

ソフトウェアの視覚化と転移学習をソフトウェア欠陥予測に使用する

この記事の目的は、ソース コードの中間表現を回避し、ソース コードを画像として表現し、コードの意味情報を直接抽出して欠陥予測のパフォーマンスを向上させることです。
まず、以下に示す志望動機の例をご覧ください。 File1.java と File2.java の両方の例には 1 つの if ステートメント、2 つの for ステートメント、および 4 つの関数呼び出しが含まれていますが、コードのセマンティクスと構造的特徴は異なります。ソースコードを画像に変換することで異なるコードを区別できるかどうかを検証するために、著者は実験を行いました。ソースコードを文字のASCII 10進数に従ってピクセルにマッピングし、それらをピクセルマトリックスに配置して画像を取得します。ソースコード。著者は、さまざまなソース コード イメージ間に違いがあると指摘しています。

図 1 動機の例
この記事の主な貢献は次のとおりです:
コードを画像に変換して抽出するそこから得られる意味情報と構造情報 ;
セルフアテンション メカニズムと転移学習を組み合わせて欠陥予測を実現するエンドツーエンドのフレームワークを提案します。
この記事で提案されているモデル フレームワークは図 2 に示されており、ソース コードの視覚化と深層転移学習モデリングの 2 つの段階に分かれています。
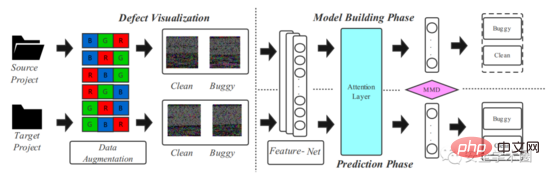
図 2 フレームワーク
1. ソース コードの視覚化
この記事では、ソース コードを 6 つの画像に変換し、そのプロセスを示しています。図3に示されています。ソース コード文字の 10 進 ASCII コードを 8 ビットの符号なし整数ベクトルに変換し、これらのベクトルを行と列ごとに配置し、イメージ行列を生成します。 8 ビット整数はグレー レベルに直接対応します。元のデータセットが小さいという問題を解決するために、著者は記事の中で色強調に基づくデータセット拡張方法を提案しました。R、G、Bの3つのカラーチャネルの値が配置され、結合して 6 つのカラー画像を生成します。ここで非常に混乱しているように見えますが、チャネル値を変更すると、セマンティック情報と構造情報が変更されるはずです。しかし、図 4 に示すように、著者は脚注でそれを説明しています。
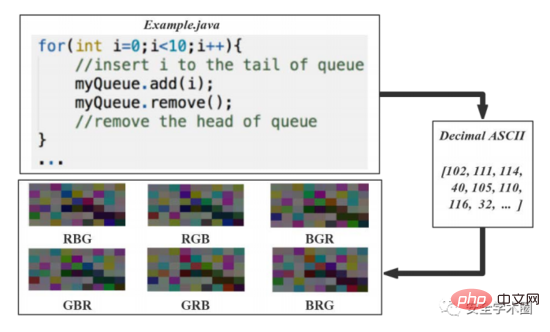
図 3 ソース コードの視覚化プロセス

図 4 記事の脚注 2
2 .深層転移学習モデリング
この記事では、DAN ネットワークを使用して、ソース コードのセマンティック情報と構造情報をキャプチャします。重要な情報を表現するモデルの能力を強化するために、作成者は元の DAN 構造にアテンション層を追加しました。トレーニングとテストのプロセスを図 5 に示します。conv1 ~ conv5 は AlexNet からのものであり、4 つの完全に接続された層 fc6 ~ fc9 が分類子として使用されています。著者は、新しいプロジェクトの場合、深層学習モデルのトレーニングには大量のラベル付きデータが必要であり、それが難しいと述べました。そこで、著者はまず ImageNet 2012 で事前トレーニングされたモデルをトレーニングし、事前トレーニングされたモデルのパラメータを初期パラメータとして使用してすべての畳み込み層を微調整することで、コード イメージと ImageNet 2012 のイメージ間の差を減らしました。
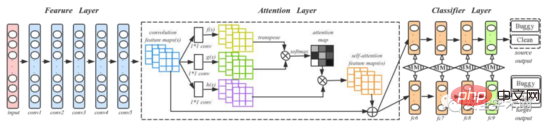
図 5 トレーニングとテストのプロセス
3. モデルのトレーニングと予測
ソース プロジェクトのタグ付きコードとターゲットの場合プロジェクト内のラベルのないコードは、コード イメージを生成し、同時にモデルにフィードします。両方とも畳み込み層とアテンション層を共有して、それぞれの特徴を抽出します。完全接続層のソースとターゲット間の MK-MDD (マルチ カーネル バリアントの最大平均不一致) を計算します。 Target にはラベルがないため、クロス エントロピーは Source に対してのみ計算されます。モデルは、ミニバッチの確率的勾配降下法を使用して、損失関数に沿ってトレーニングされます。 500 エポックの
実験部分では、作成者は PROMISE データ ウェアハウス内のすべてのオープン ソース Java プロジェクトを選択し、そのバージョン番号、クラス名、バグ タグの有無を収集しました。バージョン番号とクラス名に基づいて、github からソース コードをダウンロードします。最終的に、10 個の Java プロジェクトからデータが収集されました。データセットの構造を図 6 に示します。
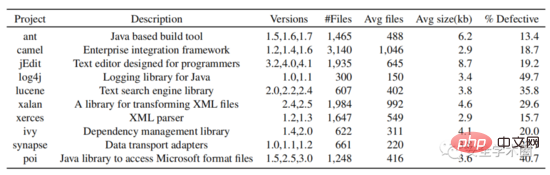
図 6 データセット構造
プロジェクト内の欠陥予測について、この記事では比較のために次のベースライン モデルを選択しています:

プロジェクト間の欠陥予測について、この記事では比較のために次のベースライン モデルを選択しています:

要約すると、この論文は 2 年前に書かれたものですが、そのアイデアは次のとおりです。まだ比較的目新しいものであり、AST などの一連のコード中間表現を回避し、コードを画像抽出機能に直接変換します。コードから変換された画像には、本当にソース コードの意味情報と構造情報が含まれているのでしょうか?あまり説明できないような気がします(笑)。後で実験的な分析を行う必要があります。
以上がソフトウェアの視覚化と転移学習をソフトウェア欠陥予測に使用するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
8
6
15
1371
52
76
11
8
6

 Bonjour とはどのようなソフトウェアですか? アンインストールできますか?
Feb 20, 2024 am 09:33 AM
Bonjour とはどのようなソフトウェアですか? アンインストールできますか?
Feb 20, 2024 am 09:33 AM
タイトル: Bonjour ソフトウェアの詳細とアンインストール方法 要約: この記事では、Bonjour ソフトウェアの機能、使用範囲、アンインストール方法を紹介します。同時に、ユーザーのニーズを満たすために、Bonjour を置き換える他のツールを使用する方法についても説明します。はじめに: Bonjour は、コンピュータおよびネットワーク技術の分野で一般的なソフトウェアです。これは一部のユーザーには馴染みのないものかもしれませんが、特定の状況では非常に便利です。 Bonjour ソフトウェアがインストールされているが、それをアンインストールしたい場合は、
 WPS Office で PPT ファイルを開けない場合の対処方法 - WPS Office で PPT ファイルを開けない場合の対処方法
Mar 04, 2024 am 11:40 AM
WPS Office で PPT ファイルを開けない場合の対処方法 - WPS Office で PPT ファイルを開けない場合の対処方法
Mar 04, 2024 am 11:40 AM
最近、多くの友人から、WPSOffice で PPT ファイルを開けない場合はどうすればよいか尋ねられました。次に、WPSOffice で PPT ファイルを開けない問題を解決する方法を学びましょう。皆さんのお役に立てれば幸いです。 1. 以下の図に示すように、まず WPSOffice を開いてホームページに入ります。 2. 次に、下の図に示すように、上の検索バーに「ドキュメント修復」というキーワードを入力し、クリックしてドキュメント修復ツールを開きます。 3. 次に、以下の図に示すように、修復のために PPT ファイルをインポートします。
 CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark は、シーケンシャルおよびランダムの読み取り/書き込み速度を迅速に測定する、ハード ドライブ用の小型 HDD ベンチマーク ツールです。次に、編集者が CrystalDiskMark と Crystaldiskmark の使用方法を紹介します。 1. CrystalDiskMark の概要 CrystalDiskMark は、機械式ハード ドライブとソリッド ステート ドライブ (SSD) の読み取りおよび書き込み速度とパフォーマンスを評価するために広く使用されているディスク パフォーマンス テスト ツールです。 ). ランダム I/O パフォーマンス。これは無料の Windows アプリケーションで、使いやすいインターフェイスとハード ドライブのパフォーマンスのさまざまな側面を評価するためのさまざまなテスト モードを提供し、ハードウェアのレビューで広く使用されています。
![Corsair iCUE ソフトウェアが RAM を検出しない [修正]](https://img.php.cn/upload/article/000/465/014/170831448976874.png?x-oss-process=image/resize,m_fill,h_207,w_330) Corsair iCUE ソフトウェアが RAM を検出しない [修正]
Feb 19, 2024 am 11:48 AM
Corsair iCUE ソフトウェアが RAM を検出しない [修正]
Feb 19, 2024 am 11:48 AM
この記事では、CorsairiCUE ソフトウェアが Windows システムの RAM を認識しない場合にユーザーができることについて説明します。 CorsairiCUE ソフトウェアは、ユーザーがコンピューターの RGB ライティングを制御できるように設計されていますが、一部のユーザーはソフトウェアが適切に機能せず、RAM モジュールを検出できないことに気づきました。 ICUE が私の記憶を認識しないのはなぜですか? ICUE が RAM を正しく識別できない主な理由は、通常、バックグラウンド ソフトウェアの競合に関連していますが、SPD 書き込み設定が正しくないこともこの問題を引き起こす可能性があります。 CorsairIcue ソフトウェアが RAM を検出しない問題を修正 CorsairIcue ソフトウェアが Windows コンピュータ上の RAM を検出しない場合は、次の提案に従ってください。
 CrystalDiskinfo 使い方チュートリアル ~CrystalDiskinfo とは何ですか?
Mar 18, 2024 pm 04:50 PM
CrystalDiskinfo 使い方チュートリアル ~CrystalDiskinfo とは何ですか?
Mar 18, 2024 pm 04:50 PM
CrystalDiskInfo は、コンピュータのハードウェア デバイスをチェックするためのソフトウェアです。このソフトウェアでは、読み取り速度、転送モード、インターフェイスなど、自分のコンピュータのハードウェアをチェックできます。では、これらの機能に加えて、CrystalDiskInfo の使い方と、CrystalDiskInfo とは何なのかを整理してみましょう。 1. CrystalDiskInfo の起源 コンピュータ ホストの 3 つの主要コンポーネントの 1 つであるソリッド ステート ドライブは、コンピュータの記憶媒体であり、コンピュータのデータ ストレージを担当します。優れたソリッド ステート ドライブは、ファイルの読み取りを高速化し、消費者エクスペリエンスに影響を与えます。消費者は新しいデバイスを受け取ると、サードパーティ ソフトウェアまたは他の SSD を使用して、
 Adobe Illustrator CS6 でキーボードの増分を設定する方法 - Adobe Illustrator CS6 でキーボードの増分を設定する方法
Mar 04, 2024 pm 06:04 PM
Adobe Illustrator CS6 でキーボードの増分を設定する方法 - Adobe Illustrator CS6 でキーボードの増分を設定する方法
Mar 04, 2024 pm 06:04 PM
多くのユーザーがオフィスで Adobe Illustrator CS6 ソフトウェアを使用していますが、Adobe Illustrator CS6 でキーボードの増分を設定する方法をご存知ですか? 次に、エディターが Adobe Illustrator CS6 のキーボードの増分を設定する方法を表示します。興味のあるユーザーは、以下をご覧ください。ステップ 1: 以下の図に示すように、Adobe Illustrator CS6 ソフトウェアを起動します。ステップ 2: メニューバーで [編集] → [環境設定] → [一般] コマンドを順にクリックします。ステップ 3: [キーボード インクリメント] ダイアログ ボックスが表示されます。[キーボード インクリメント] テキスト ボックスに必要な数値を入力し、最後に [OK] ボタンをクリックします。ステップ 4: ショートカット キー [Ctrl] を使用します。
 Edge で互換性のないソフトウェアを読み込もうとする問題を解決するにはどうすればよいですか?
Mar 15, 2024 pm 01:34 PM
Edge で互換性のないソフトウェアを読み込もうとする問題を解決するにはどうすればよいですか?
Mar 15, 2024 pm 01:34 PM
Edge ブラウザを使用すると、互換性のないソフトウェアが一緒に読み込まれようとすることがありますが、何が起こっているのでしょうか?このサイトでは、Edge と互換性のないソフトウェアをロードしようとする問題を解決する方法をユーザーに丁寧に紹介します。 Edge でロードしようとしている互換性のないソフトウェアを解決する方法 解決策 1: スタート メニューで IE を検索し、IE で直接アクセスします。解決策 2: 注: レジストリを変更すると、システム障害が発生する可能性があるため、慎重に操作してください。レジストリパラメータを変更します。 1. 操作中に regedit と入力します。 2. パス\HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Micros を見つけます。
 bonjourってどんなソフトですか? 便利ですか?
Feb 22, 2024 pm 08:39 PM
bonjourってどんなソフトですか? 便利ですか?
Feb 22, 2024 pm 08:39 PM
Bonjour は、ローカル エリア ネットワーク内のネットワーク サービスを検出および構成するために Apple が発売したネットワーク プロトコルおよびソフトウェアです。その主な役割は、同じネットワーク内に接続されているデバイス間を自動的に検出して通信することです。 Bonjour は 2002 年の MacOSX10.2 バージョンで初めて導入され、現在は Apple のオペレーティング システムにデフォルトでインストールされ有効になっています。それ以来、Apple は Bonjour のテクノロジーを他のメーカーに公開したため、他の多くのオペレーティング システムやデバイスも Bonjour をサポートできるようになりました。
