

機械学習で学ぶ必要がある 4 つの相互検証テクニック

はじめに
データセット上にモデルを作成することを検討しますが、目に見えないデータでは失敗します。
モデルをトレーニング データに適合させて、それが実際の目に見えないデータで完全に実行されるのを待つだけでは済みません。
これは過学習の例であり、モデルがトレーニング データ内のすべてのパターンとノイズを抽出しています。これを防ぐには、モデルがパターンの大部分を捕捉し、データ内のノイズをすべて拾っていないことを確認する方法 (低バイアスと低分散) が必要です。この問題に対処するための多くの手法の 1 つが相互検証です。
相互検証について理解する
特定のデータ セットに 1000 件のレコードがあり、それに対して train_test_split() が実行されるとします。 70% のトレーニング データと 30% のテスト データがあり、random_state = 0 であると仮定すると、これらのパラメーターの精度は 85% になります。ここで、random_state = 50 に設定すると、精度が 87% に向上するとします。
これは、異なるrandom_stateに対して精度値を選択し続けると、変動が発生することを意味します。これを防ぐために、相互検証と呼ばれる手法が登場します。
相互検証の種類
1 つを除外する相互検証 (LOOCV)
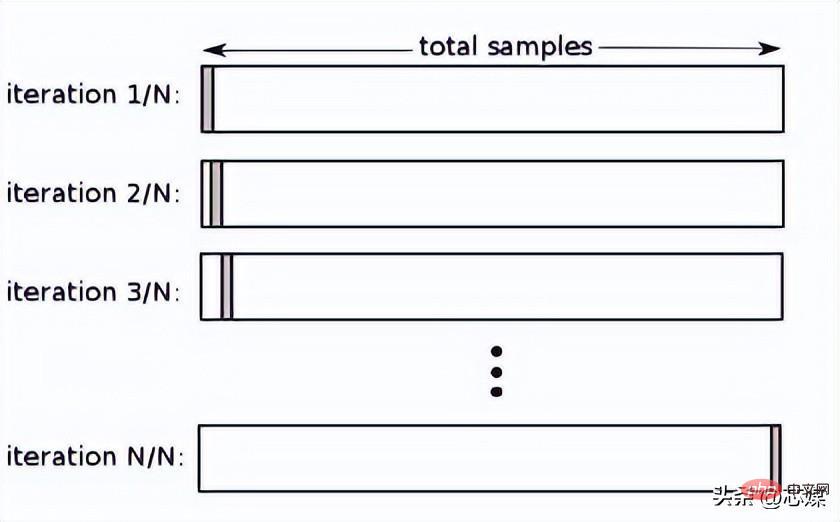
LOOCV では、1 を選択します。データ ポイントはテストとして使用され、残りのデータはすべて最初の反復からのトレーニング データになります。次の反復では、次のデータ ポイントをテストとして選択し、残りをトレーニング データとして選択します。これをデータセット全体に対して繰り返し、最後の反復で最後のデータ ポイントがテストとして選択されるようにします。
通常、反復相互検証手順の相互検証 R² を計算するには、各反復の R² スコアを計算し、その平均を取ります。
これにより、信頼性が高く偏りのないモデルのパフォーマンスの推定が可能になりますが、実行には計算コストがかかります。
2. K 分割相互検証

でK フォールド CV では、 データセットを k 個のサブセット (フォールドと呼ばれます) に分割し、すべてのサブセットでトレーニングしますが、モデルのトレーニング後の評価用に 1 つ (k-1) のサブセットを残します。
レコードが 1000 件あり、K=5 であると仮定します。この K 値は、反復が 5 回あることを意味します。テスト データとして考慮される最初の反復のデータ ポイントの数は、最初から 1000/5=200 です。次に、次の反復では、次の 200 データ ポイントがテストとみなされます。
全体の精度を計算するには、各反復の精度を計算し、平均を取ります。
このプロセスから得られる 最小精度は、すべての反復の中で生成される最も低い精度となり、同様に、最大精度 はすべての反復の中で生成されます。最高の精度。
#3.層別相互検証
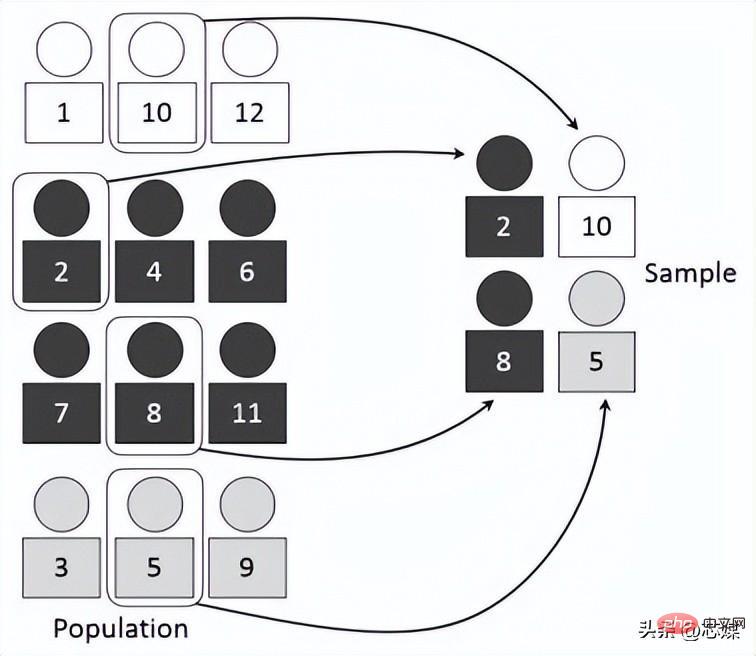
レコードが 1000 件あり、その中に 600 件の「はい」と 400 件の「いいえ」が含まれているとします。したがって、各実験では、トレーニングとテストに入力されるランダム サンプルが、各クラスの少なくとも一部のインスタンスがトレーニングとテストの分割の両方に存在するような方法で入力されることが保証されます。
4.
時系列相互検証
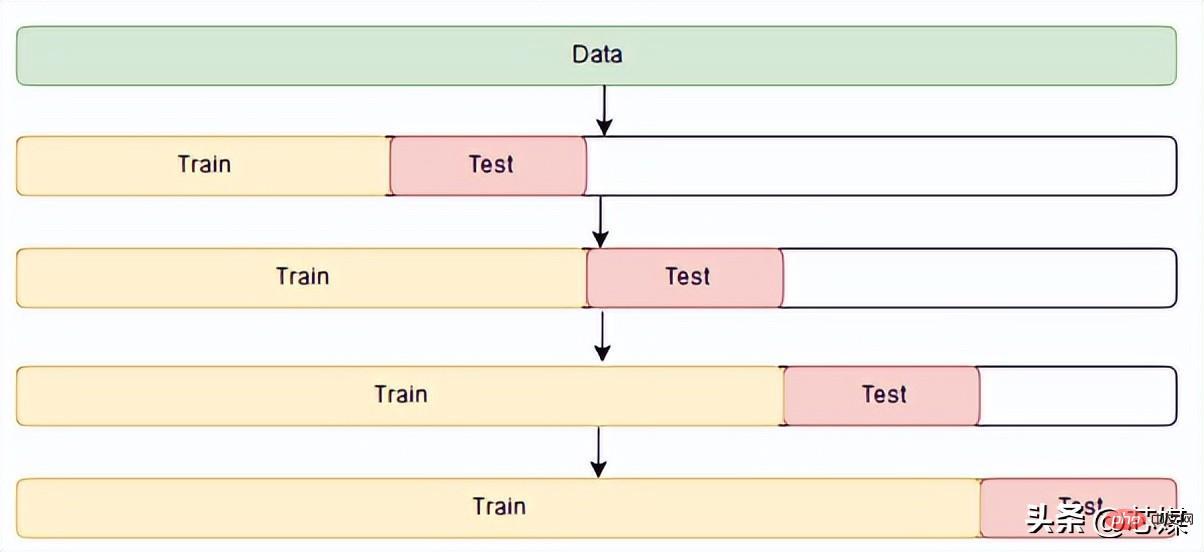
より前に発生した観測値のみが含まれています。 したがって、将来の観察を使用して予測を構築することはできません。
予測精度は、テスト セットを平均することによって計算されます。このプロセスは、予測の基礎となる「原点」が時間とともにロールフォワードされるため、「ローリング予測原点の評価」と呼ばれることもあります。機械学習では、通常、トレーニング セットで最高のパフォーマンスを発揮するアルゴリズムやモデルは必要ありません。代わりに、テスト セットで良好なパフォーマンスを発揮するモデル、および与えられた新しい入力データに対して一貫して良好なパフォーマンスを発揮するモデルが必要です。相互検証は、そのようなアルゴリズムやモデルを確実に特定できるようにするための重要なステップです。 結論
以上が機械学習で学ぶ必要がある 4 つの相互検証テクニックの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
