


Google Ngram ビューアは、書籍からスキャンされた Google の膨大なデータの宝庫を使用して、時間の経過に伴う単語の使用量の変化をプロットする、楽しくて便利なツールです。たとえば、「Python」という単語 (大文字と小文字が区別されます):
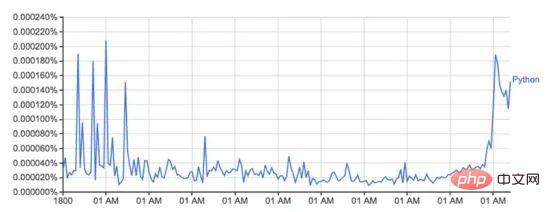
books.google.com/ngrams のこの画像は、「Python」という単語の使用法を示しています。時間の経過とともに変化します。
これは、Google の n-gram データセットによって駆動されており、書籍が印刷された年ごとに Google ブックスでの特定の単語または語句の使用状況が記録されます。これは完全ではありませんが (これまでに出版されたすべての書籍が含まれているわけではありません!)、データセットには 16 世紀から 2008 年までの数百万冊の書籍が含まれています。データセットはここから無料でダウンロードできます。
私は、Python と新しいデータ読み込みライブラリ PyTubes を使用して、上記のプロットを再生成するのがいかに簡単かを確認することにしました。
1 グラムのデータセットは、ハードディスク上で 27 GB のデータまで拡張できます。これは、Python に読み込むと大量のデータになります。 Python は一度に数ギガバイトのデータを簡単に処理できますが、データが破損して処理されると速度が低下し、メモリ効率が低下します。
合計で、これらの 14 億個のデータ (1,430,727,243) は 38 のソース ファイルに分散されており、合計 2,400 万 (24,359,460) 語 (および品詞タグ、以下を参照) が含まれます。 1505年から2008年。
10 億行のデータを処理すると、速度が急速に低下します。また、ネイティブ Python は、データのこの側面を処理するように最適化されていません。幸いなことに、numpy は大量のデータの処理に非常に優れています。いくつかの簡単なトリックを使用すると、numpy を使用してこの分析を実行できるようになります。
Python/numpy での文字列の処理は複雑です。 Python の文字列のメモリ オーバーヘッドは大きく、numpy は既知の固定長の文字列のみを処理できます。この状況により、ほとんどの単語の長さが異なるため、これは理想的ではありません。
以下のすべてのコード/例は、8 GB の RAM を搭載した 2016 Macbook Pro で実行されています。ハードウェアまたはクラウド インスタンスの RAM 構成が優れている場合、パフォーマンスは向上します。
1 グラムのデータは、次のようにタブキー区切りの形式でファイルに保存されます。 
各データには次の内容が含まれます。フィールド : 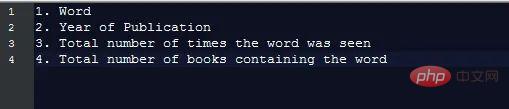
#必要に応じてグラフを生成するには、次の情報のみが必要です。
これらの情報を抽出することにより、異なる長さの文字列データを処理するための追加コストは無視されますが、それでも、関心のあるフィールドがデータのどの行に含まれているかを区別するために、異なる文字列の値を比較する必要があります。これが pytubes でできることです: 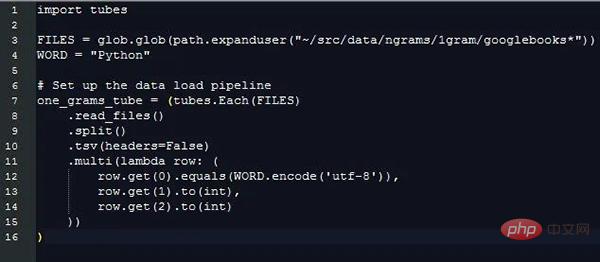
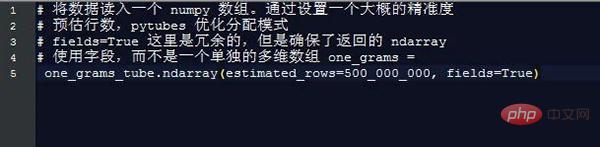
ほぼ 170 秒 (3 分) 後、one_grams は約 14 億行を含む numpy 配列になります。データは次のようになります (説明のためにテーブル ヘッダーを追加):
╒═══════════╤════════╤════ │ ═ ══ ════╡
│ 0 │ 1799 │ 2 │
----------------------------┼─────┼── ──────┤
│ 0 │ 1804 │ 1 │
§───────┼─────┼ ─ ─ ─ ┤
│ 0 │ 1805 │ 1 │
# ───────┼─── ─┼ ────┤
│ 0 │ 1811 │ 1 │
§─────┼──── ── ┼───┤
│ 0 │ 1820 │ ... │
╘═══════════╧═══ ══ ═══╧═════════╛
ここからは、numpy メソッドを使用して何かを計算するだけです:
年間の総単語使用量
Google は各単語の出現率 (単語の出現回数) を表示します。これは、元の単語を単に数えるよりも便利です。このパーセンテージを計算するには、単語の総数を知る必要があります。
幸いなことに、numpy を使用するとこれが非常に簡単になります:
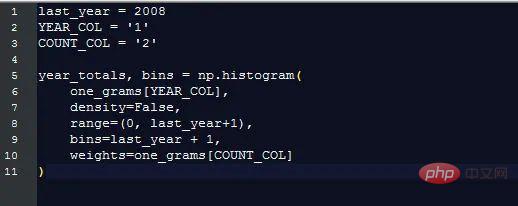
このグラフをプロットして、Google が毎年収集する単語の数を示します:
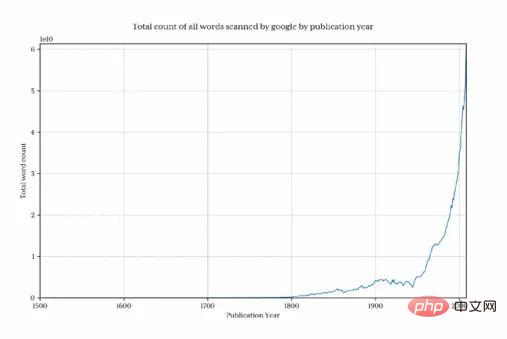
1800 年より前にデータ量が急速に減少したため、最終結果が歪められ、目的のパターンが隠蔽されていることは明らかです。この問題を回避するために、1800 年以降のデータのみをインポートします。
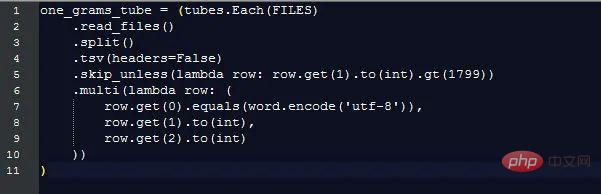
これにより、13 億行のデータが返されます (1800 年以前はわずか 3.7%)
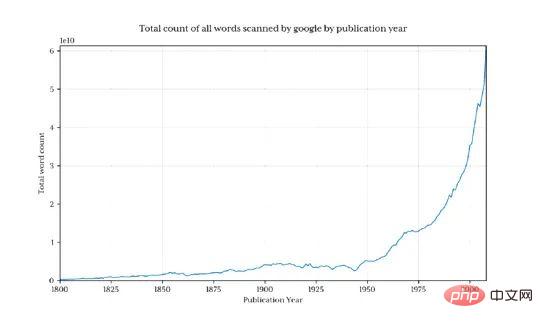
Python の年間パーセンテージ シェアの取得が特に簡単になりました。
簡単なトリックを使用して、年に基づいて配列を作成します。2008 年の要素の長さは、各年のインデックスが年の番号に等しいことを意味します。したがって、たとえば、1995 は単に次の問題です。 1995 年の要素を取得します。
これは、numpy を使用して実行する価値はありません:

word_counts の結果をプロットします:

形は Google のバージョンと似ています
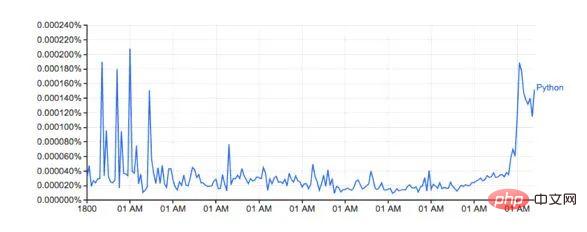
実際のパーセンテージは一致しません。ダウンロードしたデータセットに異なる単語が含まれているためだと思います。(例: Python_VERB) 。このデータセットは Google ページではあまり詳しく説明されておらず、次のようないくつかの疑問が生じます。Python を動詞として使用するにはどうすればよいですか?
「Python」の総計算量には「Python_VERB」も含まれますか? etc
幸いなことに、私が使用した方法では Google に非常によく似たアイコンが生成され、関連する傾向には影響がないことは誰もが知っているため、この調査ではそれを修正するつもりはありません。
パフォーマンス
たとえば、前年度の合計単語使用量を事前に計算し、それを別の検索テーブルに保存すると、時間を大幅に節約できます。同様に、単語の使用状況を別のデータベース/ファイルに保存し、最初の列にインデックスを付けると、処理時間のほぼすべてが削減されます。
この調査は、標準の汎用ハードウェアと Python で numpy と生まれたばかりの pytubes を使用すると、妥当な時間内に 10 億行のデータから任意の統計をロード、処理、抽出できることを示しています。
言語戦争
大文字の名前形式のみが一致します (Python ではなく Python)
各言語の言及の総数は 1800 から 1960 年のパーセンテージ平均に変換されており、Pascal を考慮した妥当なベースラインが得られます。 1970年に初めて言及されました。
結果:
Google との比較 (ベースライン調整なし):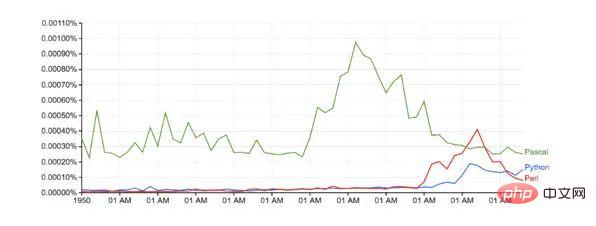
実行時間: 10 分強
現段階では、pytubes には 1 つの整数の概念しかありません。 64ビット。これは、pytubes によって生成された numpy 配列がすべての整数に対して i8 dtype を使用することを意味します。一部の場所 (ngram データなど) では、8 ビット整数は少し過剰でメモリを無駄にします (ndarray の合計は 38 GB ですが、dtypes を使用すると簡単に 60% 削減できます)。レベル 1、2、4 ビット整数のサポートを追加する予定です (github.com/stestagg/py…)
その他のフィルタリング ロジック - Tube.skip_unless() は比較的単純なフィルタ ライン メソッドですが、条件 (AND/OR/NOT) を組み合わせる機能。これにより、一部のユースケースでは、ロードされるデータのサイズをより速く削減できます。
文字列マッチングの改善 -startswith、endswith、contains、is_one_of などの単純なテストを簡単に追加して、文字列データのロード効率を大幅に向上させることができます。
以上がPython を使用して 14 億個のデータを分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



