

説明可能な AI のための 10 の Python ライブラリ

XAI の目標は、モデルの動作と決定について意味のある説明を提供することです。この記事では、説明可能な AI で現在利用可能な 10 個の Python ライブラリをまとめています
XAI とは何ですか?
XAI、Explainable AI とは、人工知能 (AI) の意思決定プロセスと予測に対して明確でわかりやすい説明を提供できるシステムまたは戦略を指します。 XAI の目標は、モデルの意思決定における信頼性の向上、説明責任、透明性の提供に役立つ、ユーザーの行動と意思決定について有意義な説明を提供することです。 XAI は解釈に限定されず、ユーザーが推論を抽出して解釈しやすくする方法で ML 実験も行います。
実際には、XAI は、特徴の重要度の測定、視覚化技術の使用、または決定木や線形回帰モデルなどの本質的に解釈可能なモデルの構築など、さまざまな方法を通じて実現できます。どの方法を選択するかは、解決する問題の種類と必要な解釈可能性のレベルによって異なります。
AI システムは、ヘルスケア、金融、刑事司法など、ますます多くのアプリケーションで使用されており、人々の生活に対する AI の潜在的な影響が大きく、特定の理由を理解した上で意思決定が行われる場合に使用されています。これらの分野での誤った決定の代償は大きい(リスクが高い)ため、AI によって行われた決定であっても、妥当性と説明可能性を慎重にチェックする必要があるため、XAI の重要性がますます高まっています。

説明可能性実践のステップ
データ準備: この段階にはデータの収集と処理が含まれます。データは高品質でバランスが取れており、解決されている現実世界の問題を表している必要があります。バランスの取れた代表的なクリーンなデータがあれば、AI の説明可能性を維持するための今後の取り組みが軽減されます。
モデル トレーニング: モデルは、従来の機械学習モデルまたは深層学習ニューラル ネットワークのいずれかの準備されたデータでトレーニングされます。モデルの選択は、解決する問題と必要な解釈可能性のレベルによって異なります。モデルが単純であればあるほど、結果の解釈は容易になりますが、単純なモデルのパフォーマンスはあまり高くありません。
モデルの評価: モデルの解釈可能性を維持するには、適切な評価方法とパフォーマンス指標を選択する必要があります。この段階でモデルの解釈可能性を評価して、予測に対して有意義な説明を提供できることを確認することも重要です。
説明の生成: これは、特徴の重要度の測定、視覚化技術などのさまざまな技術を使用して、または本質的に説明可能なモデルを構築することによって実行できます。
説明の検証: モデルによって生成された説明の正確性と完全性を検証します。これは、説明が信頼できるものであることを確認するのに役立ちます。
展開と監視: XAI の作業は、モデルの作成と検証だけでは終わりません。導入後も継続的な説明作業が必要です。実際の環境で監視する場合は、システムのパフォーマンスと解釈可能性を定期的に評価することが重要です。
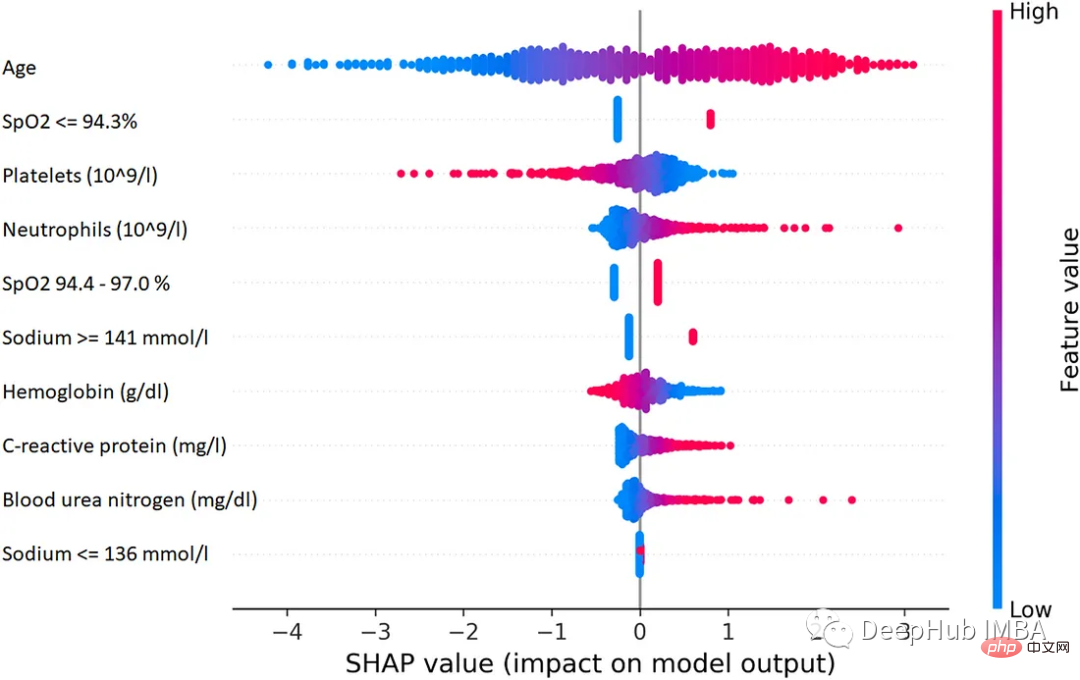
1. SHAP (SHapley Additive exPlanations)
SHAP は、あらゆる機械学習モデルの出力を説明するために使用できるゲーム理論の手法です。ゲーム理論の古典的な Shapley 値とその関連拡張を使用して、最適なクレジット割り当てをローカルな解釈に関連付けます。
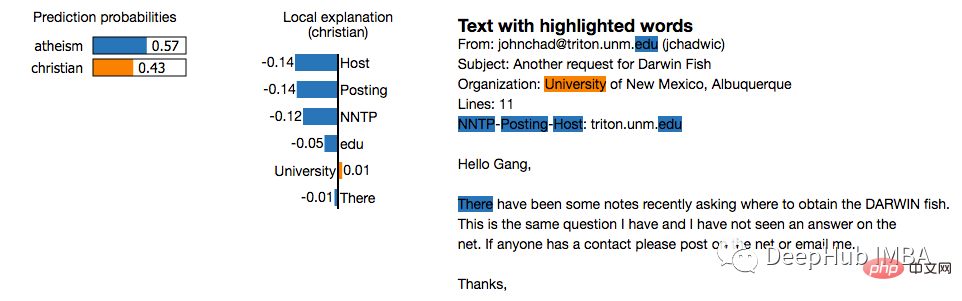
2. LIME (ローカルで解釈可能なモデルに依存しない説明)
LIME は、特定の予測をローカルで近似するモデル非依存の手法です。モデルの動作を次のように囲みます。と連携。 LIME は、機械学習モデルが何をしているのかを説明しようとします。 LIME は、テキスト分類子、表形式データの分類子、または画像の個々の予測の解釈をサポートします。
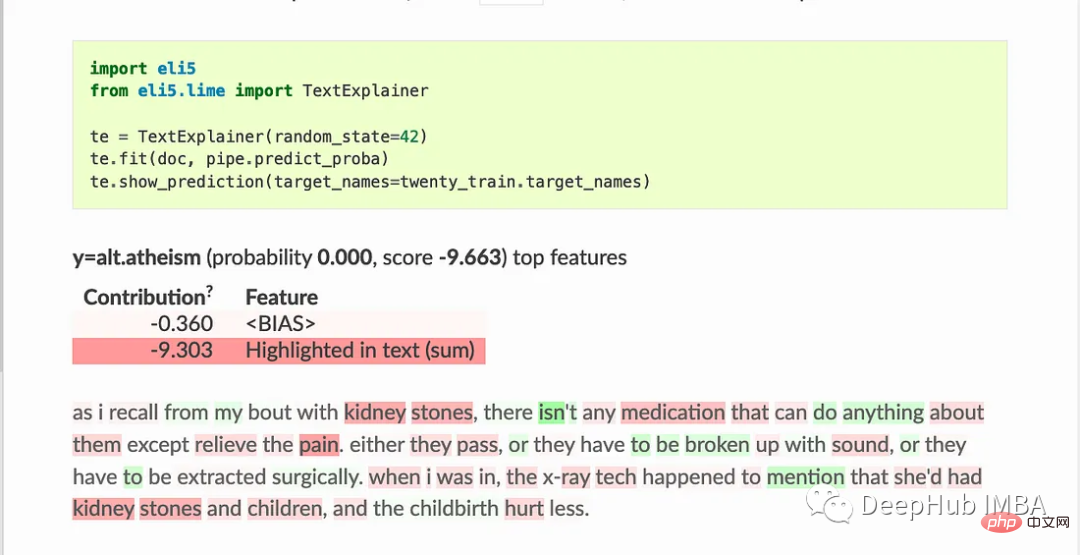
3. Eli5
ELI5 は、機械学習分類器のデバッグとその予測の解釈に役立つ Python パッケージです。次の機械学習フレームワークとパッケージのサポートを提供します。
- scikit-learn: ELI5 は、scikit-learn の線形分類器と回帰子の重みと予測を解釈でき、決定木はテキストまたはテキストとして出力できます。特徴の重要性を示し、デシジョン ツリーとツリー アンサンブルからの予測を説明する SVG。 ELI5 は、scikit-learn のテキスト ハンドラーも理解し、それに応じてテキスト データを強調表示します。
- Keras - Grad-CAM を介した画像分類子予測の視覚的解釈。
- XGBoost - 機能の重要性を示し、XGBClassifier、XGBRegressor、および XGBoost .boost の予測について説明します。
- LightGBM - 機能の重要性を示し、LGBMClassifier と LGBMRegressor の予測について説明します。
- CatBoost: CatBoostClassifier と CatBoostRegressor の機能の重要性を表示します。
- lightning - ライトニング分類器とリグレッサーの重みと予測を解釈します。
- sklearn-crfsuite。 ELI5 では、sklearn_crfsuite.CRF モデルの重みを確認できます。
基本的な使用法:
Show_weights() はモデルのすべての重みを表示します。Show_prediction() はモデルの個々の予測を確認するために使用できます

ELI5 は、ブラック ボックス モデルをチェックするためのいくつかのアルゴリズムも実装しています。
TextExplainer は、LIME アルゴリズムを使用して、テキスト分類子の予測を説明します。順列重要度法は、ブラックボックス推定器の特徴重要度を計算するために使用できます。
4. Shapash
Shapash は、モデルを理解しやすくするために、いくつかのタイプの視覚化を提供します。この概要を使用して、モデルによって提案された決定を理解します。このプロジェクトは MAIF データサイエンティストによって開発されました。 Shapash は主に一連の優れたビジュアライゼーションを通じてモデルを説明します。
Shapash は Web アプリケーション メカニズムを通じて動作し、Jupyter/ipython と完全に統合できます。
from shapash import SmartExplainer
xpl = SmartExplainer(
model=regressor,
preprocessing=encoder, # Optional: compile step can use inverse_transform method
features_dict=house_dict# Optional parameter, dict specifies label for features name
)
xpl.compile(x=Xtest,
y_pred=y_pred,
y_target=ytest, # Optional: allows to display True Values vs Predicted Values
)
xpl.plot.contribution_plot("OverallQual")
5. アンカー
アンカーは、局所的な「十分な」予測条件を表すアンカー ポイントと呼ばれる高精度のルールを使用して、複雑なモデルの動作を説明します。このアルゴリズムは、高い確率を保証して、あらゆるブラックボックス モデルの説明を効率的に計算できます。
アンカーは、LIME のいくつかの制限 (データの目に見えないインスタンスにモデルを適合できないなど) が修正された LIME v2 と考えることができます。アンカーは個々の視点ではなく、ローカルなエリアを使用します。 SHAP よりも計算が軽量であるため、高次元または大規模なデータ セットで使用できます。ただし、ラベルは整数のみであるという制限もあります。

6. BreakDown
BreakDown は、線形モデルの予測を説明するために使用できるツールです。これは、モデルの出力を各入力特徴の寄与に分解することによって機能します。このパッケージには 2 つの主なメソッドがあります。 Explainer() と Preparation()
model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up")

7、Interpret-Text
Interpret-Text は、NLP モデルのコミュニティ開発を組み合わせたものです。結果を表示するための手法と視覚化パネル。実験は複数の最先端のインタープリターで実行され、比較分析できます。このツールキットは、機械学習モデルを各タグ上でグローバルに解釈することも、各ドキュメント上でローカルに解釈することもできます。
以下は、このパッケージで利用可能なインタプリタのリストです:
- Classical Text Explainer - (デフォルト: ロジスティック回帰用のワードバッグ)
- Unified Information Explainer
- 内省的根拠の説明

from interpret_text.widget import ExplanationDashboard from interpret_text.explanation.explanation import _create_local_explanation # create local explanation local_explanantion = _create_local_explanation( classification=True, text_explanation=True, local_importance_values=feature_importance_values, method=name_of_model, model_task="classification", features=parsed_sentence_list, classes=list_of_classes, ) # Dash it ExplanationDashboard(local_explanantion)


- Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref
- Boolean Decision Rules via Column Generation, 2018. ref
- Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref
- Improving Simple Models with Confidence Profiles, , 2018. ref
- Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref
- TED: Teaching AI to Explain Its Decisions, 2019. ref
- Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref
- Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref
- Generalized Linear Rule Models, 2019. ref
9、OmniXAI
OmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。
它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。
from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances,# The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer# The created TabularExplainer for what if analysis ) dashboard.show()

10、XAI (eXplainable AI)
XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。它仍处于 alpha 阶段因此请不要将其用于生产工作流程。
以上が説明可能な AI のための 10 の Python ライブラリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7546
7546
 15
1381
52
83
11
21
89
15
1381
52
83
11
21
89

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
MINIOオブジェクトストレージ:CENTOSシステムの下での高性能展開Minioは、Amazons3と互換性のあるGO言語に基づいて開発された高性能の分散オブジェクトストレージシステムです。 Java、Python、JavaScript、Goなど、さまざまなクライアント言語をサポートしています。この記事では、CentosシステムへのMinioのインストールと互換性を簡単に紹介します。 Centosバージョンの互換性Minioは、Centos7.9を含むがこれらに限定されない複数のCentosバージョンで検証されています。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
PytorchをCentosシステムにインストールする場合、適切なバージョンを慎重に選択し、次の重要な要因を検討する必要があります。1。システム環境互換性:オペレーティングシステム:Centos7以上を使用することをお勧めします。 Cuda and Cudnn:PytorchバージョンとCudaバージョンは密接に関連しています。たとえば、pytorch1.9.0にはcuda11.1が必要ですが、pytorch2.0.1にはcuda11.3が必要です。 CUDNNバージョンは、CUDAバージョンとも一致する必要があります。 Pytorchバージョンを選択する前に、互換性のあるCUDAおよびCUDNNバージョンがインストールされていることを確認してください。 Pythonバージョン:Pytorch公式支店
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
