

ジェフ・ディーンらによる新作: 言語モデルを別の角度から見るとスケールが足りず発見できない

近年、言語モデルは自然言語処理 (NLP) に革命的な影響を与えています。パラメーターなどの言語モデルを拡張すると、さまざまな下流の NLP タスクのパフォーマンスとサンプル効率が向上することが知られています。多くの場合、スケーリングがパフォーマンスに及ぼす影響はスケーリングの法則によって予測できることが多く、ほとんどの研究者は予測可能な現象を研究してきました。
それどころか、Jeff Dean、Percy Liang などを含む 16 人の研究者が共同して論文「Emergent Abilities of Large Language Models」を執筆し、大規模モデルの予測不可能性の現象と、これは、大規模言語モデルの創発的能力と呼ばれます。いわゆる創発とは、ある現象が小さなモデルには存在しないが、より大きなモデルには存在することを意味しており、このモデルの能力が創発であると考えられています。
アイデアとしての創発は、物理学、生物学、コンピューター サイエンスなどの分野で長い間議論されてきました。この論文は、スタインハルトの研究に基づいた創発の一般的な定義から始まります。この理論のルーツは、1972 年にノーベル賞受賞者で物理学者のフィリップ・アンダーソンが執筆した「More Is Different」という論文にあります。
この記事では、トレーニング計算とモデル パラメーターによって測定されるモデル サイズの出現について説明します。具体的には、この論文では、大規模言語モデルの創発的機能を、小規模モデルには存在しないが、大規模モデルには存在する機能として定義します。したがって、小規模な言語モデルのパフォーマンス向上を単純に外挿するだけでは大規模モデルを予測することはできません。スケールモデル。この研究では、これまでのさまざまな研究で観察されたモデルの創発的な機能を調査し、それらをスモールショット キューイングやブースト キューイングなどの設定に分類します。
モデルのこの新たな能力は、なぜこれらの能力が獲得されるのか、そして大規模なスケールがより新たな能力を獲得するのかどうかについての将来の研究を刺激し、研究の重要性を強調します。

#プロンプト タスクの小さなサンプル
この記事では、最初にプロンプト パラダイムにおける創発的な能力について説明します。たとえば、GPT-3 プロンプトでは、事前トレーニングされた言語モデルのタスク プロンプトが与えられると、モデルはさらなるトレーニングやパラメーターの勾配更新を行わずに応答を完了できます。さらに、Brown らは、モデルのコンテキスト (入力) 内のいくつかの入出力例をプロンプト (プリアンブル) として使用し、目に見えない推論タスクを実行するようモデルに依頼する、小規模サンプル プロンプティングを提案しました。図 1 はプロンプトの例を示しています。
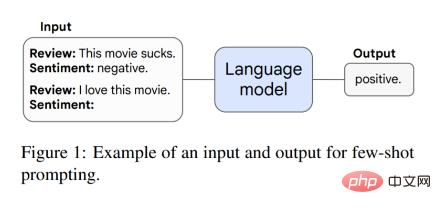

モデルに確率的なパフォーマンスがあり、ある程度の規模がある場合、小さなサンプルでタスクを実行できます。このとき、創発的な能力が現れ、モデルのパフォーマンスはランダムなパフォーマンスよりもはるかに高くなります。以下の図は、5 つの言語モデル シリーズ (LaMDA、GPT-3、Gopher、Chinchilla、PaLM) の 8 つの新しい機能を示しています。

BIG-Bench: 図 2A ~ D は、BIG-Bench からの 4 つの緊急の小規模サンプル プロンプト タスクを示しています。 Bench は、200 を超える言語モデル評価ベンチマークのスイートです。図 2A は、3 桁の数値の加算と減算、および 2 桁の数値の乗算をテストする算術ベンチマークを示しています。表 1 は、BIG-Bench のさらに新しい機能を示しています。

現在、小さなサンプル ヒントが大規模な言語モデルと対話する最も一般的な方法ですが、最近の研究では、言語モデルの機能をさらに強化するために、他のいくつかのヒントと微調整戦略が提案されています。また、この記事では、十分な規模のモデルに適用される前に、改善が見られない、または有害であるテクノロジを、新たな機能であるとみなします。
複数ステップの推論: 言語モデルと NLP モデルの場合、推論タスク、特に複数ステップの推論を伴うタスクは常に大きな課題でした。思考連鎖と呼ばれる最近の刺激戦略により、最終的な答えを与える前に一連の中間ステップを生成するように言語モデルを誘導することで、言語モデルがこの種の問題を解決できるようになります。図 3A に示すように、1023 トレーニング FLOP (約 100B パラメータ) に拡張した場合、思考連鎖プロンプトは中間ステップなしで標準プロンプトを超えるだけでした。
命令 (命令に従う): 図 3B に示すように、Wei らは、トレーニング FLOP が 7・10^21 (8B パラメーター) 以下の場合、命令は適切であることを発見しました。 -tuning (命令に従う) -finetuning) 手法はモデルのパフォーマンスに悪影響を及ぼし、トレーニング FLOP を 10^23 (~100B パラメーター) に拡張する場合にのみパフォーマンスが向上します。
プログラムの実行: 図 3C に示すように、8 ビット加算のドメイン内評価では、スクラッチパッドの使用は ~9 · 10^19 トレーニング FLOP (40M パラメーター) またはより大きなモデル。図 3D は、これらのモデルがドメイン外 9 ビット加算にも一般化できることを示しています。これは、〜1.3 · 10^20 トレーニング FLOP (100M パラメーター) で発生します。

以上がジェフ・ディーンらによる新作: 言語モデルを別の角度から見るとスケールが足りず発見できないの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7345
7345
 15
1627
14
1352
46
1265
25
1214
29
15
1627
14
1352
46
1265
25
1214
29

 GoおよびViperライブラリを使用するときにポインターを渡す必要があるのはなぜですか?
Apr 02, 2025 pm 04:00 PM
GoおよびViperライブラリを使用するときにポインターを渡す必要があるのはなぜですか?
Apr 02, 2025 pm 04:00 PM
ポインター構文とviperライブラリの使用における問題への取り組みGO言語でプログラミングするとき、特にポインターの構文と使用を理解することが重要です...
 携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
モバイルには、単純で直接無料のXMLからPDFツールはありません。必要なデータ視覚化プロセスには、複雑なデータの理解とレンダリングが含まれ、市場のいわゆる「無料」ツールのほとんどは経験がありません。コンピューター側のツールを使用したり、クラウドサービスを使用したり、アプリを開発してより信頼性の高い変換効果を取得することをお勧めします。
 GO言語の範囲を使用してマップを通過してマップを保存するのに、なぜすべての値が最後の要素になるのですか?
Apr 02, 2025 pm 04:09 PM
GO言語の範囲を使用してマップを通過してマップを保存するのに、なぜすべての値が最後の要素になるのですか?
Apr 02, 2025 pm 04:09 PM
GOのマップイテレーションにより、すべての値が最後の要素になるのはなぜですか? Go言語では、いくつかのインタビューの質問に直面したとき、あなたはしばしば地図に遭遇します...
 XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XMLの美化は、合理的なインデンテーション、ラインブレーク、タグ組織など、本質的に読みやすさを向上させています。原則は、XMLツリーを通過し、レベルに応じてインデントを追加し、テキストを含む空のタグとタグを処理することです。 PythonのXML.ETREE.ELEMENTTREEライブラリは、上記の美化プロセスを実装できる便利なchile_xml()関数を提供します。
 GOモジュールの下でカスタムパッケージを正しくインポートする方法は?
Apr 02, 2025 pm 03:42 PM
GOモジュールの下でカスタムパッケージを正しくインポートする方法は?
Apr 02, 2025 pm 03:42 PM
GO言語開発では、カスタムパッケージを適切に導入することが重要なステップです。この記事では、「ゴラン...
 GOでロックを使用するコードが時々パニックにつながるのはなぜですか?
Apr 02, 2025 pm 04:36 PM
GOでロックを使用するコードが時々パニックにつながるのはなぜですか?
Apr 02, 2025 pm 04:36 PM
ロックを使用すると、なぜパニックを引き起こすのですか?興味深い質問を見てみましょう。コードにロックが追加されたとしても、時々...
 XML形式を確認する方法
Apr 02, 2025 pm 10:00 PM
XML形式を確認する方法
Apr 02, 2025 pm 10:00 PM
XML形式の検証には、その構造とDTDまたはスキーマへのコンプライアンスを確認することが含まれます。 ElementTree(基本的な構文チェック)やLXML(より強力な検証、XSDサポート)など、XMLパーサーが必要です。検証プロセスでは、XMLファイルを解析し、XSDスキーマをロードし、AssertValidメソッドを実行してエラーが検出されたときに例外をスローすることが含まれます。 XML形式の確認には、さまざまな例外を処理し、XSDスキーマ言語に関する洞察を得る必要があります。
 GO言語では、工場モードを介して異なるインターフェイスの異なるパブリックメソッドパラメータータイプの問題を解決する方法は?
Apr 02, 2025 pm 04:39 PM
GO言語では、工場モードを介して異なるインターフェイスの異なるパブリックメソッドパラメータータイプの問題を解決する方法は?
Apr 02, 2025 pm 04:39 PM
GO言語では、共通のインターフェイスを定義し、インターフェイスによって実装されたメソッドを制約し、同時に異なるインターフェイスの同じ方法と異なるパラメータータイプを処理する方法...
