

GPTとの対話によるゼロサンプル情報抽出

特定のタスク向けにカスタマイズされた独自のモデルを汎用の大規模モデルに置き換えるという現在の傾向が徐々に現れており、このアプローチにより AI モデル アプリケーションの限界コストが大幅に削減されました。これにより次のような疑問が生じます: トレーニングなしでゼロサンプルの情報抽出を達成することは可能でしょうか?
情報抽出技術はナレッジ グラフを構築する上で重要な部分であり、まったくトレーニングなしで実装できれば、データ分析の敷居が大幅に下がり、次のような実現に役立ちます。自動化された知識、ライブラリの構築。
GPT-3.5のプロンプトエンジニアリング手法を用いて一般的なゼロサンプルIEシステムを構築します——GPT4IE(情報抽出用GPT) では、GPT3.5 では元の文章から構造化情報を自動的に抽出できることがわかりました。中国語と英語の両方をサポートしており、ツールコードはオープンソースです。
ツールの URL: https://cocacola-lab.github.io/GPT4IE/
コード: https://github.com/cocacola-lab/GPT4IE
#1 背景紹介
情報 目標抽出 (情報抽出、IE) は、非構造化テキストから構造化情報を抽出することです。これには、エンティティ関係トリプル抽出 (エンティティ関係抽出、RE)、固有表現認識 (固有表現認識、NER)、およびイベント抽出 (イベント抽出、EE) が含まれます。 ) [1][2][3][4][5]。多くの研究は、臨床 IE など、ゼロショット/少数ショットの作業を自動化するために IE テクノロジーに依存し始めています [6]。
最近、大規模な事前トレーニング済み言語モデル (LLM) は、ガイドとしてほんの数例を使用しただけでも、多くの下流タスクで非常に優れたパフォーマンスを発揮しています。少し調整するだけで達成できます。ここから、次のような疑問が生じます。プロンプトを通じてのみゼロサンプル IE タスクを実装することは可能ですか? プロンプト方式を使用して、GPT-3.5 - GPT4IE (情報抽出用 GPT) 用の一般的なゼロサンプル IE システムを構築しようとします。 GPT3.5とヒントを組み合わせることで、元の文章から構造化情報を自動的に抽出できます。
2 技術フレームワーク
タスク指定のプロンプト テンプレートを設計し、そのテンプレートにユーザー入力を入力します。 特定のスロット値 (スロット)プロンプト (プロンプト) を形成します。これは GPT-3.5 に入力され、IE で使用されます。 RE、NER、EE の 3 つのタスクがサポートされており、3 つのタスクはすべて中国語と英語のバイリンガルです。ユーザーは文を入力し、抽出タイプのリスト (つまり、関係リスト、先頭エンティティ リスト、末尾エンティティ リスト、エンティティ タイプ リスト、またはイベント リスト) を作成する必要があります。詳細は次のとおりです。
RE タスク の目標は、テキストから「(中国、首都、北京)」などのトリプルを抽出することです。 「(「如懿「伝記」、主演、周迅)」。必須の入力形式は次のとおりです (「*」が付いた項目は必須ではないフィールドを表します。これらのオプションにはデフォルト値を設定していますが、柔軟性を高めるために、ユーザー定義の指定リストをサポートしています。以下同様):
- 入力文: 入力テキスト
- 関係タイプ リスト (rtl)* : ['関係タイプ 1'、'関係タイプ 2' , ...]
- 件名タイプ リスト (stl)* : ['ヘッダー エンティティ タイプ 1', 'ヘッダー エンティティ タイプ 2', ...]
- オブジェクト タイプ リスト (otl)* : ['末尾エンティティ タイプ 1', '末尾エンティティ タイプ 2', ...]
- OpenAI API キー: OpenAI API キー (利用可能なキーの一部は、使用例として Github で提供されています。)
NER タスクは、テキストからエンティティを抽出するように設計されています。 「(LOC、北京)」、「(キャラクター、周恩来)」など。 NER タスクでの入力形式は次のとおりです。
- 入力文: 入力テキスト
- エンティティ タイプ リスト (etl) * : [ 'エンティティ タイプ 1', 'エンティティ タイプ 2', ...]
- OpenAI API キー: OpenAI API キー
EE タスクは、「{人生-離婚: {人物: ボブ、時刻: 今日、場所: アメリカ}}」、「{コンテスト行動-プロモーション: {時間 : なし、プロモーション側: ノースウェスト ウルブズ、プロモーション イベント: 中国プレミア リーグのトップの座を巡る戦い}}」入力形式は次のとおりです:
- 入力文: 入力テキスト
- イベント タイプ リスト (etl)* : {'イベント タイプ 1': ['引数の役割 1', ' 引数ロール 2', ...], ...}
- OpenAI API キー: OpenAI API キー
3 ツールの使用例
##3.1 RE 例 1
#入力:
入力文 : Bob は、中国の首都、北京の Google で働いていました。
rtl: [ 'location-located_in '、'行政区画-国'、'人-居住地'、'個人-会社'、'個人-国籍'、'会社設立者'、'国-行政区画'、'個人-子供'、'国 -首都'、 'deeased_person-place_of_death', 'neighborhood-neighborhood_of', 'person-place_of_birth']
stl: ['organization', 'person' , 'location' 、'国']
otl: ['個人', '場所', '国', '組織', '都市']
出力:

##3.2 RE 例 2入力文:
「如懿の宮廷愛」は、王軍監督、周迅、霍建華、張俊寧、董傑主演の古代衣装宮殿の感情的なテレビ シリーズです。 、シン・ジレイ、トン・ヤオ、リー・チュン、ウー・ジュンメイなど。
rtl: [「アルバム」、「設立年月日」、「標高」、「公用語」、「地域」、「父親」、「歌手」 '、'プロデューサー'、'監督'、'資本金'、'主演'、'会長'、'先祖代々の家'、'妻'、'母親'、'気候'、'地域'、'主人公'、'郵便番号'、'略称'、'制作会社'、'資本金'、'脚本家'、'創立者'、'出身校'、'国籍'、'職業コード'、'王朝'、'作者'、'歌詞'、 「都市」、「ゲスト」、「本社所在地」、「人口」、「広報担当者」、「原作者」、「校長」、「夫」、「司会者」、「テーマソング」、「学習年数」、 「構成」、「ナンバー」、「公開時期」、「興行収入」、「演技」、「吹き替え」、「受賞歴」]
# #stl: [「国」、「行政地域」、「文学作品」、「登場人物」、「映画・テレビ作品」、「学校」、「書籍作品」、「場所」、「歴史上の人物」、「観光スポット」、 '歌」、「専攻分野」、「企業」、「TV バラエティ番組」、「機関」、「企業/ブランド」、「エンターテイメント人物」]
otl: [「国」、「人」、「テキスト」、「日付」、「場所」、「気候」、「都市」、「曲」、「企業」、「番号」、「音楽アルバム」、「学校」 、「仕事」、「言語」]出力:
3.3 NER 例 1

入力: 入力文 : ボブは中国の首都北京の Google で働いていました。
etl
: ['LOC', 'MISC', 'ORG', ' PER'] 出力:
## 3.4 NER の例 2

入力文: 過去 5 年間、鄧小平理論の指導の下、志公党は社会主義の初段階段階の基本路線に従い、政策の実施に懸命に取り組んできました。志公党第10回全国代表大会で提案された党活動への参加と自己建設の強化という基本的課題。 etl: ['組織', '場所', '人'] 出力: 
3.5 EE 例 1
入力:
入力文: 昨日、ボブと彼の妻は広州で離婚しました。
# #etl : {'人事:選出': ['人物', 'エンティティ', '役職', '時刻', '場所'], '事業:破産宣告': ['組織', '時刻 ', '場所']、'正義:逮捕-刑務所': ['人', '代理人', '犯罪', '時間', '場所'], '人生:離婚': ['人', '時間', '場所']、'生命:傷害': ['エージェント'、'被害者'、'楽器'、'時間'、'場所']}
出力:

##3.6 EE 例 2
入力:
入力文:: 2022 年カタール ワールドカップ決勝では、アルゼンチンが PK 戦でフランスを辛くも破りました。
etl: {'組織行動-ストライキ': ['時間', '所属', 'ストライキ参加者の数', 'ストライキ要員'], '競争行為 - プロモーション': ['時間'、'プロモーション パーティー'、'プロモーション イベント']、'財務/トレーディング-在庫制限': ['時間'、'在庫制限']、'組織関係 - 解雇': [ ' 時間'、'解雇パーティー'、'解雇された人']}
出力:

3.7 EE 例 3 (興味深いエラーの例)
入力:
入力文:: 私は今日彼と離婚しました
##etl: {'組織行動ストライキ': [ '時間', '組織', 'ストライカーの数', 'ストライカー'], '競争行為-プロモーション': ['時間', 'プロモーションパーティー', 'プロモーションイベント'], '財務/取引-上限':['時間', '在庫制限'] , '組織関係 - 解雇': ['時間', '解雇当事者', '解雇された従業員']}出力:

#
以上がGPTとの対話によるゼロサンプル情報抽出の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Microsoft Word で作成者と最終変更情報を削除する方法
Apr 15, 2023 am 11:43 AM
Microsoft Word で作成者と最終変更情報を削除する方法
Apr 15, 2023 am 11:43 AM
Microsoft Word ドキュメントには、保存時にいくつかのメタデータが含まれます。これらの詳細は、作成日、作成者、変更日など、ドキュメントの識別に使用されます。文字数、単語数、段落数などの他の情報もあります。他の人に値が知られないよう、作成者や最終更新情報、その他の情報を削除したい場合は、方法があります。この記事では、ドキュメントの作成者と最終変更情報を削除する方法を見てみましょう。 Microsoft Word 文書から作成者と最終変更情報を削除する ステップ 1 – 次のページに移動します。
 Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
人工知能と機械学習テクノロジーが発展し続ける中、企業や組織はこれらのテクノロジーを活用して競争力を強化するための革新的な戦略を積極的に模索し始めています。 K8sGPT[2] は、この分野で最も強力なツールの 1 つであり、k8s オーケストレーションの利点と GPT モデルの優れた自然言語処理機能を組み合わせた k8s ベースの GPT モデルです。 K8sGPT とは何ですか? まず例を見てみましょう: K8sGPT 公式 Web サイトによると: K8sgpt は、Kubernetes クラスターの問題をスキャン、診断、分類するために設計されたツールであり、SRE の経験を分析エンジンに統合して、最も関連性の高い情報を提供します。人工知能技術の応用を通じて、K8sgpt はコンテンツを充実させ続け、ユーザーがより迅速かつ正確に理解できるように支援します。
 win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 オペレーティング システムを使用している場合、システムを再インストールしてハードディスクをパーティション分割する必要がある状況に遭遇することがあります。 win7 のハードディスク フォーマットに mbr と gpt のどちらが必要かという問題については、編集者は依然として独自のシステムとハードウェア構成の詳細に基づいて選択する必要があると考えています。互換性の観点から、mbr 形式を選択するのが最善です。詳細については、エディターがどのように実行したかを見てみましょう~ Win7 ハードディスク フォーマットには mbr または gpt1 が必要です。システムが Win7 でインストールされている場合は、互換性の良い MBR を使用することをお勧めします。 2. 3T を超える場合、または win8 をインストールする場合は、GPT を使用できます。 3. 確かに GPT は MBR よりも高度ですが、互換性の点では MBR は間違いなく無敵です。 GPT および MBR 領域
 Windows 11 で GPU を取得し、グラフィックス カードの詳細を確認する方法
Nov 07, 2023 am 11:21 AM
Windows 11 で GPU を取得し、グラフィックス カードの詳細を確認する方法
Nov 07, 2023 am 11:21 AM
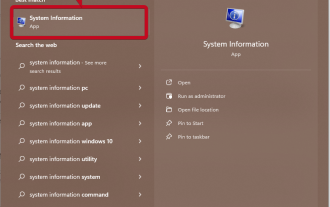
システム情報の使用 [スタート] をクリックし、システム情報を入力します。下の画像に示すようにプログラムをクリックするだけです。ここではほとんどのシステム情報が見つかりますが、グラフィック カード情報も見つかります。システム情報プログラムで、「コンポーネント」を展開し、「表示」をクリックします。プログラムに必要な情報をすべて収集させ、準備が完了すると、システム上でグラフィックス カード固有の名前やその他の情報を見つけることができます。複数のグラフィックス カードをお持ちの場合でも、コンピュータに接続されている専用および統合グラフィックス カードに関連するほとんどのコンテンツをここから見つけることができます。デバイス マネージャーの使用 Windows 11 他のほとんどのバージョンの Windows と同様に、デバイス マネージャーからコンピューター上のグラフィック カードを見つけることもできます。 「開始」をクリックしてから、
 Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
独自のシステムをパーティション分割する場合、ユーザーが使用するハードドライブが異なるため、多くのユーザーは win10 パーティション形式が gpt か mbr のどちらであるかを知りません。このため、これらの違いを理解するのに役立つ詳細な紹介を提供しました。二。 Win10 パーティション形式 gpt または mbr: 回答: 3 TB を超えるハード ドライブを使用している場合は、gpt を使用できます。 gpt は mbr よりも高度ですが、互換性の点では mbr の方がまだ優れています。もちろん、ユーザーの好みに応じて選択することもできます。 gpt と mbr の違い: 1. サポートされるパーティションの数: 1. MBR は最大 4 つのプライマリ パーティションをサポートします。 2. GPT はパーティションの数によって制限されません。 2. サポートされるハードドライブのサイズ: 1. MBR は最大 2TB までのみサポートします
 コンピューターのハードドライブが GPT または MBR のどちらのパーティション分割方法を使用しているかを確認する方法
Dec 25, 2023 pm 10:57 PM
コンピューターのハードドライブが GPT または MBR のどちらのパーティション分割方法を使用しているかを確認する方法
Dec 25, 2023 pm 10:57 PM
コンピュータのハードディスクが GPT パーティションか MBR パーティションかを確認するにはどうすればよいですか? コンピュータのハードディスクを使用するとき、GPT と MBR を区別する必要があります。実際、この確認方法は非常に簡単です。一緒に見てみましょう。コンピュータのハードドライブが GPT または MBR であることを確認する方法 1. デスクトップのコンピュータを右クリックし、[管理] をクリックします。 2. [管理] で [ディスクの管理] を見つけます。 3. ディスクの管理に入り、ディスクの一般的なステータスを確認します。 4. 「プロパティ」の「ボリューム」タブに切り替えると、「ディスク パーティション フォーム」が表示されます。 「MBR パーティション win10 ディスクに関連する問題 MBR パーティションを GPT パーティションに変換する方法 >」として表示されます。
 NameDrop で連絡先の詳細を共有する方法: iOS 17 のハウツー ガイド
Sep 16, 2023 pm 06:09 PM
NameDrop で連絡先の詳細を共有する方法: iOS 17 のハウツー ガイド
Sep 16, 2023 pm 06:09 PM
iOS 17には、2台のiPhoneをタッチすることで誰かと連絡先情報を交換できる新しいAirDrop機能があります。これは NameDrop と呼ばれるもので、その仕組みは次のとおりです。 NameDrop を使用すると、新しい相手の電話番号を入力して電話したりテキストメッセージを送信したりする代わりに、iPhone を相手の iPhone の近くに置くだけで連絡先の詳細を交換できるため、相手はあなたの番号を知ることができます。 2 つのデバイスを組み合わせると、連絡先共有インターフェイスが自動的にポップアップ表示されます。ポップアップをクリックすると、個人の連絡先情報と連絡先ポスターが表示されます(自分の写真をカスタマイズして編集できます。これも iOS17 の新機能です)。この画面には、「受信のみ」するか、応答として自分の連絡先情報を共有するかのオプションも含まれています。
 シングルビュー NeRF アルゴリズム S^3-NeRF は、マルチイルミネーション情報を使用してシーンのジオメトリとマテリアル情報を復元します。
Apr 13, 2023 am 10:58 AM
シングルビュー NeRF アルゴリズム S^3-NeRF は、マルチイルミネーション情報を使用してシーンのジオメトリとマテリアル情報を復元します。
Apr 13, 2023 am 10:58 AM
現在の画像 3D 再構成作業では、通常、一定の自然光条件下で複数の視点 (マルチビュー) からターゲット シーンをキャプチャする多視点ステレオ再構成手法 (マルチビュー ステレオ) が使用されます。ただし、これらの方法は通常、ランバート曲面を前提としており、高周波の詳細を復元するのが困難です。シーン再構築のもう 1 つのアプローチは、固定視点から異なる点光源でキャプチャされた画像を利用することです。たとえば、フォトメトリック ステレオ法では、この設定を採用し、そのシェーディング情報を使用して、非ランバーシアン オブジェクトの表面の詳細を再構成します。ただし、既存のシングルビュー手法は通常、可視領域を表現するために法線マップまたは深度マップを使用します。
