

機械学習は高品質のソフトウェア エンジニアリングを強化します

翻訳者 | Zhu Xianzhong
##改訂 | Sun Shujuan
はじめに一般的に、ソフトウェア テストは次のような傾向があります。比較的単純です: すべての入力 => 既知の出力。しかし、ソフトウェア テストの歴史を振り返ると、多くのテストが推測のレベルに留まっていることがよくあります。つまり、テスト中に開発者はユーザーの操作プロセスを想像し、予想される負荷を見積もり、それにかかる時間を分析してからテストを実行し、現在の結果をベースラインの回答と比較します。回帰がないことが判明した場合は、現在のビルド計画が正しいと見なされ、後続のテストを続行します。回帰があった場合は、それを返します。ほとんどの場合、出力はすでにわかっていますが、出力をより明確に定義する必要があります。回帰の境界は明確であり、それほど曖昧ではありません。実際、ここで機械学習 (ML) システムと予測分析が登場し、曖昧さを解消します。
テストが完了したら、パフォーマンス エンジニアは結果の算術平均と幾何平均だけでなく、関連するパーセンテージ データも確認します。たとえば、システムの実行中、最も遅いリクエストの 10% はシステム エラーが原因であることがよくあります。このエラーは、常にプログラムの速度に影響を与える状態を引き起こします。
データ内で利用可能な属性を手動で関連付けることもできますが、ML の方がデータ属性をより速くリンクできる可能性があります。不正なリクエストの 10% を引き起こす条件を特定した後、パフォーマンス エンジニアは、動作を再現するテスト シナリオを構築できます。修正の前後にテストを実行すると、修正が修正されたことを確認できます。

#機械学習とデータ サイエンスのパフォーマンス
機械学習はソフトウェア開発の促進に役立ち、開発テクノロジーをより堅牢にし、さまざまな分野や業界のユーザーのニーズに応えやすくします。パイプラインや環境からディープラーニング アルゴリズムにデータをフィードすることで、因果関係のパターンを明らかにできます。予測分析アルゴリズムとパフォーマンス エンジニアリング手法を組み合わせることで、より効率的かつ高速なスループットが可能になり、エンド ユーザーが自然なシナリオでソフトウェアをどのように使用するかについての洞察が得られ、開発者が運用環境で欠陥製品が使用される可能性を減らすことができます。問題とその原因を早い段階で特定することで、開発ライフサイクルの早い段階で問題を修正し、実稼働への影響を防ぐことができます。全体として、予測分析を活用してアプリケーションのパフォーマンスを向上させる方法をいくつか紹介します。
- 根本原因を特定します。 機械学習技術を使用して可用性やパフォーマンスの問題の根本原因を特定し、注意が必要な他の領域に焦点を当てることができます。その後、予測分析により各クラスターのさまざまな特性を分析し、理想的なパフォーマンスを達成し、ボトルネックを回避するために必要な変更についての洞察を提供します。
- アプリケーションの健全性を監視します。 機械学習テクノロジーを使用してリアルタイムのアプリケーション監視を実行すると、企業はシステム パフォーマンスの低下を適時に検出し、迅速に対応できます。ほとんどのアプリケーションは、アプリケーション全体のステータスを取得するために複数のサービスに依存しています。予測分析モデルは、アプリケーションが正常に実行されているときにデータを関連付けて分析し、受信データが外れ値であるかどうかを識別できます。
- ユーザー負荷を予測します。 当社では、将来アプリケーションにアクセスするユーザー数に対応できるよう、インフラストラクチャのサイズをピーク ユーザー トラフィックに依存しています。このアプローチには変化やその他の未知の要因が考慮されていないため、限界があります。予測分析により、ユーザー負荷を視覚化し、対応に向けてより適切に準備できるようになり、チームがインフラストラクチャのニーズと容量使用率を計画するのに役立ちます。
- 手遅れになる前にダウンタイムを予測します。 アプリケーションのダウンタイムや機能停止を事前に予測することは、予防策を講じるのに役立ちます。予測分析モデルは、以前の停止シナリオに従い、同様の状況を監視し続けて、将来の停止を予測します。
- しきい値の表示をやめて、データの分析を始めてください。 可観測性と監視によって生成される大量のデータは、1 週間に最大数百メガバイトを必要とします。最新の分析ツールを使用する場合でも、何を探しているのかを事前に知っておく必要があります。その結果、チームはデータを直接見るのではなく、アクションのトリガーとしてしきい値を設定することになります。成熟したチームでも、データを詳しく調べるのではなく、例外を探します。これを軽減するために、モデルを利用可能なデータ ソースと統合します。次に、モデルはデータをフィルター処理し、時間の経過とともにしきい値を計算します。この手法を使用すると、モデルに履歴データが入力されて集約され、人間が設定するのではなく季節性に基づいたしきい値が提供されます。アルゴリズムに基づいてしきい値を設定すると、トリガーされるアラートの数が減りますが、その一方で、これはより優れた実用性とより高い価値にもつながります。
- データセット全体を分析し、関連付けます。 データはほとんどが時系列であるため、時間の経過とともに変化する個々の変数を確認するのが簡単になります。多くの傾向は、複数の指標の相互作用から生じます。たとえば、応答時間は、同じターゲット上でさまざまなトランザクションが同時に発生している場合にのみ低下します。人間にとって、これはほぼ不可能ですが、適切にトレーニングされたアルゴリズムは、これらの相関関係を発見するのに役立ちます。
予測分析におけるデータの重要性
「ビッグ データ」は通常、データ セットを指します。はい、それは大規模なデータセットであり、速度は急速に向上し、内容は大きく変化します。このようなデータの分析には、そこからパターンや情報を抽出できるようにするための特殊な方法が必要です。近年、ストレージ、プロセッサ、プロセスの並列処理、およびアルゴリズム設計の改善により、システムは大量のデータを適切な時間内に処理できるようになり、これらの方法がより幅広く使用できるようになりました。有意義な結果を得るには、データの一貫性を確保する必要があります。
たとえば、各プロジェクトは同じランキング システムを使用する必要があるため、あるプロジェクトがキー値として 1 を使用し、別のプロジェクトが 5 を使用する場合、たとえば「DEFCON 5」を使用する人は「DEFCON 1」を意味します。 ”; その場合、処理前に値を正規化する必要があります。予測アルゴリズムは、アルゴリズムと、アルゴリズムが入力するデータで構成されます。ソフトウェア開発では、最近まで削除されるのを待ってアイドル状態にあった大量のデータが生成されます。ただし、予測分析アルゴリズムはこれらのファイルを処理して、検出できないパターンについてこのデータに基づいて質問し、回答することができます。たとえば、「未知のものをテストするのは時間を無駄にしていますか? 使用シナリオは?」などです。
- パフォーマンスの向上はユーザーの幸福度とどのように関係するのでしょうか?
- 特定の欠陥を修正するにはどれくらい時間がかかりますか?
- #これらの質問とその回答は、何が起こる可能性があるかをより深く理解するために、予測分析が目的としています。
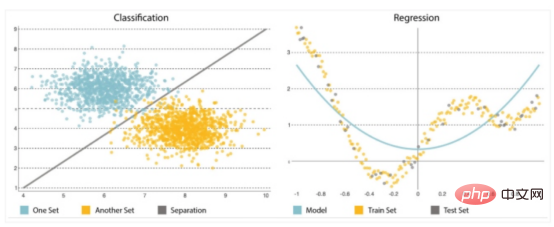
- 分類: 分類は、セットの結果を予測するために使用されます。入力データ まず、コレクションをさまざまなカテゴリに分割します。
- 回帰: 回帰は、出力変数が実数値のセットである場合に、セットの結果を予測するために使用されます。入力データを処理して予測を行います。たとえば、使用されているメモリの量、開発者が作成したコード行などです。最も一般的に使用される予測モデルは、ニューラル ネットワーク、デシジョン ツリー、線形回帰およびロジスティック回帰です。
- 分析環境の欠陥
- カスタマー エクスペリエンスに対する評価の影響
- 問題のパターンを特定する
- より正確なテスト シナリオなどを作成する
- 欠陥の種類
- 欠陥が発見された段階
- 欠陥の根本原因は何ですか
- 欠陥は再現可能ですか
アルゴリズム
予測分析のもう 1 つの主要なコンポーネントはアルゴリズムであり、慎重に選択または実装する必要があります。モデルはますます複雑になり、入力データの変化にますます敏感になり、予測を歪める可能性があるため、シンプルに始めることが重要です。分類と回帰という 2 種類の問題を解決できます (図 2 を参照)。
ニューラル ネットワーク
ニューラルネットワークは例から学習し、過去のデータと現在のデータを使用して将来の価値を予測します。そのアーキテクチャにより、データに隠された複雑な関係を特定することができ、私たちの脳がパターンを検出する方法が再現されます。これらは、データを受け入れ、予測を計算し、単一の予測として出力を提供する多くのレイヤーで構成されています。デシジョン ツリー
デシジョン ツリーは、特定のオプションの潜在的なリスクを予測するために、一連の「if/then」オプションで結果を提示する分析手法です。収入。すべての分類問題を解決し、複雑な質問に答えることができます。図 3 に示すように、デシジョン ツリーは、将来の意思決定を説明するためにデータを枝状のパーティションに分割するさまざまな方法を認識するアルゴリズムによって生成されるトップダウン ツリーに似ています。意思決定パスを特定するのに役立ちます。
読み込みに 3 秒以上かかる場合は、ツリー内の 1 つのブランチがカートを放棄したユーザーである可能性があります。この下の別の分岐は、それらが女性であるかどうかを示す場合があります。分析によると、女性は衝動買いをする可能性が高く、この遅れが反芻につながる可能性があるため、「はい」の答えはリスクを高めます。
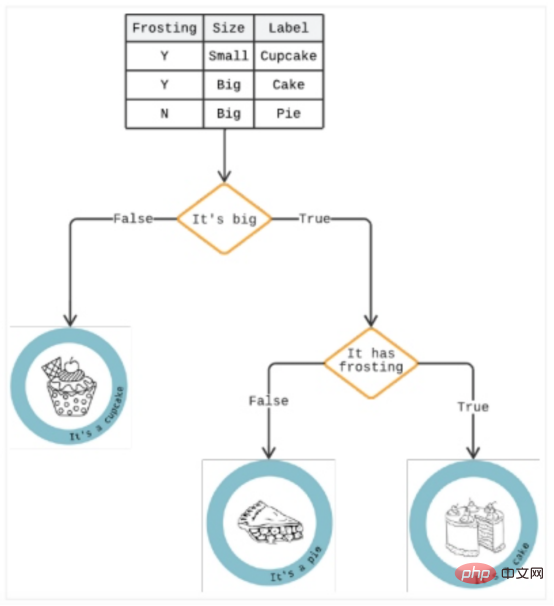 #図 3: デシジョン ツリーの例
#図 3: デシジョン ツリーの例
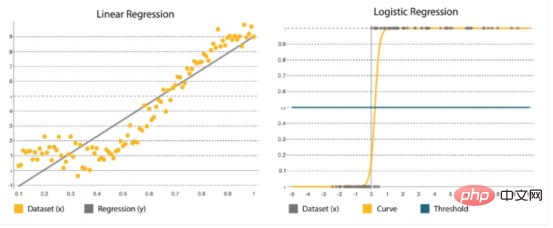
線形回帰およびロジスティック回帰
回帰最も一般的な統計手法の 1 つです。これは、ブラック フライデー セール中に各サービスに追加するリソースの数など、数字を見積もるときに重要です。多くの回帰アルゴリズムは、変数間の関係を推定し、大規模な混合データ セット内の重要なパターンと変数間の関係を見つけるように設計されています。これは、単純な線形回帰モデル (データに適合する直線関数の計算) からロジスティック回帰 (曲線の計算) まで多岐にわたります (図 4)。
全体的な比較 | #リニアリターン|
ロジスティック回帰 |
|
| ## は、今後数か月でユーザー トラフィックが急増するリスクなど、連続的な範囲の値を定義するために使用されます。 |
#これは、古いセットに基づいてパラメータを予測する統計的手法です。これはバイナリ分類、つまり y=0 または 1 のデータセットに最適に機能します。1 はデフォルトのクラス を表します。その名前は、変換関数 ( は論理関数 ) に由来しています。 |
y=a bx として表されます。ここで、x は出力 y を決定するために使用される入力セットです。係数 a と b は、x と y の関係を定量化するために使用されます。ここで、a は切片、b は直線の傾きです。 |
論理関数で表されます: where、β0 は切片、β1 はレートです。トレーニング データを使用して、予測結果と実際の結果の間の誤差を最小限に抑える係数を計算します。 |
目標は、ほとんどの点に最も近い直線を当てはめて、y と直線の間の距離または誤差を減らすことです。 |
# S 字曲線を形成し、しきい値を適用して確率を二項分類に変換します。 |
以上が機械学習は高品質のソフトウェア エンジニアリングを強化しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7675
7675
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
この AI 支援プログラミング ツールは、急速な AI 開発のこの段階において、多数の有用な AI 支援プログラミング ツールを発掘しました。 AI 支援プログラミング ツールは、開発効率を向上させ、コードの品質を向上させ、バグ率を減らすことができます。これらは、現代のソフトウェア開発プロセスにおける重要なアシスタントです。今日は Dayao が 4 つの AI 支援プログラミング ツールを紹介します (すべて C# 言語をサポートしています)。皆さんのお役に立てれば幸いです。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot は、より少ない労力でより迅速にコードを作成できるようにする AI コーディング アシスタントであり、問題解決とコラボレーションにより集中できるようになります。ギット
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
