

推奨のための自動車ナレッジグラフの構築

背景
1. はじめに
ナレッジ グラフの概念は、よりインテリジェントな検索エンジンの実現を目指して 2012 年に Google によって最初に提案され、2013 年以降に学術界で使用され始めました。 . そして産業レベルの普及。現在、人工知能技術の急速な発展に伴い、ナレッジグラフは検索、推奨、広告、リスク管理、インテリジェントスケジューリング、音声認識、ロボットなどの分野で広く使用されています。
2. 開発状況
ナレッジ グラフは、人工知能の原動力となるコア技術として、膨大なトレーニング データと大規模なコンピューティング能力に依存するディープ ラーニングの問題を軽減できます。下流のタスクを実行でき、解釈可能性が高いため、世界中の大手インターネット企業が独自のナレッジ グラフを積極的に展開しています。
たとえば、2013 年に Facebook はソーシャル ネットワーク上のインテリジェント検索に使用される Open Graph をリリースし、2014 年には Baidu は主に検索、アシスタント、および toB ビジネス シナリオで使用されるナレッジ グラフをリリースしました。 2015 年にアリババは製品ナレッジ グラフを開始しました。これは、フロントエンド ショッピング ガイド、プラットフォーム ガバナンス、インテリジェントな質疑応答ビジネスで重要な役割を果たしています。2017 年にテンセントによって開始された Tencent Cloud Knowledge Graph は、財務検索、エンティティ リスク予測、およびエンティティ リスク予測を効果的に支援します。その他のシナリオ; Meituan が 2018 年に開始した Meituan Brain ナレッジ グラフは、インテリジェントな検索レコメンデーションやインテリジェントな加盟店運営など、複数のビジネスに導入されています。
3. 目標とメリット
現在のドメインマップは主に電子商取引、医療、金融などの事業分野に集中していますが、自動車知識のセマンティック ネットワーク そして、ナレッジ グラフ構築のための体系的なガイダンス方法が欠如しています。この記事では、自動車分野の知識を例として、車のシリーズ、モデル、ディーラー、メーカー、ブランドなどのエンティティと関係に焦点を当て、ドメイン マップをゼロから構築するためのアイデアを提供し、その手順と詳細を説明します。ナレッジ マップを構築する方法について説明し、このマップに基づくいくつかの典型的なアプリケーションを紹介します。
データソースはオートホームのウェブサイトですオートホームは、ショッピングガイド、情報、レビュー、口コミなどの複数のセクションで構成される自動車サービスプラットフォームです。自動車データは、自動車中心のコンテンツを整理およびマイニングするためのナレッジ グラフを構築することによって整理およびマイニングされ、豊富な知識情報を提供し、構造化され正確に関心を描写し、コールド スタート、リコール、並べ替え、表示などの複数の側面をサポートします。ビジネスリフトを提供することで、推奨ユーザーの割合が増加し、結果が得られます。
2. グラフの構築
1. 構築の課題
ナレッジグラフは現実世界の意味表現であり、その基本単位は[エンティティ-関係-エンティティ]です。 [エンティティ - 属性 - 属性値] の 3 つの要素であるエンティティは関係を通じて相互に接続され、セマンティック ネットワークを形成します。グラフの構築には大きな課題がありますが、構築後は、データ分析、推奨事項の計算、解釈可能性などの複数のシナリオで豊富なアプリケーション価値を示すことができます。
構築の課題:
- スキーマの定義が難しい: 現在、統一された成熟したオントロジー構築プロセスはなく、通常は特定の分野でオントロジーの定義が行われます。専門家の参加が必要;
- 異種データ タイプ: 通常、ナレッジ グラフの構築に直面するデータ ソースは、構造化データ、半構造化データ、非構造化データ、データなど単一のタイプではありません。 、知識の伝達とマイニングはより困難です;
- 専門知識に頼る: ドメインナレッジグラフは通常、車両モデルに対応したメンテナンス方法、機械、電気などの強力な専門知識に依存します。エンジニアリング、材料、力学などの分野の知識、この種の関係には精度に対する高い要件があり、知識が十分に正しいことを保証する必要があるため、効率的なグラフを作成するには、専門家とアルゴリズムのより適切な組み合わせも必要です構築;
- データ品質保証なし: 情報のマイニングまたは抽出には、下流のアプリケーションを支援するための知識として使用する前に、知識の融合または手動による検証が必要です。
利点:
- ナレッジ グラフは知識表現を統合します。マルチソースの異種データを統合することで統一ビューを形成します。
- 豊富な意味論的情報: 関係推論を通じて新しい関係エッジを発見でき、より豊富な意味論的情報を取得できます;
- 強力な解釈可能性: 明示的推論パスは深層学習の結果よりも解釈しやすい;
- 高品質で継続的な蓄積: ビジネス シナリオに基づいて合理的なナレッジ ストレージ ソリューションを設計し、ナレッジの更新と蓄積を実現します。
2. グラフ アーキテクチャの設計
技術アーキテクチャは主に構築層、ストレージ層、アプリケーション層の 3 つの層に分かれており、アーキテクチャ図は次のとおりです:
- 構築層: スキーマ定義、構造化データ変換、非構造化データマイニング、知識融合を含む;
- ストレージ層: 知識のストレージとインデックス作成、知識の更新、メタデータ管理、および基本的な知識のサポートを含むクエリ;
- サービス層: インテリジェントな推論、構造化クエリ、その他のビジネス関連の下流アプリケーション層を含みます。

3. 具体的な構築ステップとプロセス
アーキテクチャ図によると、具体的な構築プロセスは 4 つのステップに分けることができます: オントロジー設計、知識の取得、知識の保管、アプリケーション サービスの設計と使用。
3.1 オントロジーの構築
オントロジーは認識された概念の集合です オントロジーの構築とは、オントロジーの定義に基づいてオントロジー構造と知識グラフの知識フレームワークを構築することを指します。
オントロジーに基づいてグラフを構築する主な理由は次のとおりです:
- 明確な専門用語、関係、およびその領域の公理。事前定義されたスキーマ エンティティ オブジェクトとタイプは、ナレッジ グラフに更新できます。
- ドメイン知識と運用知識の分離 スキーマを通じて、トリプルから要約して整理することなく、グラフ構造と関連定義の巨視的な理解を得ることができます。
- ドメイン知識のある程度の再利用を達成します。オントロジーを構築する前に、まず関連するオントロジーが構築されているかどうかを調査することで、既存のオントロジーに基づいて改善および拡張し、半分の労力で 2 倍の結果を達成できます。
- オントロジーの定義に基づいて、グラフがアプリケーションから切断される状況や、グラフ スキーマの変更コストが再構築よりも高くなる状況を回避できます。たとえば、「BMW x3」と「2022 BMW x3」を車エンティティとして保存すると、適用時にインスタンスの関係が混乱し、使いやすさが低下する可能性があります。この状況は、「車」をオントロジー設計段階に変換することで解決できます。これは、次の方法で回避できます。 「自動車シリーズ」と「モデル」のサブカテゴリーを「クラス エンティティ」に細分化します。
ナレッジの範囲に応じて、ナレッジ グラフは一般ナレッジ グラフとドメイン ナレッジ グラフに分けられ、現在、一般ナレッジ グラフは Google の Knowledge Graph、Microsoft のSatori、 Probase など。ドメイン マップは、金融や電子商取引などの特定の業界のマップです。一般的なグラフは幅に注意を払い、より多くのエンティティの統合を重視しますが、精度に対する高い要件はありません。オントロジー ライブラリの助けを借りて公理、規則、制約を推論して使用するのは困難ですが、ドメイン グラフの知識範囲は非常に困難です。知識の深さはより深く、特定の専門分野で構築されることがよくあります。
ドメイン オントロジーの構築は、精度の要件を考慮すると、代表的な 7 ステップ手法や IDEF5 手法など [1] のように手動で行われる傾向があります。このタイプの手法の中心的な考え方は次のとおりです。構造化データに変換し、オントロジー分析を実行し、アプリケーションの目的と範囲を満たすオントロジーを要約して構築し、オントロジーを最適化して検証して、オントロジー定義の最初のバージョンを取得します。より大きなドメイン オントロジを取得したい場合は、非構造化コーパスから補完することができますが、手動による構築プロセスが比較的大規模であることを考慮して、この記事では自動車分野を例として、半自動オントロジ構築の方法を提供します。手順は次のとおりです。
- まず、統計的手法や統計的手法を使用して、初期の個別コンセプト セットとして大量の非構造化自動車コーパス (自動車シリーズのコンサルティング、新車ショッピング ガイドの記事など) を収集します。教師なしモデル (TF-IDF、BERT など) を使用して文字の特徴と単語の特徴を取得します。
- 第 2 に、BIRCH クラスタリング アルゴリズムを使用して概念を階層に分割し、最初に概念間の階層関係を確認し、クラスタリング結果に対して手動の概念検証と帰納を実行して、オントロジーの同等性、上位概念と下位概念を取得します。
- 最後に、畳み込みニューラル ネットワークと遠隔監視方法を組み合わせてエンティティ関係を抽出します。自動車ドメイン オントロジーを構築するために、オントロジー内のクラスと属性の概念を手動で識別することによって補足されます。
上記の方法では、BERT などのディープ ラーニング テクノロジを効果的に使用して、コーパス間の内部関係をより適切にキャプチャし、クラスタリングを使用してオントロジーの各モジュールを階層的に構築し、手動介入で補うことができ、迅速に、予備的なオントロジー構築を正確に完了します。次の図は、半自動オントロジー構築の概略図です。
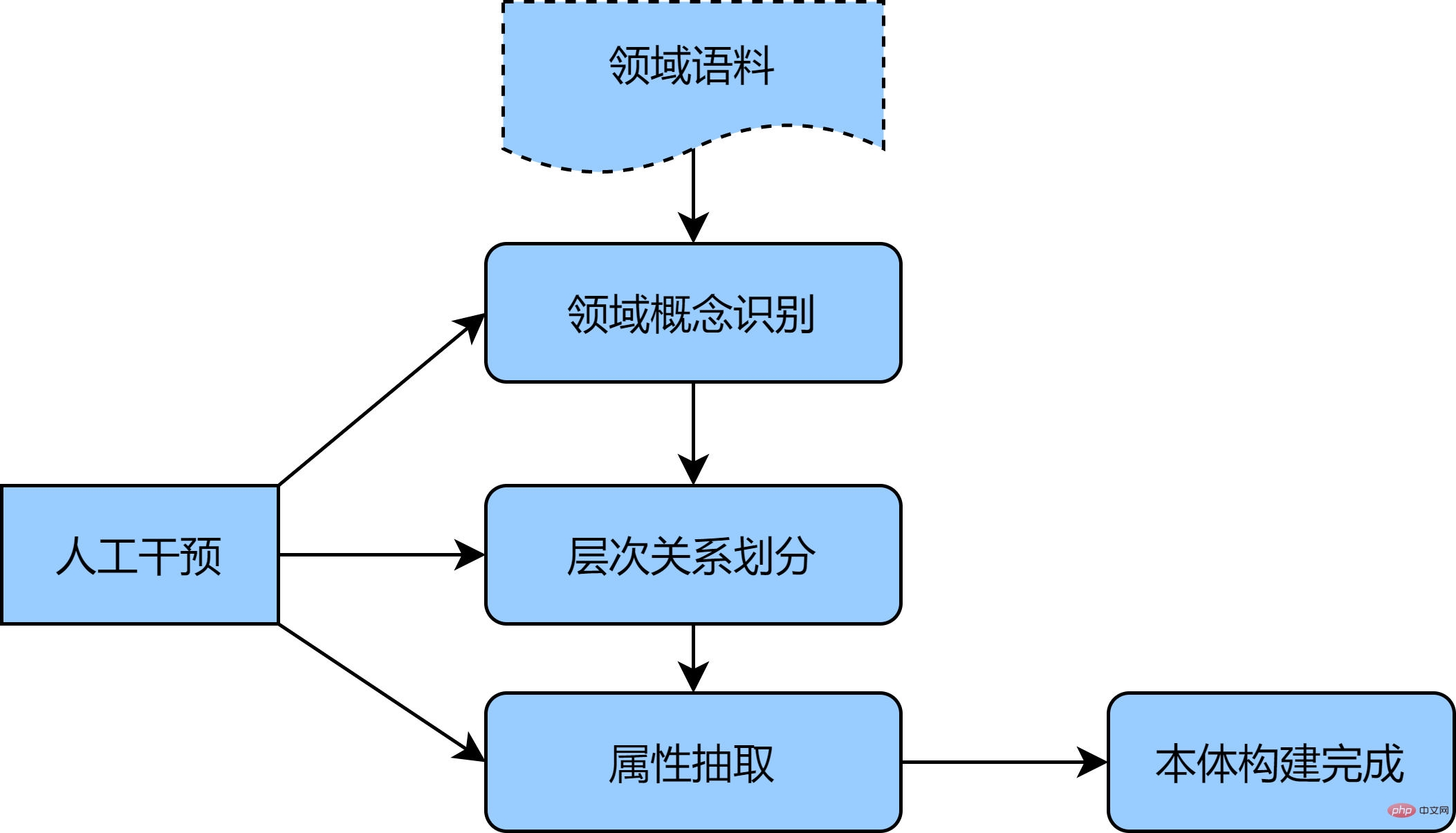
Protégé オントロジー構築ツールの使用 [2 ], オントロジーの概念は、クラス、関係、属性、インスタンスの構築を実行できます。次の図は、オントロジー構築の視覚的な例です。自動車分野のトップレベルのオントロジー概念を 3 つのカテゴリに分類: エンティティとイベント、ラベル システム:
1) エンティティ クラスは、語彙エンティティや自動車エンティティなど、特定の意味を持つ概念エンティティを表し、その中には自動車エンティティには、組織や自動車の概念などのサブエンティティ タイプが含まれます;
2) ラベル システムは、タグ システムを表しますコンテンツ分類、概念タグ、関心タグ、およびマテリアル次元で説明されるその他のタグを含む、さまざまな次元でのイベント クラス;
3) イベント クラスは 1 つまたは複数の役割の客観的事実を表し、異なる役割間には進化的な関係があります。イベントの種類。
Protégé さまざまな種類のスキーマ構成ファイルをエクスポートできます。そのうちの owl.xml 構造構成ファイルは次の図に示すとおりです。この設定ファイルは、MYSQL や JanusGraph に直接ロードして使用することで、スキーマの自動作成を実現できます。

3.2 知識の獲得
ナレッジ グラフのデータ ソースには通常、構造化データ、半構造化データ、非構造化データ。 データ ソースの種類が異なれば、知識の抽出に関連する主要なテクノロジや、解決する必要がある技術的な問題も異なります。
3.2.1 構造化知識の伝達
構造化データはグラフに対する最も直接的な知識源であり、基本的には事前変換を行うだけで利用できます。コストが最も低いため、一般にグラフデータは構造化データよりも優先されます。構造化データには複数のデータベース ソースが含まれる場合があり、通常はモデルを変換するために ETL メソッドを使用する必要があります。ETL とは、抽出、変換、読み込みを指します。抽出とは、さまざまな独自のビジネス システムからデータを読み取ることです。これがすべての作業の前提となります。 ; 変換とは、元々異質だったデータ形式を統一できるように、事前に設計されたルールに従って抽出されたデータを変換することです; ロードとは、変換されたデータを増分または完全にウェアハウス内の計画どおりのデータにインポートすることです。
上記の ETL プロセスを通じて、さまざまなソースからのデータを中間テーブルにドロップして、その後の知識の保存を容易にすることができます。次の図は、自動車シリーズのエンティティ属性と関係テーブルの図の例です:
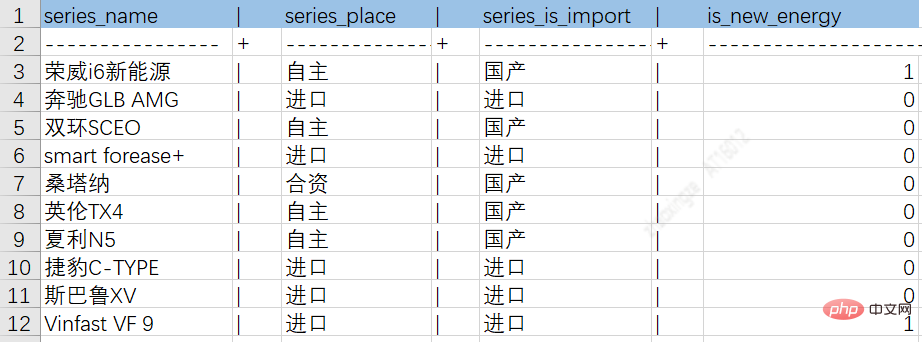
自動車シリーズとブランドの関係テーブル:
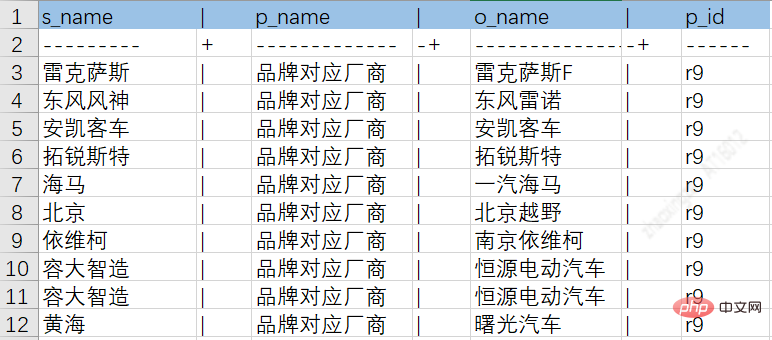
3.2.2 非構造化知識の抽出-三重抽出
構造化データに加えて、非構造化データにも大量の知識 (三重) 情報が存在します。一般に、企業内の非構造化データの量は構造化データよりもはるかに多く、非構造化ナレッジをマイニングすると、ナレッジ グラフが大幅に拡張され、強化されます。
トリプル抽出アルゴリズムの課題
問題 1: 単一フィールド内で文書の内容と形式が多様であるため、大量の注釈付きデータと高コストが必要になります
問題 2: 分野間の移行の効果は十分ではなく、分野を超えたスケーラブルな拡張にはコストが高い
モデルは基本的に、特定の業界の特定のシナリオを対象としています。シナリオによっては影響は異なりますが、大幅な減少が見られました。
ソリューションのアイデア、事前トレーニング Finetune パラダイム、事前トレーニング: 重量ベースにより、モデルは「より多くの情報を参照」し、大規模で複数の業界のラベルのないドキュメントを最大限に活用して、統合された事前トレーニングをトレーニングできます。トレーニング ベースにより、さまざまな種類のドキュメントを表現し理解するモデルの能力が強化されます。
微調整: 軽量のドキュメント構造化アルゴリズム。事前トレーニングに基づいて、軽量のドキュメント指向の構造化アルゴリズムが構築され、ラベル付けコストが削減されます。
ドキュメントの事前トレーニング方法
ドキュメントには既存の事前トレーニング モデルがあり、テキストが短い場合、Bert はテキスト全体を完全にエンコードできます。ただし、実際のドキュメントは通常比較的長く、抽出する必要がある属性値の多くは 1024 文字を超えるため、Bert のエンコーディングにより属性値が切り捨てられます。
長文事前トレーニング手法の利点と欠点
Sparse Attendance メソッドは、Self-Attendance を最適化することで O(n2) から O(n) への計算を最適化します。 . )、入力テキストの長さが大幅に改善されました。通常モデルのテキスト長は 512 から 4096 に増加しましたが、テキストが切り捨てられる断片化の問題はまだ完全には解決できません。 Baidu は、理論的に無制限のテキストをモデル化できる Recurrence Transformer メソッドを使用した ERNIE-DOC [3] を提案しました。モデリングには全ての文字情報を入力する必要があるため、非常に時間がかかります。
長いテキストに基づく上記の 2 つの事前トレーニング方法では、空間 (Spartial)、視覚 (Visual) およびその他の情報などの文書の特性は考慮されていません。そして、テキスト設計に基づく PretrainTask は、文書の論理構造設計を行わず、純粋なテキスト全体を対象として設計されています。
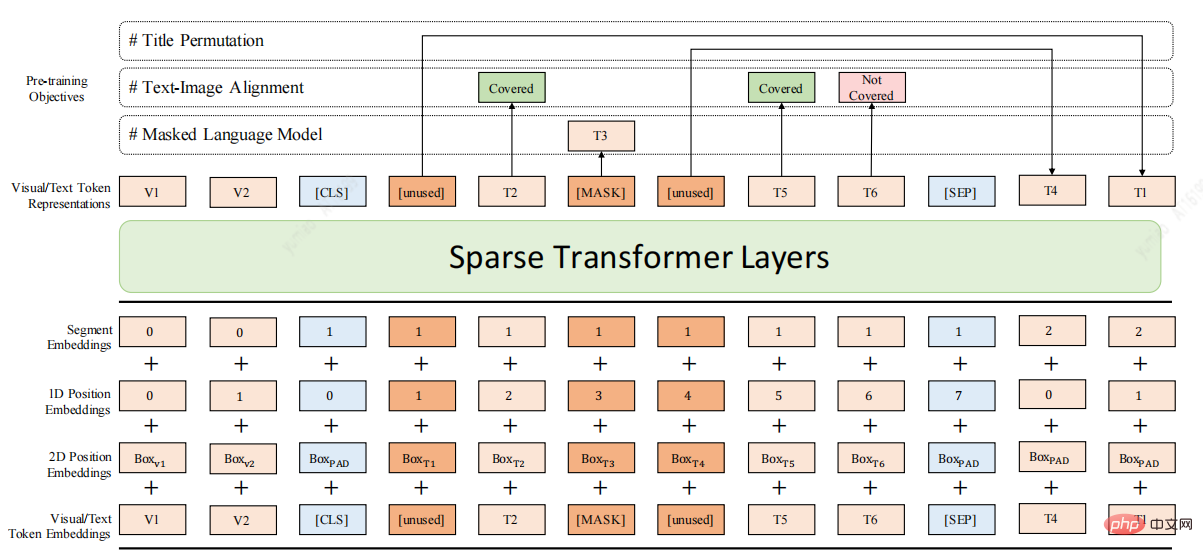
上記の欠点を考慮して、ここに長いドキュメントの事前トレーニング モデル DocBert[4]、DocBert モデル設計を示します:
大規模 (百万レベル) のラベルなしドキュメント データを事前トレーニングに使用し、テキスト セマンティクス (Text)、レイアウト情報 (Layout)、および視覚的特徴 (Visual) に基づいて自己教師あり学習タスクを構築します。 document を使用すると、モデルがドキュメントのセマンティクスと構造情報をよりよく理解できるようになります。
1.レイアウトを意識した MLM: ドキュメントのレイアウトを意識した意味論的な理解を実現するために、マスク言語モデル内のテキストの位置とフォント サイズ情報を考慮します。
2.テキストと画像の配置: ドキュメントの視覚的特徴を融合し、画像内のマスクされたテキストを再構築し、モデルがテキスト、レイアウト、画像のさまざまなモード間の配置関係を学習できるようにします。
3.タイトルの並べ替え: 自己教師ありの方法でタイトル再構築タスクを構築し、ドキュメントの論理構造を理解するモデルの能力を強化します。
4.スパース トランスフォーマー レイヤー: スパース アテンション メソッドを使用して、長いドキュメントを処理するモデルの機能を強化します。
3.2.3 車のシリーズやエンティティに関連するマイニングの概念、関心のある単語タグ
Autohome は、構造化テキストおよび非構造化テキストからトリプルを取得することに加えて、マテリアルに含まれるカテゴリ、コンセプト タグ、および興味のあるキーワード タグをマイニングし、マテリアルと車両エンティティ間の関連付けを確立して、自動車ナレッジ グラフに新しい知識をもたらします。以下では、Autohome によるコンテンツ理解の作業と考え方の一部を、分類、概念タグ、関心語タグの観点から紹介します。
分類システムは、コンテンツの説明とマテリアルの大まかな分類の基礎として機能します。確立された統一コンテンツ システムは、手動定義に基づいており、AI モデルによって分割されています。分類手法としては、能動学習を用いて分類が困難なデータにラベルを付けるほか、データ強化、敵対的トレーニング、キーワード融合などを活用して分類効果を高めています。
コンセプト ラベルの粒度は、分類ラベルと関心語ラベルの間であり、分類粒度よりも細かく、関心点の説明は関心語よりも完全です。人間の視覚とコンテンツの視覚の 3 つの側面により、ラベルの次元が強化され、ラベルの粒度が洗練されます。豊富で具体的なマテリアル タグにより、タグ ベースのモデル最適化の検索と推奨が容易になり、ユーザーや二次トラフィックを引き付けるためのタグ アウトリーチに使用できます。コンセプト タグのマイニングでは、クエリなどの重要なデータに対する機械マイニング手法の使用と一般化分析を組み合わせており、手動レビューを通じて一連のコンセプト タグを取得し、分類にマルチラベル モデルを使用します。
インタレスト ワード タグは最も詳細なタグであり、ユーザーの興味にマッピングされます。さまざまなユーザーの興味の好みに応じて、パーソナライズされた推奨事項をより適切に作成できます。キーワード マイニングでは、キー部分文字列の Keybert 抽出を含む複数の関心語マイニング手法を TextRank、positionRank、singlerank、TopicRank、MultipartiteRank などのさまざまな構文分析手法と組み合わせて使用し、関心語候補を生成します。
マイニングされた単語は比較的類似性が高く、同義語を識別する必要があるため、手作業の効率化が必要であるため、クラスタリングを使用して意味的類似性の自動識別も実行します。クラスタリングに使用される機能には、word2vec、bert emding、その他の人工的な機能が含まれます。次に、クラスタリング手法を使用し、最後に手動修正を通じて、オフラインで高品質のキーワードのバッチを生成しました。
異なる粒度のラベルについては、ラベルを車に関連付ける必要があります。まず、タイトル記事のラベルを計算し、次にタイトル記事内のエンティティを識別して、いくつかのラベルを取得します。 -Entity pseudo最後に、大量のコーパスに基づいて、共起確率の高いラベルがエンティティのラベルとしてマークされます。上記の 3 つの作業を通じて、豊富で大量のラベルを取得しました。これらのタグを車のシリーズやエンティティに関連付けることで、車のマップが大幅に充実し、メディアやユーザーの注目を集める車のタグが確立されます。
3.2.4 人的効率の向上:
トレーニング サンプルが大規模になると、より良いモデルの品質を取得する方法、ラベル付けの高コスト、および長いラベル付けサイクルを解決する方法が緊急になっています。解決すべき問題。まず、半教師あり学習を使用して、事前トレーニングに大量のラベルなしデータを使用できます。次に、能動学習手法を使用してアノテーション付きデータの値を最大化し、アノテーション用の高情報サンプルを繰り返し選択します。最後に、リモート監視を使用して、既存の知識の価値を活用し、タスク間の相関関係を発見できます。たとえば、マップとタイトルを取得した後、リモート監視方法を使用して、マップに基づいて NER トレーニング データを構築できます。
3.3 知識のストレージ
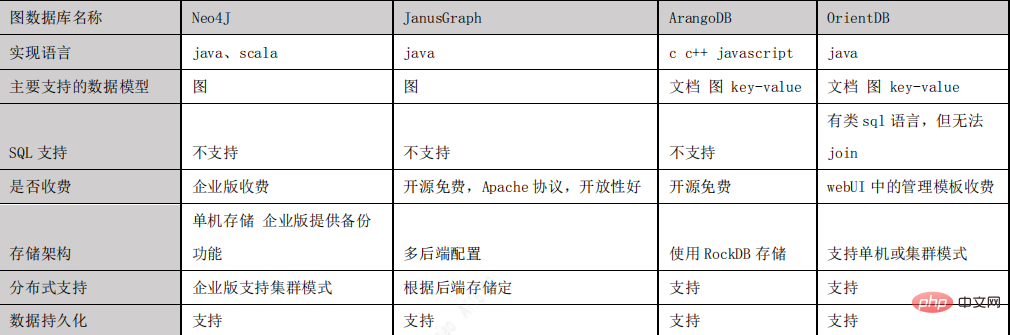
ナレッジ グラフ内の知識は RDF 構造を通じて表現され、その基本単位はファクトです。各ファクトはトリプレット (S、P、O) であり、実際のシステムでは、さまざまな保存方法に従って、ナレッジ グラフの保存は RDF テーブル構造に基づく保存と属性グラフ構造に基づく保存に分けることができます。画像ギャラリーはほとんどの場合、属性グラフ構造を使用して保存されます。一般的なストレージ システムには、Neo4j、JanusGraph、OrtentDB、InfoGrid などが含まれます。
グラフ データベースの選択
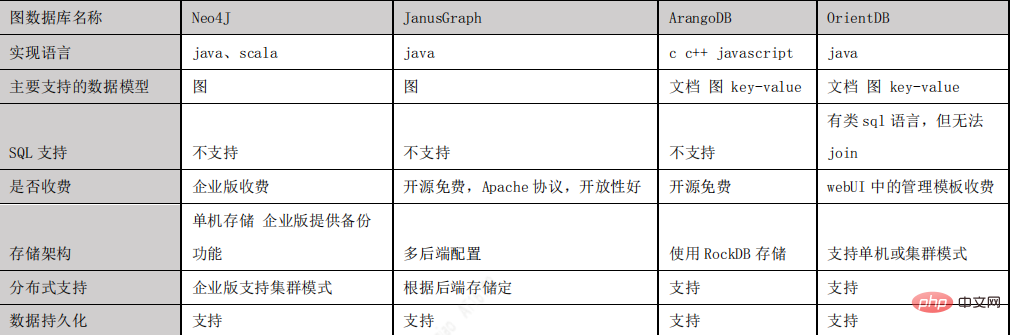
JanusGraph を Neo4J、ArangoDB、OrientDB などのいくつかの主流グラフ データベースと比較した後、最終的にプロジェクトのグラフ データベースとして JanusGraph を選択しました。理由:
- Apache 2 ライセンス契約に基づいたオープンソースであり、オープン性が優れています。
- グローバル グラフ分析およびバッチ グラフ処理のための Hadoop フレームワークの使用をサポートします。
- 大規模な同時トランザクション処理とグラフ操作処理をサポートします。マシンを追加して JanusGraph のトランザクション処理機能を水平方向に拡張することで、大規模なグラフ上の複雑なクエリをミリ秒レベルで処理できるようになります。
- Apache TinkerPop で記述された現在一般的なプロパティ グラフ データ モデルのネイティブ サポート。
- グラフトラバーサル言語 Gremlin をネイティブにサポートします。
- 次の図は、主流のグラフ データベースの比較です。
Janusgraph の概要
JanusGraph[5] は、グラフデータベースエンジン。コンパクトなグラフのシリアル化、豊富なグラフ データ モデリング、効率的なクエリの実行に重点を置いています。ギャラリー スキーマの構成は、次の式で表すことができます。
janusgraph スキーマ = 頂点ラベル エッジ ラベル プロパティ キー
ここで、プロパティ キーは通常、グラフ インデックスに使用されることに注意してください。 。
グラフ クエリのパフォーマンスを向上させるために、janusgraph はインデックスを確立し、インデックスはグラフ インデックスと頂点中心のインデックスに分かれています。グラフインデックスには、複合インデックス (Composite Index) と混合インデックス (Mixed Index) があり、
複合インデックスは均等検索に限定されます。 (結合インデックスは外部インデックス バックエンドを構成する必要はなく、メイン ストレージ バックエンドによってサポートされます (もちろん、hbase、Cassandra、および Berkeley も構成できます))
例:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">mgmt</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildIndex</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'byNameAndAgeComposite'</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Vertex</span>.<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">class</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildCompositeIndex</span>() <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#构建一个组合索引“name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">-</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age”</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'age'</span>, <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">30</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'小明'</span>)<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#查找</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">名字为小明年龄30的节点</span>
ハイブリッド インデックスでは、等価以外の複数条件クエリをサポートするバックエンド エンド インデックスとして ES が必要です (等価クエリもサポートされていますが、等価クエリ、結合インデックスの方が高速です)。単語の分割が必要かどうかに応じて、全文検索と文字列検索に分けられます。
JanusGraph データ ストレージ モデル
Janusgraph がデータを保存する方法を理解することは、ライブラリをより有効に活用するのに役立ちます。 。 JanusGraph はグラフを隣接リスト形式で保存します。これは、グラフが頂点とその隣接リストのコレクションとして保存されることを意味します。
頂点の隣接リストには、頂点のすべてのインシデント エッジ (および属性) が含まれます。
#JanusGraph は、基礎となるストレージ バックエンドに各隣接リストを行として保存します。 (64 ビット) 頂点 ID (JanusGraph によって各頂点に一意に割り当てられる) は、頂点の隣接リストを含む行を指すキーです。
各エッジと属性は行内の個別のセルとして保存されるため、効率的な挿入と削除が可能になります。したがって、特定のストレージ バックエンドで行ごとに許可されるセルの最大数は、JanusGraph がそのバックエンドでサポートできる頂点の最大次数でもあります。
ストレージ バックエンドがキー順序をサポートしている場合、隣接リストは頂点 ID によって並べ替えられ、JanusGraph は頂点 ID を割り当ててグラフを効果的に分割できます。頻繁にアクセスする頂点の絶対差が小さい ID を持つように ID を割り当てます。
3.4 GraphQuery サービス
Janusgraph はグラフ検索に gremlin 言語を使用します。統合されたグラフ クエリ サービスを提供します。外部ユーザーは特定の実装を気にする必要はありませんgremlin 言語の、クエリに共通のインターフェイスを使用します。これを、条件付き検索インターフェイス、ノード中心の外部クエリ、およびノード間パス クエリ インターフェイスの 3 つのインターフェイスに分割します。次に、gremlin の実装例をいくつか示します。
- 条件付き検索:販売台数が約 100,000 台の最高の車をクエリします: # #
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">gt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">12</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">order</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'sales'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">desc</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">limit</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">1</span>)
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span>{<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">price</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sales</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">45767</span>]}- ノードを中心として外側にクエリします。: クエリは Xiao Ming、2 度ノードを中心としています
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">times</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">2</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>()
- ノード間パス クエリ: Xiao Ming に 2 つの記事を勧めます。これら 2 つの記事はそれぞれカローラとシルフィを紹介します。Xiao Ming とこれら 2 つの記事のパスをクエリします:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">simplePath</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">until</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">or</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'kaluola'</span>),<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'xuanyi'</span>))).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"name"</span>)
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">kaluola</span>]<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>]
3. 推奨アプリケーションのナレッジ グラフ
ナレッジ グラフには大量の非欧州データが含まれています。KG に基づく推奨アプリケーションは、非欧州データを効果的に使用して改善を図っています。レコメンドシステムの精度を高め、従来のシステムでは達成できない効果をレコメンドシステムに実現させます。 KG に基づく推奨事項は、KG 表現技術 (KGE)、パスベースの手法、およびグラフ ニューラル ネットワークに基づく 3 つのカテゴリに分類できます。 この章では、コールド スタート、理由、推奨システムでのランキングという 3 つの側面から KG のアプリケーションと論文を紹介します。
3.1 コールド スタートの推奨におけるナレッジ グラフの適用
ナレッジ グラフは、ユーザーとアイテムのインタラクションから KG に隠された高次の関係をモデル化でき、これは問題の優れた解決策です。限られた数の動作を呼び出すことによって生じるデータの希薄性は、コールド スタートの問題を解決するために適用できます。業界ではこの問題に関する関連研究も行われています。
Sang et al. [6] は、KG コンテキストとユーザーの長期的な関係依存関係を利用する、ナレッジ グラフ強化残差再帰ニューラル協調フィルタリング (KGNCF-RRN) と呼ばれるデュアルチャネル ニューラル インタラクション手法を提案しました。アイテムが相互作用して推奨事項を作成します。
(1) KG コンテキスト インタラクション チャネルの場合、残差リカレント ネットワーク (RRN) がコンテキスト ベースのパス埋め込みを構築するために提案され、残差学習は従来のリカレント ニューラル ネットワーク (RNN) に統合されて効果的にエンコーディングされます。 KG の長期的な関係依存関係。次に、セルフ アテンション ネットワークをパスの埋め込みに適用して、さまざまなユーザー インタラクション動作の曖昧さを捉えます。
(2) ユーザーとアイテムのインタラクション チャネルの場合、ユーザーとアイテムの埋め込みが新しく設計された 2 次元インタラクション ダイアグラムに入力されます。
(3) 最後に、デュアルチャネル ニューラル インタラクション マトリックスに加えて、畳み込みニューラル ネットワークを使用して、ユーザーとアイテム間の複雑な相関関係を学習します。この方法では、豊富なセマンティック情報を取得できるほか、ユーザーと推奨項目の間の複雑な暗黙的な関係も取得できます。
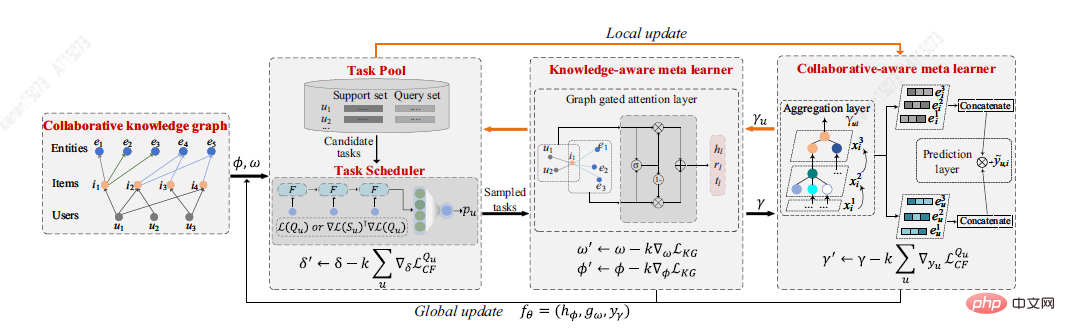
Du Y et al. [7] は、協調性を意識したメタ学習者と知識を意識したメタ学習者を含む、メタ学習フレームワーク MetaKG に基づいて、コールド スタート問題に対する新しい解決策を提案しました。 、ユーザーの好みとエンティティのコールド スタートの知識を取得します。共同作業を意識したメタ学習者の学習タスクは、各ユーザーの好みの知識表現を集約することを目的としています。対照的に、知識認識メタ学習者の学習タスクは、ユーザーが好むさまざまな知識表現をグローバルに一般化することです。 2 人の学習者の指導の下、MetaKG は高次の協調関係と意味表現を効果的にキャプチャでき、コールド スタート シナリオに簡単に適応できます。さらに、ノイズ情報によるモデルの干渉を防ぐために、学習用のKG情報を適応的に選択できる適応タスクも設計しました。 MetaKG アーキテクチャを次の図に示します。
3.2 推奨理由の生成におけるナレッジ グラフの適用
推奨理由により、推奨システムの解釈可能性が向上し、ユーザーは次のことを行うことができます。理解する 推奨結果を生成するための計算プロセスによって、アイテムが人気がある理由も説明できます。ユーザーは、推奨理由を通じて推奨結果を生成する原理を理解しているため、システムの推奨結果に対するユーザーの信頼が高まり、推奨エラーが発生した場合の誤った結果に対する耐性が高まります。
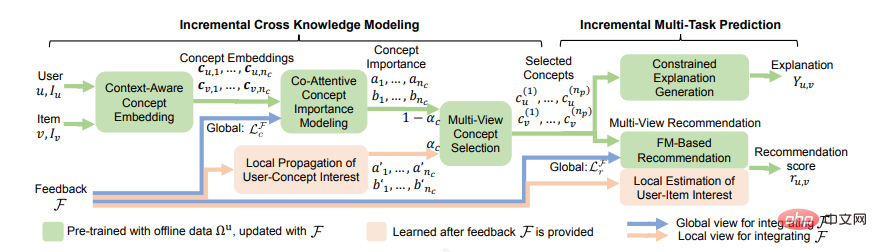
最も初期の解釈可能な推奨事項はテンプレートに基づいていました。テンプレートの利点は、読みやすさと高精度が保証されることです。ただし、テンプレートは手動で並べ替える必要があり、あまり汎用的ではないため、繰り返しの印象を与えます。その後、プリセットを必要としない自由形式のフォームが開発され、ナレッジ グラフが追加されました。パスの 1 つは説明として使用され、アノテーションとともに、KG パスを組み合わせたいくつかの生成方法がありました。各ポイントまたはモデルで選択されたエッジは、ユーザーにデモンストレーションできる推論プロセスでした。最近、Chen Z [8] らは、推奨の予測、説明の生成、およびユーザー フィードバックの統合の間の密接な連携を実現できる増分マルチタスク学習フレームワーク ECR を提案しました。 2 つの部分から構成されます。最初の「増分クロスナレッジモデリング」では、転送されたクロスナレッジを推奨タスクと説明タスクで学習し、増分学習によって更新されるクロスナレッジの活用方法を説明します。 2 番目の部分である増分マルチタスク予測では、クロスナレッジに基づいて説明を生成する方法と、クロスナレッジとユーザーのフィードバックに基づいて推奨スコアを予測する方法について説明します。
3.3 レコメンデーションソートにおけるナレッジグラフの適用
KG はユーザーを作成できます。アイテム間の相互作用は、uesr-item グラフを組み合わせます。と KG を 1 つの大きなグラフにまとめ、項目間の高次のつながりを捉えることができます。従来のレコメンデーション手法は、教師あり学習タスクとして問題をモデル化するものですが、この手法では項目間の本質的な関係(カムリとアコードの競合製品関係など)が無視され、ユーザーの行動から相乗効果のあるシグナルを得ることができません。 KGアプリケーションに関する論文2件をおすすめランキングで紹介します。
Wang[9] らは KGAT アルゴリズムを設計しました。まず、彼らは GNN を使用して埋め込みを反復的に伝播および更新し、高次の接続を迅速に取得できるようにしました。次に、集計中にアテンション メカニズムを使用してそれぞれの接続を学習しました近傍の重みは高次の接続の重要性を反映しており、最終的にユーザーアイテムの N 個の暗黙的表現が N 次の伝播更新を通じて取得され、異なる層は異なる次数の接続情報を表します。 KGAT は、より豊富で不特定の高次接続をキャプチャできます。
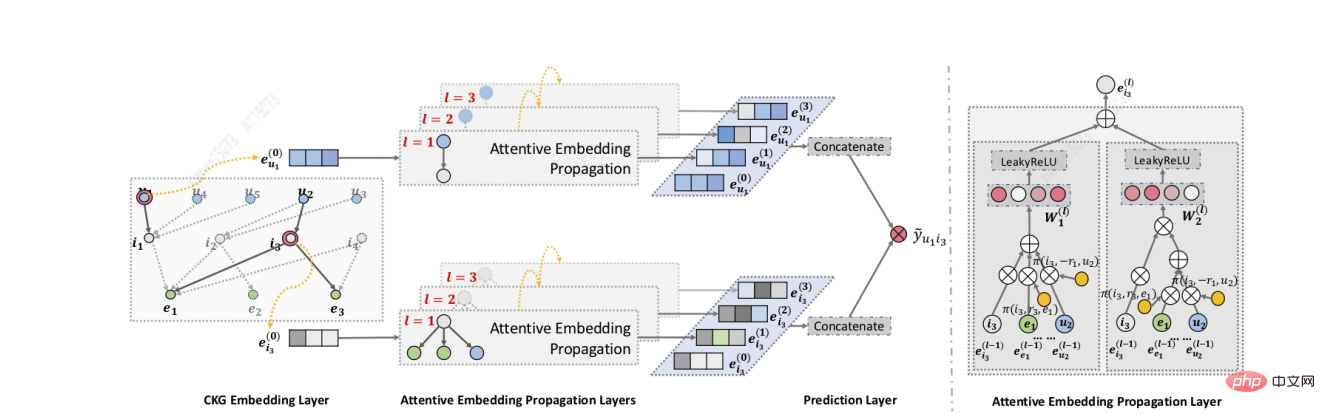
Zhang[20] らは、RippleNet モデルを提案しました。重要なアイデアは、関心の伝播です。RippleNet は、ユーザーの過去の関心を KG のシードセットとして使用し、ユーザーを拡張します。 KG 上のユーザーの関心の分布を形成するために、KG の接続に沿って関心を外側に向けます。 RippleNet の最大の利点は、メタパスやメタグラフを手動で設計することなく、ユーザーが履歴内でクリックしたアイテムから候補アイテムまでの可能なパスを自動的にマイニングできることです。
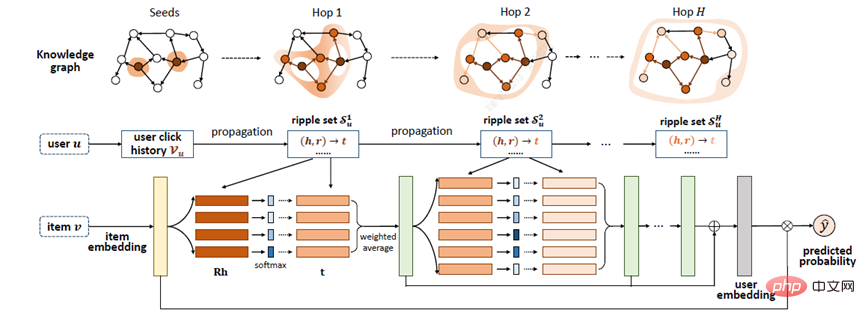
#RippleNet は、ユーザー U とアイテム V を入力として受け取り、ユーザー U がアイテム V をクリックする予測確率を出力します。ユーザー U の場合、その歴史的関心 V_{u} をシードとして、最初の開始点は 2 であり、その後周囲に広がり続けることが図でわかります。与えられた itemV と、ユーザー U の 1 ホップ リップル セット V_{u_{}^{1}} 内の各トリプル left(h_{i},r_{i},t_{i}right) を比較して、関連する確率を割り当てますノード h_{i} とトリプルの関係 r_{i} に接続します。
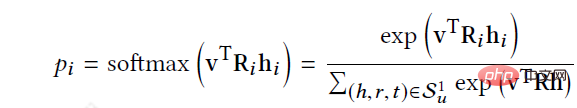
相関確率を取得した後、V_{u_{}^{1}} のトリプレットの末尾に対応する相関確率を乗算して加重和を求め、次の結果を取得します。ユーザー U のこれまでの関心は、V に対する一次応答です。ユーザーの関心は、V_{u} から o_{u}^{1}、o_{u}^{2}、o_{u}^{3 に転送されます。 ...o_{u}^{n} を計算すると、アイテム V に関する U の特性を計算して、U のすべての注文応答を融合できます。
4. 概要
要約すると、主に推奨事項に焦点を当て、グラフ構築の詳細なプロセスを紹介し、それに伴う困難と課題を分析しました。同時に、多くの重要な作業を要約し、具体的な解決策、アイデア、提案も提供します。最後に、ナレッジ グラフを含むアプリケーション、特にコールド スタート、解釈可能性、リコール ランキングなどのレコメンデーション分野におけるナレッジ グラフの役割と使用法を紹介します。
引用:
[1] キム S、オー S G.オントロジー品質評価の評価基準の抽出と適用[J]. Library Hi Tech、2019.
[2]弟子: https://www.php.cn/link/9d405c24be657bbf7a5244815a908922
[3] Ding S、Shang J、Wang S、他 ERNIE-DOC: The Retrospective Long-Document Modeling Transformer[J]. 2020.
[4] DocBert、[1] Adhikari A 、Ram A、Tang R、他 DocBERT: 文書分類のための BERT[J]. 2019.
[5]JanusGraph、 https://www.php.cn /link/fc0de4e0396fff257ea362983c2dda5a
[6] Sang L、Xu M、Qian S、他、ナレッジ グラフは残留リカレント ネットワークによるニューラル協調フィルタリングを強化[J]、ニューロコンピューティング、2021 、454: 417-429.
[7] Du Y 、Zhu X 、Chen L ら、MetaKG: コールドスタート推奨のためのナレッジ グラフに関するメタ学習[J]. arXiv e-prints、 2022.
[8] Chen Z 、Wang X 、Xie X ら、説明可能な会話の推奨に向けて[C]// 第 29 回人工知能に関する国際共同会議および第 17 回環太平洋人工知能に関する国際会議{IJCAI-PRICAI-20. 2020.
[9] Wang X 、He X 、Cao Y ら、KGAT: Knowledge Graph Attendance Network for Recommendation[J]. ACM、2019.
[10]Wang H、Zhang F、Wang J、他 RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems[J]. ACM、2018.
以上が推奨のための自動車ナレッジグラフの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
