

現在 ChatGPT の恩恵を受けることができる 3 つの主要産業


以上が現在 ChatGPT の恩恵を受けることができる 3 つの主要産業の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7524
7524
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルのアーキテクチャに注目している場合は、最新のモデルや研究論文で「SwiGLU」という用語を見たことがあるかもしれません。 SwiGLUは大規模言語モデルで最もよく使われるアクティベーション関数と言えますので、この記事で詳しく紹介します。実はSwiGLUとは、2020年にGoogleが提案したSWISHとGLUの特徴を組み合わせたアクティベーション関数です。 SwiGLU の正式な中国語名は「双方向ゲート線形ユニット」で、SWISH と GLU の 2 つの活性化関数を最適化して組み合わせ、モデルの非線形表現能力を向上させます。 SWISH は大規模な言語モデルで広く使用されている非常に一般的なアクティベーション関数ですが、GLU は自然言語処理タスクで優れたパフォーマンスを示しています。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェント カスタマー サービス チャットボットの作成 はじめに: 今日の情報化時代において、インテリジェント カスタマー サービス システムは企業と顧客の間の重要なコミュニケーション ツールとなっています。より良い顧客サービス体験を提供するために、多くの企業が顧客相談や質問応答などのタスクを完了するためにチャットボットに注目し始めています。この記事では、OpenAI の強力なモデル ChatGPT と Python 言語を使用して、インテリジェントな顧客サービス チャットボットを作成し、顧客サービスを向上させる方法を紹介します。
 FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
オープンソースの大規模言語モデルのパフォーマンスが向上し続けるにつれて、コードの作成と分析、推奨事項、テキストの要約、および質問と回答 (QA) ペアのパフォーマンスがすべて向上しました。しかし、QA に関しては、LLM はトレーニングされていないデータに関連する問題に対応していないことが多く、多くの内部文書はコンプライアンス、企業秘密、またはプライバシーを確保するために社内に保管されています。これらの文書がクエリされると、LLM は幻覚を起こし、無関係なコンテンツ、捏造されたコンテンツ、または矛盾したコンテンツを生成する可能性があります。この課題に対処するために考えられる手法の 1 つは、検索拡張生成 (RAG) です。これには、生成の品質と精度を向上させるために、トレーニング データ ソースを超えた信頼できるナレッジ ベースを参照して応答を強化するプロセスが含まれます。 RAG システムには、コーパスから関連する文書断片を取得するための検索システムが含まれています。
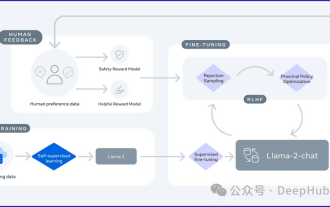 セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
2024 年は、大規模言語モデル (LLM) が急速に開発される年です。 LLM のトレーニングでは、教師あり微調整 (SFT) や人間の好みに依存する人間のフィードバックによる強化学習 (RLHF) などのアライメント手法が重要な技術手段です。これらの方法は LLM の開発において重要な役割を果たしてきましたが、位置合わせ方法には手動で注釈を付けた大量のデータが必要です。この課題に直面して、微調整は活発な研究分野となっており、研究者は人間のデータを効果的に活用できる方法の開発に積極的に取り組んでいます。したがって、位置合わせ方法の開発は、LLM 技術のさらなる進歩を促進するでしょう。カリフォルニア大学は最近、SPIN (SelfPlayfInetuNing) と呼ばれる新しいテクノロジーを導入する研究を実施しました。 S
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
幻覚は、大規模言語モデル (LLM) を扱う場合によくある問題です。 LLM は滑らかで一貫性のあるテキストを生成できますが、生成される情報は不正確または一貫性がないことがよくあります。 LLM の幻覚を防ぐために、データベースやナレッジ グラフなどの外部知識ソースを使用して事実情報を提供できます。このようにして、LLM はこれらの信頼できるデータ ソースに依存できるため、より正確で信頼性の高いテキスト コンテンツが得られます。ベクトル データベースとナレッジ グラフ ベクトル データベース ベクトル データベースは、エンティティまたは概念を表す高次元ベクトルのセットです。これらは、ベクトル表現を通じて計算された、異なるエンティティまたは概念間の類似性または相関関係を測定するために使用できます。ベクトル データベースは、ベクトル距離に基づいて、「パリ」と「フランス」の方が「パリ」よりも近いことを示します。
