的に示しています。

#この記事では、Python のプロットを使用してサンキー図を描画します。
サンキー ダイアグラムを描画する方法?
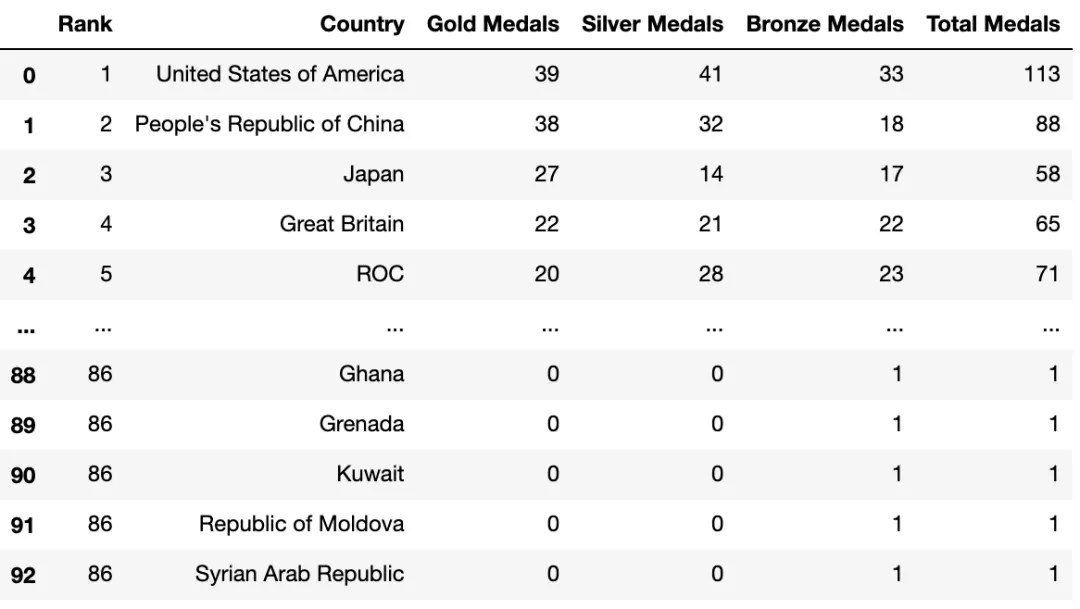
この記事では、2021 年のオリンピック データ セットを使用してサンキー ダイアグラムを描画します。データセットには、メダルの総数 (国、メダルの総数、金、銀、銅メダルの個人の合計) に関する詳細情報が含まれています。サンキー チャートをプロットして、国が獲得した金、銀、銅メダルの数を確認します。
df_medals = pd.read_excel("data/Medals.xlsx")
print(df_medals.info())
df_medals.rename(columns={'Team/NOC':'Country', 'Total': 'Total Medals', 'Gold':'Gold Medals', 'Silver': 'Silver Medals', 'Bronze': 'Bronze Medals'}, inplace=True)
df_medals.drop(columns=['Unnamed: 7','Unnamed: 8','Rank by Total'], inplace=True)
df_medals<class 'pandas.core.frame.DataFrame'> RangeIndex: 93 entries, 0 to 92 Data columns (total 9 columns): # Column Non-Null CountDtype --------- ------------------- 0 Rank 93 non-null int64 1 Team/NOC 93 non-null object 2 Gold 93 non-null int64 3 Silver 93 non-null int64 4 Bronze 93 non-null int64 5 Total93 non-null int64 6 Rank by Total93 non-null int64 7 Unnamed: 7 0 non-nullfloat64 8 Unnamed: 8 1 non-nullfloat64 dtypes: float64(2), int64(6), object(1) memory usage: 6.7+ KB None
Sankey 図の描画の基礎
plotly の go.Sankey を使用します。このメソッドは、ノードとリンク (nodes と links ) の 2 つのパラメーターを受け取ります。
注: すべてのノード (ソースとターゲット) には一意の識別子が必要です。
この記事で設定されているオリンピックのメダルデータの場合:
出典は国です。最初の 3 か国 (米国、中国、日本) をソース ノードとして考えます。これらのソース ノードに次の (一意の) 識別子、ラベル、色を付けます。
- 0: 米国: 緑
- 1: 中国: 青
- 2 : 日本: オレンジ
対象は金、銀、銅のいずれかです。これらのターゲット ノードに、次の (一意の) 識別子、ラベル、色を付けます。
- 3: 金メダル: 金
- 4: 銀メダル: シルバー
- 5 : ブロンズ: ブラウン
リンク(ソースノードとターゲットノード間)は、各種類のメダルの数です。各ソースには 3 つのリンクがあり、各リンクはターゲット (ゴールド、シルバー、ブロンズ) で終わります。つまり、リンクは合計 9 つあります。各リンクの幅は、金、銀、銅のメダルの数でなければなりません。これらのリンクを次のソースでターゲット、値、色にタグ付けします:
- 0 (米国) から 3,4,5 : 39, 41, 33
- 1 (中国) ) to 3 ,4,5 : 38, 32, 18
- 2 (日本) to 3,4,5 : 27, 14, 17
2 つの Python をインスタンス化する必要がありますdict オブジェクトを表します。
- ノード (ソースとターゲット): 個別のリストとしてのラベルと色、および
- リンク: ソース ノード、ターゲット ノード、リンクの値 (幅) と色別のリスト
として、plotly の go.Sankey に渡します。
リストの各インデックス (ラベル、ソース、ターゲット、値、色) は、ノードまたはリンクに対応します。
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) LINKS = dict( source = [0,0,0,1,1,1,2,2,2], # 链接的起点或源节点 target = [3,4,5,3,4,5,3,4,5], # 链接的目的地或目标节点 value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17], # 链接的宽度(数量) # 链接的颜色 # 目标节点: 3-Gold4-Silver5-Bronze color = [ "lightgreen", "lightgreen", "lightgreen",# 源节点:0 - 美国 States of America "lightskyblue", "lightskyblue", "lightskyblue",# 源节点:1 - 中华人民共和国China "bisque", "bisque", "bisque"],)# 源节点:2 - 日本 data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.show()

これは非常に基本的なサンキー図です。しかし、グラフの幅が広すぎて、銀メダルが金メダルよりも前に表示されていることにお気づきでしょうか?
ノードの位置と幅を調整する方法は次のとおりです。
ノードの位置とチャートの幅を調整する
x および y の位置をノードに追加して、ノードの位置を明示的に指定します。値は 0 から 1 の間である必要があります。
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) x = [ 0,0,0,0.5,0.5,0.5], y = [ 0,0.5,1,0.1,0.5,1],) data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.update_layout(title="Olympics - 2021: Country &Medals",font_size=16) fig.show()
これで、コンパクトなサンキー図が完成しました。
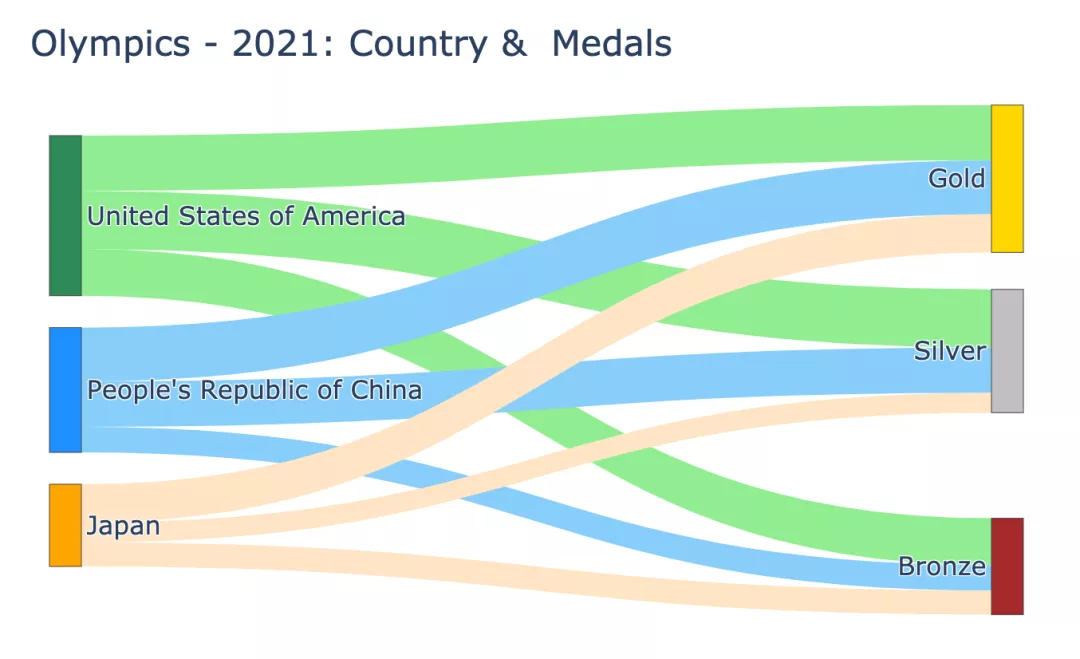
コードで渡されたさまざまなパラメーターがどのようにノードにマップされるかを見てみましょう。グラフ内。リンク。
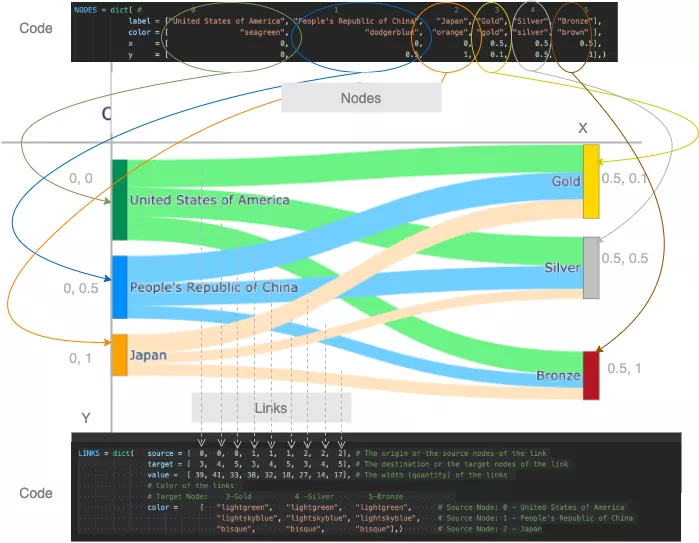
代码如何映射到桑基图
添加有意义的悬停标签
我们都知道plotly绘图是交互的,我们可以将鼠标悬停在节点和链接上以获取更多信息。
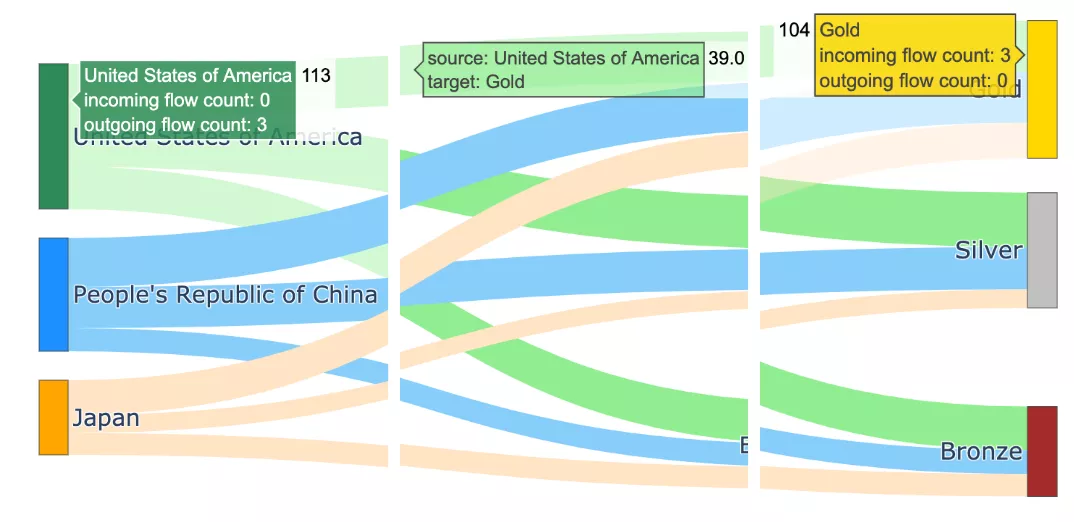
带有默认悬停标签的桑基图
当将鼠标悬停在图上,将会显示详细信息。悬停标签中显示的信息是默认文本:节点、节点名称、传入流数、传出流数和总值。
例如:
- 节点美国共获得11枚奖牌(=39金+41银+33铜)
- 节点金牌共有104枚奖牌(=美国39枚,中国38枚,日本27枚)
如果我们觉得这些标签太冗长了,我们可以对此进程改进。使用hovertemplate参数改进悬停标签的格式
- 对于节点,由于hoverlabels 没有提供新信息,通过传递一个空hovertemplate = ""来去掉hoverlabel
- 对于链接,可以使标签简洁,格式为-
- 对于节点和链接,让我们使用后缀"Medals"显示值。例如 113 枚奖牌而不是 113 枚。这可以通过使用具有适当valueformat和valuesuffix的update_traces函数来实现。
NODES = dict(
# 0 1 23 4 5
label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"],
color = ["seagreen", "dodgerblue","orange", "gold", "silver", "brown" ],
x = [ 0,0, 0,0.5,0.5,0.5],
y = [ 0,0.5, 1,0.1,0.5,1],
hovertemplate=" ",)
LINK_LABELS = []
for country in ["USA","China","Japan"]:
for medal in ["Gold","Silver","Bronze"]:
LINK_LABELS.append(f"{country}-{medal}")
LINKS = dict(source = [0,0,0,1,1,1,2,2,2],
# 链接的起点或源节点
target = [3,4,5,3,4,5,3,4,5],
# 链接的目的地或目标节点
value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17],
# 链接的宽度(数量)
# 链接的颜色
# 目标节点:3-Gold4 -Silver5-Bronze
color = ["lightgreen", "lightgreen", "lightgreen", # 源节点:0 - 美国
"lightskyblue", "lightskyblue", "lightskyblue", # 源节点:1 - 中国
"bisque", "bisque", "bisque"],# 源节点:2 - 日本
label = LINK_LABELS,
hovertemplate="%{label}",)
data = go.Sankey(node = NODES, link = LINKS)
fig = go.Figure(data)
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16, width=1200, height=500,)
fig.update_traces(valueformat='3d',
valuesuffix='Medals',
selector=dict(type='sankey'))
fig.update_layout(hoverlabel=dict(bgcolor="lightgray",
font_size=16,
font_family="Rockwell"))
fig.show("png") #fig.show()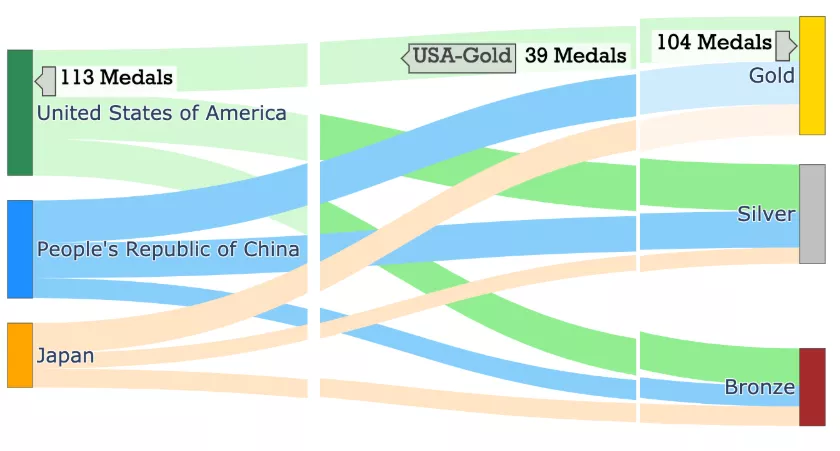
带有改进的悬停标签的桑基图
对多个节点和级别进行泛化相对于链接,节点被称为源和目标。作为一个链接目标的节点可以是另一个链接的源。
该代码可以推广到处理数据集中的所有国家。
还可以将图表扩展到另一个层次,以可视化各国的奖牌总数。
NUM_COUNTRIES = 5
X_POS, Y_POS = 0.5, 1/(NUM_COUNTRIES-1)
NODE_COLORS = ["seagreen", "dodgerblue", "orange", "palevioletred", "darkcyan"]
LINK_COLORS = ["lightgreen", "lightskyblue", "bisque", "pink", "lightcyan"]
source = []
node_x_pos, node_y_pos = [], []
node_labels, node_colors = [], NODE_COLORS[0:NUM_COUNTRIES]
link_labels, link_colors, link_values = [], [], []
# 第一组链接和节点
for i in range(NUM_COUNTRIES):
source.extend([i]*3)
node_x_pos.append(0.01)
node_y_pos.append(round(i*Y_POS+0.01,2))
country = df_medals['Country'][i]
node_labels.append(country)
for medal in ["Gold", "Silver", "Bronze"]:
link_labels.append(f"{country}-{medal}")
link_values.append(df_medals[f"{medal} Medals"][i])
link_colors.extend([LINK_COLORS[i]]*3)
source_last = max(source)+1
target = [ source_last, source_last+1, source_last+2] * NUM_COUNTRIES
target_last = max(target)+1
node_labels.extend(["Gold", "Silver", "Bronze"])
node_colors.extend(["gold", "silver", "brown"])
node_x_pos.extend([X_POS, X_POS, X_POS])
node_y_pos.extend([0.01, 0.5, 1])
# 最后一组链接和节点
source.extend([ source_last, source_last+1, source_last+2])
target.extend([target_last]*3)
node_labels.extend(["Total Medals"])
node_colors.extend(["grey"])
node_x_pos.extend([X_POS+0.25])
node_y_pos.extend([0.5])
for medal in ["Gold","Silver","Bronze"]:
link_labels.append(f"{medal}")
link_values.append(df_medals[f"{medal} Medals"][:i+1].sum())
link_colors.extend(["gold", "silver", "brown"])
print("node_labels", node_labels)
print("node_x_pos", node_x_pos); print("node_y_pos", node_y_pos)node_labels ['United States of America', "People's Republic of China", 'Japan', 'Great Britain', 'ROC', 'Gold', 'Silver', 'Bronze', 'Total Medals'] node_x_pos [0.01, 0.01, 0.01, 0.01, 0.01, 0.5, 0.5, 0.5, 0.75] node_y_pos [0.01, 0.26, 0.51, 0.76, 1.01, 0.01, 0.5, 1, 0.5]
# 显示的图
NODES = dict(pad= 20, thickness = 20,
line = dict(color = "lightslategrey",
width = 0.5),
hovertemplate=" ",
label = node_labels,
color = node_colors,
x = node_x_pos,
y = node_y_pos, )
LINKS = dict(source = source,
target = target,
value = link_values,
label = link_labels,
color = link_colors,
hovertemplate="%{label}",)
data = go.Sankey(arrangement='snap',
node = NODES,
link = LINKS)
fig = go.Figure(data)
fig.update_traces(valueformat='3d',
valuesuffix=' Medals',
selector=dict(type='sankey'))
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16,
width=1200,
height=500,)
fig.update_layout(hoverlabel=dict(bgcolor="grey",
font_size=14,
font_family="Rockwell"))
fig.show("png") 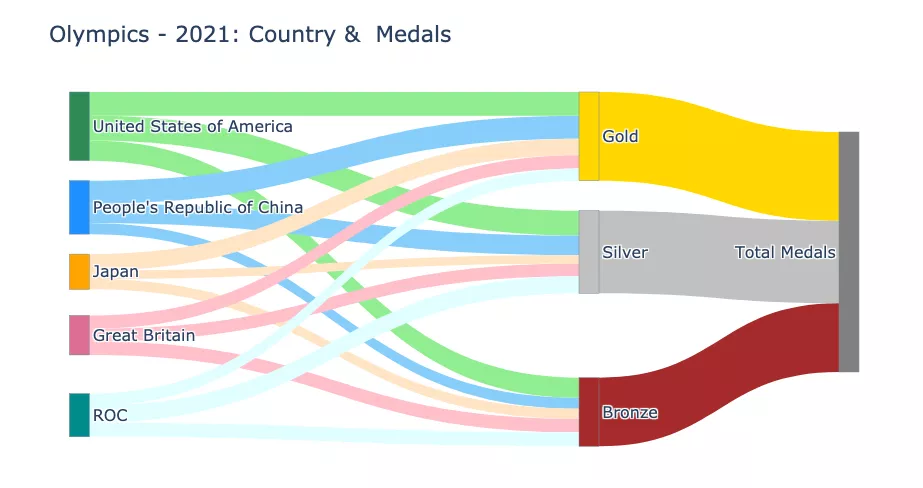
以上がPython は見事なサンキー図を描画します。学習しましたか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
 CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentOSシステムのPytorchデータを効率的に処理するには、次の手順が必要です。依存関係のインストール:システムを最初に更新し、Python3とPIPをインストールします。仮想環境構成(推奨):Condaを使用して、新しい仮想環境を作成およびアクティブにします。例:Condacreate-N
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
