


個々の株式の資金の流れをクローリングする上記の例を通じて、独自のクローリング コードの作成方法を学習できるはずです。次に、それを統合して、同様の小さな演習を実行します。オンラインセクターの資金の流れをクロールするには、独自の Python プログラムを作成する必要があります。クロールされた URL は http://data.eastmoney.com/bkzj/hy.html で、表示インターフェイスは図 1 に示されています。
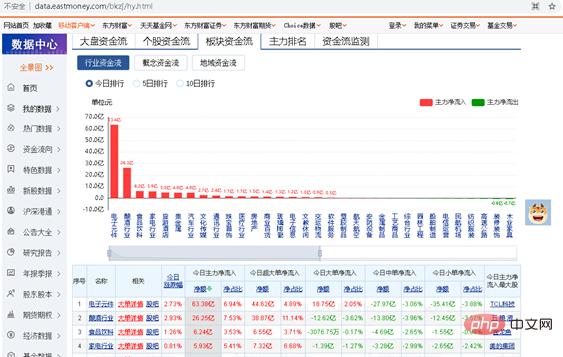
# 図 1 教員ストリーム URL インターフェイス
# F12 キーを直接押して、開発コミッショニングを開きますツールを使用してデータを検索します。対応する Web ページを図 2 に示します。
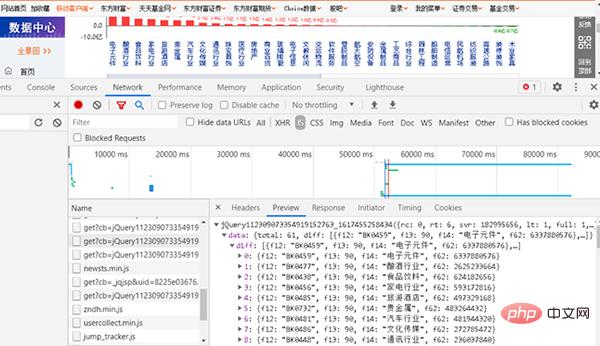
図 2 JS
に対応する Web ページを見つけて、ブラウザに URL を入力します。URL は比較的長いです。
http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_1617455258434&pn=1&pz=500&po=1&np=1&fields=f12,f13,f14,f62&fid=f62&fs=m:9 0 + t:2&ut=b2884a393a59ad64002292a3e90d46a5&_=1617455258435
この時点で、図 3 に示すように、Web サイトからフィードバックを受け取ります。

図 3 Web サイトからのセクションと資金フローの取得
この URL に対応するコンテンツが、クロールするコンテンツです。
クローラー コードを記述します。詳細については、次のコードを参照してください。
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
r.status_code には 200 が表示され、レスポンス ステータスが示されていることを示します。は普通。図 4 に示すように、r.text には資本フロー データのクロールが成功したことを示すデータもあります。
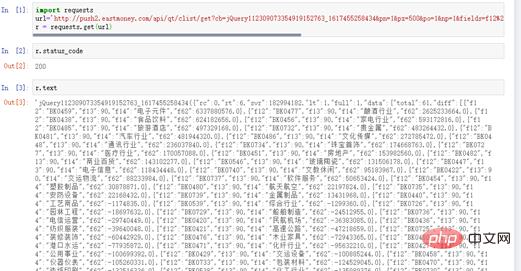
図 4 応答ステータス
(1) r.text データを分析します。その内部形式は標準の JSON ですが、先頭にいくつかの追加のプレフィックスが付いています。 jQ プレフィックスを削除し、split() 関数を使用してこの操作を完了します。詳細については、次のコードを参照してください。
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_text実行結果を図 5 に示します。

r_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_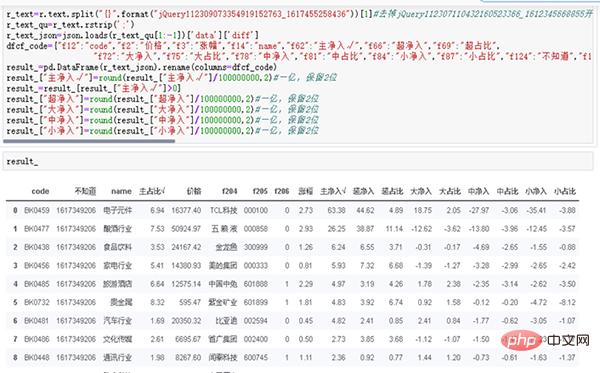 上記の 2 つのファンド クローリングの例を通じて、クローラの使用方法の一部を理解できたはずです。核となるアイデアは次のとおりです:
上記の 2 つのファンド クローリングの例を通じて、クローラの使用方法の一部を理解できたはずです。核となるアイデアは次のとおりです:
(1) 個別銘柄の資金の流れの利点を選択する;
(3) 利用するデータを収集するクローラ データを取得して保存します。
図 6 データの保存概要JSON 形式のデータは、多くの Web サイトで使用されている標準化されたデータ形式の 1 つです。 Exchange フォーマットは読み書きが非常に簡単で、ネットワーク伝送効率を効果的に向上させることができます。最初にクロールされるのはstr形式の文字列で、データ加工を経て標準のJSON形式、さらにPandas形式となります。ケース分析と実際の戦闘を通じて、財務データをクロールする独自のコードを作成し、それを JSON 標準形式に変換する能力を習得する必要があります。日々のデータ クローリングとデータ ストレージ作業を完了して、将来のデータの履歴テストと履歴分析に効果的なデータ サポートを提供します。
もちろん、有能な読者であれば、MySQL、MongoDB、さらにはクラウド データベース Mongo Atlas などのデータベースに結果を保存できますが、ここでは説明に重点を置きません。私たちは定量的な学習と戦略の研究に完全に焦点を当てています。 txt 形式を使用してデータを保存すると、初期のデータ保存の問題を完全に解決でき、データも完全かつ効果的になります。
以上がセクターの資金の流れをクロールする Python プログラムを作成するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



