

データ サイエンスの生産性を向上させ、貴重な時間を節約できる 8 つの Python ライブラリ

データ サイエンスを行う場合、コーディングやコンピューターが何かを実行するのを待つことに多くの時間を無駄にすることがあります。そこで、貴重な時間を節約できる Python ライブラリをいくつか選びました。
1. Optuna
Optuna は、機械学習モデルに最適なハイパーパラメーターを自動的に見つけることができるオープンソースのハイパーパラメーター最適化フレームワークです。
最も基本的な (そしておそらくよく知られている) 代替手段は、sklearn の GridSearchCV です。これは、複数のハイパーパラメーターの組み合わせを試し、相互検証に基づいて最適なものを選択します。
GridSearchCV は、以前に定義されたスペース内での組み合わせを試みます。たとえば、ランダム フォレスト分類器の場合、いくつかの異なるツリーの最大深さをテストしたい場合があります。 GridSearchCV は、各ハイパーパラメータの可能なすべての値を提供し、すべての組み合わせを調べます。
Optuna は、定義された検索スペース内での独自の試行履歴を使用して、次に試行する値を決定します。使用する手法は「ツリー構造パルゼン推定器」と呼ばれるベイジアン最適化アルゴリズムです。
この異なるアプローチは、すべての値を無駄に試すのではなく、試す前に最適な候補を探し、絶望的な代替案の試行に費やされる時間を節約することを意味します (また、より良い結果が得られる可能性もあります)。
最後に、これはフレームワークに依存しないため、TensorFlow、Keras、PyTorch、またはその他の ML フレームワークで使用できます。
2. ITMO_FS
ITMO_FS は、ML モデルの特徴選択を実行できる特徴選択ライブラリです。観測値が少ないほど、過剰適合を避けるために特徴量が多すぎることに注意する必要があります。 「賢明」とは、モデルを標準化する必要があることを意味します。通常、より単純なモデル (機能が少ない) の方が理解しやすく、解釈しやすくなります。
ITMO_FS アルゴリズムは、教師ありフィルター、教師なしフィルター、ラッパー、ハイブリッド、組み込み、アンサンブルの 6 つの異なるカテゴリに分類されます (ただし、主に教師ありフィルターに焦点を当てています)。
「教師ありフィルター」アルゴリズムの簡単な例は、ターゲット変数との相関に基づいて特徴を選択することです。 「逆方向選択」を使用すると、特徴を 1 つずつ削除して、それらの特徴がモデルの予測能力にどのような影響を与えるかを確認できます。
ITMO_FS の使用方法とモデル スコアへの影響の簡単な例を次に示します。
>>> from sklearn.linear_model import SGDClassifier >>> from ITMO_FS.embedded import MOS >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2) >>> sel = MOS() >>> trX = sel.fit_transform(X, y, smote=False) >>> cl1 = SGDClassifier() >>> cl1.fit(X, y) >>> cl1.score(X, y) 0.9033333333333333 >>> cl2 = SGDClassifier() >>> cl2.fit(trX, y) >>> cl2.score(trX, y) 0.9433333333333334
ITMO_FS は比較的新しいライブラリなので、まだ少し不安定ですが、それでも使用することをお勧めします。それを試してみてください。
3. shap-hypetune
これまで、機能選択とハイパーパラメーター調整のためのライブラリを見てきましたが、両方を同時に使用しないのはなぜでしょうか?これが shap-hypetune の役割です。
「SHAP」とは何かを理解することから始めましょう:
「SHAP (SHApley Additive exPlanations) は、機械学習モデルの出力を説明するためのゲーム理論手法です。」
SHAP は、モデルを解釈するために最も広く使用されているライブラリの 1 つであり、モデルの最終予測に対する各特徴の重要性を生成することによって機能します。
一方、shap-hypertune は、最良の機能だけでなく、最良のハイパーパラメータも選択するこのアプローチの恩恵を受けます。それらを組み合わせたいのはなぜですか? 機能の選択とハイパーパラメーターの調整を個別に行うと、それらの間の相互作用を考慮しないため、最適とは言えない選択が生じる可能性があります。両方を同時に実行すると、これが考慮されるだけでなく、コーディング時間もいくらか節約されます (ただし、検索スペースが増えるため、実行時間が長くなる可能性があります)。
検索は、グリッド検索、ランダム検索、ベイジアン検索の 3 つの方法で実行できます (さらに、並列化も可能)。
ただし、shap-hypertune は勾配ブースティング モデルでのみ機能します!
4. PyCaret
PyCaret は、機械学習を自動的に実行できるオープンソースのローコード機械学習ライブラリです。ワークフローの学習。探索的データ分析、前処理、モデリング (解釈可能性を含む)、および MLOps について説明します。
Web サイトで実際の例をいくつか見て、どのように機能するかを見てみましょう:
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
best = compare_models()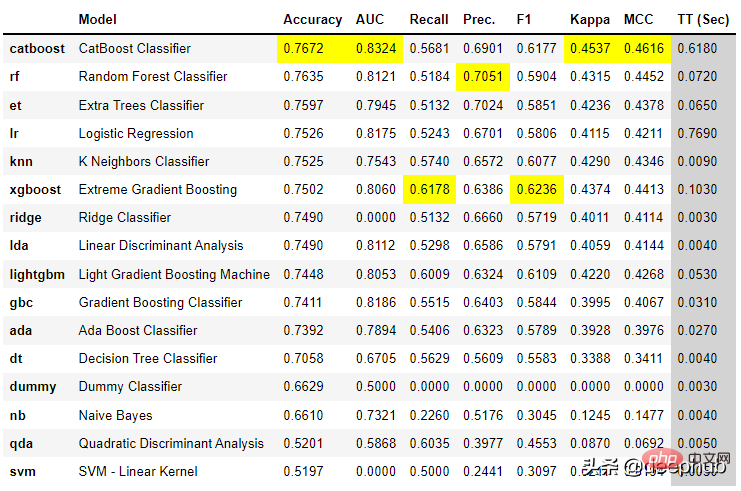
わずか数行のコードで、複数のモデルが試行され、主要な分類メトリック間で比較されました。
また、モデルと対話する基本的なアプリケーションを作成することもできます:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_app(lr)最後に、モデル用の API および Docker ファイルを簡単に作成できます:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api')Nothing簡単ですよね?
PyCaret は非常に完全なライブラリであり、ここですべてを説明するのは難しいため、今すぐダウンロードして使い始めて、実際の機能の一部を理解することをお勧めします。
5. floWeaver
FloWeaver は、ストリーミング データ セットからサンキー図を生成できます。サンキー ダイアグラムが何なのかわからない場合は、次の例を参照してください:
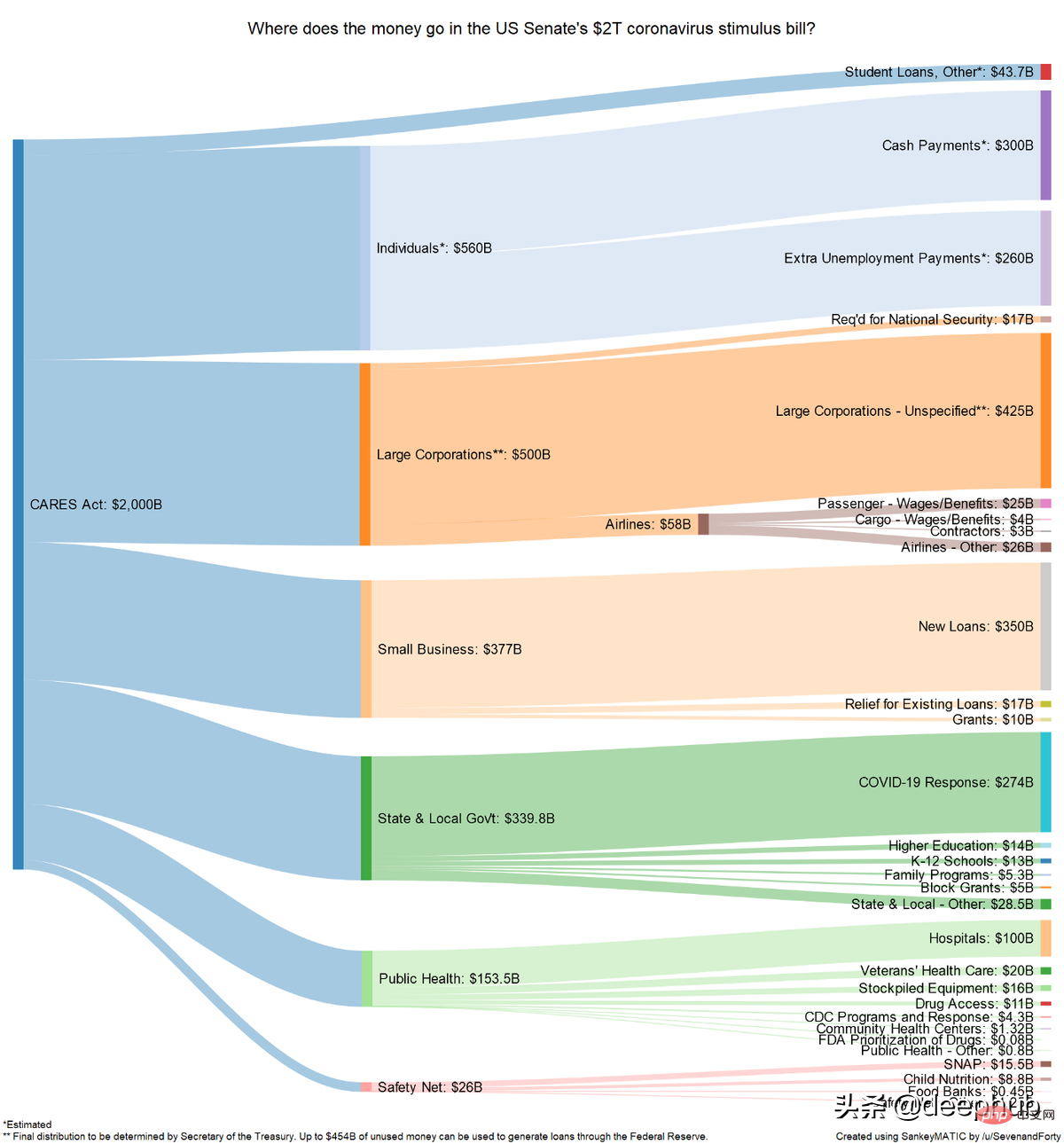
サンキー ダイアグラムは、コンバージョン ファネル、マーケティング ジャーニー、または予算配分のデータを表示するときに非常に役立ちます (例)その上 )。ポータル データは次の形式である必要があります: 「ソース x ターゲット x 値」 このようなプロット (非常に具体的ですが、非常に直観的) を作成するのに必要なコードは 1 行だけです。
6、Gradio
如果你阅读过敏捷数据科学,就会知道拥有一个让最终用户从项目开始就与数据进行交互的前端界面是多么有帮助。一般情况下在Python中最常用是 Flask,但它对初学者不太友好,它需要多个文件和一些 html、css 等知识。
Gradio 允许您通过设置输入类型(文本、复选框等)、功能和输出来创建简单的界面。 尽管它似乎不如 Flask 可定制,但它更直观。
由于 Gradio 现在已经加入 Huggingface,可以在互联网上永久托管 Gradio 模型,而且是免费的!
7、Terality
理解 Terality 的最佳方式是将其视为“Pandas ,但速度更快”。这并不意味着完全替换 pandas 并且必须重新学习如何使用df:Terality 与 Pandas 具有完全相同的语法。实际上,他们甚至建议“import Terality as pd”,并继续按照以前的习惯的方式进行编码。
它快多少?他们的网站有时会说它快 30 倍,有时快 10 到 100 倍。
另一个重要是 Terality 允许并行化并且它不在本地运行,这意味着您的 8GB RAM 笔记本电脑将不会再出现 MemoryErrors!
但它在背后是如何运作的呢?理解 Terality 的一个很好的比喻是可以认为他们在本地使用的 Pandas 兼容的语法并编译成 Spark 的计算操作,使用Spark进行后端的计算。所以计算不是在本地运行,而是将计算任务提交到了他们的平台上。
那有什么问题呢?每月最多只能免费处理 1TB 的数据。如果需要更多则必须每月至少支付 49 美元。 1TB/月对于测试工具和个人项目可能绰绰有余,但如果你需要它来实际公司使用,肯定是要付费的。
8、torch-handle
如果你是Pytorch的使用者,可以试试这个库。
torchhandle是一个PyTorch的辅助框架。 它将PyTorch繁琐和重复的训练代码抽象出来,使得数据科学家们能够将精力放在数据处理、创建模型和参数优化,而不是编写重复的训练循环代码。 使用torchhandle,可以让你的代码更加简洁易读,让你的开发任务更加高效。
torchhandle将Pytorch的训练和推理过程进行了抽象整理和提取,只要使用几行代码就可以实现PyTorch的深度学习管道。并可以生成完整训练报告,还可以集成tensorboard进行可视化。
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseContext
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseContext(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
context_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)定义一个模型,设置数据集,配置优化器、损失函数就可以自动训练了,是不是和TF差不多了。
以上がデータ サイエンスの生産性を向上させ、貴重な時間を節約できる 8 つの Python ライブラリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:軽量で高レベルのスケーラブルなPythonデータベースHadIDB(HadIDB)は、Pythonで記述された軽量データベースで、スケーラビリティが高くなっています。 PIPインストールを使用してHADIDBをインストールする:PIPINSTALLHADIDBユーザー管理CREATEユーザー:CREATEUSER()メソッド新しいユーザーを作成します。 Authentication()メソッドは、ユーザーのIDを認証します。 fromhadidb.operationimportuseruser_obj = user( "admin"、 "admin")user_obj。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
MySQLは、基本的なデータストレージと管理のためにネットワーク接続なしで実行できます。ただし、他のシステムとのやり取り、リモートアクセス、または複製やクラスタリングなどの高度な機能を使用するには、ネットワーク接続が必要です。さらに、セキュリティ対策(ファイアウォールなど)、パフォーマンスの最適化(適切なネットワーク接続を選択)、およびデータバックアップは、インターネットに接続するために重要です。
 MySQLワークベンチはMariadBに接続できますか
Apr 08, 2025 pm 02:33 PM
MySQLワークベンチはMariadBに接続できますか
Apr 08, 2025 pm 02:33 PM
MySQLワークベンチは、構成が正しい場合、MariadBに接続できます。最初にコネクタタイプとして「mariadb」を選択します。接続構成では、ホスト、ポート、ユーザー、パスワード、およびデータベースを正しく設定します。接続をテストするときは、ユーザー名とパスワードが正しいかどうか、ポート番号が正しいかどうか、ファイアウォールが接続を許可するかどうか、データベースが存在するかどうか、MariadBサービスが開始されていることを確認してください。高度な使用法では、接続プーリングテクノロジーを使用してパフォーマンスを最適化します。一般的なエラーには、不十分な権限、ネットワーク接続の問題などが含まれます。エラーをデバッグするときは、エラー情報を慎重に分析し、デバッグツールを使用します。ネットワーク構成を最適化すると、パフォーマンスが向上する可能性があります
 MySQLにはサーバーが必要ですか
Apr 08, 2025 pm 02:12 PM
MySQLにはサーバーが必要ですか
Apr 08, 2025 pm 02:12 PM
生産環境の場合、パフォーマンス、信頼性、セキュリティ、スケーラビリティなどの理由により、通常、MySQLを実行するためにサーバーが必要です。サーバーには通常、より強力なハードウェア、冗長構成、より厳しいセキュリティ対策があります。小規模で低負荷のアプリケーションの場合、MySQLはローカルマシンで実行できますが、リソースの消費、セキュリティリスク、メンテナンスコストを慎重に考慮する必要があります。信頼性とセキュリティを高めるには、MySQLをクラウドまたは他のサーバーに展開する必要があります。適切なサーバー構成を選択するには、アプリケーションの負荷とデータボリュームに基づいて評価が必要です。
