

トップ国際出版物 PNAS に掲載されました!理論的なコンピューターから出発して、科学者たちは意識モデル「意識的チューリングマシン」を提案しました。


#トップ国際ジャーナル「米国科学アカデミー紀要」(PNAS)は、5 月下旬、昨年 10 月に査読された論文を発表しました。非常に堅実: チューリングの計算モデル Turing Machine (TM) と意識的グローバル ワークスペース理論 (GWT) の影響を受け、著者らは計算量理論と機械学習の知識を組み合わせた、理論コンピューターの観点からの形式を提案しました。 Conscious Turing Machine」(CTM)は、「意識」をさらに理解するのに役立ちます。

論文リンク: https://www.pnas.org/doi/epdf/10.1073/pnas.2115934119 たとえば、著者チームは、計算に時間がかかるという点について言及しました。 。この観点から、理論的なコンピューターの観点は、「自由意志」の定義を変える可能性があります。つまり、自由意志とは、さまざまな行動方針の結果を計算する自由、または利用可能なリソース (時間、空間、計算能力、情報) これらの結果をできるだけ多く計算し、目標に最も適した行動方針を選択してください。
著者の見解は、意識は、血肉でできているか、金属とシリコンでできているかに関係なく、合理的に組織されたすべてのコンピューティング システムの特性であるということです。この観点から、CTM は脳をモデル化するものではなく、意識の神経相関を示唆するものでもありませんが、意識とそれに関連する現象を理解しようとする意識の単純かつ抽象的な計算モデルです。この論文は非常に長く、AI Technology Review では要点を次のようにまとめています。 理論的コンピュータの観点から「意識」を見る
1 理論的コンピュータの観点から「意識」を見る
1.1. 理論コンピュータサイエンス
アラン チューリングの独創的な論文「Entscheidungsproblem への応用を伴う計算可能な数について」は、理論コンピュータの起源であると言えます。この論文は、現在チューリング マシン (TM) として知られている「コンピューティング マシン」の数学的定義を示しました。チューリングの定義では、このコンピューティング マシンは、コンピューターまたはスーパーコンピューターが計算できるあらゆる関数を計算できます。定理は数学理論の存在意義であり、チューリングは理論コンピューターの第一定理として知られる停止問題の解けないことを証明しました。
現代の言葉で言えば、この定理は、どのコンピュータ プログラムが停止するか停止しないかを判断できる汎用 (デバッグ) プログラムは不可能であり、そのようなプログラムを構築することも不可能であることを証明しています。停止問題の解けないことは、初等整数論の決定不可能性と同等であり、ゲーデルの第一不完全性定理の弱い形式を意味します。ゲーデルとチューリングの後、数理論理学者はどの問題が解けるのか、どの問題が解けないのかを分類し始め、解けない問題の深いレベルを研究し始めました。
1960 年代にコンピューティング マシンが出現し、広く利用できるようになると、原理的には解決できる多くの重要な問題が実際には解決できず、たとえ最速のコンピュータを使っても解決できないことがすぐにわかりました。技術的な問題ではなく、より深い問題です。理論的コンピューティングの新興分野の研究者 (特にジャック・エドモンズ、スティーブン・クック、リチャード・カープ、レオニード・レビン) は、自然に有限な (したがって解決可能な) 問題の中に、ある種の解決可能な問題と解決不可能な問題があるように見えることに気づきました。これは、解決可能と解決不可能の間の以前の二分法を反映しています。実行可能な解決策がある問題は、何らかのコンピューター プログラムによって多項式時間 P で解決できるものとして数学的に形式化できます。
さらに、多項式時間で解ける問題と多項式時間 NP で検査できる問題の実現は等価ではない可能性があります。実際、等価性が決定できれば、有名な 100 万ドルの P=?NP 問題に答えることができます。 Theoretical Computers は、シリアル高速 (マルチタイム) 計算複雑性クラスの階層を定義することに加えて、並列超高速 (マルチタイム) 計算複雑性クラスの階層も定義します。どちらの階層も、モデルで使用される定義と選択を提供します。簡単と困難、速いと遅いという二項対立の理解とその意味は、豊富な理論、思考の再構築、斬新な概念、驚くべき応用を伴う複雑さの革命を引き起こしました。実際、過去 40 年間にわたる計算の複雑さの発展は、一見不可能に見える問題に取り組むためにその難しさをどのように利用できるかを示してきました。ここではコンピュータが生成したランダムなシーケンスを使用して説明しますが、このシーケンスは「擬似ランダムシーケンス」と呼ばれます。
一見すると、擬似乱数シーケンスの概念は非常に不快なので、フォン ノイマンは「乱数を生成するための算術的手法を考える人は間違いなく有罪です。」と冗談を言ったほどです。 (多項式時間) 実現可能なコンピュータ プログラム (公平なコインを独立して投げることによって生成されるものなど) によって生成されるシーケンスと区別できない、真にランダムなシーケンスを生成するためのコンピュータ プログラム。したがって、人間が住む多項式時間の世界では、擬似乱数列は実際には真にランダムです。この理解は、理論コンピューターにおける多項式と超多項式の複雑さの違いを説明しなければ不可能でした。上記のアイデアの 1 つの応用は、確率的 CTM のランダム シーケンスを、(短い) ランダム シードを提供する擬似ランダム ジェネレーターによって生成されたシーケンスに置き換えることです。特に、確率論的 CTM に「自由意志」があるとすれば、決定論的 CTM にも「自由意志」があります。この決定論的な CTM の自由意志は、一部の (おそらくほとんどの) 決定論的な考え方に反しています。
1.2. さて、意識について話しましょう
CTM の定義は理論的コンピューターの観点を採用しています。 CTM は、意識 GWT を数学的に形成 (およびダイナミクスを介して変更) する単純なマシンです。意識 GWT の概念は、認知神経科学者 Bernard Baars によって生まれ、Dehaene と Mashour らの Global Neural Network で導入されました。 (GNWT)。 『Theatre of Consciousness』において、バールズは意識を作業記憶の舞台で演じる演劇俳優に例えており、彼らの演技は暗闇の中に座っている観客(あるいは無意識の処理者)の観察の下で行われる。 CTM では、GWT の段階は、いつでも CTM の意識内容を含む短期記憶 (STM) によって表されます。
視聴者は、それぞれ独自の専門知識を持つ強力なプロセッサによって代表され、これらのプロセッサは CTM の長期メモリ (LTM) を構成します。これらの LTM プロセッサは予測を行い、CTM の世界からフィードバックを受け取ります。各プロセッサー内の学習アルゴリズムにより、このフィードバックに基づいてプロセッサーの動作が改善されます。各 LTM プロセッサには独自の専門分野があり、ステージ上で質問、回答、情報をチャンクに分割して取得し、そのコンテンツを聴衆に即座に配信するために互いに競い合います。
意識的認識 (注意とも呼ばれることもあります) は、LTM プロセッサによる CTM 意識的コンテンツ ブロードキャストの受信として CTM で正式に定義されます。時間の経過とともに、一部のプロセッサはリンクを介して接続され、これらの LTM プロセッサは、STM を介した意識的な通信から、リンクを介した無意識の通信に変化します。リンクを介してブロックを伝播すると、ブロックの意識を強化できます。これは、Dehaene と Changeux によって「点火」と呼ばれるプロセスです。 Baars の GWT アーキテクチャからインスピレーションを得た CTM には、意識を高めるために重要な追加機能も統合されています。これらには、そのダイナミクス、豊富なマルチモーダル内部言語 (Brainish と呼ばれます)、および CTM が世界のモデルを作成できるようにする特別な LTM プロセッサが含まれます。
1.3. 複雑さの考慮事項
限られたリソースの結果は、変化盲目や自由意志などの意識関連現象の高レベルの説明において重要な役割を果たします。これらの結果により、CTM の詳細な定義も変更されます。詳細は次のとおりです。
ブロックの正式な定義: ブロックとは、各 LTM プロセッサが刻々と意識を競い合う情報です。
到達する競合ブロックの 1 つを選択します。意識 高速の確率的競争アルゴリズム;
グローバル ブロードキャスト、他のプロセッサ、および外界からのフィードバックを使用してプロセッサの競争力と信頼性を向上させる、各プロセッサの機械学習アルゴリズム。
CTM はチューリングのコンピューター モデルからインスピレーションを受けていますが、標準のチューリング マシンではありません。これは、CTM に「意識の感覚」を与えるのは、その計算能力や入出力マッピングではなく、グローバル ワークスペース アーキテクチャ、予測ダイナミクス (予測、フィードバック、学習のループ)、豊富なマルチモーダル内部言語であるためです。 、およびワールド モデル プロセッサなどの一部の特殊な LTM プロセッサ。前に述べたように、私たちが探しているのは脳のモデルではなく、意識の単純なモデルです。
2 CTM モデルの概要2.1 CTM の基本構造と CTM における意識の定義
次のように仮定します。 CTM のライフサイクル t は有限です。時間は、t= 0,1,2,…T∼10^10 の離散クロック刻みで測定されます。 (1秒間に約10回、アルファ脳波リズム)。 CTM は時刻 0 に誕生しました。 CTM は、
2.1.1. STM および LTM プロセッサ
セクション 2.2 で定義されているように、CTM では、STM は単一ブロックを保存できる小さなメモリです。 LTM は N 個のプロセッサ (N>10^7) の大規模な集合であり、各プロセッサは T ブロックの一部を保持するのに十分な大きさのランダム アクセス メモリを備えたランダム アクセス マシンです。プロセッサは LTM にのみ搭載されており、STM には搭載されていないため、この記事でプロセッサについて言及する場合は、LTM プロセッサについて言及しています。特定の特殊な LTM プロセッサは、特に CTM の意識的な感覚を担当します。これらの特別なプロセッサには、ワールド プロセッサ、内部スピーチ プロセッサ、および内部ビジョンや内部タッチなどを処理するためのその他の内部汎用スピーチ プロセッサのモデルが含まれます。
2.1.2. アップリンク ツリーの競合とダウンリンク ツリーの競合
ダウン ツリー (ダウン ツリー) は、高さ 1 の単純な下向きツリーです。はルートであり、ルートからリーフへ向かう N 個のエッジがあり、各 LTM プロセッサには 1 つのリーフがあります。昇順ツリーは、高さ h、N 個のリーフ、LTM プロセッサごとに 1 つのリーフ、および STM 内の (単一の) ルートを持つ上向きのバイナリ ツリーです。各 LTM プロセッサは独自の専門知識を備えており、アップリンク ツリーでの競争を通じて独自の質問、回答、STM への情報を取得し、それらをダウンリンク ツリーを通じてすべての LTM プロセッサの視聴者に即座にブロードキャストします。 CTM を簡単に実行するために、すべての LTM プロセッサが STM コンペティションに情報を送信し、すべてのプロセッサが STM からのすべてのブロードキャストを受信します。しかし、人間では、視覚の背側経路は決して意識されず(STMに到達することはありません)、腹側経路だけが意識されています。このボトムアップ/トップダウンのサイクルは、グローバル ニューロン ワークスペース (GNW) 仮説に似ています。この仮説では、「意識的なアクセスは 2 つの連続した段階で発生します…最初の段階では、約 100 ミリ秒から約 300 ミリ秒まで、刺激はボトムアップの無意識的な方法でプロセッサの皮質レベルを上昇させます。第 2 段階では、刺激が現在の目標と注意状態を満たしているとみなされる場合、トップダウンのアプローチは継続的な方法によって増幅され、維持されます。 GNW ニューロンの小さなサブセットの活動が、残りのニューロンが抑制されます。ワークスペース全体がグローバルに接続されており、常にそのような意識表現の 1 つだけがアクティブになります。"
2.1.3.チャンク、意識的なコンテンツ、意識的な認識、意識の流れ
質問、回答、情報はチャンクで配信されます。 STM への参入競争に勝ったブロックを CTM の意識コンテンツと呼びます。 CTM では、バールズの演劇の比喩とは異なり、STM (舞台) には常にまったく同じ俳優がいます。時間の各ステップで、俳優は勝利ブロックを取得します。これは、下降ツリーを通じて瞬時に再生されるスクリプトです。すべての LTM プロセッサがこのブロードキャストを介してコンテンツを受信すると、CTM はこれらのコンテンツを意識的に認識すると考えられます。 STM で勝利ブロックが発生するのではなく、すべての LTM プロセッサによる STM ブロードキャストの受信として意識的認識を定義します。この定義は、プロセッサ、特にワールド モデルと内部音声モデルが受信された後に意識の感覚が現れることを強調しています。放送後に生成されます。 CTM における意識の定義は、認知神経科学者が「注意」と呼ぶものとほぼ一致しています。 CTM で私たちが意識の感覚と呼ぶものは、認知神経科学者が「認識」または「主観的認識」と呼ぶものとほぼ一致しています。 CTM 内のバブリング ブロックは STM と競合し、勝ったブロックが STM から LTM プロセッサに継続的にブロードキャストされます。 STM から LTM に伝播された時間順のチャンクが意識の流れを形成します。セクション 3 で述べたように、この流れは主観的な意識の感覚の一部です。
2.1.4. リンク、無意識のコミュニケーション、グローバル点火
プロセッサ間のすべての通信は、最初は STM を通じて発生します。たとえば、プロセッサ A は、ツリーを上って競合することによって、STM に質問を送信できます。問題が競争に勝った場合、その問題はすべての LTM プロセッサにブロードキャストされます。プロセッサ B は、コンテストを通じて回答を送信でき、プロセッサ B が勝った場合はブロードキャストされます。 A が B の答えが十分に役立つと考える場合、A と B の間に双方向の接続が形成されます。この関係は、「一緒に発火するニューロンは一緒に配線する」というヘブの法則を思い出させます。プロセッサは、上流のツリーで競合するためにブロックを送信するだけでなく、リンク全体にもブロックを送信します。このようにして、A と B の間の (STM を介した) 意識的なコミュニケーションは、(リンクを介して) A と B の間で送信されるブロックを介して、直接的な無意識のコミュニケーションになる可能性があります。 A と B の間に追加のつながりが形成されます。私たちの言葉では、A と B の間のつながりが強化されます。リンクは、プロセッサ間で情報を転送するためのチャネルです。 CTM を意識したコンテンツがブロードキャストされると、リンクされたプロセッサ間で送信されるそれらのチャンクによって、意識的な認識が強化され、維持されます。この強化は、Dehaene と Changeux が GNWT で「グローバル点火」と呼ぶものに関連しています。 Dehaene 氏が書いているように、「全体的な点火は発生します...ブロードキャストが特定のしきい値を超えて自己強化されると、一部のニューロンが他のニューロンを刺激し、この刺激が再び興奮を伝達します。接続は一緒にあります (細胞) が突然領域に入ります。ヘブの言うところの、高レベルの活動の自立した状態、エコーする「細胞集合体」。」
2.1.5. 入力と出力のマッピング: センサーとアクチュエーター
CTM の環境 (Env) は Rm(t) のサブセットであり、R は実数を表します。 m は正の整数の次元で、t (非負の整数) は時間です。入力マップは、CTM のセンサーによって取得された時変環境情報を指定された LTM プロセッサに送信し(簡単にするために、ここではこれらのセンサーが入力マップの一部であると仮定します)、そこで環境情報がブロックに変換されます。出力マップは、環境上で動作するためにコマンド情報を LTM プロセッサから実行プログラム (ここでは実行プログラムが出力マップの一部であると仮定します) に渡します。
2.1.6. 接続の概要
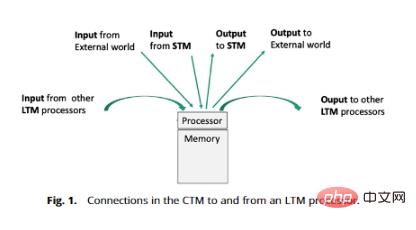
CTM には、情報送信のパスとメカニズムを提供する 5 種類の接続があります。次の図は、CTM プロセッサと LTM プロセッサ間の 5 つの接続を示しています:
- Env-LTM: 環境からの指向性エッジはセンサーとセンサー データのプロセッサを通過します。 #LTM—STM: アップリンク ツリー経由;
- STM—LTM: ダウンリンク ツリー経由;
- LTM—LTM: プロセッサ間の双方向エッジ;
- LTM —Env: 特定のプロセッサは、実行者を介して環境に指向性エッジを渡し、実行者は環境に作用します (特定のプロセッサとは、指の動きの命令を生成するプロセッサを指し、実行者はこれらのプロセッサを受け取ります。命令の指、アクチュエーターは、これらのプロセッサーの指の動きを通じて環境に作用します)。

です。このうち、address(アドレス)はLTMプロセッサによって生成されたアドレスブロック、tはブロックが生成された時刻、gist(要点)は脳言語で「簡潔に表現された」情報です。プロセッサが通信する予定のコンテンツ。重みはプロセッサによって主要なポイントに提供される偽の数値です。強度とムードはそれぞれ時間 t の |weight| と重みで始まります。研究者らは、ブロックのサイズ (および要点を含むそのコンポーネントのサイズ) は、計算の複雑さを考慮して必然的に制限されることに注意しています。
2.3. 確率的なアップツリー競合: コイン投げニューロンと競合関数アップツリー競合は、どの LTM プロセッサが独自のブロックを STM に配置できるかを決定するメカニズムです。各タイミング ポイント t = 0,1,…,T で、t 番目の競合が始まると、各プロセッサ p はそのブロックを昇順ツリーのプロセッサ リーフ ノードに配置します。ブロックが上位ツリーの競争に送られた後、競争ツリーを上に進むにつれて、そのアドレス、t、要点、および重みは変わりませんが、よりグローバルな情報を組み込むために強度と雰囲気が変化します。 2.4. 意識的知覚の計算量と時間遅延t>0 および s>0 の場合、ノードでのブロックとアップリンク ツリーの競合でのブロックの更新には、必要な計算が含まれます: 1) f の 2 つの簡単な計算、その値の合計と除算、および 1 つの簡単な確率的選択; 2) 選択したブロックのアドレス、ポイント、重みをノード vs に入力します; 3) vs の子ノードを相関させます。ブロックが合計され、これらの合計が vs ノードでのブロックの強さとセンチメントに設定されます。これらの計算はすべて 1 単位時間内に完了する必要があり、これによってノード上のブロックのサイズとそのノード上で実行できる計算量の制限が設定されます。2.5. メモリと高レベルのストレージ
各プロセッサ p は、プロセッサによって競合 , t に送信されたブロック p を含む、時間 t でソートされた一連のタプルを内部メモリに保存すると仮定します。 、0、およびSTMのブロードキャストを介してプロセッサによって受信されたチャンク、および時間tにおいてリンクまたは入力マップからプロセッサによって受信されたチャンクの選択されたサブセット。これらのシーケンスは CTM ストレージの重要な部分です。 「履歴」は、p が見たこと、行ったことの高レベルのストレージを提供します。高レベルのストレージは、意識的な感情における CTM の自己認識を主に説明します。 CTM には、夢を生み出すための予測アルゴリズムと組み合わせた高レベルのストレージが必要です (詳細についてはセクション 4.5 を参照)。この保存された情報は定期的に削除され、「重要な」チャンク、特にひどい、素晴らしい、または予期せぬイベントを表すチャンクだけが残るようにすることができます。通常、各プロセッサは、生成、変更、および保存するブロックについて予測を行います。
2.6. 予測ダイナミクス = 予測フィードバック学習 (睡眠エキスパート アルゴリズム、SEA)
プロセッサーは、予測の正しさを評価してエラーを検出し、精度を向上させ、エラーを減らす方法を学習するためにフィードバックを必要とします。そして間違いを修正してください。 •LTM プロセッサは、STM コンペティションに送信されたか、リンクを介して他のプロセッサに送信されたか、環境に影響を与えるエグゼキュータに送信されたかに関係なく、すべてのブロックに対して CTM 予測を実行します。 • STM ブロードキャストから受信したチャンク、リンク経由で受信したチャンク、入力マップ経由で環境から受信したチャンクをフィードバックします。 •すべての CTM 学習とエラー修正はプロセッサ内で行われます。 CTM では、予測、フィードバック、学習の継続的なサイクルが行われます。 CTM は、必要に応じてこれらに対処し、世界に対する理解を常に向上させるために、異常な出来事やあらゆる種類の驚きに注意を払う必要があります。このサイクルを通じて、予測エラー (「驚き」など) が最小限に抑えられます。特に、プロセッサは、重み割り当てアルゴリズムを変更できるように、重みの設定が保守的すぎるのか大胆すぎるのかを知る必要があります。 Sleep Expert Algorithms (SEA) は、この目標を達成するために LTM プロセッサによって使用される学習アルゴリズムのクラスです。ここに示されているのは、SEA の最も単純なバージョンの 1 つです。次の場合にプロセッサを奨励します (ブロックに割り当てる強度を高めます):
- そのブロックが STM に入らず、
- そのブロックの情報 (SEA の観点から) がより多くの場合STM に入力される情報よりも貴重です。
次の場合にプロセッサを抑制します (ブロックに割り当てる強度を下げます):
- そのブロックが STM に入る
- それ 発見された情報(おそらく後で) STM に取り込めなかった一部のブロックからの情報ほど価値はありません。
SEA は、プロセッサがブロックを STM に入れるかどうかに役割を果たします。 SEA は、プロセッサがリンクを通じて送信されるブロック内の重要なポイントに「注意を払う」かどうかにも影響します。ブロックの重みの絶対値は、ブロックを生成するプロセッサがそのポイントを重要であるとみなしているかどうかを示し、これはブロックを受信するプロセッサがそれに気づくかどうかに影響します。
2.7. CTM モデルと GWT モデルの比較
研究者らは、以下の図に示すように、CTM と Baars の GWT モデルを比較しました。

注: モデル スケッチ: Baars の GWT モデル (左) と CTM モデル (右) わかりやすくするために、この図では多くの機能を簡略化しています。たとえば、CTM ではステージ上に「アクター」が 1 人だけ存在し、この「アクター」は一度に 1 つのブロックしか保持しません。さらに、CTM のプロセッサはすべて LTM にあります。ここでは、中央執行部の機能がプロセッサーに引き継がれるため、中央執行部は排除されます。 CTM では、入力と出力は STM を直接経由するのではなく、LTM プロセッサとの間で直接やり取りされます。 CTM では、ブロックは明確に定義された競技で競い合い、ステージ (STM) に到達します。
意識的な認識 (注意) は、入力と STM の間で発生するイベントではなく、すべての LTM プロセッサによるブロードキャスト勝ちブロック (つまり、CTM の意識的なコンテンツ) の受信です。 Baddeley と Hitch の口頭リハーサルと視空間スケッチパッドの役割は、LTM プロセッサによって引き継がれました。予測ダイナミクス (予測、フィードバック、学習のループ) とマルチモーダルな内部言語 (脳言語)、および計算と複雑さの考慮事項は、CTM の主要な機能です。
最後に、「心の拡張理論」で述べたように、CTM は Google、Wikipedia、WolframAlpha、AlphaGo などの LTM プロセッサの形式で既存のテクノロジーにアクセスできます。LTM プロセッサのタスクは次のとおりです。これらのアプリケーションを使用してください。これは、CTM がその寿命の初め(t=0)に、その寿命全体にわたってスケーラブルな大規模で強力なプロセッサのコレクションを確実に持つようにする方法です。
CTM モデルの主要な特徴とそのダイナミクスは、デネットによって概説された意識の特性に似ています。つまり、私たちの意識的思考の変換を制御するのは、マスター スケジューラーでも、ボス ニューロンでも、ホムンクルスでもありません。 . またはレス・コギタンス。制御の実装は、動的である程度競争力のあるプロセスでなければなりません。いったい何が勝者を決めるのでしょうか?
は、痛み、恥ずかしさ、欲望などの強迫的な記憶のような感情的に顕著な出来事だけでなく、すべてのコンテンツに付随し、その運命を制御する微感情、正と負の原子価の強さのようなものでなければなりません。抽象的な理論的思考。 CTM は Baars の GWT アーキテクチャに触発されていますが、意識的な体験に必要な機能を統合しています。これが次のセクションの焦点です。
3 意識の感覚STM によって広められた意識内容の定義によれば CTM は意識的ですが、この定義は意識の内容を説明するものではありません。 CTMにおける意識の感覚を生み出すもの。著者は、CTM の意識は主に、CTM のアーキテクチャ、特定の特殊プロセッサ、および CTM の予測ダイナミクス (予測、フィードバック、学習) と組み合わせた、非常に表現力豊かな脳言語によってもたらされると考えています。
1) 脳言語
マルチモーダルな脳言語は、CTM によって認識される世界を正確に記述します。この認識は、多様な言語の感覚から構成されています。その語彙には、息(鼻孔で感じる匂い)、痛み(非常に不快な痛みの感覚)、顔(他人の顔を見たときに見えるもの)などが含まれます。夢は、CTM に入力も出力もないときに、その点が何を表現できるかを示すため、重要です。
2) アーキテクチャ
これには、STM へのアクセスを獲得するためのアップツリー競争と、その後の勝者、特に特別な役割を果たすすべての人々のグローバルなダウンツリー ブロードキャストが含まれます。意識的な感情を生成する際のキャラクターハンドラー。
3) 特別なプロセッサ
著者は、誕生時に特別なアルゴリズムが組み込まれたいくつかのプロセッサを選択しました。
- Model of The World プロセッサは、環境から取得した情報、または変更された可能性がある内部メモリから取得した情報に基づいて、CTM ワールドのモデルを構築します。 CTM によって作成されたスパース「CTM」モデル。CTM の内部世界をワールド プロセッサのモデルとして定義します。 CTM の外界を、CTM が持つ(かもしれない)感情や実行する(かもしれない)行動など、脳言語で注釈を付けるラベルと説明として定義します。
- 内部スピーチ プロセッサは、STM によってブロードキャストされた要点内でエンコードされた音声を抽出し、入力マップが外部音声 (入力マップによって作成された要点) を送信する要点と同じ場所に送信します。 )。これは、最初は STM 経由で送信され、リンクが形成されるとリンク経由で直接送信されます。 「内部音声」は内部音声プロセッサによって生成され、これにより CTM は過去を思い出し、未来を予測し、計画を立てることができます。内なる会話の要点(独り言や夢の中で言われたこと、聞かれたことなど)は、外的な会話の要点とほとんど区別がつきません。統合失調症患者の場合と同様、人間の内部音声は外部音声と非常によく似ているため、両者を区別するのは困難です。
- 内部視覚プロセッサと内部 (触覚) 感覚プロセッサ。STM によってブロードキャストされるあらゆる画像と感覚を、入力マッピングが外部シーンと外部感覚に送信される任意の場所にマッピングします。内部視覚と外部視覚 (入力画像によって生成される視覚的なハイライト) の間にはほとんど違いはありません。 CTM の記憶力と予測能力により、CTM は内部イメージや感覚を創造し、その結果想像力や夢が生まれます。統合失調症の幻覚を防ぐために、人間の脳は内部の画像と外部の画像を区別します。脳はこれを行うためにあらゆる種類のトリックを備えていますが、その 1 つは夢を覚えにくくすることです。
これらのプロセッサは、CTM ワールド モデルの「目」と「皮膚」に情報を与え、CTM が視覚記憶から呼び出すものすべてを「見て」、「触覚的に知覚」できるようにします。感覚記憶。この目と皮膚はCTMの心の目と心の皮膚です。著者は、これらのプロセッサは内部の汎用音声プロセッサであると考えています。
4) 予測ダイナミクス
さらに、著者は、CTM は予測、フィードバック、学習の継続的なサイクルを通じて CTM の意識に影響を与えると考えています。この感覚は、CTM が常に計画とテストを行っている CTM のワールド プロセッサ モデルの (並列) 予測ダイナミクスによってさらに強化されます。正のフィードバックは、何が起こっているのかを理解しているという信号を CTM に与えます。負のフィードバックは、予期せぬ大きな衝撃音などの予測不可能なものに関するものでない限り、CTM に未知または理解していないことの証拠を与えます。 CTM の意識には、他にも以下の要素があります。
5) 思考と計画を立てるための基本的 (一般的) 能力
6) 計画を立てて実行する動機 (=エネルギー的動機)。
次に、ワールド プロセッサ モデルに戻り、中心的なタスクを説明します。これは、モデルのさまざまなコンポーネントを自己 (自己)、非自己、または不明としてマークすることです。ワールドプロセッサーのモデルは、何が自己であり、何が自己ではないかをどのように決定するのでしょうか?ブロックのブロードキャスト (CTM のアイデア) の直後に、実行者が環境内でアクション (同じアクションを継続的に繰り返すというアイデア) を実行する場合、これは実行者が自己の一部であることを示します。
ワールド モデルのプロセッサには、想像力の創造、環境のマッピングの作成、環境の動きの表現など、CTM に自己認識を与える他の重要な仕事もあり、環境内での行動の計画を支援します。自己および非自己の行動、自己および非自己の行動の予測を修正する。
CTM がブロードキャストを通じて自分自身の意識について考えていることに気づくと、ワールド モデル プロセッサはモデル内の「CTM」を「意識」としてマークします。それでは、CTM が意識的であると考える理由を見てみましょう。これは、ワールド モデル プロセッサやその他のプロセッサが意識があると考えているためではあり得ません。プロセッサはアルゴリズムを実行する単なる機械であり、そのような機械には感情がないからです。
著者は、CTM 全体が意識的であると信じています。その理由の 1 つは、ワールド モデル プロセッサがワールド モデル内の「CTM」を意識的として扱い、このビューをすべてのプロセス デバイスに伝播するためです。ここで、「CTM」は、より複雑な CTM を単純に学習した表現です。
#4 高レベルの説明このセクションでは、CTM が一般に意識に関連するさまざまな現象をどのように経験するかを検討します。著者らは、このモデルから導き出された説明は、意識経験がどのように生じるか、または生じる可能性があるかについての高度な理解を提供し、これらの説明は心理学および神経科学の文献と非常に一致していると信じています。
4.1. ブラインドサイト
以下の例では、ブラインドサイトは意識的認識と無意識的認識の違いを示しています。盲目では、人は意識的に外の世界を見ることができません。散らかった部屋で何かを取りに行くように頼まれた場合、参加者は「それがどこにあるのか分からない」という典型的な反応をしますが、その要求が注意深く扱われれば、参加者は依然としてタスクを適切に実行できます。どうしたの? CTM では、視覚入力はビジョン センサーから、視覚入力を処理する LTM プロセッサのサブセットに直接送られます。ただし、ブラインドサイト型 CTM では、何らかの不具合、おそらく昇順ツリーの破損、またはビジュアル プロセッサがブロックの情報を競合的に入力できないため、この情報は STM にアップロードできず、したがってグローバルにブロードキャストできません。 . .このため、CTM は何が見えているのかを意識的に認識しません。ただし、リンクを介して (無意識の) プロセッサ間で情報を通信することはできます。したがって、ビジョンプロセッサが受信した視覚情報は、リンクを介して脚アクチュエータを制御する歩行プロセッサに送信できます。
4.2. 不注意による失明
意図的な失明は、明らかに目の前にある視覚刺激を感知できないときに発生します。不注意による失明とは、「他の作業に注意を集中しているときに、予期せぬものの存在に気づかないこと」です。たとえば、有名な選択的注意テストでは、実験者は聴衆に「見えないゴリラ」のビデオを見せ、聴衆に「白いシャツを着た選手が出したパスの数を数えてください」と頼みました。視聴者のほぼ全員が正解に近い数字を挙げたが、「ゴリラを見ましたか?」との質問には唖然とした。一体何が起こっているのでしょうか? CTM がゴリラの映画を見ているとします。
白シャツの選手に関する入力クエリは STM へのアクセスを取得し、すぐにすべての LTM プロセッサにブロードキャストされます。このタスクを実行するために、CTM のビジョン プロセッサは白いシャツのハイライトに高い密度を割り当て、黒いものには非常に低い密度を割り当てるため、「ゴリラ」パターンのブロック状のオブジェクトにはハイライトがほとんどありません。
CTM は意識的にこのゴリラを見たわけではありません。不注意による失明についての CTM の説明は、「重要なポイントに異なる密度を与え、無関係なポイントに低い密度を与えると、より高い密度のブロックを取得する方が競争上の優位性が高まる」というものです。参考文献で実行されたシミュレーションによると、特定の「燃え上がった」状態では「自発的な活動が外部の感覚処理を妨げる可能性がある」という。彼らは、この遮断が不注意による失明の原因と関連付けました。私たちの意見では、黒い物体に対する人間の脳の「感覚処理」をブロックすることは、CTM がブロック内の黒い点の密度を大幅に減らし、それによってこれらのブロックが STM に入る可能性を減らすのとほぼ同等です。 CTM における異なる密度の効果は、人間の不注意による失明が「無関係な情報に対するフィルターとして機能し、予期せぬイベントを除外する可能性がある」という理論的意味とも一致しています。
4.3. 変化盲目
変化盲目は、人が写真やシーンの大きな変化に気づくことができないときに発生します。一瞬から別の瞬間へ。」
有益な例は探偵ビデオです。刑事が殺人現場に入り、「明らかに、この部屋の誰かがスミス卿を殺害した」と言い、すぐに各容疑者を順番に尋問します。メイドは言いました:「マスターベッドルームで真鍮を磨いているのです。」家政婦は言いました:「マスターのスコーンにバターを塗っているのです。」そしてスマイス夫人は「盆栽小屋でアサガオを育てています。」情報 賢い探偵であれば、殺人事件をその場で解決するのに十分です。
しかし、なぜ私たちは、冒頭のスクリーンショットとエンディングの間で多くの不快なシーンの変化に気づかなかったのでしょうか?
CTM の視点から見ると、CTM は「探偵」のビデオを見たとき、全体的な印象はありましたが、ウインドブレーカー、花、絵画などが他のものに置き換えられた後に起こった変化には気づきませんでした。これは次の理由によるものです:
1) 撮影の過程で、監督はシーン全体や個々の登場人物の変化を巧みにアレンジし、暗いトレンチコートを脱いで白いトレンチコートに、クマを鎧に、麺棒を燭台に変えました。 、故人が着替えたり足を上げたりして変化に移行します。ビデオ入力は、「シーン」が変更されたことを CTM のビジョン プロセッサに信号で伝えることはありません。
2) 重要なのは、同じ箇条書きで冒頭と最後のシーンが同じように説明されているということです。「刑事、家政婦、メイドなどがいる邸宅のリビングルーム、そして床に男が倒れている、死者。」
このような状況では、CTM には変更盲点が発生します。
繰り返しますが、CTM の説明は、人間の変化盲目に関する文献と一致しています。変化の検出には、変化前と変化後のシーンの適切な表現と比較が必要であることを考えると、表現の豊かさ、または表現を比較する傾向に影響を与えるタスクの特性は、検出に影響を与えるはずです。変化するオブジェクトの意味論的な重要性は、被験者がその変化に注目し、したがってそれに気づく可能性に最も大きな影響を与えると思われます。
4.4 幻覚、不注意による失明、および失明の変化は幻覚の例と考えられます。
定義により、CTM は STM からブロードキャストされるブロック内のポイントを意識的に認識することです。 (これらのポイントは、LTM プロセッサから STM に到着します。LTM プロセッサは、入力マッピングを通じてセンサーから、リンクを通じて他の LTM プロセッサから、またはブロードキャストを通じて STM からこれらのポイントを取得します)。キーポイントはさまざまな理由で LTM メモリに保存されますが、その 1 つは、夢の中で何が起こるかなど、高レベルのストーリーをプロセッサに提供することです。
CTM では、意識の流れは STM によって演じられる一連のキーポイントです。あらゆる瞬間のあらゆる視覚点によって、CTM は、たとえせいぜいそのほんの一部しか見えていないとしても、目の前のシーン全体を見ているように感じられます。全体的な錯覚にはいくつかの説明がありますが、その主な説明は、マルチモーダルな脳音声の要旨によって、「私は小川、小道、橋、木々のある日本風の庭園に立っている」などの非常に複雑な情景を説明できるというものです。フォワード"。この箇条書きには、iPhone のカメラで撮影された 12 メガピクセルの写真 (まるで私たちが見ているように感じられる) の詳細が含まれていますか?全体的な錯覚は、箇条書きの非常に示唆に富んだ (簡潔な) 情報の結果です。 CTM はこのシーンを魔法のように呼び起こしました。キース・フランキッシュはこれを意識の幻想論と呼んでいます。
4.5. 夢の創造
夢は究極の幻想です。夢を見ないと主張する人もいますが、ほとんどの人は夢を見ます。夢には視覚、聴覚、触覚などがあります。夢は感情的なプロセスに関連していることが多く、大きな痛みや恐怖(悪夢)、または大きな喜び(空を飛ぶ夢など)を表現する場合があります。足にひどい痛みを感じ、目が覚めるとその痛みは完全に幻想で全く痛みがなかったことに気づくこともあれば、うつ伏せで眠り、仰向けで目が覚めることもあります。
CTM では、内蔵の睡眠プロセッサが時間、習慣、昼夜などを追跡し、睡眠のニーズを監視する内部アルゴリズムを備えています。スリープ プロセッサがスリープが必要であると判断すると、ブロックが STM に入ることができ、他のブロックが STM からブロックされるように、自身のブロックの密度が増加します。これには、他の LTM プロセッサのブロック密度を減らすのとほぼ同じ効果があります。このプロセッサはまた、さまざまな入力 (視覚と聴覚) の密度をブロックまたは大幅に低減し、出力 (手足で受信するものなど) をアクティブにする信号をブロックします。これが睡眠状態です。スリープ プロセッサはスリープの必要性を継続的に監視し、この必要性が減少するのに応じて自身のブロックの密度を比例的に減らします。これにより、最終的には夢の要点 (チャンク単位) が STM に到達できるようになります。これが夢の状態です。
最後に、スリープ状態のプロセッサが入出力の制限を下げると、CTM が起動します。人間では、目が覚める前に、非急速眼球運動睡眠と急速眼球運動睡眠が数回交互に繰り返されることがあります。
CTM がドリーム状態になると、ドリーム クリエーター (Dream Creator) がアクティブになり始めます (つまり、このプロセッサーはブロックを STM に送信し始めます)。これらのブロックのポイントには、思考の核心が含まれています (通常、初期の CTM 活動、懸念、想像力に基づいています)。これらのチャンクがブロードキャストされると、意識感覚において重要な役割を果たすプロセッサを含むすべてのプロセッサがこれらのブロードキャストを受信し、反応しようと競い合います。これにより、CTM は目覚めているときと同じように、夢の中でも生きているという感覚を得ることができます。
Dream プロセッサと他のプロセッサは交互にやり取りを行います。夢プロセッサとプロセッサの間の対話、つまり前後の対話は、夢を構成する点のシーケンスであり、このシーケンスは夢の意識の流れです。
夢は本質的に、このシーケンスの一部をつなぎ合わせて、1) 夢の世界を見て、聞いて、感じ、2) 夢の世界に影響を与える、夢の意識の流れ (内なる映画) を生成します。世界に現れます。このような (インタラクティブな) インナー ムービーは、一連の感覚入力 (画像、匂い、音) を表示し、一連のアクションを生成します。
ほとんどのプロセッサは、CTM がスリープしていても夢を見ていないときは、チャンクを STM にフィードできません。巨大なノイズ検出器とスリープ状態のプロセッサ自体は例外です。 STM 内でプロセッサのブロックをスリープ状態にすると、他のほとんどのプロセッサのブロックが STM に到達できなくなります。設計上、スリープ プロセッサは空の Gist を保持するため、CTM はまったく認識しないか、ほとんど認識しません。
CTM がスリープ状態を抜けてドリーム状態に入ると、内視鏡プロセッサなどの一部の LTM プロセッサはブロックを STM に送信できます。したがって、夢を見ている間、CTM は意識があり、出来事を生き生きと経験することができます。セクション 3 で説明したように、内なる音声、内なる視覚、内なる感覚、世界モデルなどの主要なプロセッサは、CTM の意識的な感覚を生成する際に特別な役割を果たします。
これらのプロセッサは、CTM が夢を見ているときに同様の役割を果たします。プロセッサが CTM の夢をどのように作成するかの例をいくつか示します。
- 内部スピーチ プロセッサは、STM によってブロードキャストされたマルチモーダル グラフィックスから内部スピーチを抽出し、そのスピーチを外部メッセージを受信する受信機に送信します。同じプロセッサ。このプロセスにより、夢の言語が外部の言語のように聞こえます。内なる視覚と内なる感覚プロセッサは、同様の方法で夢を作り出すのに役立ちます。
夢は、脳の論点の力を示しています。 CTM が夢の中で見たり、聞いたり、感じたり、行ったりすることは、呼び出し、修正し、STM のコンテストに作品を提出できるプロセッサーによって捏造されたに違いありません。これらの捏造は、起きている間に生成されたものと同じポイントを使用するため、現実的です。
したがって、CTM が外部入力から完全に切り離されている場合でも、夢は現実世界の感覚を生み出すことができます。その結果、夢が非常に現実的に見えるため、CTM では夢と現実を区別することが困難になる可能性があります (ただし、人間は夢を思い出すのが難しいため、人間ではこの問題は回避されます)。既存の文献では、人が顔を見た後、その顔を記憶から呼び出す場合でも、その顔が夢の中に現れる場合でも、同じパターンの神経活動が現れることが証明されています。また文献では、人が動きを感じるレム睡眠中、夢の中での運動皮質の活性化は覚醒時と同じであることも指摘されている。
- ワールド モデル プロセッサは、CTM の動作がその (内部および外部) 世界に与える影響を予測します。これは、ワールド モデル内のアクションの影響から行われます。夢プロセッサは、これと同じ予測マシンを使用して夢を作成できます。
夢は、CTM が未知の危険な状況で自分自身をテストすることも可能にします。人間と CTM の両方において、夢はさまざまな解決策を実験するための実験室として機能します。ただし、覚醒時とは異なり、CTM のワールド モデル プロセッサ内の「整合性チェッカー」は環境から入力を取得しないため、覚醒時よりも夢の中で不一致が気付かれずに発生しやすくなります。
したがって、CTM は夢の中で飛ぶことができます。ザドラとスティックゴールドは、人間の場合、「夢は記憶を正確に再現するわけではない。夢は、最近の記憶と同じ要点を持ち、同じタイトルの物語を作り出す。」と主張し、「レム睡眠は、弱った脳の状態を提供する」と指摘している。そして、予期せぬ連想が通常の強い連想よりも強く活性化されることで、レム睡眠が弱い関連性のある遠くの連想を見つけるのにどのように役立つかを説明しており、おそらくそれがレム睡眠中の私たちの夢が非常に奇妙な理由を説明しているのかもしれません。」
4.6. 自由意志
自由意志の問題は古く、紀元前 1 世紀にルクレティウス (De Rerum Natura) によって登場しました。 「すべての運動が常に相互に関連しており、新しいものが古いものから一定の順序で生じているとすれば、もし原子が何らかの新しい運動を生み出すために決して回転せず、運命の絆、原因と結果の永遠の順序を断ち切るのであれば――サミュエル・ジョンソン博士の 1709 年から 1784 年にかけての観察は、自由意志のパラドックスを捉えています。「すべての理論は意志に反しています。意志の自由、そしてすべての経験」スタニスラス・デハーンは現代的な声で次のように述べています。「私たちの脳の状態には明らかに原因がないわけではなく、物理法則から逃れることはできません。何も逃れることはできません。しかし、私たちの決定が意識的な思考に基づいており、自律的に行われている限り、 「何の妨げもなく、メリットとデメリットを慎重に考慮してから、特定の行動をとります。それが真の自由です。これが実現したとき、私たちは自発的な決定について話しています。もちろん、それが最終的に私たちの遺伝子とによって引き起こされたとしても」
" この記事の著者は、Dehaene に基づいて、計算には時間がかかると付け加えました。意思決定を行うために、CTM は時間がかかる評価で代替案を評価しますが、その間 CTM は自由に、実際には自由に、最良と思われる (または計算された) 結果を選択できます。
したがって、理論的コンピューターの見解は、自由意志の定義に影響を与えます。自由意志とは、さまざまな行動方針の結果を計算する、または利用可能なリソース (時間、空間、計算能力、情報) の範囲内でこれらの結果をできるだけ多く計算し、その中から方針を選択する自由です。自分の目標に最も適した行動を。
この定義には、予測ダイナミクス (さまざまな行動方針の結果の計算) とリソース制約 (時間、空間、計算能力、情報) の両方が含まれます。たとえば、CTM がチェスのゲームで特定のポジションをプレイするように求められたとします。プロセッサーが異なれば、提案される動きも異なります。 CTM の主要なチェスプレイ プロセッサ (そのようなプロセッサが存在するか、ゲームの「高レベル」ビューを持つプロセッサが存在すると仮定) は、チェスの手を選択できることを認識する STM 内のブロックをブロードキャストすることによって表されます。それぞれの動きの結果を注意深く研究する価値があると考えています。この時点で、考えられる手の選択肢に直面していますが、その手の結果をまだ評価していないため、CTM は制限時間内に最善と思われる手を自由に選択できます。 CTM は自分に自由意志があると感じていますか?
1) CTM が「どうすればいいのか?」という問いが現れる瞬間を考えると、この問いが STM 段階にまで上がり、ブロードキャストを通じて LTM プロセッサ側の視聴者に届いたことを意味します。これに応じて、一部の視聴者がイベントに独自の提案を投稿し、コンテストの勝者がステージ上で放送されます。要点が短いため、より簡潔な放送のようなものを合理的に述べることができます。
2) STM に表示され、LTM にグローバルにブロードキャストされる継続的かつ繰り返されるコメント、コマンド、質問、提案、および回答により、CTM はその制御を認識します。 CTM がどのようにして特定の提案に至ったのか (つまり、その提案を行う際にどのような考えを経たのか) を尋ねられると、CTM のプロセッサーは、その段階に到達した会話の一部を明らかにすることができます (ただし、実際にはそうではないかもしれません)。この段階を超えても短期間)。
3) 多くの LTM プロセッサは競合を利用して CTM の最終決定を行いますが、CTM はすべてを競合に提出するのではなく、STM に何が入っているかを意識的に知っているだけです。さらに、CTM の大部分、つまりそのプロセッサのほとんどは、プロセッサ間の (リンクを介した) 無意識の会話を認識しません。 CTM の場合、意思決定を意識的に無視するプロセスが何度も発生すると、意思決定が何もないところから出てきたように見えることがあります。それでも、CTM は、STM によって広められる高レベルのコンテンツ以外に、自分のアドバイスがどのように採用されるかを意識的に知ることはできませんが、アドバイスが自分自身の内部から来ていることを知っています。 CTM には提案があると認められるべきであり (結局のところ、提案は CTM 内から出てくるものです)、一部は高レベルの説明で説明でき、説明されていないものは「わかりません」または「知りません」と言えます。覚えて。" 。 CTM が自由な意識の感覚を生み出すのは、まさに選択の知識 (CTM は選択を理解し、理解しない) によってです。決定論的かどうかにかかわらず、この経験的な感覚は自由意志の一形態です。
この自由意志の感覚を説明する上で、ランダム性はどれほど重要でしょうか? CTM では、上記の説明は量子物理学の適用を必要としないことに注意してください。唯一のランダム性は、ツリーの上で競合するコイン投げニューロンと、プロセッサが確率的アルゴリズムで使用するランダム性です。さらに、自由感に関する上記の議論は、完全に決定論的な CTM (擬似ランダム性を使用する CTM など) にも依然として適用されることがわかります。つまり、完全に決定論的な世界であっても、CTM は自分に自由意志があると感じるだろうということになります (そして、これは予想通り激しい議論につながるでしょう)。
以上がトップ国際出版物 PNAS に掲載されました!理論的なコンピューターから出発して、科学者たちは意識モデル「意識的チューリングマシン」を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1318
25
1269
29
1248
24
14
1423
52
1318
25
1269
29
1248
24

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
