

勾配ブースティング アルゴリズムの意思決定プロセスの段階的な視覚化

勾配ブースティング アルゴリズムは、最も一般的に使用されるアンサンブル機械学習手法の 1 つであり、このモデルは、一連の弱い決定ツリーを使用して、強力な学習器を構築します。これは XGBoost モデルと LightGBM モデルの理論的基礎でもあるため、この記事では勾配ブースティング モデルを最初から構築して視覚化します。
勾配ブースティング アルゴリズムの概要
勾配ブースティング アルゴリズム (勾配ブースティング) は、複数の弱分類器を構築し、それらを組み合わせて強分類器にすることでパフォーマンスを向上させるアンサンブル学習アルゴリズムです。モデル。
勾配ブースティング アルゴリズムの原理は、次のステップに分割できます。
- モデルの初期化: 一般的に、単純なモデル (デシジョン ツリーなど) を次のように使用できます。初期分類子。
- 損失関数の負の勾配を計算する: 現在のモデルの各サンプル ポイントの損失関数の負の勾配を計算します。これは、新しい分類器に現在のモデルに誤差を適合させるよう要求するのと同じです。
- 新しい分類器をトレーニングする: これらの負の勾配をターゲット変数として使用して、新しい弱分類器をトレーニングします。この弱分類器には、デシジョン ツリー、線形モデルなどの任意の分類器を使用できます。
- モデルの更新: 元のモデルに新しい分類子を追加し、加重平均またはその他の方法を使用してそれらを結合します。
- 反復を繰り返す: 事前に設定された反復回数に達するか、事前に設定された精度に達するまで、上記の手順を繰り返します。
勾配ブースティング アルゴリズムはシリアル アルゴリズムであるため、トレーニング速度が遅くなる可能性があります。実際の例で紹介しましょう:
特徴量 Set Xi と値 Yi があると仮定します。 、y の最良推定値を計算するには、y

 #ステップごとに、F_m(x) を y|x に近づけたいと考えます。
#ステップごとに、F_m(x) を y|x に近づけたいと考えます。
 各ステップで、x が与えられた場合に F_m(x) が y のより適切な近似値になるようにします。
各ステップで、x が与えられた場合に F_m(x) が y のより適切な近似値になるようにします。
まず、損失関数を定義します。
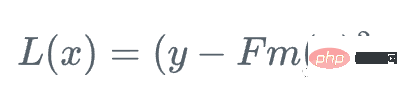
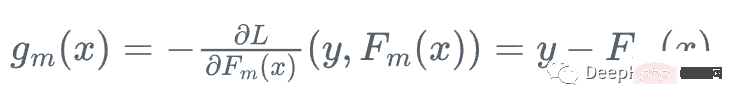
したがって、弱回帰木 h_m を使用して勾配関数 g_m を近似し、残差をトレーニングできます:
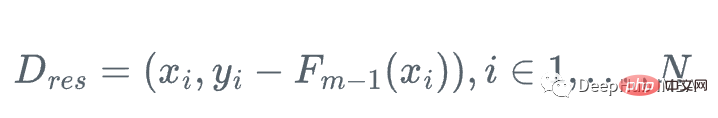
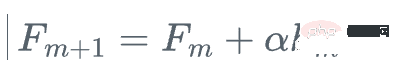
#つまり、次の手順を繰り返します
2 . 回帰木 h_m をトレーニング サンプルとその残差 (x_i, r_i) に当てはめる  #3. ステップ アルファでモデルを更新する
#3. ステップ アルファでモデルを更新する
 意思決定プロセスの視覚化
意思決定プロセスの視覚化
ここでは、sklearn の衛星データ セットを使用します。これは古典的な非線形カテゴリ データであるためです
import numpy as np import sklearn.datasets as ds import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from itertools import product,islice import seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16) moon = moonDS[0] color = -1*(moonDS[1]*2-1) df =pd.DataFrame(moon, columns = ['x','y']) df['z'] = color df['f0'] =df.y.mean() df['r0'] = df['z'] - df['f0'] df.head(10)
データを視覚化しましょう:
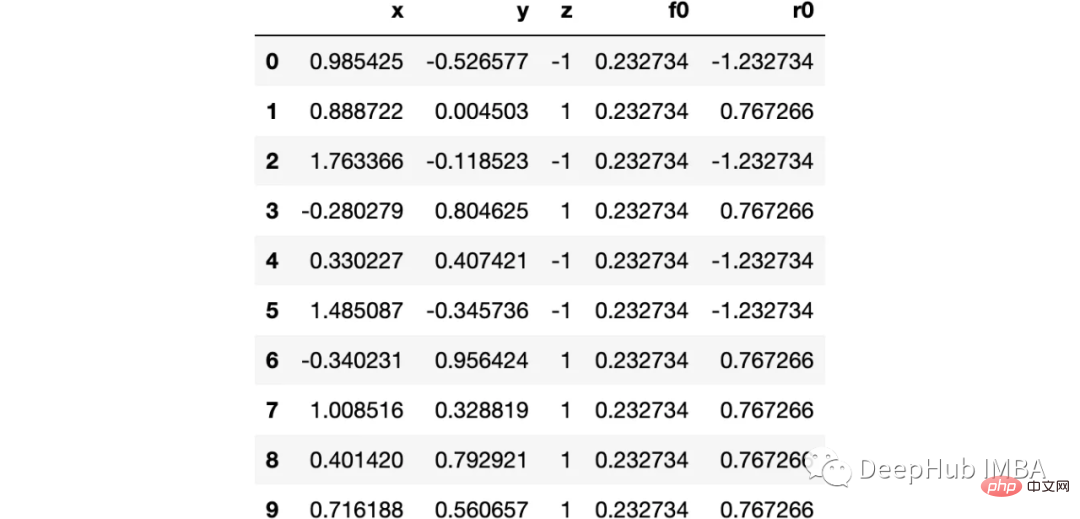
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。
那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):
"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""
clf = tree.DecisionTreeRegressor(max_depth=1)
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
eta = 0.9
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
df[f'r{i}'] = df['z'] - df[f'f{i}']
rmse = (df[f'r{i}']**2).sum()
clfs.append(clf)
rmses.append(rmse)上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']步骤就是这样简单,下面我们来一步一步执行这个过程。
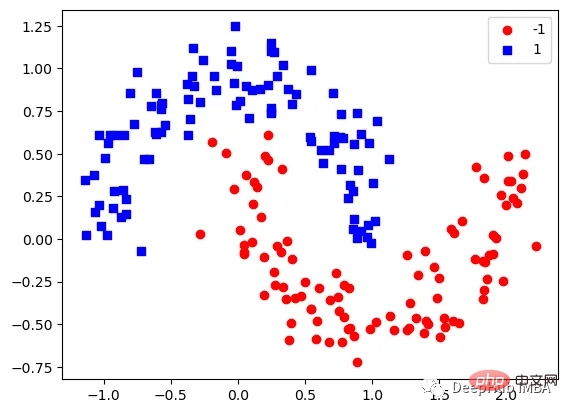
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策
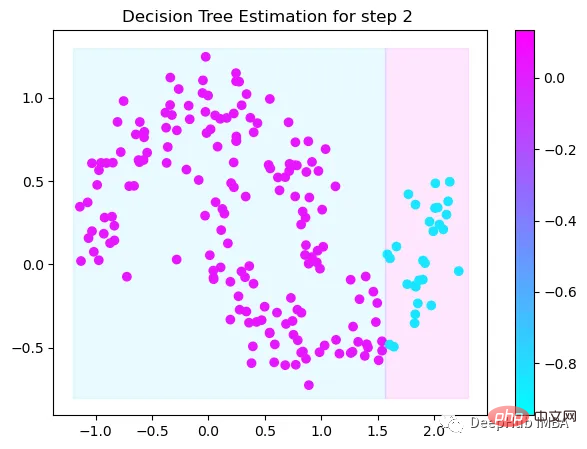
Tree Split for 1 and level 0.5143677890300751
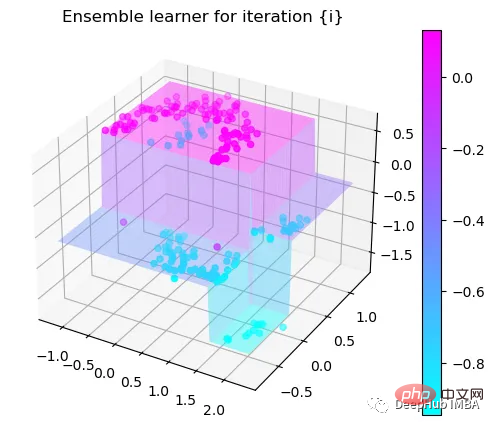
第3次决策
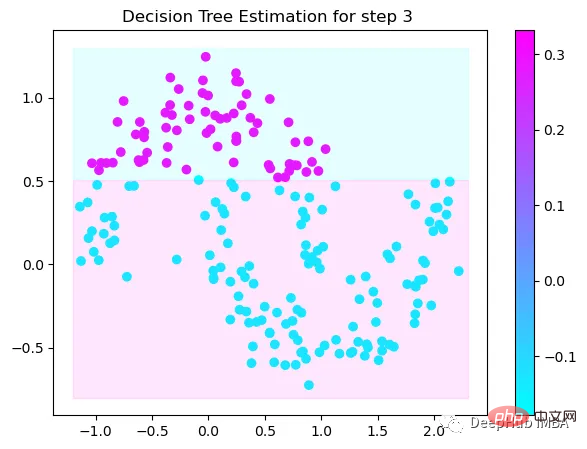
Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://www.php.cn/link/bfc89c3ee67d881255f8b097c4ed2d67
以上が勾配ブースティング アルゴリズムの意思決定プロセスの段階的な視覚化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7773
7773
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
