

Pandas のための 10 の代替データ処理手法

この記事でまとめたテクニックは、以前に 10 Pandas でまとめた一般的なテクニックとは異なります。頻繁には使用しないかもしれませんが、非常に難しい問題に遭遇したとき、これらのテクニックは、まれな問題を迅速に解決するのに役立ちます。

1. カテゴリ タイプ
デフォルトでは、限られた数のオプションを持つ列にオブジェクト タイプが割り当てられます。しかし、これはメモリの観点からは効率的な選択ではありません。これらの列にインデックスを付け、実際の値ではなくオブジェクトへの参照のみを使用できます。 Pandas は、この問題を解決するために Categorical と呼ばれる Dtype を提供します。
たとえば、画像パスを含む大規模なデータ セットで構成されます。各行には、アンカー、ポジティブ、ネガティブの 3 つの列があります。
カテゴリカル列に Categorical を使用すると、メモリ使用量を大幅に削減できます。
# raw data +----------+------------------------+ |class |filename| +----------+------------------------+ | Bathroom | Bathroombath_1.jpg| | Bathroom | Bathroombath_100.jpg| | Bathroom | Bathroombath_1003.jpg | | Bathroom | Bathroombath_1004.jpg | | Bathroom | Bathroombath_1005.jpg | +----------+------------------------+ # target +------------------------+------------------------+----------------------------+ | anchor |positive|negative| +------------------------+------------------------+----------------------------+ | Bathroombath_1.jpg| Bathroombath_100.jpg| Dinningdin_540.jpg| | Bathroombath_100.jpg| Bathroombath_1003.jpg | Dinningdin_1593.jpg | | Bathroombath_1003.jpg | Bathroombath_1004.jpg | Bedroombed_329.jpg| | Bathroombath_1004.jpg | Bathroombath_1005.jpg | Livingroomliving_1030.jpg | | Bathroombath_1005.jpg | Bathroombath_1007.jpg | Bedroombed_1240.jpg | +------------------------+------------------------+----------------------------+
ファイル名列の値は頻繁にコピーされます。したがって、Categorical を使用すると、メモリ使用量を大幅に削減できます。
ターゲット データ セットを読み取って、メモリ内の違いを見てみましょう:
triplets.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null category # 1 positive 525000 non-null category # 2 negative 525000 non-null category # dtypes: category(3) # memory usage: 4.6 MB # without categories triplets_raw.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null object # 1 positive 525000 non-null object # 2 negative 525000 non-null object # dtypes: object(3) # memory usage: 118.1 MB
この違いは非常に大きく、繰り返し回数が増加するにつれて、その差は非線形に増加します。
2. 行-列変換
行-列変換の問題は SQL でよく発生します. Pandas もそれを必要とすることがあります. Kaggle コンテストのデータセットを見てみましょう。 census_start .csv ファイル:
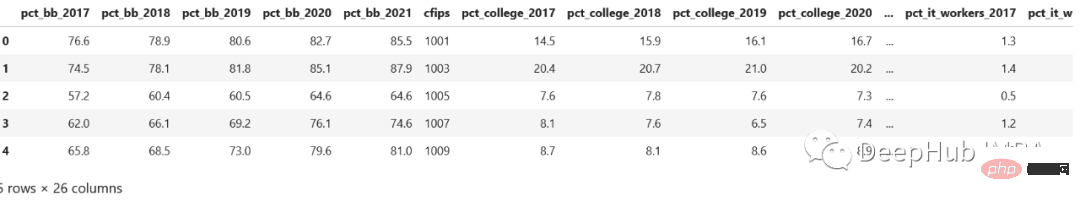
ご覧のとおり、これらは年ごとに保存されています。列 year と pct_bb があり、各行に対応する値がある場合、良くなりますよ、たくさん、そうですね。
cols = sorted([col for col in original_df.columns
if col.startswith("pct_bb")])
df = original_df[(["cfips"] + cols)]
df = df.melt(id_vars="cfips",
value_vars=cols,
var_name="year",
value_name="feature").sort_values(by=["cfips", "year"])結果を見てください。これははるかに優れています:

3. apply() は非常に遅いです
前回紹介したように、このメソッドは各行を反復処理して指定されたメソッドを呼び出すため、使用しないことをお勧めします。しかし、他に選択肢がない場合、速度を上げる方法はあるのでしょうか?
swifter や pandaralrew などのパッケージを使用してプロセスを並列化できます。
Swifter
import pandas as pd import swifter def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def swifter_way(data): data['out'] = data['in'].swifter.apply(target_function)
Pandaralllel
import pandas as pd from pandarallel import pandarallel def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def pandarallel_way(data): pandarallel.initialize() data['out'] = data['in'].parallel_apply(target_function)
マルチスレッド化することで計算速度を向上させることができます。もちろん、クラスターがある場合は dask を使用するのが最適です。または pyspark
4. Null 値、int、Int64
標準の整数データ型は Null 値をサポートしていないため、浮動小数点数に自動的に変換されます。したがって、データの整数フィールドに null 値が必要な場合は、null 値を表すために pandas.NA を使用するため、Int64 データ型の使用を検討してください。
5. CSV、圧縮、それとも寄木細工ですか?
できるだけ寄木細工を選択してください。 Parquet はデータ型を保持するため、データを読み取るときに dtype を指定する必要はありません。 Parquet ファイルはデフォルトで snappy を使用して圧縮されるため、必要なディスク容量はほとんどありません。以下にいくつかの比較を示します。
|file|size | +------------------------+---------+ | triplets_525k.csv| 38.4 MB | | triplets_525k.csv.gzip |4.3 MB | | triplets_525k.csv.zip|4.5 MB | | triplets_525k.parquet|1.9 MB | +------------------------+---------+
parquet を読むには、pyarrow や fastparquet などの追加パッケージが必要です。 chatgpt は、pyarrow が fastparquet よりも速いと言っていますが、小規模なデータセットでテストしたとき、fastparquet は pyarrow よりも高速でしたが、pandas 2.0 もデフォルトで pyarrow を使用するため、ここでは pyarrow を使用することをお勧めします。
6, value_counts ()
絶対値の取得、カウント、合計での除算など、相対頻度の計算は複雑ですが、value_counts を使用すると、このタスクをより簡単に実行できます。このメソッドには、NULL 値を含めるか除外するオプションが用意されています。
df = pd.DataFrame({"a": [1, 2, None], "b": [4., 5.1, 14.02]})
df["a"] = df["a"].astype("Int64")
print(df.info())
print(df["a"].value_counts(normalize=True, dropna=False),
df["a"].value_counts(normalize=True, dropna=True), sep="nn")
これはもっと簡単ではありませんか?
7. Modin
注: Modin はまだ存在します。テスト段階。
Pandas はシングルスレッドですが、Modin はパンダをスケーリングすることでワークフローを高速化できます。パンダが非常に遅くなったり、過剰なメモリ使用量によって OOM が発生したりする大規模なデータ セットで特にうまく機能します。
!pip install modin[all]
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")以下は modin の公式 Web サイトのアーキテクチャ図です。興味がある場合は、

8 を抜粋してください。 ()
複雑な半構造化データが頻繁に発生し、そのデータから個々の列を分離する必要がある場合は、次の方法を使用できます:
import pandas as pd
regex = (r'(?P<title>[A-Za-z's]+),'
r'(?P<author>[A-Za-zs']+),'
r'(?P<isbn>[d-]+),'
r'(?P<year>d{4}),'
r'(?P<publisher>.+)')
addr = pd.Series([
"The Lost City of Amara,Olivia Garcia,978-1-234567-89-0,2023,HarperCollins",
"The Alchemist's Daughter,Maxwell Greene,978-0-987654-32-1,2022,Penguin Random House",
"The Last Voyage of the HMS Endeavour,Jessica Kim,978-5-432109-87-6,2021,Simon & Schuster",
"The Ghosts of Summer House,Isabella Lee,978-3-456789-12-3,2000,Macmillan Publishers",
"The Secret of the Blackthorn Manor,Emma Chen,978-9-876543-21-0,2023,Random House Children's Books"
])
addr.str.extract(regex)
9、读写剪贴板
这个技巧有人一次也用不到,但是有人可能就是需要,比如:在分析中包含PDF文件中的表格时。通常的方法是复制数据,粘贴到Excel中,导出到csv文件中,然后导入Pandas。但是,这里有一个更简单的解决方案:pd.read_clipboard()。我们所需要做的就是复制所需的数据并执行一个方法。
有读就可以写,所以还可以使用to_clipboard()方法导出到剪贴板。
但是要记住,这里的剪贴板是你运行python/jupyter主机的剪切板,并不可能跨主机粘贴,一定不要搞混了。
10、数组列分成多列
假设我们有这样一个数据集,这是一个相当典型的情况:
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3],
"b": [4, 5, 6],
"category": [["foo", "bar"], ["foo"], ["qux"]]})
# let's increase the number of rows in a dataframe
df = pd.concat([df]*10000, ignore_index=True)
我们想将category分成多列显示,例如下面的

先看看最慢的apply:
def dummies_series_apply(df):
return df.join(df['category'].apply(pd.Series)
.stack()
.str.get_dummies()
.groupby(level=0)
.sum())
.drop("category", axis=1)
%timeit dummies_series_apply(df.copy())
#5.96 s ± 66.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)sklearn的MultiLabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
def sklearn_mlb(df):
mlb = MultiLabelBinarizer()
return df.join(pd.DataFrame(mlb.fit_transform(df['category']), columns=mlb.classes_))
.drop("category", axis=1)
%timeit sklearn_mlb(df.copy())
#35.1 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)是不是快了很多,我们还可以使用一般的向量化操作对其求和:
def dummies_vectorized(df):
return pd.get_dummies(df.explode("category"), prefix="cat")
.groupby(["a", "b"])
.sum()
.reset_index()
%timeit dummies_vectorized(df.copy())
#29.3 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
总结
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!
以上がPandas のための 10 の代替データ処理手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 Win11 ヒントの共有: ワン トリックで Microsoft アカウントのログインをスキップする
Mar 27, 2024 pm 02:57 PM
Win11 ヒントの共有: ワン トリックで Microsoft アカウントのログインをスキップする
Mar 27, 2024 pm 02:57 PM
Win11 のヒントの共有: Microsoft アカウントのログインをスキップする 1 つのトリック Windows 11 は、新しいデザイン スタイルと多くの実用的な機能を備えた、Microsoft によって発売された最新のオペレーティング システムです。ただし、一部のユーザーにとっては、システムを起動するたびに Microsoft アカウントにログインしなければならないのが少し煩わしい場合があります。あなたがそのような人であれば、次のヒントを試してみるとよいでしょう。これにより、Microsoft アカウントでのログインをスキップして、デスクトップ インターフェイスに直接入ることができるようになります。まず、Microsoft アカウントの代わりにログインするためのローカル アカウントをシステムに作成する必要があります。これを行う利点は、
 ベテラン必携:C言語の*と&のヒントと注意点
Apr 04, 2024 am 08:21 AM
ベテラン必携:C言語の*と&のヒントと注意点
Apr 04, 2024 am 08:21 AM
C 言語では、他の変数のアドレスを格納するポインタを表し、& は変数のメモリ アドレスを返すアドレス演算子を表します。ポインタの使用に関するヒントには、ポインタの定義、ポインタの逆参照、ポインタが有効なアドレスを指していることの確認が含まれます。アドレス演算子の使用に関するヒントには、変数アドレスの取得、配列要素のアドレスを取得するときに配列の最初の要素のアドレスを返すことなどが含まれます。 。ポインター演算子とアドレス演算子を使用して文字列を反転する実際の例。
 初心者がフォームを作成するためのヒントは何ですか?
Mar 21, 2024 am 09:11 AM
初心者がフォームを作成するためのヒントは何ですか?
Mar 21, 2024 am 09:11 AM
私たちは Excel で表を作成したり編集したりすることがよくありますが、ソフトウェアに触れたばかりの初心者にとって、Excel を使用して表を作成する方法は私たちほど簡単ではありません。以下では、初心者、つまり初心者がマスターする必要があるテーブル作成のいくつかの手順について演習を行います。初心者向けのサンプルフォームを以下に示します。入力方法を見てみましょう。 1. Excel ドキュメントを新規作成するには 2 つの方法があります。 [デスクトップ]-[新規作成]-[xls]ファイル上の何もない場所でマウスを右クリックします。 [スタート]-[すべてのプログラム]-[Microsoft Office]-[Microsoft Excel 20**] を実行することもできます。 2. 新しい ex ファイルをダブルクリックします。
 VSCode 入門ガイド: 初心者が使い方のスキルをすぐにマスターするための必読の書です。
Mar 26, 2024 am 08:21 AM
VSCode 入門ガイド: 初心者が使い方のスキルをすぐにマスターするための必読の書です。
Mar 26, 2024 am 08:21 AM
VSCode (Visual Studio Code) は、Microsoft によって開発されたオープン ソース コード エディターであり、強力な機能と豊富なプラグイン サポートを備えており、開発者にとって推奨されるツールの 1 つです。この記事では、初心者が VSCode の使用スキルをすぐに習得できるようにするための入門ガイドを提供します。この記事では、VSCode のインストール方法、基本的な編集操作、ショートカット キー、プラグインのインストールなどを紹介し、具体的なコード例を読者に提供します。 1. まず VSCode をインストールします。
 Golang はどのようにデータ処理効率を向上させますか?
May 08, 2024 pm 06:03 PM
Golang はどのようにデータ処理効率を向上させますか?
May 08, 2024 pm 06:03 PM
Golang は、同時実行性、効率的なメモリ管理、ネイティブ データ構造、豊富なサードパーティ ライブラリを通じてデータ処理効率を向上させます。具体的な利点は次のとおりです。 並列処理: コルーチンは複数のタスクの同時実行をサポートします。効率的なメモリ管理: ガベージ コレクション メカニズムによりメモリが自動的に管理されます。効率的なデータ構造: スライス、マップ、チャネルなどのデータ構造は、データに迅速にアクセスして処理します。サードパーティ ライブラリ: fasthttp や x/text などのさまざまなデータ処理ライブラリをカバーします。
 PHP プログラミング スキル: 3 秒以内に Web ページにジャンプする方法
Mar 24, 2024 am 09:18 AM
PHP プログラミング スキル: 3 秒以内に Web ページにジャンプする方法
Mar 24, 2024 am 09:18 AM
タイトル: PHP プログラミングのヒント: 3 秒以内に Web ページにジャンプする方法 Web 開発では、一定時間内に別のページに自動的にジャンプする必要がある状況によく遭遇します。この記事では、PHP を使用して 3 秒以内にページにジャンプするプログラミング手法を実装する方法と、具体的なコード例を紹介します。まず、ページ ジャンプの基本原理は、HTTP 応答ヘッダーの Location フィールドを通じて実現されます。このフィールドを設定すると、ブラウザは指定されたページに自動的にジャンプできます。以下は、P の使用方法を示す簡単な例です。
 Laravel と CodeIgniter のデータ処理機能はどのように比較されますか?
Jun 01, 2024 pm 01:34 PM
Laravel と CodeIgniter のデータ処理機能はどのように比較されますか?
Jun 01, 2024 pm 01:34 PM
Laravel と CodeIgniter のデータ処理機能を比較します。 ORM: Laravel はクラスとオブジェクトのリレーショナル マッピングを提供する EloquentORM を使用しますが、CodeIgniter は ActiveRecord を使用してデータベース モデルを PHP クラスのサブクラスとして表します。クエリビルダー: Laravel には柔軟なチェーンクエリ API がありますが、CodeIgniter のクエリビルダーはよりシンプルで配列ベースです。データ検証: Laravel はカスタム検証ルールをサポートする Validator クラスを提供しますが、CodeIgniter には組み込みの検証関数が少なく、カスタム ルールの手動コーディングが必要です。実践例:ユーザー登録例はLarを示しています
 Win11 の裏技が明らかに: Microsoft アカウントのログインをバイパスする方法
Mar 27, 2024 pm 07:57 PM
Win11 の裏技が明らかに: Microsoft アカウントのログインをバイパスする方法
Mar 27, 2024 pm 07:57 PM
Win11 のトリックが明らかに: Microsoft アカウントのログインをバイパスする方法 最近、Microsoft は新しいオペレーティング システム Windows11 を発表し、広く注目を集めています。以前のバージョンと比較して、Windows 11 はインターフェイスのデザインや機能の改善の点で多くの新しい調整を加えましたが、いくつかの議論も引き起こしました. 最も目を引く点は、ユーザーが Microsoft アカウントでシステムにログインすることを強制することです。ユーザーによっては、ローカル アカウントでログインすることに慣れており、個人情報を Microsoft アカウントにバインドすることに抵抗がある場合があります。
