

ハッシュとハッシュは両方ともハッシュという単語に由来しており、前者は音訳、後者は意訳です。任意の長さのバイナリ値を固定長のバイナリ値にマッピングできるアルゴリズムで、マッピングされた固定長のバイナリ値をハッシュ値と呼びます。優れたハッシュ アルゴリズムは次の要件を満たす必要があります:
はハッシュ値から元のデータを逆に推定できない;
は入力データの影響を非常に受けやすく、ビットが異なるとハッシュが発生します。ハッシュ値は大きく異なります;
ハッシュ競合の可能性は非常に小さくなければなりません;
ハッシュ アルゴリズムの計算プロセスは単純かつ十分に効率的でなければなりません。元のデータは非常に長いため、ハッシュ値をすぐに取得できます ハッシュ値;
より一般的なハッシュ暗号化アルゴリズムMD5 (MD5 Message-Digest Algorithm、MD5 メッセージ ダイジェスト アルゴリズム) と SHA (Secure Hash Algorithm、セキュア ハッシュ アルゴリズム) です。
ハッシュ値暗号文からは平文パスワードが推定できないこと、ハッシュ衝突の可能性が比較的低いこと、この2点によりハッシュアルゴリズムは安全な暗号化方式としての信頼性が確保されています。
なぜハッシュ アルゴリズムはハッシュの競合を完全に回避することはできず、ハッシュの競合を最小限に抑えることしかできないのですか?
鳩の巣の原則は、11 羽の鳩が 10 の鳩かごに飛ぶ場合、1 つの鳩かごには 2 羽以上の鳩がなければならないことを示しています。この場合、ハッシュ値は固定長であるため、ハッシュ値を使い果たすことができると判断されますが、理論上、元のデータは無限であるため、ハッシュの競合が発生する可能性があります。
このアプリケーション シナリオでは、ハッシュ アルゴリズムの特性 1 と 3 を使用します。このうち 3 は、パスワードが順方向に解読されるのが非常に困難であることを保証します (MD5 を例にとると、ハッシュ値の長さは128 ビット、2 ^128 の異なるハッシュがあり、解読するのは非常に困難です)。
セキュリティ分野に絶対的なセキュリティはありません。MD5 を解読するのは困難ですが、それを解読する方法はまだあります。たとえば、レインボー テーブル マッチングを使用すると、一般的なパスワードを簡単に解読できます。
したがって、一般的に、安全な暗号化にはソルテッド ハッシュ アルゴリズムを使用します。ソルティング方法は厳重に機密に保つ必要があり、クラッキングの難易度とコストが大幅に増加します。
2つのファイルが同一かどうかを検証する場合、単純にファイル名だけでは判断できません。同じ名前のファイルが存在することがあまりにも一般的であるためです。
特定のルールに従って大きなファイルからバイナリ データを取得し、ハッシュ アルゴリズムを使用してファイルの一意の識別子としてハッシュ値を取得できます。このように、同じファイルは同じハッシュ値、つまり同じ一意の識別子を持つ必要があります。異なるファイルは異なるハッシュ値の一意の識別子を持つ可能性が高くなります。
たとえ本当に散在する If に遭遇したとしても列の競合がある場合は、2 つのファイルのすべてのバイナリ データを詳細に比較して、それらが同じファイルであるかどうかをさらに判断できますが、このイベントが発生する確率は非常に低いです。ただし、このソリューションでは効率と信頼性の両方が保証されます。
このアプリケーション シナリオでは、ハッシュ アルゴリズムの機能 2 と 3 を使用します。
P2P ダウンロード プロトコルでは、同じムービーの異なる部分を異なるマシンからダウンロードし、自分のマシン上でムービーを組み立てます。動画の一部のダウンロード処理にエラーが発生したり、コンテンツが改ざんされたりすると、ダウンロードエラーやウイルスの原因となる可能性があります。
したがって、最初にすべての部分に対してハッシュ計算を実行し、シード ファイルに保存します。すべてのパーツがダウンロードされたら、すべてのパーツをハッシュしてハッシュ値を取得し、それをシード ファイル内のハッシュ値と比較して、ファイルが完全であるかどうかを確認します。
このアプリケーション シナリオでは、ハッシュ アルゴリズムの機能 2 と 4 を使用します。
このシナリオは、ハッシュ テーブルについて説明するときに以前に紹介されました。このシナリオでは、機能 1 の要件はそれほど高くありません。機能 2 の要件は、ハッシュ値が可能な限り均等に分散されることです。機能 3 は、ある程度の競合を許容することもできます。これは次のように解決できます。オープンアドレッシング方式とジッパー方式を使用し、機能4はより要求が厳しく、パフォーマンスを追求する必要があります。
ポーリング、ランダム、加重ポーリングなど、多くの負荷分散アルゴリズムがありますが、目標は、セッション固定負荷分散アルゴリズムを実装することです。同じ セッション中のすべてのクライアント要求は同じサーバーにルーティングされます。
クライアントの IP またはセッション ID をハッシュし、ハッシュ値とサーバーの数に対してモジュロ演算を実行できます。最終的な値は、ルーティングが必要なサーバーであるため、セッションの持続性を実現できます。目的停滞の。
大量のデータを処理する必要がある場合、単一のサーバーではそのような大量のデータを読み込んで計算することはできません。その場合、大量のデータを N 台のサーバーに均等に分散する必要があります。サーバーは並列実行します。データを N 個のサーバーに均等に分散するにはどうすればよいですか?
データに対してハッシュ計算を実行し、取得したハッシュ値をサーバー数 N で割って使用します。同じ結果のデータは同じサーバーに割り当てられ、このサーバーに渡されて処理されます。 N 台のサーバーが大量のデータを並列処理し、最終的に結果をマージします。
大量のデータを分散キャッシュまたは分散データベースに保存する借用の考え方は、上記のデータ シャーディングと似ています。しかし、最初に設定したサーバーの数が足りない場合はどうすればよいでしょうか。
この問題は、マシンを数台追加するだけでは解決できません。これにより、ハッシュ値のモジュロ演算が破壊され、キャッシュの侵入が発生し、雪崩現象が発生します。同様に、マシンの障害が解消されたときにも同じ問題が発生する可能性があります。現時点では、この問題を解決するには一貫したハッシュ アルゴリズムを使用する必要があります。
一貫性のあるハッシュ アルゴリズムは、リング上に 2^32 のノードを含むハッシュ リングを構築し、サーバー IP とファイルを対応するノードにハッシュするだけです。すべてのファイルが時計回りに最初に遭遇するサーバーが、ファイルが保存されているサーバーです。このようにして、サーバーが追加または削除されたときに、影響を受けるファイルの数を制御でき、グローバルな雪崩を引き起こすことはありません。
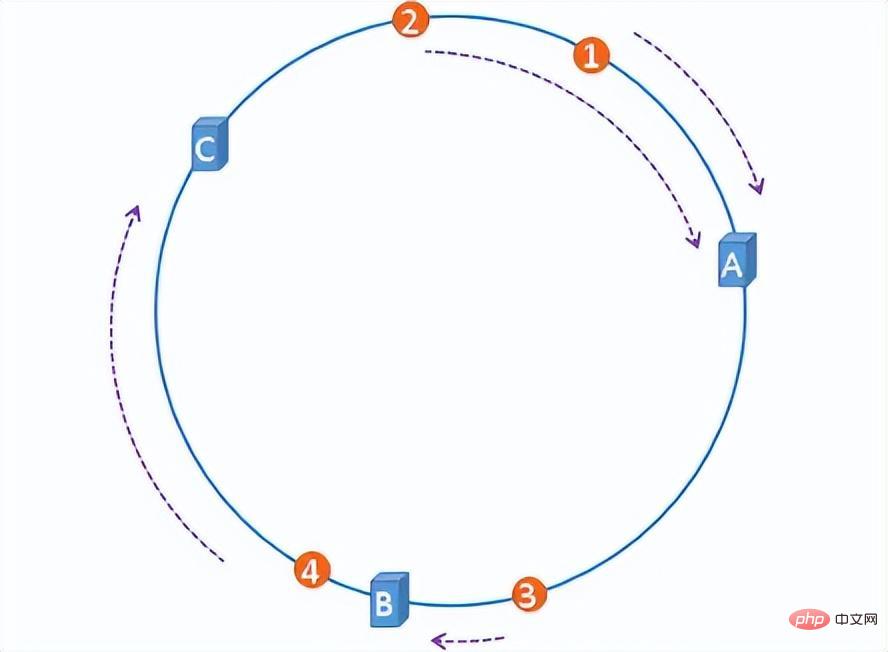
ハッシュリング
しかし、サーバーIPがハッシュリングにマッピングされると、一定の確率でハッシュリングスキューの問題が発生します。これにより、サーバー上のファイルの分散が非常に不均一になり、最初にサーバーを追加または削除するときに簡単に雪崩現象が発生するシナリオに陥ります。
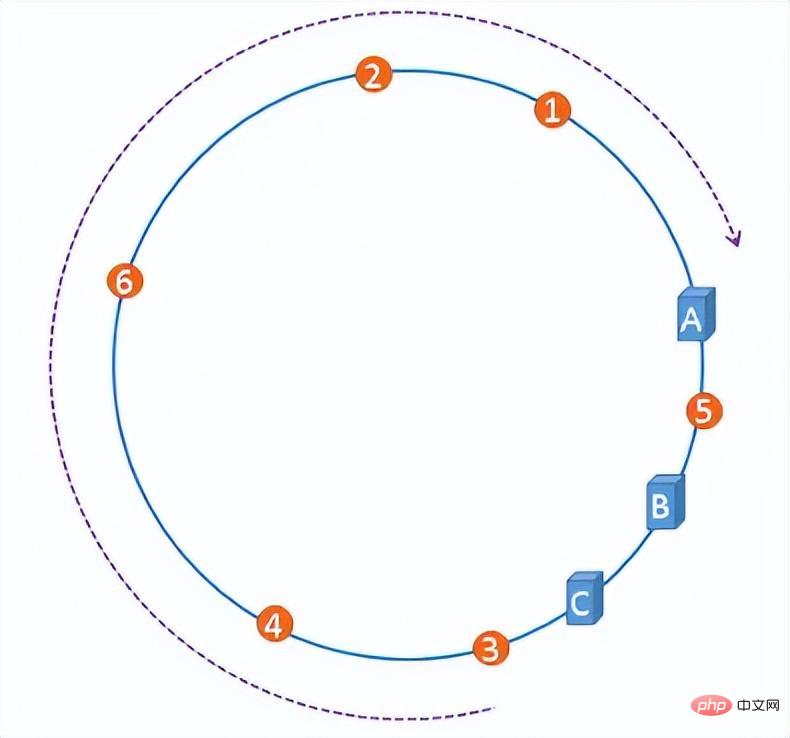
ハッシュ リングの歪度
これらのサーバーに多数の仮想ノードを人為的に追加して、すべてのサーバー ノードがハッシュ上に均等に分散されるようにすることができます。指輪。
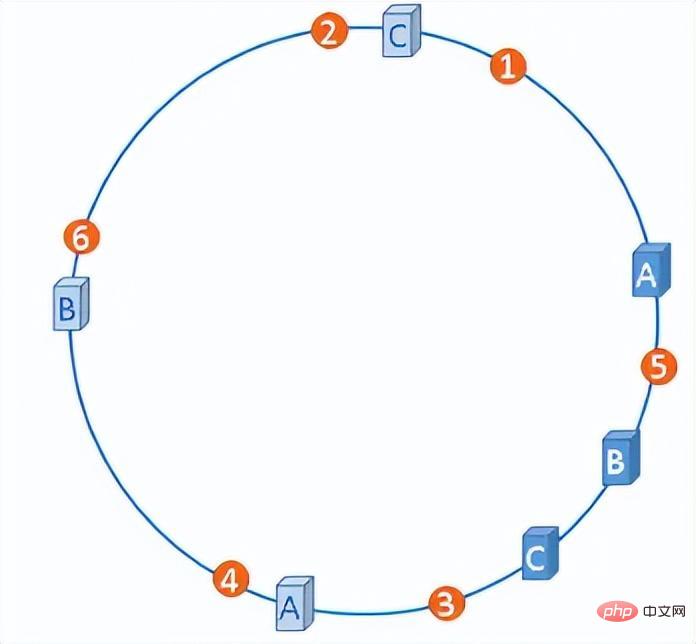
仮想ノードを使用したハッシュ リング
ハッシュ アルゴリズムの使用シナリオは上記以外にも多数あります。 CRCチェックなども。
以上がハッシュ アルゴリズムとアプリケーション シナリオを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



