

音声認識は、コンピューターが人間の音声を理解してテキストに変換できるようにする人工知能の分野です。この技術はAlexaなどのデバイスやさまざまなチャットボットアプリケーションで使用されています。私たちが行う最も一般的なことは音声文字起こしであり、文字起こしや字幕に変換できます。

#wav2vec2、Conformer、Hubert などの最先端モデルの最近の開発により、音声認識の分野は大幅に進歩しました。これらのモデルは、データに手動でラベルを付けることなく生の音声から学習する技術を採用しており、ラベルのない音声の大規模なデータセットを効率的に使用できます。また、学習データを最大 1,000,000 時間まで使用できるように拡張されており、学術的な教師ありデータセットで使用される従来の 1,000 時間を大幅に超えていますが、複数のデータセットおよびドメインにわたって教師あり方法で事前学習されたモデルは、保持される堅牢性と一般化がより優れていることがわかっています。データセットであるため、音声認識などのタスクを実行するには依然として微調整が必要であり、その可能性を最大限に発揮できません。この問題を解決するために、OpenAI は弱い監視方法を利用するモデル Whisper を開発しました。
この記事では、学習に使用するデータセットの種類、モデルの学習方法、Whisperの使い方について説明します
Whisper モデルは、96 の異なる言語での 117,000 時間の音声と、「任意の言語」から英語への 125,000 時間の翻訳データを含む、680,000 時間のラベル付き音声データのデータセットでトレーニングされました。このモデルは、人間が作成したものではなく、他の自動音声認識システム (ASR) によって生成されたインターネット生成テキストを利用します。このデータセットには、YouTube 動画から抽出され、動画のタイトルと説明の言語に基づいてタグ付けされた短い音声クリップのコレクションである VoxLingua107 でトレーニングされた言語検出器と、誤検知を除去するための追加手順も含まれています。
使用される主な構造は、エンコーダ-デコーダ構造です。
リサンプリング: 16000 Hz
特徴抽出方法: 25 ms ウィンドウと 10 ms ステップを使用して、80 チャネルのログ メル スペクトログラム表現を計算します。
特徴の正規化: 入力は -1 から 1 の間でグローバルにスケーリングされ、事前トレーニングされたデータセットの平均はほぼゼロになります。
エンコーダー/デコーダー: このモデルのエンコーダーとデコーダーはトランスフォーマーを使用します。
エンコーダはまず、GELU アクティベーション関数を使用して、2 つの畳み込み層 (フィルター幅 3) を含むステムを使用して入力表現を処理します。
2 番目の畳み込み層のストライドは 2 です。
次に、正弦波位置埋め込みがステムの出力に追加され、エンコーダーの Transformer ブロックが適用されます。
トランスフォーマーは事前にアクティブ化された残差ブロックを使用し、エンコーダーの出力は正規化レイヤーを使用して正規化されます。

デコーダでは、位置の埋め込み学習と入出力マーカーのバインディングが高速に使用されます。 。
エンコーダーとデコーダーの Transformers ブロックの幅と数は同じです。
モデルのスケーリング特性を改善するために、モデルはさまざまな入力サイズでトレーニングされます。
FP16、動的損失スケーリング、およびデータ並列処理を通じてモデルをトレーニングします。
AdamW と勾配ノルム クリッピングを使用すると、最初の 2048 アップデートをウォームアップした後、線形学習率はゼロに減衰します。
バッチ サイズ 256 を使用し、220 回の更新に対してモデルをトレーニングします。これは、データセットの 2 ~ 3 回の前方パスに相当します。
モデルはほんの数エポックに対してトレーニングされたため、過剰適合は重大な問題ではなく、データ拡張や正則化手法は使用されませんでした。これは、一般化と堅牢性を促進するために、大規模なデータセット内の多様性に依存しています。
Whisper は、以前に使用されたデータセットで優れた精度を実証しており、他の最先端のモデルに対してテストされています。
さまざまなデータセットでの Whisper の比較結果。wav2vec と比較して、これまでで最も低い単語誤り率を達成しました。

モデルは timit データセットではテストされていないため、単語誤り率をチェックするために、ここでは Whisper を使用して timit データセットを自己検証する方法、つまり Whisper を使用して独自の音声認識を構築する方法を示します。応用 。
TIMIT リーディング音声コーパスは、音響音声研究および自動音声認識システムの開発と評価に特に使用される音声データのコレクションです。これには、アメリカ英語の 8 つの主要な方言の 630 人の話者の録音が含まれており、それぞれが音声的に豊かな 10 文を朗読しています。コーパスには、時間的に調整された正書法、表音文字、および単語の転写と、各音声の 16 ビット、16 kHz の音声波形ファイルが含まれています。このコーパスは、マサチューセッツ工科大学 (MIT)、SRI インターナショナル (SRI)、およびテキサス インスツルメンツ (TI) によって開発されました。 TIMIT コーパスの転写は、音声と方言の範囲のバランスをとるために指定されたテストとトレーニングのサブセットを使用して手動で検証されています。
インストール:
!pip install git+https://github.com/openai/whisper.git !pip install jiwer !pip install datasets==1.18.3
最初のコマンドは、ウィスパー モデルに必要なすべての依存関係をインストールします。 jiwer は、テキスト誤り率パッケージのダウンロードに使用されます。データセットは、hugface によって提供されます。timit データセットをダウンロードできます。
インポート ライブラリ
import whisper from pytube import YouTube from glob import glob import os import pandas as pd from tqdm.notebook import tqdm
読み込み制限データ セット
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")英語データと英語以外のデータのフィルタリングを検討するニーズを満たすために、ここでは英語専用に設計されたモデルの代わりに多言語モデルを使用することを選択します。
しかし、TIMIT データセットは純粋な英語であるため、同じ言語検出および認識プロセスを適用する必要があります。さらに、TIMIT データセットはトレーニング セットと検証セットに分割されており、直接使用できます。
Whisper を使用するには、まずさまざまなモデルのパラメーター、サイズ、速度を理解する必要があります。

Load model
model = whisper.load_model('tiny')tiny は上記のモデル名に置き換えることができます。
言語検出器を定義する関数
def lan_detector(audio_file):
print('reading the audio file')
audio = whisper.load_audio(audio_file)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
if max(probs, key=probs.get) == 'en':
return True
return False音声をテキストに変換する関数
def speech2text(audio_file): text = model.transcribe(audio_file) return text["text"]
さまざまなモデル サイズで上記の関数を実行し、トレーニングとテストによって得られた単語エラーを制限します。速度は次のとおりです。
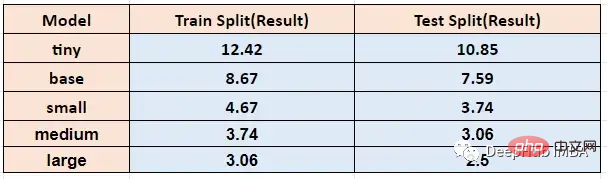
他の音声認識モデルと比較して、Whisper は音声を認識するだけでなく、音声の内容を解釈することもできます。人の音声の句読点のイントネーションを検出し、適切な句読点を挿入します。以下のテストには u2b のビデオを使用します。
ここでは、オーディオを簡単にダウンロードして抽出できる pytube パッケージが必要です。
def youtube_audio(link):
youtube_1 = YouTube(link)
videos = youtube_1.streams.filter(only_audio=True)
name = str(link.split('=')[-1])
out_file = videos[0].download(name)
link = name.split('=')[-1]
new_filename = link+".wav"
print(new_filename)
os.rename(out_file, new_filename)
print(name)
return new_filename,linkwav ファイルを取得したら、上記の関数を適用してそこからテキストを抽出できます。
この記事のコードはこちらです
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view
こちらこの操作は Whisper で完了でき、この記事のコードに基づいて自分で試すことができます。
以上がOpenAI の Whisper モデルを使用した音声認識の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



