

ChatGPTが非常に強力な理由: WolframAlphaの父による10,000ワードの長い記事の詳細な説明

Wolfram言語の父であるStephen Wolframが再びChatGPTを支持するようになりました。
先月、彼は ChatGPT との完璧な組み合わせを期待して、独自のコンピューティング知識検索エンジン WolframAlpha を強く推奨する特別記事も書きました。
一般的な意味は、「あなたのコンピューティング能力が標準に達していない場合は、私の『スーパーパワー』をそれに注入することができます。」です。

1 か月以上後、Stephen Wolfram は「ChatGPT とは何ですか」と「なぜそれほど効果的ですか?」という 2 つの質問を中心に再度公開しました。 10,000文字に及ぶ長文で、平易かつ分かりやすい言葉で丁寧に解説されています。

(読書体験を確実にするために、以下のコンテンツはスティーブン ウルフラムの一人称で語られます。最後にイースターエッグがあります)
一度に 1 語ずつ追加する
ChatGPT の、人間が書いたテキストに似たテキストを自動的に生成する機能は、注目に値すると同時に予想外でもあります。では、それはどのように達成されるのでしょうか?なぜ意味のあるテキストを生成するのにこれほどうまく機能するのでしょうか?
この記事では、ChatGPT の内部動作の概要を説明し、ChatGPT が満足のいくテキストを生成できる理由を探ります。
ChatGPT の全体的な仕組みに焦点を当て、技術的な詳細についてはいくつか触れますが、深くは説明しません。同時に、私が述べたことは、ChatGPT だけでなく、現在の他の「大規模言語モデル」(LLM) にも当てはまることを強調しておく必要があります。
最初に説明する必要があるのは、ChatGPT の中心的なタスクは常に「合理的な継続」を生成すること、つまり、既存のテキストに基づいて、人間の書き込みに準拠した次の合理的なコンテンツを生成することであるということです。習慣。いわゆる「合理的」とは、何十億もの Web ページ、デジタル書籍、その他人間が書いたコンテンツの統計的パターンに基づいて、次に表示される可能性のあるコンテンツを推測することを指します。
たとえば、「AI の最も優れている点はそのパワーです」というテキストを入力すると、ChatGPT は人間による数十億ページのテキストの中から類似のテキストを検索し、次の単語が出現する確率をカウントします。 ChatGPT はテキストそのものを直接比較するのではなく、ある意味の「意味の一致」に基づいていることに注意してください。最終的に、ChatGPT は候補となる単語のリストを生成し、各単語に確率ランキングを与えます:

ChatGPT がタスクを完了するときは、注目に値します。記事を書くのと同じように、実際には「すでに存在するテキストを考えると、次の単語は何にすべきですか?」と何度も尋ねるだけです。説明したように、そのたびに (より正確には) 単語を追加します。トークン」は単語の一部にすぎない可能性があり、それが「新しい単語を作成する」場合がある理由です)。
各ステップで、確率を含む単語のリストを取得します。しかし、執筆中の記事 (またはその他) に追加するにはどの単語を選択すればよいでしょうか?
「最もランクの高い」単語 (つまり、最も高い「確率」が割り当てられた単語) を選択する必要があると考える人もいるかもしれません。しかし、ここで何か謎が忍び込み始めます。なぜなら、何らかの理由で、そしておそらくいつか科学的な理解が得られるかもしれませんが、常に最高ランクの単語を選択すると、通常はまったく創造性を示さない非常に「当たり障りのない」記事になってしまうからです(場合によっては逐語的に繰り返すことさえあります)。時々 (ランダムに) ランクの低い単語を選択すると、「より興味深い」記事が得られる可能性があります。
ここでのランダム性の存在は、同じプロンプトを複数回使用すると、毎回異なる記事が取得される可能性が高いことを意味します。ブードゥー教の概念と一致して、プロセスには特定のいわゆる「温度」パラメータがあり、これによって下位の単語が使用される頻度が決まります。記事生成の場合、この「温度」は 0.8 に設定するのが最適です。ここで「理論」が使用されているのではなく、実際に機能することが証明されている単なる事実であることを強調しておく必要があります。たとえば、「温度」の概念は、たまたま指数分布(統計物理学でよく知られた分布)が使用されているために存在しますが、少なくとも私たちが知る限り、それらの間には「物理的」つながりはありません。
話を続ける前に、プレゼンテーションのために、私はほとんどの場合 ChatGPT の完全なシステムを使用しません; 代わりに、通常は、優れた機能を備えたより単純な GPT-2 システムを使用していることを説明する必要があります。標準的なデスクトップ コンピュータで実行できるほど小さいです。したがって、私が示すほぼすべてのものには、コンピュータ上ですぐに実行できる明示的なWolfram言語コードが含まれています。
たとえば、次の図は、上記の確率テーブルを取得する方法を示しています。まず、基礎となる「言語モデル」ニューラル ネットワークを取得する必要があります。

#後で、このニューラル ネットワークについて詳しく説明し、その仕組みについて説明します。動作します。しかし今のところ、この「ネットワーク モデル」をブラック ボックスとしてテキストに適用し、モデルが従うべきであると考える確率に基づいて上位 5 つの単語をリクエストできます:

結果が取得された後、それらは明示的にフォーマットされた「データセット」に変換されます:

以下は例です。繰り返し「モデルを適用」します - 各ステップで最も確率の高い単語を追加します (このコードではモデルの「決定」として指定されています):








#これらの確率はどこから来たのでしょうか?
ChatGPT は常に確率に基づいて次の単語を選択します。しかし、これらの確率はどこから来るのでしょうか?
もっと簡単な質問から始めましょう。英語のテキストを (単語ごとではなく) 文字ごとに生成することを検討する場合、各文字の確率をどのように決定すればよいでしょうか?
最も簡単な方法は、英語のテキストのサンプルを採取し、その中に含まれるさまざまな文字の頻度を数えることです。たとえば、Wikipedia の「猫」の記事の文字は次のようになります (カウントはここでは省略されています):

これは「犬」です。 ” " case:

結果は似ていますが、まったく同じではありません (結局のところ、「犬」の記事では「o」がより一般的です)それ自体が「犬」という単語に現れているからです)。ただし、十分な量の英語テキストのサンプルを取得すれば、最終的には少なくともかなり一貫した結果が得られることが期待できます。これらの確率だけを使用して一連の文字を生成するサンプル:

たとえば、スペースを次のように扱うことで、文字を「単語」に分解できます。特定の確率の文字:






#しかし、ChatGPT と同様に、文字ではなく単語全体を扱っていると仮定しましょう。英語には一般的な単語が約 40,000 あります。大量の英語のテキスト (たとえば、数百億の単語を含む数百万冊の本) を調べることで、各単語の頻度を推定できます。この推定を使用すると、各単語がコーパス内に出現するのと同じ確率で独立してランダムに選択される「文」の生成を開始できます。これが私たちが得たもののサンプルです:

当然のことながら、これはナンセンスです。では、より良い文章を生成するにはどうすればよいでしょうか?文字と同様に、単語だけでなく、単語のペアやより長い N グラムの確率についても考え始めることができます。単語のペアについては、以下に 5 つの例を示します。すべて単語「cat」で始まります。

少し「より意味がある」ように思えます。十分な長さの N グラムを使用できれば、本質的に「ChatGPT を取得する」ことを想像できるかもしれません。つまり、「記事全体の正しい確率」で長いテキスト シーケンスを生成するものを取得できることになります。しかし問題は、これらの確率を推定できるほど十分な英語のテキストが実際に書かれていないということです。
Web クローラーには数百億の単語が含まれる可能性があり、デジタル化された書籍にはさらに数百億の単語が含まれる可能性があります。しかし、一般的な単語が 40,000 個あったとしても、可能な 2 タプルの数はすでに 16 億、可能な 3 タプルの数はなんと 60 兆にもなります。したがって、既存のテキストからこれらの可能性の確率を推定することはできません。 20 語の「エッセイの断片」を生成する必要がある時点で、可能性の数はすでに宇宙の粒子の数を超えているため、ある意味、すべてを書き留めることはできません。 ######だから何をすべきか?重要なアイデアは、私たちが見ているテキスト コーパス内でこれらのシーケンスを明示的に見たことがなくても、シーケンスが出現する確率を推定できるモデルを構築することです。 ChatGPT の中核となるのは、いわゆる「大規模言語モデル」(LLM) であり、これらの確率を非常に適切に推定するために構築されています。
(スペースの都合上、「モデルとは」、「ニューラル ネットワーク」、「機械学習とニューラル ネットワーク トレーニング」、「ニューラル ネットワーク トレーニングの実践と知識」、「埋め込みの概念」など。 ############################################################### これが最終的に巨大なニューラルネットワークであることは間違いありません。現在のバージョンは、1,750 億重みの GPT-3 ネットワークを備えたネットワークです。多くの点で、このニューラル ネットワークはこれまで説明してきた他のニューラル ネットワークと非常に似ていますが、言語を処理するために特別に設計されたニューラル ネットワークです。最も注目すべき機能は、「Transformer」と呼ばれるニューラルネットワークアーキテクチャです。
上で説明した最初のタイプのニューラル ネットワークでは、任意の層の各ニューロンは、本質的に、前の層のすべてのニューロンに (少なくともある程度の重みを付けて) 接続されています。ただし、特定の既知の構造を持つデータを処理したい場合、このような完全に接続されたネットワークは (おそらく) 過剰です。したがって、画像処理の初期段階では、いわゆる畳み込みニューラル ネットワーク (「convnet」) を使用するのが一般的です。このネットワークでは、ニューロンが実際には画像のピクセルと同様のグリッド上に配置され、ピクセルの近くのニューロンとのみ相互作用します。グリッドが接続されました。
Transformer のアイデアは、少なくともテキストを構成するトークン シーケンスと同様のことを実行することです。ただし、Transformer は、接続を作成できる固定領域を定義するだけでなく、「注意」の概念、つまりシーケンスの特定の部分に他の部分よりも重点を置く「注意」の概念も導入します。おそらくいつか、トレーニングを通じてすべてのカスタマイズを行った一般的なニューラル ネットワークを起動するだけで意味があるようになるでしょう。しかし、少なくとも現時点では、実際には、トランスフォーマーと同じように、そしておそらく私たちの脳も同様に、物事をモジュール化することが重要です。
それでは、ChatGPT (より正確には、ChatGPT のベースとなる GPT-3 ネットワーク) は実際に何をするのでしょうか?覚えておいてください、その全体的な目標は、トレーニングで得られたものに基づいてテキストを「合理的に」書き続けることです (これには、Web やその他の場所の何十億ページからテキストを調べることも含まれます)。したがって、いつでも一定量のテキストがあり、その目標は次のトークンに適切な選択肢を選択することです。
ChatGPT の操作は 3 つの基本的な段階に基づいています。まず、現在のテキストに対応するトークンのシーケンスを取得し、それらを表す埋め込み (つまり、数値の配列) を見つけます。次に、この埋め込みを「標準的なニューラル ネットワークの方法」で操作し、ネットワーク内の連続する層を通じて値を「変動」させ、新しい埋め込み (つまり、新しい数値配列) を生成します。次に、その配列の最後の部分を取得し、異なる可能性のある次のトークンの確率に変換される約 50,000 個の値を含む配列を生成します (はい、たまたま一般的な英語の単語と同じ数のトークンが存在しますが、約 50,000 個の値しかありません) 3000 個のトークンは完全な単語で、残りは断片です。)
重要な点は、このパイプラインの各部分がニューラル ネットワークによって実装されており、その重みがエンドツーエンドのトレーニングによって決定されるということです。通信網。言い換えれば、アーキテクチャ全体以外に実際に「明示的に設計」されるものは何もなく、すべてがトレーニング データから「学習」されます。
ただし、アーキテクチャの構築方法には多くの詳細があり、ニューラル ネットワークに関するさまざまな経験と知識が反映されています。これは確かに詳細な問題ですが、少なくとも ChatGPT を構築するために何が必要かを理解するために、これらの詳細のいくつかについて説明することが有益であると考えました。
最初は埋め込みモジュールです。これはWolfram言語で表現されたGPT-2の概略図です:

このテキストでは「embedding module」と呼ばれるモジュールを紹介します。これには3つのモジュールがあります。主な手順。最初のステップでは、テキストがトークン シーケンスに変換され、単層ニューラル ネットワークを使用して、各トークンが長さ 768 (GPT-2 の場合) または 12288 (ChatGPT の GPT-3 の場合) の埋め込みベクトルに変換されます。 。同時に、モジュールには「二次経路」もあり、トークンの整数位置を埋め込みベクトルに変換するために使用されます。最後に、トークン値とトークン位置の埋め込みベクトルが加算されて、最終的な埋め込みベクトル シーケンスが生成されます。
なぜトークン値とトークン位置の埋め込みベクトルを追加するのでしょうか?特に科学的な説明はないようです。さまざまなことを試してみましたが、これはうまくいくようです。また、ニューラル ネットワークの伝統では、十分なトレーニングを受けて初期設定が「おおよそ正しい」限り、通常は実際に「ニューラル ネットワークがどのように設計されているかを理解」しなくても、詳細は自動的に調整できると考えられています。
この「埋め込みモジュール」モジュールの機能は、テキストを埋め込みベクトル シーケンスに変換することです。文字列「hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye」を例にすると、各トークン情報を含む長さ 768 の一連の埋め込みベクトルに変換できます。値と場所から抽出されます。

各トークン埋め込みベクトルの要素をここに示します。一連の「hello」埋め込みが水平方向に表示され、その後に一連の「bye」が続きます。埋め込み。上の 2 番目の配列は位置埋め込みであり、その一見ランダムな構造がたまたま「学習された」だけです (この場合は GPT-2 で)。
わかりました。埋め込みモジュールの後には、Transformer の「主要部分」が来ます。これは、一連のいわゆる「アテンション ブロック」です (GPT-2 の場合は 12、ChatGPT の GPT-3 の場合は 96)。これは複雑で、通常は理解できない大規模な工学システムや生物学的システムを思い出させます。ただし、ここに GPT-2 の単一の「アテンション ブロック」の図を示します。

各アテンション ブロックには、「」のセットがあります。アテンション ヘッド」(GPT-2 は 12、ChatGPT の GPT-3 は 96)、各アテンション ヘッドは、埋め込みベクトル内の異なる値のブロックに対して独立して動作します。 (はい、埋め込みベクトルを部分に分割する利点も、それぞれの部分が何を意味するのかもわかりません。これは、機能することがわかっている手法の 1 つにすぎません。)
それでは、注意頭の機能とは何でしょうか?基本的に、これらは一連のトークン (つまり、すでに生成されたテキスト) を「振り返り」、次のトークンを簡単に見つけるために履歴情報を有用な形式に「パッケージ化」する方法です。上で、バイナリ確率を使用して前のトークンに基づいて単語を選択することについて説明しました。 Transformer の「注意」メカニズムにより、前の単語に「注意」することができ、たとえば、動詞が文内でその前に複数の単語が出現する名詞を参照する方法を捕捉できる可能性があります。
具体的には、アテンション ヘッドの機能は、さまざまなトークンに関連する埋め込みベクトルのブロックを再結合し、それらに特定の重みを与えることです。したがって、たとえば、GPT-2 の最初のアテンション ブロックの 12 個のアテンション ヘッドには、上記の「hello, bye」文字列に対する次の (「トークン シーケンスを先頭まで遡る」) 「重みを再グループ化」パターンがあります。 :

アテンションメカニズムによる処理後、「再重み付けされた埋め込みベクトル」が取得されます (GPT-2 の場合、長さは 768、ChatGPT の GPT の場合) -3 長さ 12,288)、標準の「完全に接続された」ニューラル ネットワーク層を通過します。この層が何をしているのかを理解するのは困難です。ただし、使用する 768×768 の重み行列 (ここでは GPT-2) のプロットは次のとおりです。

64×64 移動平均による 、いくつかの (ランダム ウォークのような) 構造が現れ始めます:

この構造は何が決定するのでしょうか?これは、人間の言語の特性の「ニューラル ネットワーク エンコーディング」である可能性があります。しかし、これらの特徴はこれまで知られていなかったかもしれません。事実上、私たちは ChatGPT (または少なくとも GPT-2) の「脳を開いて」おり、そこには私たちが理解していない複雑さがたくさんあることを発見していますが、最終的には人間を認識する能力が得られます。スピーチ。
わかりました。アテンション モジュールを通過した後、新しい埋め込みベクトルを取得し、他のアテンション モジュールを連続して通過します (GPT-2 では合計 12、GPT-3 では合計 96)。各アテンション モジュールには、独自の特定の「アテンション」および「完全に接続された」重み付けパターンがあります。これは、「こんにちは、さようなら」入力 (GPT-2 の場合) の最初のアテンション ヘッドのアテンション ウェイトのシーケンスです。

次のとおりです。は、全結合層 (移動平均後) の「行列」です。

興味深いことに、異なるアテンション ブロックであっても、これらの「重み行列」は" 見た目は非常に似ていますが、ウェイト サイズの分布も異なる場合があります (ガウス分布とは限りません):

それでは、最終的な効果は何でしょうか。これらの注意ブロックをすべて終えた後、トランスフォーマーのことはどうなりますか?基本的に、トークン シーケンスの元の埋め込みセットを最終セットに変換します。 ChatGPT の具体的な動作方法は、セット内の最後の埋め込みを選択し、それを「デコード」して、次のトークンの確率リストを生成することです。
以上が ChatGPT の内部の概要です。複雑に見えるかもしれませんが (これらの選択の多くは避けられず、やや恣意的な「エンジニアリング上の選択」です)、実際には、最終的に含まれる要素は非常に単純です。なぜなら、最終的に私たちが扱っているのは、「人工ニューロン」で作られたニューラル ネットワークだけであり、各ニューロンは一連の数値入力と何らかの重みを組み合わせるという単純な演算を実行するからです。
ChatGPT への元の入力は数値の配列 (これまでのトークンの埋め込みベクトル) であり、ChatGPT が新しいトークンを生成するために「実行」されると、これらの数値は単純にレイヤーを介して「伝播」されます。ニューラル ネットワーク、各ニューラル ネットワーク ニューロンは「自分の仕事をし」、結果を次の層のニューロンに渡します。ループや「バックトラック」はありません。すべてはネットワークを介して「フィードフォワード」されるだけです。
これは、同じ計算要素を通じて結果を繰り返し「再処理」するチューリング マシンなどの典型的な計算システムとはまったく異なります。ここで、少なくとも特定の出力トークンの生成に関しては、各計算要素 (つまりニューロン) は 1 回だけ使用されます。
しかし、ChatGPT には依然として「外側のループ」の感覚があり、計算された要素でも再利用されます。なぜなら、ChatGPT が新しいトークンを生成したいときは、ChatGPT 自体によって以前に「書き込まれた」トークンを含む、その前に出現したトークンのシーケンス全体を常に「読み取る」(つまり、入力として使用する) からです。この設定は、ChatGPT がその最も外側のレベルで少なくとも「フィードバック ループ」を含んでいることを意味すると考えることができますが、各反復は生成されるテキストに現れるトークンとして明示的に表示されます。
ChatGPT の核心に戻りましょう。各トークンの生成に使用されるニューラル ネットワークです。あるレベルでは、それは非常に単純です。同一の人工ニューロンの集合です。ネットワークの一部の部分は、(「完全に接続された」) ニューロン層のみで構成されており、その層のすべてのニューロンは、前の層のすべてのニューロンに (ある程度の重みを付けて) 接続されています。しかし、特に Transformer アーキテクチャにおいて、ChatGPT には特定の層の特定のニューロンのみが接続される、より構造化された部分があります。 (もちろん、「すべてのニューロンが接続されている」と言うこともできますが、重みがゼロのニューロンもあります)。
さらに、ChatGPT のニューラル ネットワークのいくつかの側面は、最も自然に「均一な」層ではありません。たとえば、アテンション ブロック内には、受信データの「複数のコピー」が作成される場所があり、それぞれが後で再組み立てされる前に、おそらく異なる数のレイヤーを含む異なる「処理パス」を通過します。これは便利な表記方法かもしれませんが、少なくとも原理的には、レイヤーを「密に埋める」ことを考慮し、一部の重みをゼロにすることは常に可能です。
ChatGPT の最長パスを見ると、それは約 400 層 (コア層) ですが、ある意味、それほど大きな数ではありません。しかし、数百万のニューロン、合計 1,750 億の接続、したがって 1,750 億の重みが存在します。認識すべき点の 1 つは、ChatGPT が新しいトークンを生成するたびに、各重みを含む計算を実行する必要があるということです。実装の面では、これらの計算は高度に並列な配列演算に編成でき、GPU 上で簡単に完了できます。しかし、生成される各トークンには依然として 1,750 億回の計算が必要です (そして最終的にはもう少し多くなります)。ですから、ChatGPT で長いテキストを生成するのに時間がかかるのは当然のことです。
しかし、最終的には、これらすべての操作が何らかの形で連携して、テキストを生成するという「人間らしい」仕事を達成することにも注意する必要があります。 (少なくとも私たちが知る限りでは) このようなものが機能する「究極の理論的理由」は存在しないことをもう一度強調しなければなりません。実際、これから議論するように、私たちはこれを - 驚くべき可能性がある - 科学的発見として考える必要があると思います: ChatGPT のようなニューラル ネットワークでは、人間の脳が言語を生成する際に行うことを捕捉することが可能です。それができる。
(元の記事は長いため、興味のある友人は記事の最後にあるリンクをクリックして全文を読むことができます)
One More Thing
おそらく、この記事を開いたときに、いくつかの微妙な変化に気づいた友人もいるでしょう:

はい、この記事の核となるコンテンツの編集者は他でもない、チャットGPT!
また、Stephen Wolfram の記事に対する見解についても述べています:

参考リンク:
[1 ] https://www.php.cn/link/e3670ce0c315396e4836d7024abcf3dd
[2] https://www.php.cn/link/b02f0c434ba1da7396aca257d0eb1e2f
[3] https://www.php.cn/link/76e9a17937b75b73a8a430acf210feaf
以上がChatGPTが非常に強力な理由: WolframAlphaの父による10,000ワードの長い記事の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7560
7560
 15
1384
52
84
11
28
98
15
1384
52
84
11
28
98

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 iPhoneで言語を変更する3つの方法
Feb 02, 2024 pm 04:12 PM
iPhoneで言語を変更する3つの方法
Feb 02, 2024 pm 04:12 PM
iPhone が最も使いやすい電子機器の 1 つであることは周知の事実であり、その理由の 1 つは、自分好みに簡単にカスタマイズできることです。個人設定では、iPhone のセットアップ時に選択した言語とは別の言語に変更できます。複数の言語に精通している場合、または iPhone の言語設定が間違っている場合は、以下で説明するように変更できます。 iPhoneの言語を変更する方法[3つの方法] iOSでは、ユーザーはさまざまなニーズに合わせてiPhoneの優先言語を自由に切り替えることができます。 Siri との対話言語を変更して、音声アシスタントとのコミュニケーションを容易にすることができます。同時に、ローカルキーボードを使用する場合、複数の言語を簡単に切り替えることができ、入力効率が向上します。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 Win10コンピュータの言語を中国語に設定するにはどうすればよいですか?
Jan 05, 2024 pm 06:51 PM
Win10コンピュータの言語を中国語に設定するにはどうすればよいですか?
Jan 05, 2024 pm 06:51 PM
コンピュータ システムをインストールしただけで、システムが英語になっている場合があります。この場合、コンピュータの言語を中国語に変更する必要があります。それでは、win10 システムでコンピュータの言語を中国語に変更するにはどうすればよいでしょうか?具体的な操作方法を説明します。 。 win10 でコンピューターの言語を中国語に変更する方法 1. コンピューターの電源を入れ、左下隅にあるスタート ボタンをクリックします。 2. 左側の設定オプションをクリックします。 3. 開いたページで「時刻と言語」を選択します 4. 開いたら、左側の「言語」をクリックします 5. ここで、希望するコンピューター言語を設定できます。
 ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
この記事では、ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法を紹介し、いくつかの具体的なコード例を示します。 ChatGPT は、OpenAI によって開発された生成事前トレーニング トランスフォーマーの最新バージョンです。これは、自然言語を理解し、人間のようなテキストを生成できるニューラル ネットワーク ベースの人工知能テクノロジーです。 ChatGPT を使用すると、適応型チャットを簡単に作成できます
 中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
chatgpt は中国でも使用できますが、香港やマカオでも登録できません。ユーザーが登録したい場合は、外国の携帯電話番号を使用して登録できます。登録プロセス中にネットワーク環境を切り替える必要があることに注意してください。外国のIP。
 ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法 はじめに: 人工知能技術の発展に伴い、顧客サービスの分野でロボットの使用が増えています。 ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築すると、企業はより効率的でパーソナライズされた顧客サービスを提供できるようになります。この記事では、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法を紹介し、具体的なコード例を示します。 1. ChatGPTPHP をインストールし、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築します。
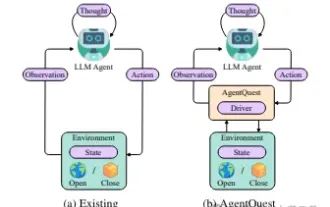 エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
大規模モデルの継続的な最適化に基づいて、LLM エージェント - これらの強力なアルゴリズム エンティティは、複雑な複数ステップの推論タスクを解決する可能性を示しています。自然言語処理から深層学習に至るまで、LLM エージェントは徐々に研究や業界の焦点になりつつあります。LLM エージェントは、人間の言語を理解して生成するだけでなく、戦略を策定し、多様な環境でタスクを実行し、API 呼び出しやコーディングを使用して構築することもできます。ソリューション。この文脈において、AgentQuest フレームワークの導入はマイルストーンであり、LLM エージェントの評価と進歩のためのモジュール式ベンチマーク プラットフォームを提供するだけでなく、研究者にこれらのエージェントのパフォーマンスを追跡および改善するための強力なツールも提供します。より細かいレベル
