

時系列予測におけるトランスフォーマーの衰退と時系列埋め込み手法の台頭、さらに異常検出と分類も進歩しました
2022年には、この分野全体がいくつかの異なる側面で進歩しました。この記事では、過去 1 年ほどの間に発表された、より有望で重要な論文のいくつかと、Flow Forecast (FF) 予測フレームワークについて取り上げます。

https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
トランスフォーマー関連の研究では、オートフォーマー、パイラフォーマー、フェドフォーマーなどの効果と問題点を比較しています
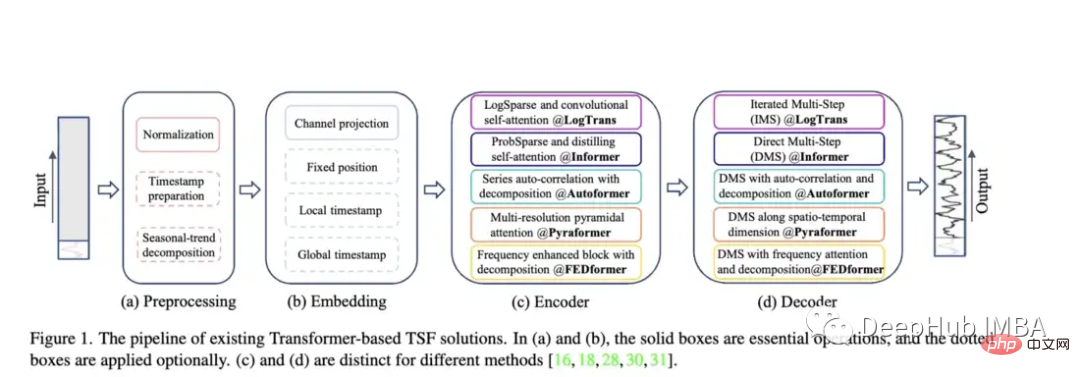
Autoformer (Neurips 2021)、Pyraformer (ICLR 2022)、Fedformer (ICML 2022)、EarthFormer (Neurips 2022)、Non-Stationary Transformer (Neurips) などのモデルの登場により、時系列予測アーキテクチャの Transformer ファミリは成長を続けています)。しかし、特に新しい研究 (後で説明します) を考慮すると、これらのモデルがデータを正確に予測し、既存の手法を上回るパフォーマンスを発揮できるかどうかは依然として疑問です。
Autoformer: Informer モデルのパフォーマンスが拡張および向上しました。 Autoformer は、モデルが標準的な注意よりも時間的な依存関係を学習できるようにする自動相関メカニズムを備えています。時系列データの傾向と季節成分を正確に分解することを目的としています。
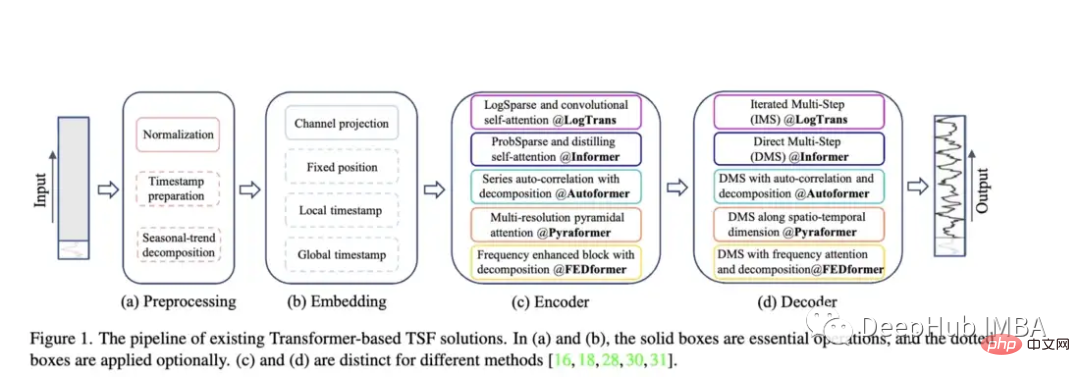
Pyraformer: 著者は「ピラミッド アテンション モジュール (PAM)」を紹介します。このモジュールでは、スケール間のツリー構造がさまざまな解像度での特徴を要約し、スケール内の隣接する特徴が要約されます。接続ペアの異なる範囲 時系列の時間的依存性のモデリング。」
フェドフォーマー: このモデルは、時系列データの世界的な傾向を捉えることに重点を置いています。著者らは、時系列の全体的な特徴を捉えるために設計された季節傾向分解モジュールを提案しています。
Earthformer: おそらくこれらの論文の中で最もユニークな論文で、特に天気、気候、農業などの地球システムの予測に焦点を当てています。新しい立方体アテンション アーキテクチャが導入されています。古典的なトランスフォーマーの多くは河川や鉄砲水の予測に関する研究で失敗しているため、この論文には大きな可能性があるはずです。
非定常変圧器: これは、予測に変圧器を使用した最新の論文です。著者らは、非定常時系列を処理できるように Transformer をより適切に調整することを目指しています。これらは、注意を不安定にするメカニズムと一連の安定化メカニズムの 2 つのメカニズムを使用します。これらのメカニズムは既存の Transformer モデルに接続でき、作成者はこれらのメカニズムを Informer、Autoformer、および従来の Transformer に接続するとパフォーマンスが向上することをテストしました (付録では、Fedformer のパフォーマンスが向上することも示されています)。
論文の評価方法: Informer と同様に、これらすべてのモデル (Earthformer を除く) は電力、交通、金融、気象データセットに基づいて評価されます。主に平均二乗誤差 (MSE) および平均絶対誤差 (MAE) 指標に基づいて評価されます。

この論文は非常に優れていますが、Transformer に関連する論文のみを比較しています。実際、単純な線形回帰、LSTM/GRU、さらには XGB などのツリー モデルなどのより単純な方法と比較する必要があります。もう 1 つは、他の時系列関連データ セットで良好なパフォーマンスが得られたことがないため、一部の標準データ セットに限定すべきではないということです。たとえば、情報提供者は川の流れを正確に予測するのに大きな問題を抱えており、そのパフォーマンスは LSTM や通常の変圧器と比較しても劣ることがよくあります。
さらに、コンピューター ビジョンとは異なり、画像の寸法は少なくとも一定のままであるため、時系列データは長さ、周期性、傾向、季節性が大きく異なる可能性があるため、より広範囲のデータ セットが必要になります。
OpenReview の Non-Stationary Transformer のレビューで、1 人のコメント投稿者もこれらの問題を表明しましたが、最終的なメタレビューで反対票が投じられました:
「モデルは Transformer フィールドに属しており、Transformerこれまでに多くのタスクで最先端のパフォーマンスを示してきたため、他の「ファミリー」手法と比較する必要はないと思います。」
これは非常に問題のある議論であり、研究には適用性が欠けているという結論につながります。現実世界へ。誰もが知っているように、表形式データにおける XGB の圧倒的な優位性は変わっていません。では、Transformer が密室で動作することに何の意味があるのでしょうか?毎回上回り、毎回負けた。
最先端の手法と革新的なモデルを実際に重視する人間として、いわゆる「良い」モデルを動作させるために数か月を費やしたところ、最終的にそのパフォーマンスが劣悪であることがわかりました。単純な線形回帰ほど良くはありませんでしたが、この数か月には何の意味があるのでしょうか?このいわゆる「良い」モデルのポイントは何でしょうか?
すべての変圧器論文は、評価が限られているという同じ問題に悩まされています。私たちは、最初からより厳密な比較と欠点の明確な説明を要求する必要があります。モデルは複雑である可能性があります。最初は単純なモデルよりも優れているとは限りませんが、このことは、ごまかしたり、単にそうではないと仮定したりするのではなく、論文の中で明示的に述べる必要があります。 MovingMNIST データセットと N-body MNIST データセットで評価しました。著者は、立方体アテンションの有効性を検証するために使用し、降水即時予測とエルニーニョ周期予測を評価しました。良いものだと思います。例、物理知識の統合
2. トランスフォーマーは時系列予測に効果的ですか (2022)?
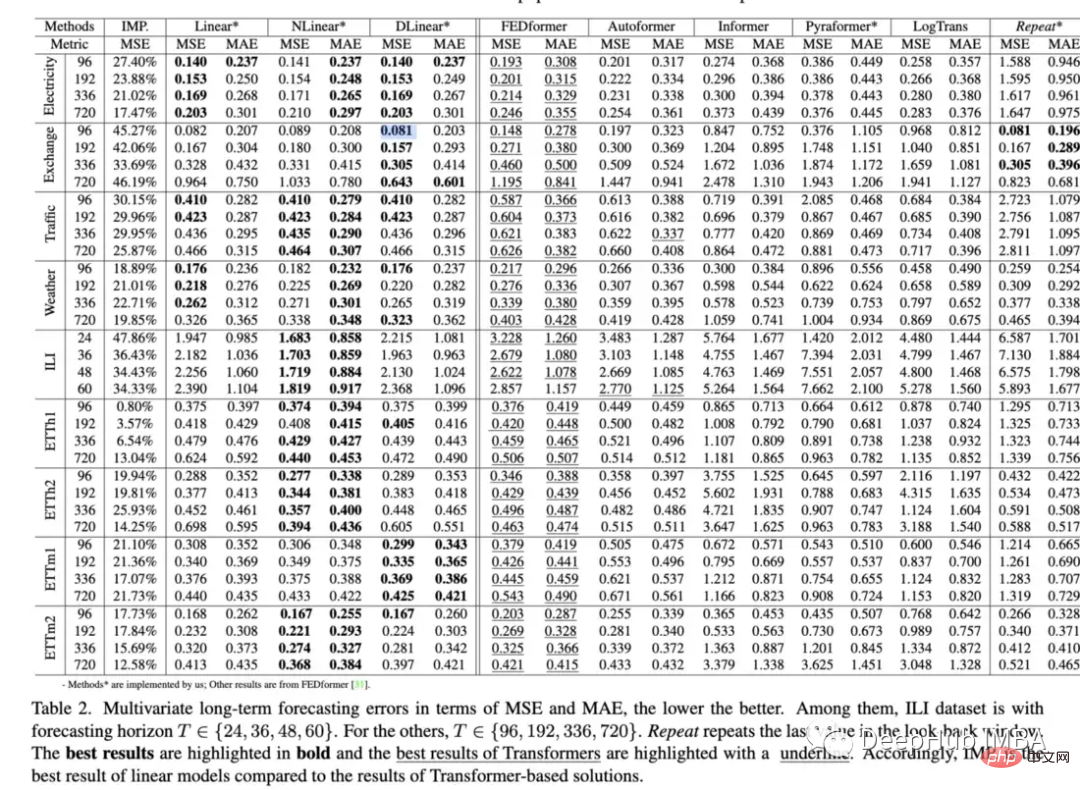 この論文では、Transformer がベースライン手法と比較してデータを予測する能力を調査します。論文からのいくつかの興味深い点: 注意と発見: 「Informer のパフォーマンスは、単純化が進むにつれて向上しており、少なくとも既存の LTSF ベンチマークでは、セルフ アテンション スキームやその他の複雑なモジュールが不要であることを示しています」 "
この論文では、Transformer がベースライン手法と比較してデータを予測する能力を調査します。論文からのいくつかの興味深い点: 注意と発見: 「Informer のパフォーマンスは、単純化が進むにつれて向上しており、少なくとも既存の LTSF ベンチマークでは、セルフ アテンション スキームやその他の複雑なモジュールが不要であることを示しています」 "
バックトラッキングの追加を調査したところ、ウィンドウ処理 (ルックバック ウィンドウ) によって Transformers のパフォーマンスが向上するかどうかを調査した結果、次のことが判明しました。「SOTA Transformers のパフォーマンスはわずかに低下しました。これは、これらのモデルが隣接する時系列シーケンスから同様の時間情報のみをキャプチャしていることを示しています。」 ”
https:/ /www.php.cn/link/ab22e28b58c1e3de6bcef48d3f5d8b4a
かなりの研究が、トランスフォーマーを予測に適用することに焦点を当ててきましたが、例外として、検出に関する研究は比較的少数です。この記事では、(教師なし) トランスフォーマーを紹介します。異常を検出します。このモデルは、特別に構築された異常注意メカニズムと minmax 戦略を組み合わせて使用します。この記事では、サーバー マシン データセット、プールされたサーバー メトリクス、土壌水分アクティブ パッシブ、および NeurIPS-TS (それ自体が 5 つの異なるデータセットで構成されています) を含む 5 つの実際のデータセットでモデルのパフォーマンスを評価します。特に 2 番目の論文の観点に関しては、このモデルに懐疑的な人もいるかもしれませんが、この評価は非常に厳密です。 Neurips-TS は、異常検出モデルのより厳密な評価を提供するために特別に設計された最近作成されたデータセットです。このモデルは、より単純な異常検出モデルと比較してパフォーマンスが向上しているようです。
著者らは、大量の異常検出データセットで適切に動作する独自の教師なし Transformer を提案しています。これは、過去数年間の時系列トランスフォーマーの分野で最も有望な論文の 1 つです。なぜなら、予測は分類や異常検出よりも困難です。将来に向けて、膨大な範囲の可能な値を予測しようとしているからです。多くの研究が予測に焦点を当てており、分類や異常検出は無視されています。Transformer については単純なことから始めるべきでしょうか?
## https://www.php.cn/link/ae95296e27d7f695f891cd26b4f37078
この論文では、深い時系列予測モデル (特に上記の変換器) のトレーニングを改善できる新しい形式の正則化を紹介します。 著者らは、これを既存のトランス LSTNet モデルに挿入して評価します。ほとんどの場合、パフォーマンスが大幅に向上することがわかりました。ただし、彼らは Autoformer モデルのみをテストし、Fedformer のような新しいモデルはテストしませんでした。 新しい形式の正則化関数または損失関数は、通常、既存の時系列モデルに組み込むことができるため、常に役立ちます。 Fedformer の非定常メカニズムと Wavebound を組み合わせると、パフォーマンスにおいて単純な線形回帰を上回る可能性があります :)。 時系列表現Transformer は予測の方向ではうまく機能しませんが、有用な時系列表現の作成においては大きな進歩を遂げています。これは、時系列深層学習の分野における印象的な新しい領域であり、より深く研究されるべきだと思います。 5. TS2Vec: 時系列の普遍的な表現に向けて (AAAI 2022)https://www.php.cn/link/7690dd4db7a92524c684e3191919eb6b
TS2Vec は、時系列表現/埋め込みを学習するための一般的なフレームワークです。この論文自体はやや古いものですが、時系列表現学習論文のトレンドの始まりとなりました。 予測と異常検出の表現を使用して評価されたこのモデルは、Informer や Log Transformer などの多くのモデルよりも優れています。 6、時系列予測のための潜在的な季節トレンド表現の学習(Neurips 2022)https://www.php.cn/link/0c5534f554a26f7aeb7c780e12bb1525


https://www.php.cn/link/791d3a0048b9c200dceca07f99ddd178
これは、2022 年の初めに ICLR で発表された論文で、学習時期と傾向の表現の点で LaST と非常によく似ています。 LaST はそのパフォーマンスを大幅に置き換えているため、ここではあまり説明しません。ただし、読みたい人のために上にリンクがあります。https://www.php.cn/link / d4ea5dacfff2d8a35c0952291779290d

トレーニング データが不足している場合、DNN にとって予測は課題となります。このペーパーでは、豊富なデータを持つドメインに対して共有アテンション レイヤーを使用し、ターゲット ドメインに対して個別のモジュールを使用します。
提案されたモデルは、合成データセットと実際のデータセットを使用して評価されます。合成環境では、コールドスタート学習と少数ショット学習がテストされ、それらのモデルはプレーンな Transformer や DeepAR よりも優れたパフォーマンスを発揮することがわかりました。実際のデータセットには Kaggle 小売データセットが採用され、モデルはこれらの実験のベースラインを大幅に上回りました。
コールド スタート、少数のサンプル、限られた学習は非常に重要なトピックですが、時系列を扱った論文はほとんどありません。このモデルは、これらの問題のいくつかに対処するための重要なステップを提供します。これは、より多様で限定された実世界のデータセットで評価し、より多くのベースラインモデルと比較できることを意味します微調整または正則化の利点は、あらゆるアーキテクチャに合わせて調整できることです。
https://www.php.cn/link/f38fef4c0e4988792723c29a0bd3ca98
これは「典型的な」時系列論文ではありませんが、この論文の焦点はマシンが故障する前に介入する最適なタイミングを見つけることにあるため、このリストに含めることにしました。これは OTI または介入までの最適時間と呼ばれます。
OTI を評価する際の問題の 1 つは、基礎となる生存分析の精度です (それが不正確であれば、評価も不正確になります)。著者らは、2 つの静的しきい値に対してモデルを評価し、パフォーマンスが良好であることを確認し、さまざまなポリシーについて予想されるパフォーマンスとヒット対失敗の比率をプロットしました。
これは興味深い問題であり、著者らは新しい解決策を提案しており、Openreview のあるコメント投稿者は次のように述べています。「失敗確率と予想される介入時間の間のトレードオフを示すグラフがあったとしたら、実験は人々がこのトレードオフ曲線の形状を直観的に理解できるように、より説得力のあるものにしてください。」
Monash 時系列予測アーカイブ (Neurips 2021): このアーカイブは、さまざまな時系列データセットの「マスター リスト」を形成し、より信頼できるベンチマークを提供することを目的としています。このリポジトリには、医療、小売、ライドシェア、人口統計など、複数の業界にわたる 20 を超える異なるデータセットが含まれています。
https://www.php.cn/link/5d7009220a974e94404889274d3a9553
Subseasonal Forecasting Microsoft (2021): これは、Microsoft によって公開されたデータ セットです。 Microsoft 、季節未満の予測 (例: 2 ~ 6 週間先) を改善するために機械学習の使用を促進するように設計されています。季節未満の予報は、政府機関が気象現象や農家の決定に対してより適切に備えるのに役立ちます。 Microsoft は、このタスク用にいくつかのベンチマーク モデルを組み込みましたが、一般に深層学習モデルのパフォーマンスは他の手法と比べてかなり劣ります。最適な DL モデルは単純なフィードフォワード モデルであり、Informer のパフォーマンスは非常に悪いです。
https://www.php.cn/link/c3cbd51329ff1a0169174e9a78126ee1
時系列外れ値検出の再検討: この記事では、多くの既存の異常値/外れ値検出をレビューします。データセット、および 35 の新しい合成データセットと 4 つの現実世界のデータセットがベンチマーク用に提案されています。
https://www.php.cn/link/03793ef7d06ffd63d34ade9d091f1ced
フロー予測オープンソースの時系列予測フレームワークであり、次のモデルが含まれています:
Vanilla LSTM (LSTM)、SimpleTransformer、Multi-Head tention、線形デコーダー付きの Transformer、DARNN、Transformer XL、Informer、DeepAR 、DSANet、SimpleLinearModel Wait
これは、時間予測に深層学習を使用する方法を学習するためのモデル コードの優れたソースです。興味がある場合は、ご覧ください。
https://www.php.cn/link/fea33a31df7d05a276193d32621ecbe4
過去 2 年間で、時系列予測における Transformer の台頭と衰退の可能性、および異常検出と分類におけるさらなるブレークスルーを伴う時系列埋め込み手法の台頭が見られました。
しかし、深層学習時系列の場合、モデルがどこで実行され、どこでパフォーマンス障害が発生するかが非常に重要であるため、解釈可能性、視覚化、およびベンチマーク手法がまだ不足しています。さらに、将来的には、パフォーマンスを向上させるための正則化、前処理、転移学習の形式がさらに登場する可能性があります。
Transformer は時系列予測に適しているのかもしれません (そうでないかもしれません) VIT と同様に、Patch の登場がなければ Transformer もまだ役に立たないと考えられているかもしれません。今後も Transformer の開発や置き換えに注目していきます時系列。
以上が2022 年の時系列予測と分類におけるディープラーニングの研究進捗状況のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



