

顔認識アルゴリズムとシステムに関する一般科学に関する 10,000 ワードの長文記事


顔認識の目標
2 つのポイントを要約すると、まず、同じ人を認識すると、どのような身分であっても、自分がその人であることがわかります。ステータスが変化します。 2 番目に、異なる人物を区別します。2 人は非常によく似ている、または両方とも化粧をしているかもしれませんが、ステータスがどのように変化しても、顔認識はこの 2 人が別人であることを認識できます。
顔認証自体は生体認証技術の一種であり、主に本人認証の手段を提供するものであり、精度という点では顔認証が最も優れているわけではありません。顔認識は、照明などの他の多くの条件の影響を受けます。顔認証は、一般にユーザーの協力をほとんど必要としないという利点があり、現在、コンピュータカメラ、携帯電話のビデオ入力装置、写真機器など、さまざまな場所の監視カメラが非常に普及しています。顔認証ができる。そのため、顔認証を導入する場合、新たな投資が非常に少なくて済むのがメリットです。
顔認識プロセス
顔認識のコアプロセスいわゆるコアプロセスとは、どのような種類の顔認識システムであっても、基本的にこのプロセスが存在することを意味します。まず、顔検出、第 2 ステップ、顔位置合わせ、第 3 ステップ、特徴抽出。これら 3 つのステップは、すべての写真に対して実行する必要があります。比較する場合は、抽出された特徴を比較し、2 つの顔が同じ顔に属するかどうかを判断します。同じ人。
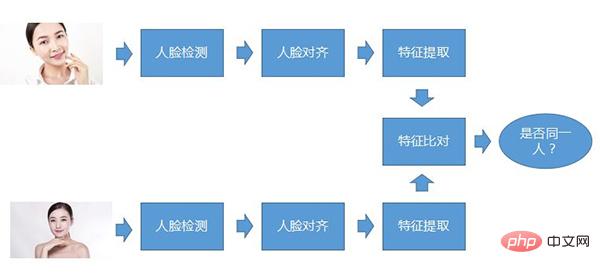
顔検出
顔検出とは、大きなシーンの中に顔があるかどうかを判断し、顔の位置を見つけて切り出すことです。 。これは物体検出技術の一種であり、顔認識タスク全体の基礎となります。顔検出の基本的な方法は、画像ピラミッド上でウィンドウをスライドさせ、分類子を使用して候補ウィンドウを選択し、回帰モデルを使用して位置を修正することです。
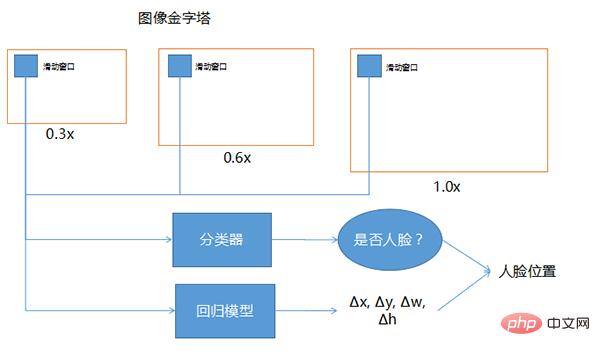
上図の 3 つのウィンドウは、0.3 倍、0.6 倍、1.0 倍であり、顔の位置が不確かで、サイズが特定できない場合に使用できる技術です。グラフ自体は異なるサイズになりますが、スライディング ウィンドウは同じサイズになります。ディープネットワークに入力される画像のサイズは一般的に固定されているため、前面のスライディングウィンドウは基本的に固定です。固定スライディング ウィンドウがさまざまな範囲をカバーできるようにするために、画像全体のサイズがさまざまな比率に拡大縮小されます。ここで示した 0.3、0.6、1.0 は単なる例であり、実際には他にもさまざまな倍数が使用されます。
分類子は、スライディング ウィンドウの各位置を調べて、それが顔であるかどうかを判断することを指します。これは、スライディング ウィンドウがスライドする位置に顔全体が含まれていない場合や、顔全体よりも大きい場合があるためです。 . .より正確な顔を見つけるために、回帰モデルにスライディング ウィンドウを挿入すると、顔検出の精度を修正するのに役立ちます。
入力はスライディングウィンドウで、出力時に顔が入っていた場合、どの方向をどれだけ補正する必要があるのか、つまりΔx、Δy、Δw、Δhはその座標とその座標です。幅と高さ、およそどのくらいの補正量か。補正量を求め、識別器を用いて人物の顔の窓であると判断した後、これらを組み合わせることで、より正確な人物の顔の位置を取得することができる。
以上は顔検出の処理ですが、他の物体検出にも応用できます。
顔検出の評価指標
機種を問わず、速度と精度に基づいています
1. 速度
(1) 速度は指定された解像度での検出速度です
スライディングウィンドウがスライドするため解像度は指定されています毎回各位置に到達するまでに分類と回帰判定を行う必要があるため、画像が大きくなると検出と判定に必要なウィンドウの数が多くなり、顔検出全体に時間がかかる場合があります。
したがって、アルゴリズムまたはモデルの品質を評価するには、固定解像度での検出速度を調べる必要があります。一般的に、検出速度はどれくらいですか? 100 ミリ秒、200 ミリ秒、50 ミリ秒、30 ミリ秒など、写真の顔を検出するのにかかる時間です。
速度を表すもう一つの方法にfpsというものがありますが、現在一般的なWebカメラは25fpsや30fpsのものが多く、これは1秒間に何枚の画像を処理できるかということを意味しており、fpsの利点を活かして顔検出が可能かどうかを判断することができます。リアルタイム検出を実現するには、顔検出の fps 数がカメラの fps 数より大きければリアルタイム検出が可能ですが、それ以外の場合はリアルタイム検出ができません。
(2) 同じ写真内の顔の数が速度に影響するかどうか
実際に操作してみると、主にスライドの数に影響されるため、ほとんどの面は影響を受けません。ウィンドウの数はヒット数に影響します。ヒット数はそれほど大きくありませんが、若干の影響があります。
2. 精度
精度は基本的に再現率、誤検出率、ROC 曲線によって決まります。再現率は写真のうち人間の顔であり、実際のモデルが人間の顔であると判断する割合を指します、誤検出率とネガティブサンプルエラー率は人間ではない写真の割合を指します顔だが人間の顔と誤認される。
ACC 精度
ACC の計算方法は、正しいサンプル数をサンプルの総数で割ることです。たとえば、顔検出のために 10,000 枚の写真を撮影した場合、 、これらの 10,000 写真には顔があるものもあれば、顔がないものもあります。次に、正しい比率を決定します。
しかし、この精度には問題があります。判定に使用する場合、陽性サンプルと陰性サンプルの比率は関係ありません。つまり、陽性サンプルの正答率は気にしません。そして、陰性サンプルの正解率ですが、それが何かというと、私が気にするのは合計だけです。このモデルの精度が 90% である場合、他の人は陽性サンプルと陰性サンプルの違いを知りません。分類を含め、回帰も含めて、一般的に言えば、分類モデルはまず回帰を使用して、いわゆる信頼水準を取得します。信頼水準が特定の値より大きい場合は、その信頼水準であるとみなされ、次に信頼水準が高くなった場合に、信頼水準が得られます。同じ値より小さい場合は、そうでないとみなします。
ACC 統計モデルは調整可能です。つまり、信頼水準を調整すると精度が変わります。
したがって、ACC 値自体はサンプルの割合に大きく影響されるため、モデルの品質を特徴付けるためにそれを使用するのは少し問題があります。テスト インジケーターが 99.9% に達したと表示した場合、単にこの値を見ると、だまされやすいか、この統計に偏りがあることがわかります。この問題を解決するために、一般に ROC と呼ばれる曲線がこのモデルの精度を特徴付けるために使用されます。
ROC 受信機動作特性曲線
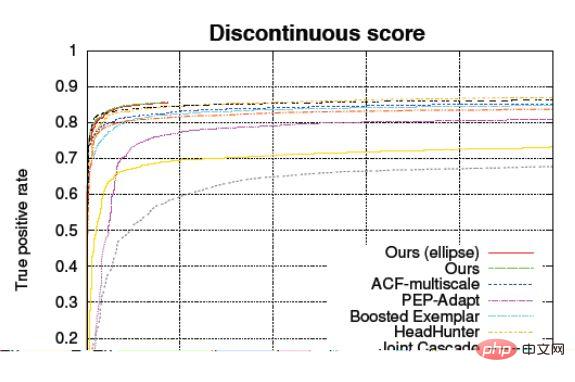
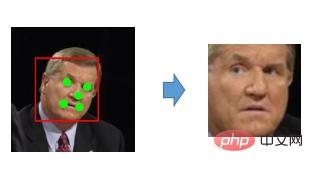
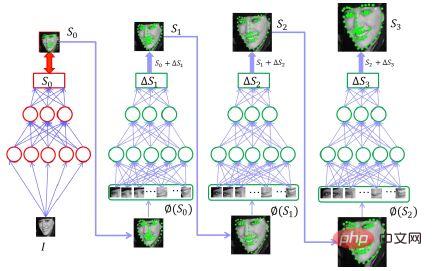
つまり、複数の入力が行われます。このネットワークへの最初の入力の後、推測が行われます。この推測は許容範囲内ですが、精度はそれほど高くありません。顔の 5 つの点がどこにあるかがおおよそわかります。次に、これら 5 つの点と元の画像を 2 番目のネットワークに入力して、おおよその補正量を取得します。基本的な 5 点を取得してから補正量を求めると、元の画像から直接正確な 5 点を見つけるよりも優れています。この点は少し簡単です。したがって、段階的に改良し、複数のネットワークをカスケード接続するこの方法を使用すると、速度と精度のより良いバランスを実現できます。実際、現在これを行うときは、基本的に 2 つのレイヤーを使用しており、ほぼ同じです。
顔特徴点抽出の評価指標
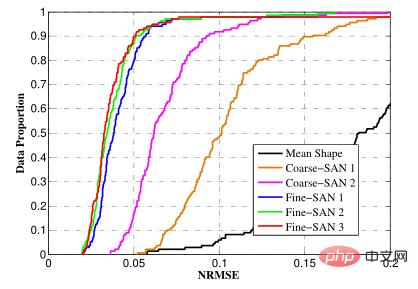
NRMSE(Normalized Root Mean Square Error)とは、正規化された二乗平均平方根誤差のことです
##各特徴点の座標とラベル付けされた座標の差を測定します。 精度異なるサイズの顔をまとめて相互に比較できるようにするために、統計的に正規化二乗平均平方根誤差と呼ばれるものが使用されます。たとえば、紙に 5 つの点を描き、これら 5 つの点の間の距離を機械に知らせます。指定された値が実際の距離に近いほど、予測の精度が高くなります。一般に、予測値には多少の誤差が生じますが、この精度の値をどのように表現するのでしょうか。通常、距離の平均値または二乗平均平方根値で表します。ただし、同じマシンが異なるサイズの画像を予測すると、画像が大きくなるほど誤差の絶対値が大きくなるため、精度の値が異なって見えるという問題が発生します。同じ原理が異なるサイズの面にも当てはまります。したがって、私たちの解決策は、人間の顔の元のサイズを考慮することです. 一般に、人間の目の間の距離または人間の顔の対角線の距離を分母として、距離の差を目の間の距離で割ります。または顔の対角線で割ると、この場合は基本的に顔の大きさによって変わらない値が得られ、評価に用いることができます。 顔の比較(1) 目的: 並んだ 2 つの顔が同じ人物のものかどうかを判断する(2) 難易度: 同一人物 顔の見え方が異なります。特に光、煙、化粧などの影響を受けるなど、さまざまな条件下での状態。 2 つ目は、2 次元の写真にマッピングされたさまざまなパラメータによって引き起こされます。いわゆる 2 次元のパラメータへのマッピングは、元の顔はこのように見えることを意味します。撮影装置が写真を撮るとき、写真が彼に提示する角度、彼との距離、ピントの正確さ、撮影角度、光の蓄積などが影響し、同じ顔でも違った状態に見えます。 3つ目は年齢や整形の影響です。 顔比較方法(1) 従来の方法
1. HOG、SIFT、ウェーブレット変換などのいくつかの特徴を手動で抽出します。つまり、抽出された特徴には固定パラメータが必要になる場合があり、トレーニングや学習は必要なく、特徴を比較するために一連の固定アルゴリズムが使用されます。(2) 深さ法
主流の方法は深さ法、つまりディープ畳み込みニューラル ネットワークであり、このネットワークは通常、以前のネットワークに代わって DCNN を使用します。それらの特徴抽出手法は、写真や顔からいくつかの異なる特徴を抽出するものです DCNN には多くのパラメータがあります これらのパラメータは人から教えられるのではなく学習されます 学習されれば、できるようになるのと同じになります人々が要約したものよりも優れています。 次に、取得された特徴セットは、一般的に 128 次元、256 次元、または 512 次元または 1024 次元を持ち、それらを比較して、特徴ベクトル間の距離を判断するには、ユークリッド距離またはコサイン類似度が一般的に使用されます。 。 顔比較の評価指標も速度と精度に分かれており、速度には単一の顔特徴ベクトルの計算時間と比較速度が含まれます。精度には ACC と ROC が含まれます。以前にも紹介しましたので、ここでは比較速度に焦点を当てます。 通常の比較は、2 点間の距離を計算する単純な操作です。内積 (2 つのベクトルの内積) を実行する必要があるのは 1 回だけですが、顔認識で 1 が検出された場合は次のようになります。 N 比較する場合、N データベースが非常に大きい場合、写真を取得して N データベースで検索すると、検索数が非常に多くなります。たとえば、N データベースが 100 万件の場合、検索が必要になる場合があります。 100万回ということは100万回の比較に相当しますが、現時点ではまだ合計時間の要件があるため、この比較を高速化するためのさまざまな技術が存在します。 その他の顔認識関連アルゴリズム主に顔追跡、品質評価、生体認識などがあります。 #●顔追跡監視やその他のビデオ顔認識シナリオでは、顔認識プロセス全体が、通り過ぎる同じ人物のフレームごとに実行されると、コンピューティング リソースを浪費するだけでなく、また、低品質のフレームによっては誤認識を引き起こす可能性があるため、どの顔が同一人物であるかを判断する必要があります。また、認識用に適切な写真を選択することで、モデルの全体的なパフォーマンスが大幅に向上します。現在では、顔追跡だけでなく、さまざまな物体追跡や車両追跡などでも追跡アルゴリズムが使用されていますが、そのようなアルゴリズムは検出に依存していないか、常に依存しているわけではありません。たとえば、最初にオブジェクトを検出した後は、それをまったく検出せず、追跡アルゴリズムのみを使用してオブジェクトを検出します。同時に、非常に高い精度を達成し、損失を回避するために、各追跡には多くの時間がかかります。
追跡された顔が顔認識器の範囲と一致しないことを防ぐために、一般的には顔検出器を使用して検出が行われますが、この検出方法は顔検出に依存しており、比較的軽量です。特定のシナリオでは速度と品質のバランスを実現できます。
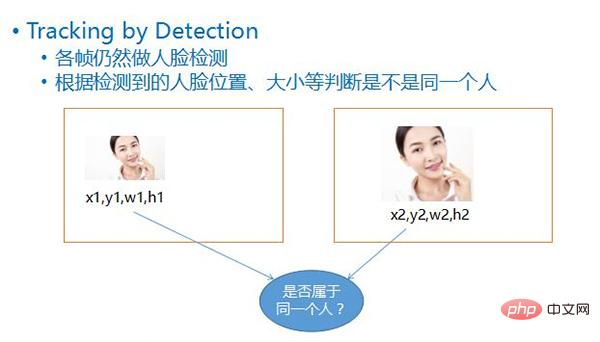
この検出方法は、Tracking by Detection (検出による追跡) と呼ばれ、フレームごとに顔検出が実行されます。顔が検出された後、4 つの値に基づいて、各顔の座標位置、その幅と高さ、前後の 2 つのフレームにおける顔の位置とサイズを比較することで、2 つの顔が同じ移動物体に属しているかどうかを大まかに推測できます。 。
# オプションの間隔全画面検出
は、検出による追跡を実行するときに参照します。1 つの方法は、前後 2 つのフレームで全画面検出を行う、いわゆるフルスクリーン検出です。画面検出 画面全体をスキャンすることですが、この方法は非常に時間がかかるため、数フレームごとに画面全体をスキャンする別の方法が使用されることもあります。一般的には、次のフレームを予測し、位置を検出しません。前のフレームであれば、フレームの位置を上下左右に少し拡大して再検出すると、高確率で検出できることが多く、ほとんどのフレームは検出できるスキップしました。
なぜ数フレームごとに全画面検出を行う必要があるのでしょうか?
は、新しいオブジェクトが入ってくるのを防ぐためです。前のオブジェクトの位置に基づいて検索するだけでは、新しいオブジェクトが入ってきたときに検出されない可能性があります。この状況を防ぐには、待機することができます。 5 フレーム、10 フレーム後にもう一度全画面検出を実行します。
# 顔品質評価
#顔認識トレーニング データなどの制限により、すべての状態の顔に対して良好な結果を得ることが不可能であるため、品質評価によって検出された人物を判断します。顔の特徴と認識装置との一致度に応じて、一致度の高い顔だけが選択されて認識に送信され、システムの全体的なパフォーマンスが向上します。
顔品質評価には以下の4つの要素が含まれます
① 顔の大きさ 小さすぎる顔が認識に選択されると、認識効果が大幅に低下します。
② 顔の姿勢とは 3 軸の回転角度を指し、一般に認識器の学習に使用されるデータに関係します。トレーニング中に姿勢の小さな顔をほとんど使用する場合、実際に認識を行う際には、たわみの大きい顔を選択しないことが最善です。そうしないと、適用できなくなります。
③ ぼかしの度合いは非常に重要で、写真の情報が失われていると認識に問題が生じます。
④ オクルージョンは、目や鼻などが覆われている場合、その部分の特徴が得られないか、得られたものが間違っている、オクルーダーの特徴であり、その後の影響に影響します。認識。 。遮蔽されていると判断できる場合は、破棄するか、認識モデルに含めないなどの特別な処理を実行します。
# 生体認識
#これは、すべての顔認識システムが遭遇する問題であり、顔だけが認識される場合、写真も騙される可能性があります。システムへの攻撃を防ぐために、これが本物の顔であるか偽の顔であるかを判断するためのいくつかの判断が行われます。
基本的に、現在 3 つの方法があります:
① 従来の動的認識 多くの銀行の現金引き出し機では、ユーザーにまばたきしたり、頭を向けたりするなど、ユーザーに何らかの協力を求める必要があります。これは、ユーザーがまばたきや首を回すことによって同じコーディネートをしたかどうかを判断するために使用されます。したがって、動的認識にはユーザーの多大な協力が必要になるため、ユーザーエクスペリエンスが少し悪くなるという問題があります。
② 静的認識とは、動作に基づいて判断するのではなく、写真自体に基づいて本物の顔か偽の顔かを判断することを意味します。これは、携帯電話やディスプレイ画面を使用して攻撃するなど、一般的に使用されている比較的便利な攻撃方法に基づいています。
この種のスクリーンの発光能力は、実際の照明条件下での人間の顔の発光能力とは異なります。たとえば、1,600万色の発光色を持つモニターでは、可視光の発光能力、つまり、すべて連続しており、すべての帯域を放射できます。したがって、このような画面を撮影すると、実際の自然環境での一次撮影と比較して、人間の目には多少の変化や不自然さがあるように見えます。この不自然さをトレーニング用のモデルに落とし込んだ後でも、この微妙な違いに基づいてそれが本当の顔であるかどうかを判断できます。
③ ステレオ認識。2台のカメラまたは深度情報付きカメラを使用すると、1つの画面で人物の3D画像化に相当する、カメラからの各撮影点の距離を知ることができます。撮影するには画面は平面でなければなりませんが、私はそれが平面であることを認識していますが、その平面は決して本物の人間ではありません。これは、3次元の認識手法を用いて平面を除外するというものです。
顔認証のシステム構成
まずは分類を行う 比較の観点からは1:1認識方式と1:N認識方式があり、比較対象の観点からは写真比較があるシステムとビデオ比較システム; 導入形態に応じて、プライベート導入、クラウド導入、またはモバイルデバイス導入があります。
写真 1:1 認識システム
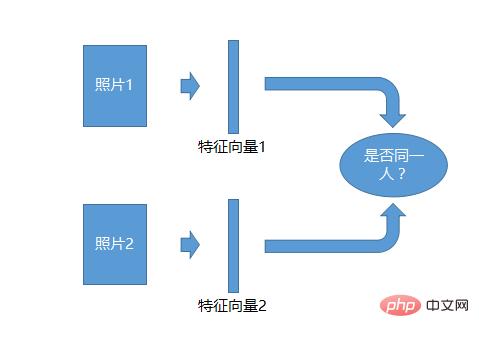
1:1 認識システムは最も単純です。2 枚の写真を撮り、各写真の特徴を生成します。ベクトル、次に、2 つの特徴ベクトルを比較して、それらが同一人物であるかどうかを確認し、識別できます。
写真 1: N の識別システム
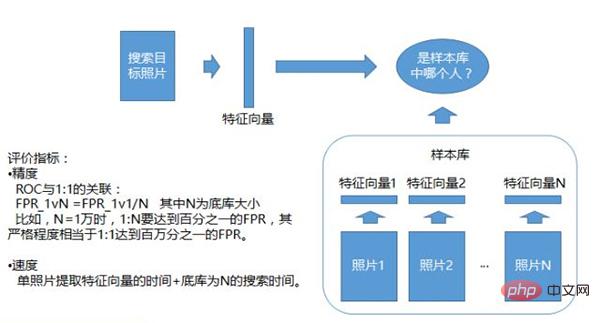
1: 写真素材がサンプル ライブラリにあるかどうかを判断する N の識別システム。このサンプル ライブラリはあらかじめ用意されており、ホワイトリストまたはブラックリストが含まれており、各人物の写真が含まれており、この写真から一連の特徴ベクトルが生成されます。これはサンプル ライブラリとして使用され、アップロードされた写真がサンプル ライブラリ内のすべての特徴と比較され、どれが人物に最も似ているかを確認する 1:N 認識システムです。
ビデオ 1:1 認識システム
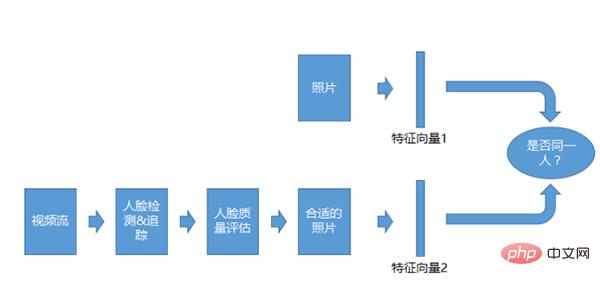
ビデオ 1:1 認識システムは写真の 1:1 システムと似ていますが、比較対象は異なります。写真だけでなく、ビデオ ストリームも。ビデオ ストリームを取得した後、検出、追跡、品質評価を行い、適切な写真を取得した後に比較します。
ビデオ 1: N 認識システム
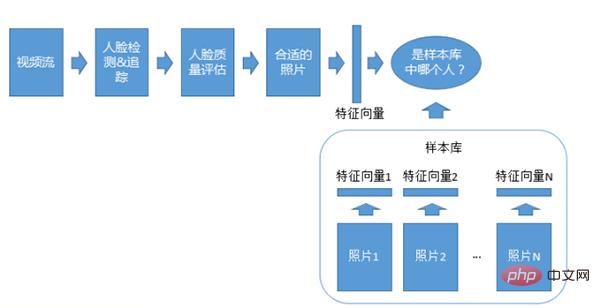
ビデオ 1: N アダプテーション システムは、認識に使用される点を除けば、1:N 写真システムと似ています。重要なのはビデオ ストリーミングであり、これには検出、追跡、品質評価も必要です。
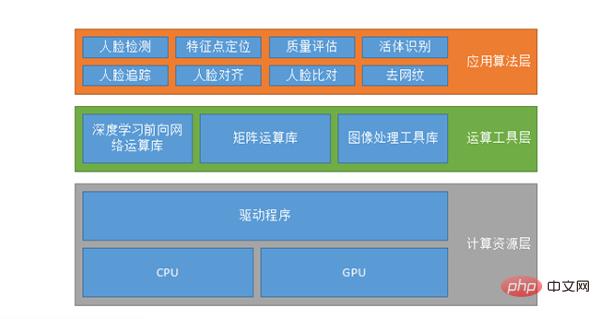
# 一般に、いわゆるシステム構成は必ずしも顔認証システムである必要はなく、さまざまな AI システムにも同様のことが考えられます。 1 つ目はコンピューティング リソース層で、CPU または GPU 上で実行されます。GPU 上で実行すると、CUDA、CUDN などもサポートされる場合があります。
2 つ目は、ディープ ラーニング フォワード ネットワーク コンピューティング ライブラリ、マトリックス コンピューティング ライブラリ、画像処理ツール ライブラリなどのコンピューティング ツール層です。アルゴリズムを作成する人全員が独自のデータ操作を記述することは不可能であるため、TensorFlow、MXNET、Caffe などの既存のデータ操作ライブラリを使用することも、独自のセットを記述することもできます。
以上が顔認識アルゴリズムとシステムに関する一般科学に関する 10,000 ワードの長文記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7457
7457
 15
1376
52
77
11
17
13
15
1376
52
77
11
17
13

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 DingTalk顔認証の入り方
Mar 05, 2024 am 08:46 AM
DingTalk顔認証の入り方
Mar 05, 2024 am 08:46 AM
インテリジェントなサービス ソフトウェアとして、DingTalk は学習や仕事において重要な役割を果たすだけでなく、その強力な機能を通じてユーザーの効率を向上させ、問題を解決することにも尽力しています。技術の継続的な進歩により、顔認識技術は徐々に私たちの日常生活や仕事に浸透してきました。それでは、DingTalk アプリを使用して顔認識入力を行う方法を以下に編集者が詳しく紹介します。さらに詳しく知りたいユーザーは、この記事の写真とテキストを参照してください。 DingTalk で顔を記録するにはどうすればよいですか?携帯電話で DingTalk ソフトウェアを開いた後、下部にある [ワークベンチ] をクリックし、[出席と時計] を見つけてクリックして開きます。 2. 次に、出席ページの右下の「設定」をクリックして入力し、設定ページの「私の設定」をクリックして切り替えます。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Apple フォンで顔認識をオフにする方法_Apple フォンの設定で顔認識を無効にする方法
Mar 23, 2024 pm 08:20 PM
Apple フォンで顔認識をオフにする方法_Apple フォンの設定で顔認識を無効にする方法
Mar 23, 2024 pm 08:20 PM
1. 寝る前に Siri に「これは誰の携帯電話ですか?」と尋ねることができます。Siri は顔認識を無効にするのに自動的に役立ちます。 2. 無効にしたくない場合は、Face ID をオンにして、[Face ID を有効にするには視線が必要] をオンにすることを選択できます。このようにすると、ロック画面は監視しているときにのみ開くことができます。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
