

ChatGPT に画像の読み方を教える方法は次のとおりです

2022年は「Wen Sheng Tu」モデルが人気ですが、2023年は何が人気になるでしょうか?
機械学習エンジニアのダニエル・バークからの答えは、その逆です。
いいえ、新しくリリースされた「写真とテキスト」モデルがインターネット上で爆発的に普及し、その優れた効果により多くのネットユーザーが再投稿し、「いいね」を押しました。

は、基本的な「写真を見て話す」機能だけでなく、愛の詩を書いたり、プロットを説明したり、オブジェクトのダイアログをデザインしたりすることもできます。写真など、すべてこのAIがやってくれます しっかり押さえて!
たとえば、インターネットで魅力的な食べ物を見つけたら、写真を送信するだけで、必要な材料と調理手順がすぐに特定されます。

写真の中のレーウェンフックの細部の一部さえもはっきりと「見る」ことができます。
写真の逆さまの家から抜け出す方法を尋ねられたとき、AI の答えは次のとおりでした。「横に滑り台があるではありませんか?」

この新しい AI は BLIP-2 (Bootstrapping Language-Image Pre-training 2) と呼ばれ、コードは現在オープンソースです。
最も重要なことは、これまでの研究とは異なり、BLIP-2 はユニバーサルな事前学習フレームワークを使用しているため、独自の言語モデルに任意に接続できることです。
一部のネチズンは、インターフェイスを ChatGPT に変更した後、すでに強力な組み合わせを想像しています。

著者の 1 人である Steven Hoi 氏は、「BLIP-2 は将来的には「ChatGPT のマルチモーダル バージョン」になるだろう」とさえ述べています。

それでは、BLIP-2 には他にどのような魔法の場所があるでしょうか?一緒に下を見てください。
一流の理解力
BLIP-2のゲームプレイは非常に多様性に富んでいると言えます。
画像を提供するだけで話しかけることができ、ストーリーを語ったり、推論したり、パーソナライズされたテキストを生成したりするなど、さまざまな要件を満たすことができます。
たとえば、BLIP-2 は、写真内の景勝地が万里の長城であることを簡単に識別できるだけでなく、万里の長城の歴史を紹介することもできます。
中国の万里の長城は、紀元前 221 年に秦の始皇帝が首都を守るために建設した北方からの侵略を防ぐために建てられました。

映画の静止画を見せてください。BLIP-2 は、それがどこから来たのかを知っているだけでなく、物語の結末、つまり船の沈没も知っています。タイタニック号、雄、主は溺死した。





猫: ねえ、犬、背中に乗ってもいいですか?
犬: もちろん、どうしてでしょう?
猫: 雪の中を歩くのは疲れた。

では、BLIP-2 はどのようにしてこのような強力な理解能力を実現しているのでしょうか?
複数のビジュアル言語タスクに新しい SOTA を実装する
# 大規模モデルのエンドツーエンドのトレーニング コストがますます高くなってきていることを考慮して、BLIP-2 は一般的で効率的な pre を使用します。トレーニング方法:
既製の凍結済み事前トレーニング済み画像エンコーダーと凍結済み大規模言語モデルから視覚言語の事前トレーニングをブートストラップします。
これは、誰もが使用したいモデルを選択できることも意味します。
モード間のギャップを埋めるために、研究者は軽量のクエリ Transformer を提案しました。
Transformer は 2 つの段階で事前トレーニングされます。
第 1 段階では、フリーズされた画像エンコーダーから学習する視覚的言語表現を導き、第 2 段階では、フリーズされた言語モデルから言語生成まで視覚を導きます。勉強。

BLIP-2 のパフォーマンスをテストするために、研究者らはゼロサンプルの画像テキスト生成、視覚的な質問応答、画像処理から開始しました。テキスト検索と画像字幕のそれぞれのタスクで評価されました。
最終結果は、BLIP-2 が複数の視覚言語タスクで SOTA を達成したことを示しています。

このうち、BLIP-2 はゼロショット VQAv2 で Flamingo 80B より 8.7% 高く、トレーニング パラメータは 54 分の 1 に削減されています。
そして、より強力な画像エンコーダまたはより強力な言語モデルがより優れたパフォーマンスを生み出すことは明らかです。

研究者が論文の最後で、BLIP-2 にはまだ欠点がある、つまり、文脈学習能力の向上:
各サンプルには画像とテキストのペアが 1 つだけ含まれており、単一シーケンス内の複数の画像とテキストのペア間の相関関係を学習することは現時点では不可能です。
研究チーム
BLIP-2 の研究チームは Salesforce Research から来ています。

最初の著者は、1 年前に創刊された BLIP の著者でもある Junnan Li です。
は現在、Salesforce Asia Research Institute の上級研究員です。香港大学を卒業し学士号を取得し、シンガポール国立大学で博士号を取得しました。
研究分野は自己教師あり学習、半教師あり学習、弱教師あり学習、視覚言語など非常に幅広いです。
以下は BLIP-2 の論文リンクと GitHub リンクです。興味のある方はぜひ入手してください~
論文リンク: https://arxiv.org/pdf/2301.12597. pdf
GitHub リンク: https://github.com/salesforce/LAVIS/tree/main/projects/blip2
参考リンク: [1]https://twitter.com/mrdbourke / status/1620353263651688448
[2] https://twitter.com/LiJunnan0409/status/1620259379223343107
以上がChatGPT に画像の読み方を教える方法は次のとおりですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7445
7445
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 トマト無料小説アプリで小説を書く方法. トマトノベルで小説を書く方法に関するチュートリアルを共有します。
Mar 28, 2024 pm 12:50 PM
トマト無料小説アプリで小説を書く方法. トマトノベルで小説を書く方法に関するチュートリアルを共有します。
Mar 28, 2024 pm 12:50 PM
トマト ノベルは非常に人気のある小説閲覧ソフトウェアです。トマト ノベルでは、新しい小説や漫画を読むことができます。どの小説も漫画もとても面白いです。小説を書きたい友達もたくさんいます。お小遣いを稼いで、小説の内容を編集することもできます。 「テキストに文章を書きたいです。それで、小説はどうやって書くのですか?友達は知らないので、一緒にこのサイトに行きましょう。小説の書き方の入門を少し見てみましょう。」 Tomato Novels を使用して小説を書く方法に関するチュートリアルを共有します。 1. まず、携帯電話で Tomato Free Novels アプリを開き、パーソナル センター - ライター センターをクリックします。 2. Tomato Writer Assistant ページに移動し、次の場所で [新しい本の作成] をクリックします。小説の終わり
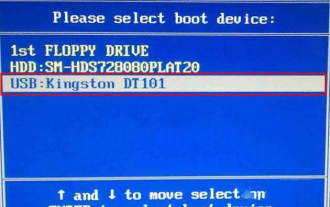 Colorful マザーボードに BIOS を入力するにはどうすればよいですか? 2つの方法を教えます
Mar 13, 2024 pm 06:01 PM
Colorful マザーボードに BIOS を入力するにはどうすればよいですか? 2つの方法を教えます
Mar 13, 2024 pm 06:01 PM
Colorful マザーボードは中国国内市場で高い人気と市場シェアを誇っていますが、Colorful マザーボードのユーザーの中には、設定のために BIOS を入力する方法がまだ分からない人もいます。この状況に対応して、編集者はカラフルなマザーボード BIOS に入る 2 つの方法を特別に提供しました。ぜひ試してみてください。方法 1: U ディスク起動ショートカット キーを使用して、U ディスク インストール システムに直接入ります。ワンクリックで U ディスクを起動する Colorful マザーボードのショートカット キーは ESC または F11 です。まず、Black Shark インストール マスターを使用して、Black Shark インストール マスターを作成します。 Shark U ディスク起動ディスクを選択し、コンピュータの電源を入れます。起動画面が表示されたら、キーボードの ESC キーまたは F11 キーを押し続けて、起動項目を順次選択するウィンドウに入ります。「USB」の場所にカーソルを移動します。 」と表示され、その後
 WeChat で削除された連絡先を回復する方法 (簡単なチュートリアルでは、削除された連絡先を回復する方法について説明します)
May 01, 2024 pm 12:01 PM
WeChat で削除された連絡先を回復する方法 (簡単なチュートリアルでは、削除された連絡先を回復する方法について説明します)
May 01, 2024 pm 12:01 PM
残念ながら、WeChat は広く使用されているソーシャル ソフトウェアであり、何らかの理由で特定の連絡先を誤って削除してしまうことがよくあります。ユーザーがこの問題を解決できるように、この記事では、削除された連絡先を簡単な方法で取得する方法を紹介します。 1. WeChat の連絡先削除メカニズムを理解します。これにより、削除された連絡先を取得できるようになります。WeChat の連絡先削除メカニズムでは、連絡先がアドレス帳から削除されますが、完全には削除されません。 2. WeChat の組み込みの「連絡先帳復元」機能を使用します。WeChat には、この機能を通じて以前に削除した連絡先をすばやく復元できる「連絡先帳復元」機能が用意されています。 3. WeChat 設定ページに入り、右下隅をクリックし、WeChat アプリケーション「Me」を開き、右上隅にある設定アイコンをクリックして設定ページに入ります。
 モバイルドラゴンの卵を孵化させる秘密が明らかに(モバイルドラゴンの卵をうまく孵化させる方法を段階的に教えます)
May 04, 2024 pm 06:01 PM
モバイルドラゴンの卵を孵化させる秘密が明らかに(モバイルドラゴンの卵をうまく孵化させる方法を段階的に教えます)
May 04, 2024 pm 06:01 PM
テクノロジーの発展に伴い、モバイルゲームは人々の生活に欠かせないものになりました。かわいいドラゴンエッグの画像と面白い孵化過程で多くのプレイヤーの注目を集めており、その中でも注目を集めているゲームの一つがモバイル版ドラゴンエッグです。プレイヤーがゲーム内で自分のドラゴンをより適切に育成し成長させることができるように、この記事ではモバイル版でドラゴンの卵を孵化させる方法を紹介します。 1. 適切な種類のドラゴン エッグを選択する プレイヤーは、ゲーム内で提供されるさまざまな種類のドラゴン エッグの属性と能力に基づいて、自分に適したドラゴン エッグの種類を慎重に選択する必要があります。 2. 孵化機のレベルをアップグレードします。プレイヤーはタスクを完了し、小道具を収集することで孵化機のレベルを向上させる必要があります。孵化機のレベルは孵化速度と孵化成功率を決定します。 3. プレイヤーはゲームに参加する必要がある孵化に必要なリソースを収集します。
 すぐにマスター: Huawei 携帯電話で 2 つの WeChat アカウントを開く方法が明らかに!
Mar 23, 2024 am 10:42 AM
すぐにマスター: Huawei 携帯電話で 2 つの WeChat アカウントを開く方法が明らかに!
Mar 23, 2024 am 10:42 AM
今日の社会において、携帯電話は私たちの生活に欠かせないものとなっています。私たちの日常のコミュニケーション、仕事、生活のための重要なツールとして、WeChat はよく使用されます。ただし、異なるトランザクションを処理する場合は 2 つの WeChat アカウントを分離する必要がある場合があり、そのためには携帯電話が 2 つの WeChat アカウントへの同時ログインをサポートする必要があります。有名な国内ブランドとして、ファーウェイの携帯電話は多くの人に使用されていますが、ファーウェイの携帯電話で 2 つの WeChat アカウントを開設する方法は何でしょうか?このメソッドの秘密を明らかにしましょう。まず、Huawei 携帯電話で 2 つの WeChat アカウントを同時に使用する必要があります。最も簡単な方法は次のとおりです。
 携帯電話の文字サイズの設定方法(携帯電話の文字サイズを簡単に調整できます)
May 07, 2024 pm 03:34 PM
携帯電話の文字サイズの設定方法(携帯電話の文字サイズを簡単に調整できます)
May 07, 2024 pm 03:34 PM
携帯電話が人々の日常生活において重要なツールになるにつれて、フォント サイズの設定は重要なパーソナライゼーション要件になりました。さまざまなユーザーのニーズを満たすために、この記事では、簡単な操作で携帯電話の使用体験を向上させ、携帯電話のフォントサイズを調整する方法を紹介します。携帯電話のフォント サイズを調整する必要があるのはなぜですか - フォント サイズを調整すると、テキストがより鮮明で読みやすくなります - さまざまな年齢のユーザーの読書ニーズに適しています - フォント サイズを使用すると、視力の悪いユーザーにとって便利です携帯電話システムの設定機能 - システム設定インターフェイスに入る方法 - 設定インターフェイスで「表示」オプションを見つけて入力します。 - 「フォント サイズ」オプションを見つけて、サードパーティでフォント サイズを調整します。アプリケーション - フォント サイズの調整をサポートするアプリケーションをダウンロードしてインストールします - アプリケーションを開いて、関連する設定インターフェイスに入ります - 個人に応じて
 Go言語のメソッドと機能の違いと応用シナリオの分析
Apr 04, 2024 am 09:24 AM
Go言語のメソッドと機能の違いと応用シナリオの分析
Apr 04, 2024 am 09:24 AM
Go 言語のメソッドと関数の違いは、構造との関連付けにあります。メソッドは構造に関連付けられ、構造データまたはメソッドを操作するために使用されます。関数は型に依存せず、一般的な操作を実行するために使用されます。
