

B局における音声認識技術の導入実践

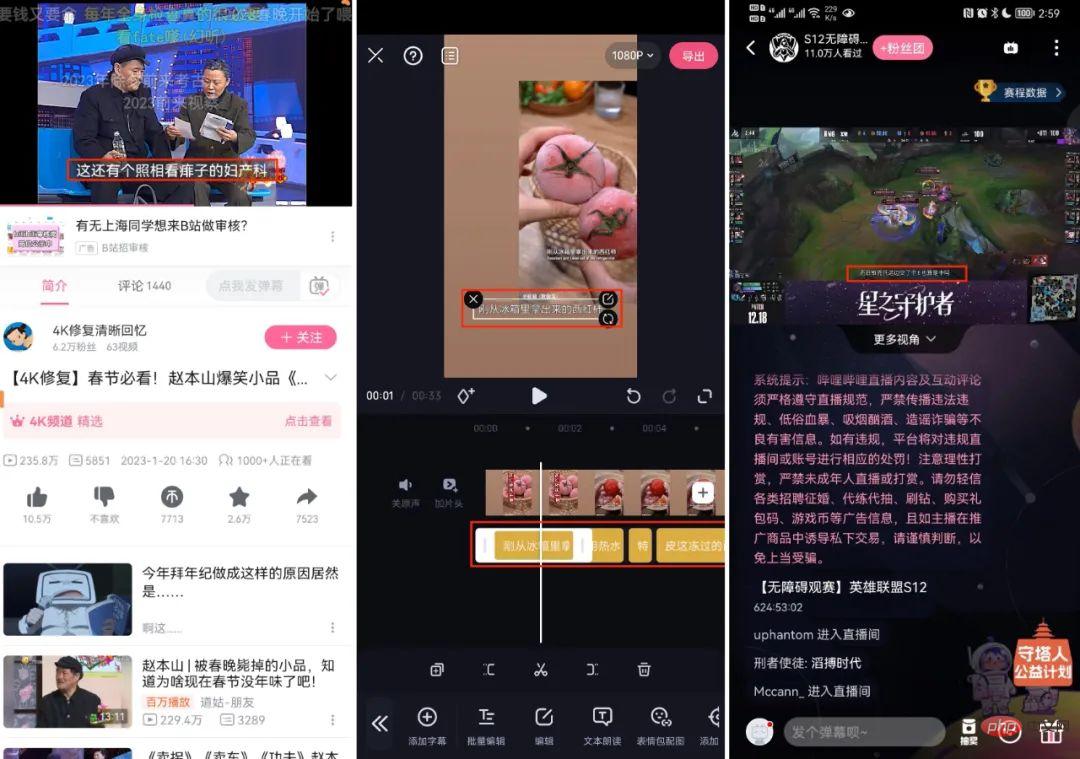
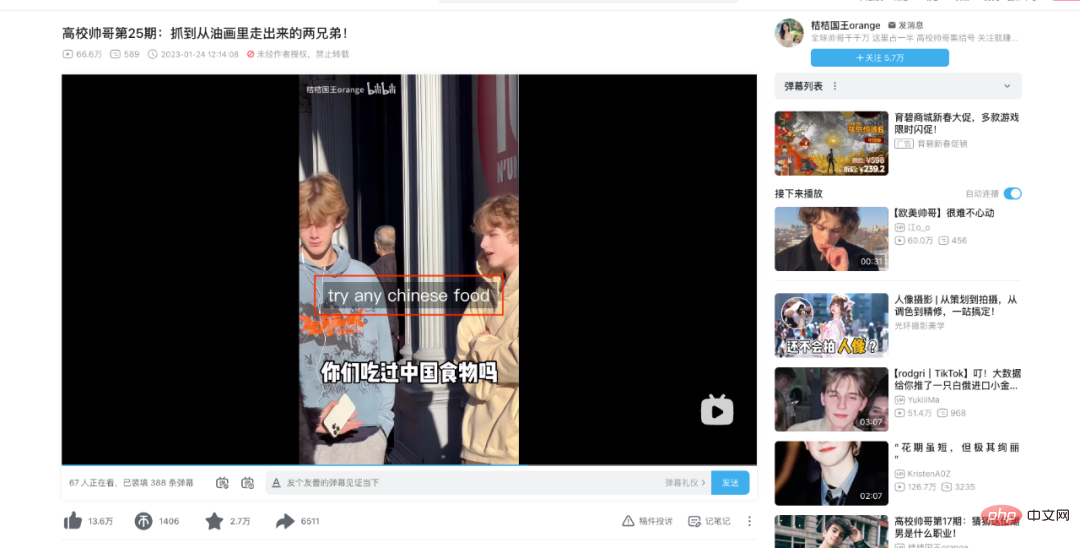
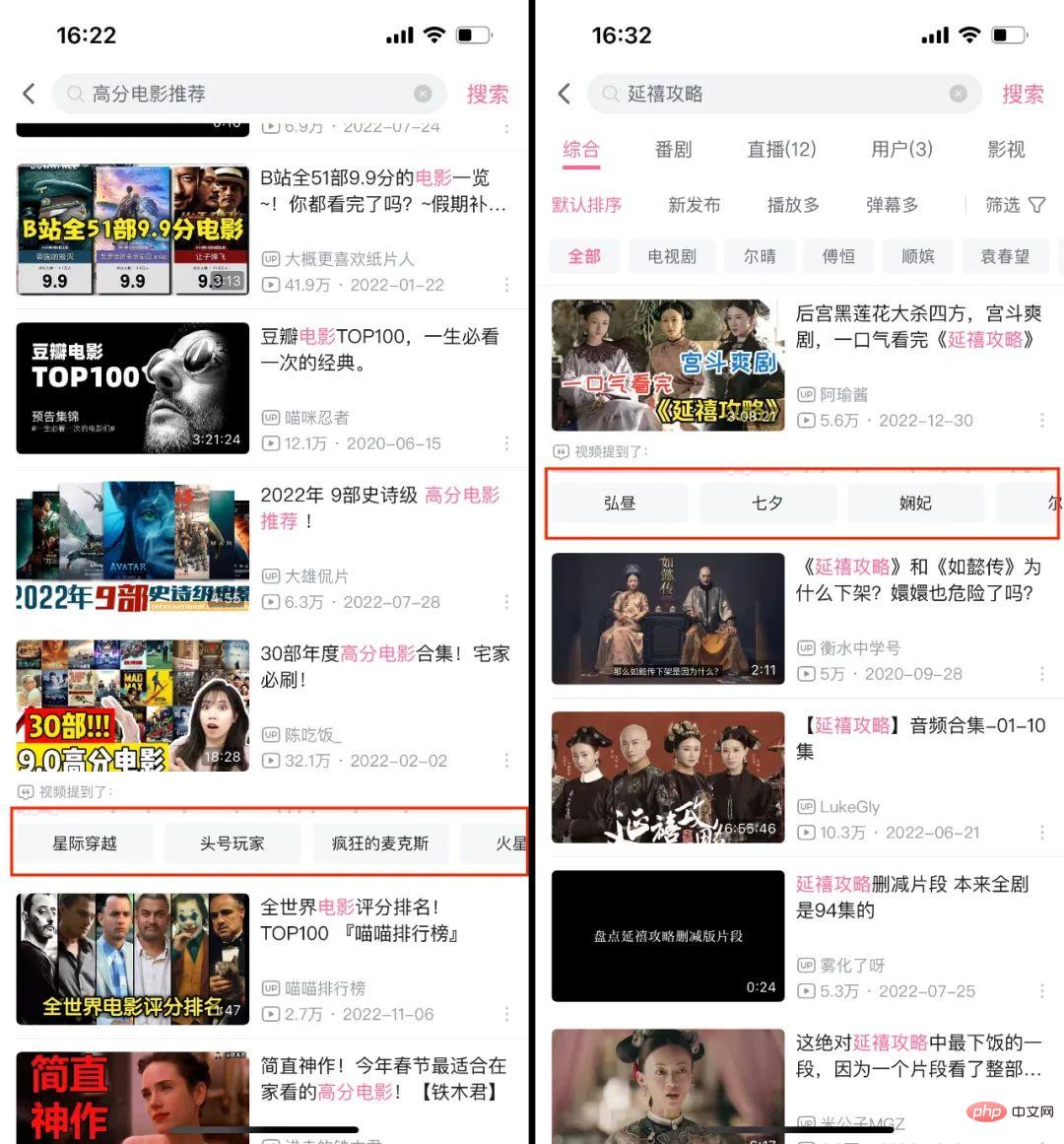
自動音声認識 (ASR) テクノロジーは、オーディオおよびビデオ コンテンツのセキュリティ レビュー、AI 字幕 (C サイド、マストカット、S12 ライブ ブロードキャストなど) など、Bilibili の関連ビジネス シナリオに大規模に実装されています。 )、動画理解(全文検索)など。
さらに、Bilibili の ASR エンジンは、2022 年 11 月に行われた産業用ベンチマーク SpeechIO (https://github.com/SpeechColab/Leaderboard) の最新の本格的な評価でも 1 位を獲得しました (https: //) github.com/SpeechColab/Leaderboard#5-ranking)、非公開のテスト セットでは利点がより明らかです。
| 全テスト セットのランキング | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| #ランキング | メーカー | ワードエラー率 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | ##ビリビリ##2.82% | #2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Alibaba Cloud |
2.85% |
3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| #Yitu | #3.16%##4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3.28% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | #テンセント##3.85% | 6 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| iFlytek | 4.05% | 7 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 思比奇奇数 | 5.19% | ##8 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8.14% |
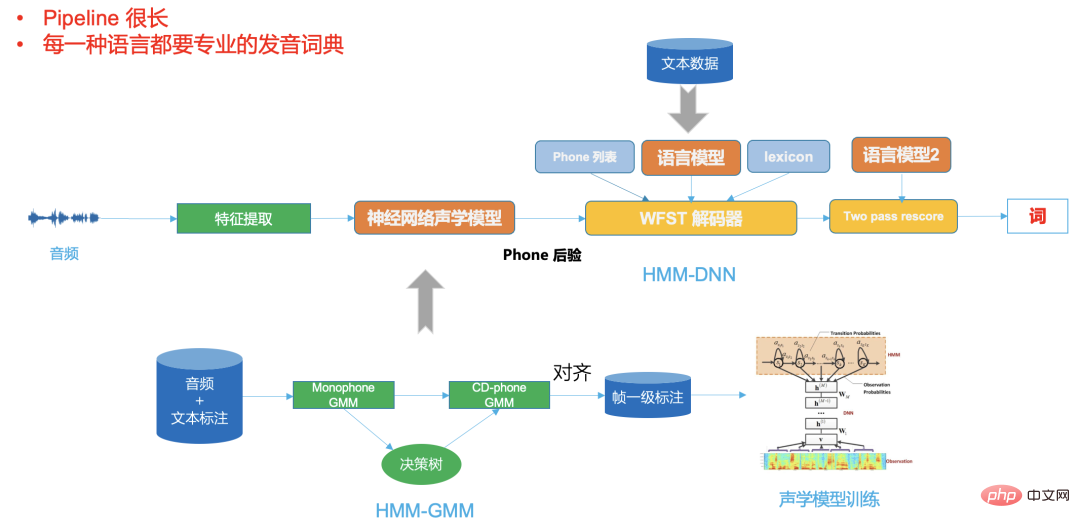
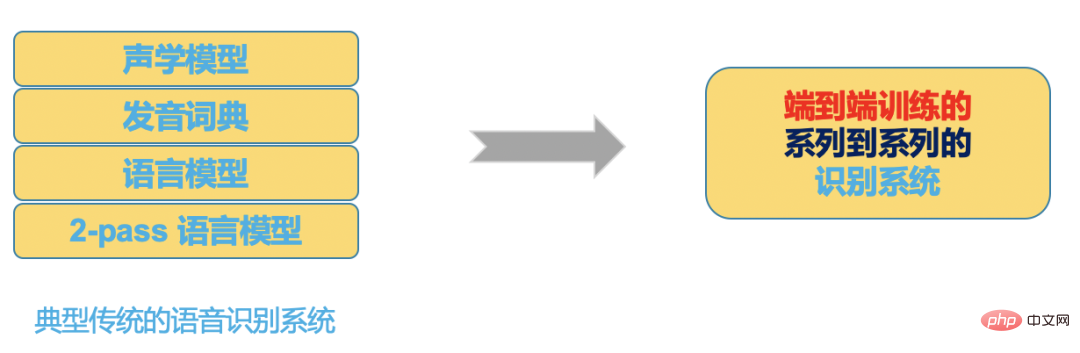
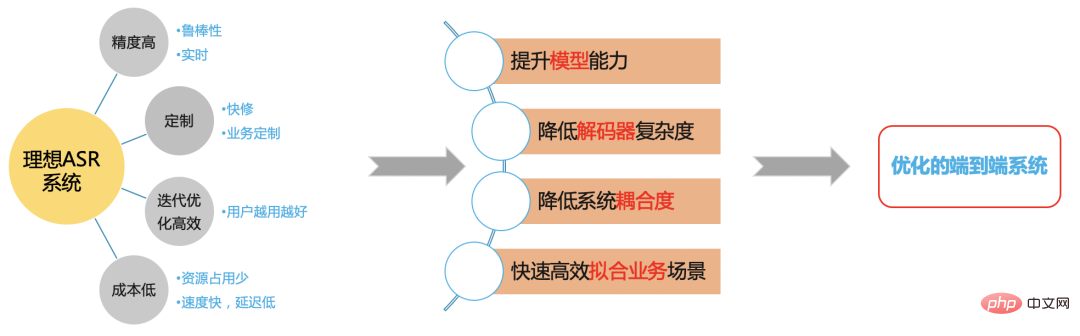
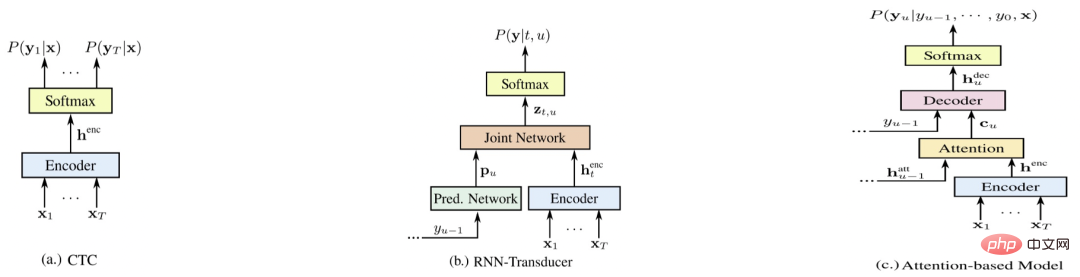
#高品質 ASR エンジン ##高品質 (コスト効率の高い) エンジン工業生産に適した ASR エンジン。次の特性を持つ必要があります:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
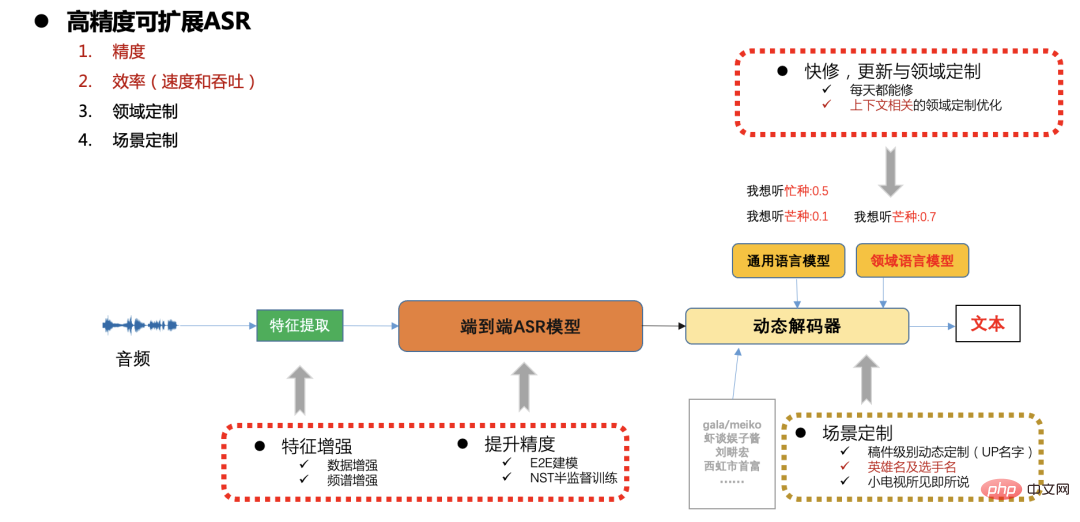
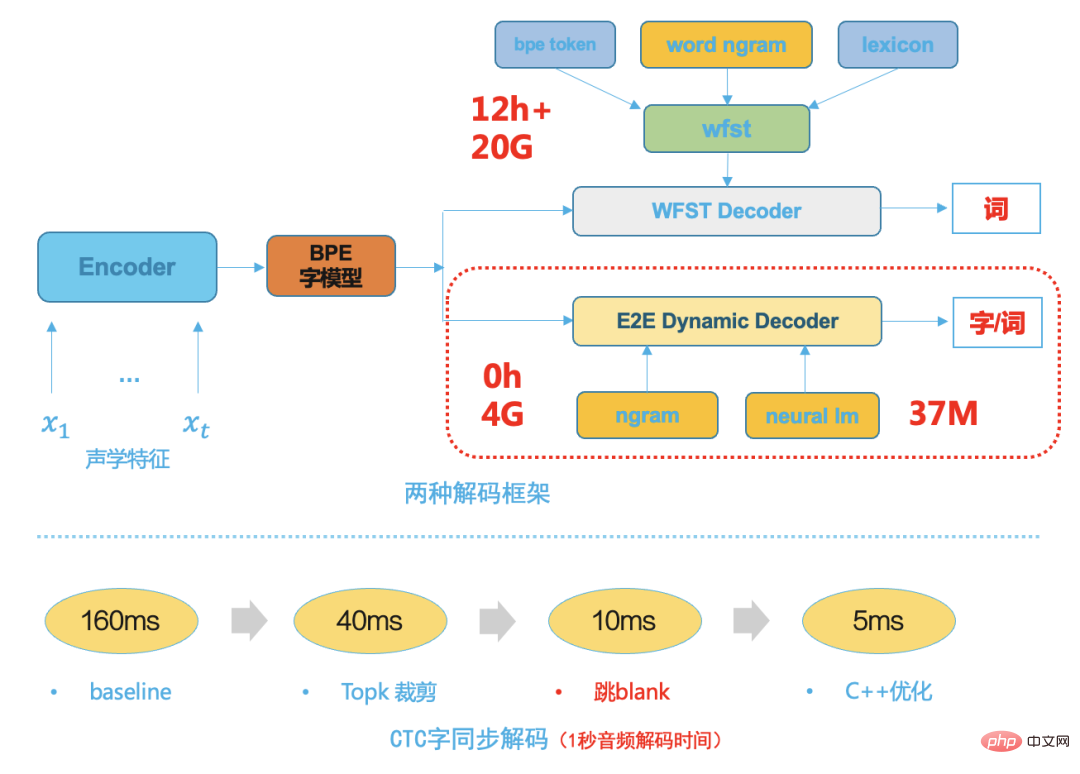
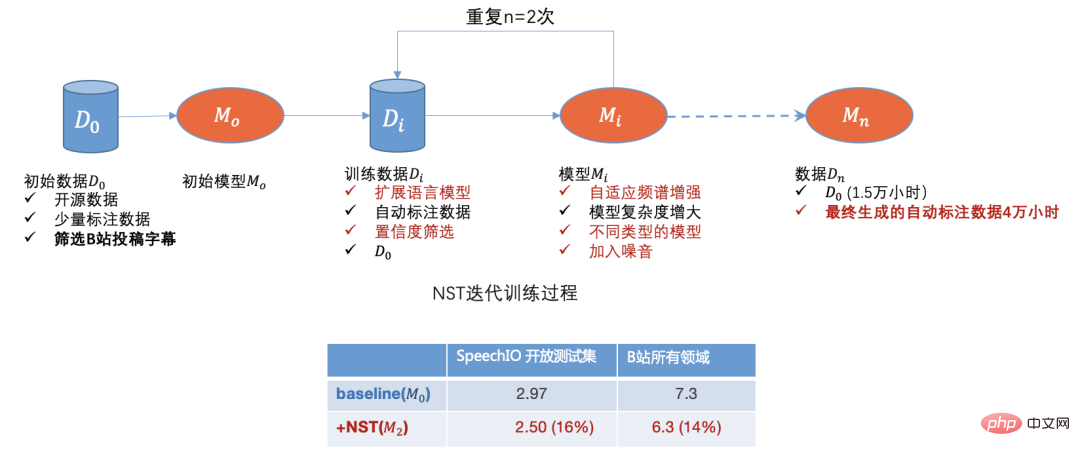 オープンソース データ、B ステーション送信データ、手動注釈データ、自動注釈データを通じて、データのコールド スタート問題を最初に解決しました。モデルを使用 反復することで、識別が不十分なドメイン データをさらに除外できます。
オープンソース データ、B ステーション送信データ、手動注釈データ、自動注釈データを通じて、データのコールド スタート問題を最初に解決しました。モデルを使用 反復することで、識別が不十分なドメイン データをさらに除外できます。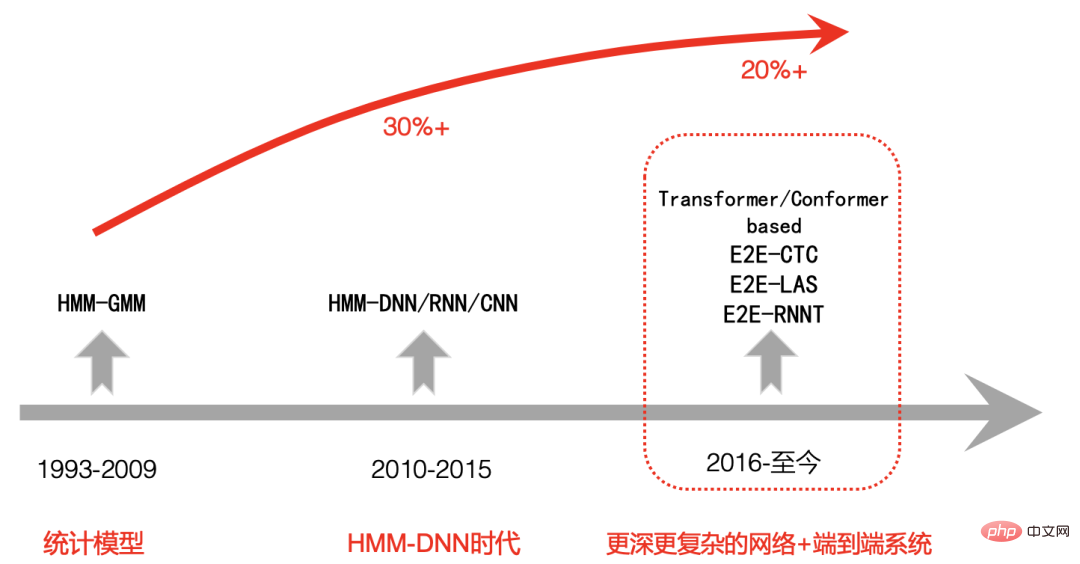
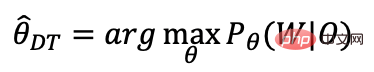

以上がB局における音声認識技術の導入実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 動画切り出しで音声を自動認識して字幕を生成する方法 字幕を自動生成する方法の紹介
Mar 14, 2024 pm 08:10 PM
動画切り出しで音声を自動認識して字幕を生成する方法 字幕を自動生成する方法の紹介
Mar 14, 2024 pm 08:10 PM
このプラットフォームに音声字幕を生成する機能を実装するにはどうすればよいですか? ビデオを作成するとき、質感を高めるため、またはストーリーをナレーションするときに、誰もが情報をよりよく理解できるように字幕を追加する必要があります。上のビデオの一部。表現にも役割を果たしますが、多くのユーザーは自動音声認識と字幕生成にあまり慣れていません。どこにいても、さまざまな面でより良い選択を簡単に行うことができます。機能的なスキルなどをゆっくり理解する必要があります。急いでエディターで確認してください。お見逃しなく。
 WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法 はじめに: 技術の継続的な発展により、音声認識技術は人工知能の分野の重要な部分になりました。 WebSocket と JavaScript をベースとしたオンライン音声認識システムは、低遅延、リアルタイム、クロスプラットフォームという特徴があり、広く使用されるソリューションとなっています。この記事では、WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法を紹介します。
 WIN10システムで音声認識をオフにする詳細な方法
Mar 27, 2024 pm 02:36 PM
WIN10システムで音声認識をオフにする詳細な方法
Mar 27, 2024 pm 02:36 PM
1. コントロール パネルに入り、[音声認識] オプションを見つけてオンにします。 2. 音声認識ページが表示されたら、[音声詳細オプション]を選択します。 3. 最後に、音声のプロパティ画面のユーザー設定欄にある「起動時に音声認識を実行する」のチェックを外します。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
皆さん、こんにちは。私は Kite です。2 年前には、オーディオ ファイルとビデオ ファイルをテキスト コンテンツに変換する必要性を実現するのは困難でしたが、今ではわずか数分で簡単に解決できるようになりました。一部の企業では、トレーニングデータを取得するために、DouyinやKuaishouなどのショートビデオプラットフォーム上のビデオをフルクロールし、ビデオから音声を抽出してテキスト形式に変換し、ビッグデータのトレーニングコーパスとして使用していると言われていますモデル。ビデオまたはオーディオ ファイルをテキストに変換する必要がある場合は、現在利用可能なこのオープン ソース ソリューションを試すことができます。たとえば、映画やテレビ番組のセリフが登場する特定の時点を検索できます。早速、本題に入りましょう。 Whisper は OpenAI のオープンソース Whisper で、もちろん Python で書かれており、必要なのはいくつかの簡単なインストール パッケージだけです。
