

機械学習におけるアンサンブル手法の概要

オンライン ショッピングをしていて、同じ製品を同じ評価で販売している 2 つの店舗を見つけたと想像してください。ただし、最初の評価は 1 人だけで、2 番目の評価は 100 人でした。どちらの評価をより信頼しますか?最終的にどの製品を購入しますか?ほとんどの人にとっての答えは簡単です。確かに1人の意見より100人の意見の方が信頼できる。これは「群衆の知恵」と呼ばれ、アンサンブル アプローチが機能する理由です。

アンサンブル手法
通常、学習データから学習者 (学習者 = トレーニング モデル) のみを作成します (つまり、学習データから学習者のみを作成します)。機械学習モデルをトレーニングするためのトレーニング データ)。アンサンブル法は、複数の学習者に同じ問題を解かせてから、それらを組み合わせる方法です。これらの学習者は基本学習者と呼ばれ、ニューラル ネットワーク、サポート ベクター マシン、デシジョン ツリーなどの基礎となるアルゴリズムを含めることができます。これらすべての基本学習器が同じアルゴリズムで構成されている場合、それらは同種基本学習器と呼ばれますが、異なるアルゴリズムで構成されている場合、それらは異種基本学習器と呼ばれます。単一の基本学習器と比較して、アンサンブルは汎化機能が優れているため、より良い結果が得られます。
アンサンブル法が弱学習器で構成される場合。したがって、基本学習者は弱い学習者と呼ばれることもあります。一方、アンサンブル モデルまたは強い学習器 (これらの弱い学習器の組み合わせ) は、バイアス/分散が低く、より優れたパフォーマンスを実現します。弱い学習者を強力な学習者に変換するこの統合されたアプローチの機能は、実際には弱い学習者がより容易に利用できるため、人気が高まっています。
近年、統合手法はさまざまなオンラインコンテストで優勝を続けています。オンライン競技に加えて、アンサンブル手法は、オブジェクトの検出、認識、追跡などのコンピューター ビジョン テクノロジなどの現実のアプリケーションにも適用されます。
アンサンブル手法の主な種類
弱学習器はどのように生成されるのでしょうか?
基本学習器の生成方法に応じて、積分法は逐次積分法と並列積分法の 2 つに大きく分けられます。名前が示すように、Sequential アンサンブル手法では、基本学習器が順番に生成され、AdaBoost などのブースティング アルゴリズムなどの予測を行うために結合されます。並列アンサンブル法では、基本的な学習器を並列に生成し、ランダム フォレストやスタッキングなどのバギング アルゴリズムなどの予測のために組み合わせます。次の図は、並列アプローチと逐次アプローチを説明する単純なアーキテクチャを示しています。
基本学習器のさまざまな生成方法に応じて、積分方法は 2 つのカテゴリに分類できます。逐次積分方法と並列積分方法です。名前が示すように、逐次アンサンブル法では、AdaBoost などのブースティング アルゴリズムのように、基本学習器を順番に生成し、組み合わせて予測を行います。並列アンサンブル手法では、基本学習器が並列に生成され、ランダム フォレストやスタッキングなどのバギング アルゴリズムなどの予測のために組み合わせられます。以下の図は、並列アプローチと逐次アプローチの両方を説明する単純なアーキテクチャを示しています。
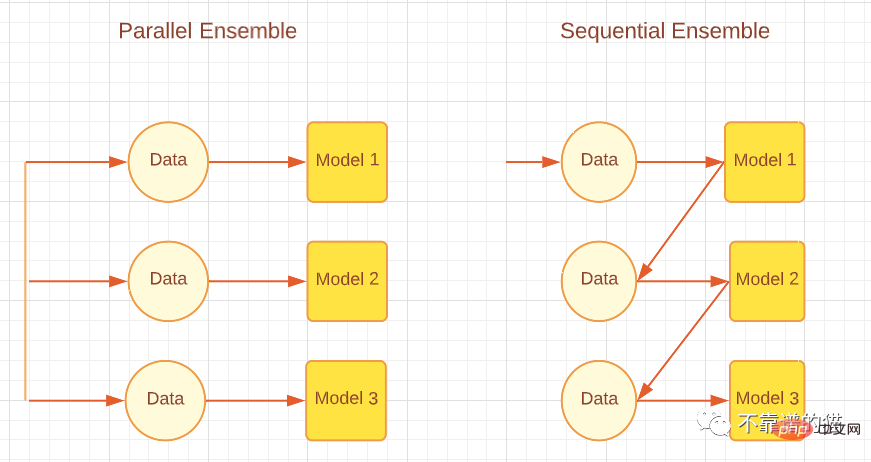
並列および逐次統合法
逐次学習法は、弱学習器間の依存関係を使用して、残差を減少させる方法で全体的なパフォーマンスを向上させます。学習者は以前の学習者の間違いにより注意を払います。大まかに言えば (回帰問題の場合)、ブースティング法によって得られるアンサンブル モデルの誤差の減少は、主に弱学習器の高いバイアスを減らすことによって達成されますが、分散の減少が観察される場合もあります。一方、並列アンサンブル法は、独立した弱学習器を組み合わせることで誤差を低減する、つまり弱学習器間の独立性を利用します。この誤差の減少は、機械学習モデルの分散の減少によるものです。したがって、ブースティングは主に機械学習モデルの偏りを減らすことによってエラーを減らし、バギングは機械学習モデルの分散を減らすことによってエラーを減らすことができると要約できます。どのアンサンブル手法が選択されるかは、弱学習器の分散が高いかバイアスが高いかによって決まるため、これは重要です。
弱い学習者を組み合わせるにはどうすればよいでしょうか?
これらのいわゆる基本学習器を生成した後、これらの学習器の中から最良のものを選択するのではなく、より一般化するためにそれらを組み合わせます。アンサンブルでこれを行う方法は、この方法で重要な役割を果たします。
平均化: 出力が数値の場合、基本学習器を結合する最も一般的な方法は平均化です。平均には、単純平均または加重平均を使用できます。回帰問題の場合、単純平均は、すべての基本モデルの誤差の合計を学習者の総数で割ったものになります。加重平均結合出力は、各基本学習器に異なる重みを与えることによって達成されます。回帰問題の場合、各基本学習器の誤差に指定された重みを乗算し、それを合計します。
投票: 名目上の出力の場合、投票は基本学習者を組み合わせる最も一般的な方法です。投票には、多数決、多数決、加重投票、ソフト投票など、さまざまな種類があります。分類問題の場合、超多数決により各学習者に 1 票が与えられ、クラス ラベルに投票します。どのクラス ラベルが投票の 50% 以上を獲得したかが、アンサンブルの予測結果となります。ただし、投票の 50% を超えるクラス ラベルが得られない場合は、拒否オプションが与えられます。これは、結合されたアンサンブルが予測できないことを意味します。相対多数決では、最も多くの票を獲得したクラス ラベルが予測結果となり、クラス ラベルには 50% 以上の票は必要ありません。つまり、3 つの出力ラベルがあり、3 つすべてが 50% 未満の結果 (40% 30% 30% など) を取得した場合、クラス ラベルの 40% がアンサンブル モデルの予測結果になります。 。加重投票は、加重平均と同様、重要性と特定の学習者の強さに基づいて分類器に重みを割り当てます。ソフト投票は、ラベル (バイナリまたはその他) ではなく、確率 (0 と 1 の間の値) を持つクラス出力に使用されます。ソフト投票はさらに、単純ソフト投票(確率の単純平均)と加重ソフト投票(学習者に重みを割り当て、確率にこれらの重みを乗算して加算する)に分類されます。
学習: もう 1 つの組み合わせ方法は学習による組み合わせであり、スタッキング アンサンブル方法で使用されます。このアプローチでは、メタ学習器と呼ばれる別個の学習器が新しいデータセットでトレーニングされ、元の機械学習データセットから生成された他の基本/弱学習器を組み合わせます。
ブースティング、バギング、スタッキングのいずれであっても、3 つのアンサンブル手法はすべて、同種または異種の弱学習器を使用して生成できることに注意してください。最も一般的なアプローチは、バギングとブースティングには同種の弱学習器を使用し、スタッキングには異種の弱学習器を使用することです。以下の図は、3 つの主要なアンサンブル手法を適切に分類したものです。
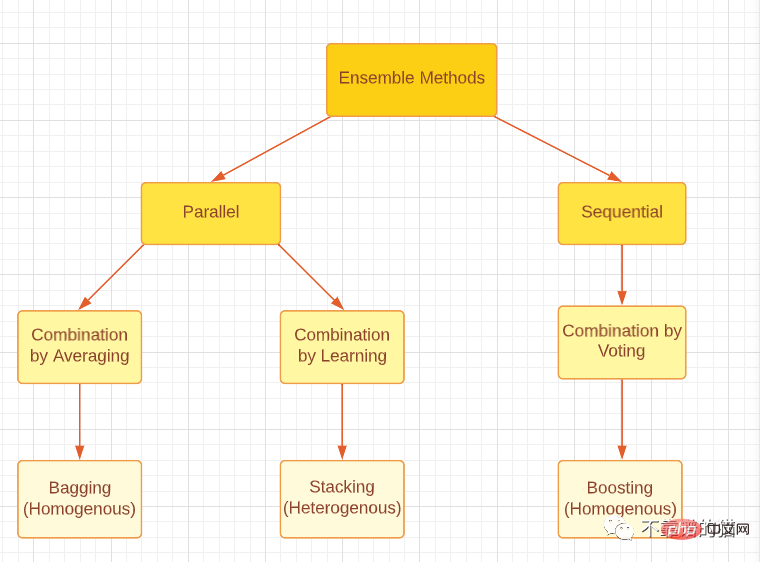
アンサンブル手法の主なタイプを分類する
アンサンブルの多様性
アンサンブルの多様性とは、基礎となる学習者の違いを指します。その大きさはどれくらいですかこれは、優れたアンサンブル モデルを生成する上で重要な意味を持ちます。さまざまな組み合わせ方法を通じて、完全に独立した (多様な) 基本学習者はエラーを最小限に抑えることができますが、完全に (高度に) 関連した学習者は何の改善ももたらさないことが理論的に証明されています。同じデータセットを使用して同じ問題を解決するようにすべての弱い学習者をトレーニングしているため、これは現実世界では困難な問題であり、高い相関関係が得られます。これに加えて、アンサンブルのパフォーマンスの低下を引き起こす可能性があるため、弱い学習器が本当に悪いモデルではないことを確認する必要があります。一方、強力で正確な基本学習器を組み合わせても、一部の弱い学習器といくつかの強力な学習器を組み合わせる場合ほど効果的ではない可能性があります。したがって、基本学習器の精度と基本学習器間の差異との間でバランスを取る必要があります。
統合の多様性を実現するにはどうすればよいでしょうか?
1. データ処理
データセットを基礎学習者向けのサブセットに分割できます。機械学習データセットが大きい場合は、データセットを単純に等しい部分に分割し、それらを機械学習モデルにフィードすることができます。データ セットが小さい場合は、置換を伴うランダム サンプリングを使用して、元のデータ セットから新しいデータ セットを生成できます。バギング法ではブートストラップ技術を使用して新しいデータセットを生成します。これは基本的に置換を伴うランダムサンプリングです。ブートストラップを使用すると、生成されたすべてのデータセットが何らかの異なる値を持つ必要があるため、ある程度のランダム性を作り出すことができます。ただし、ほとんどの値 (理論によれば約 67%) は依然として繰り返されるため、データセットは完全に独立しているわけではないことに注意してください。
2. 入力特徴
すべてのデータセットには、データに関する情報を提供する特徴が含まれています。 1 つのモデル内のすべての特徴を使用する代わりに、特徴のサブセットを作成し、異なるデータセットを生成してモデルにフィードすることができます。この手法はランダムフォレスト手法で採用されており、データ内に冗長な特徴が多数存在する場合に有効です。データセット内のフィーチャがほとんどない場合、有効性は低下します。
3. 学習パラメータ
この技術は、基本的な学習アルゴリズムにさまざまなパラメータ設定を適用することで、基本的な学習器にランダム性を生成します (ハイパーパラメータ チューニング)。たとえば、正則化項を変更することで、個々のニューラル ネットワークに異なる初期重みを割り当てることができます。
統合プルーニング
最後に、統合プルーニング テクノロジは、場合によっては統合パフォーマンスの向上に役立ちます。アンサンブル枝刈りは、すべての弱い学習器を結合するのではなく、学習器のサブセットのみを結合することを意味します。これに加えて、統合を小規模にすることでストレージとコンピューティング リソースを節約できるため、効率が向上します。
最後に
この記事は、機械学習アンサンブル手法の概要にすぎません。皆さんがより深い研究を行うことができ、さらに重要なことに、その研究を実生活に応用できるようになることを願っています。
以上が機械学習におけるアンサンブル手法の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7519
7519
 15
1378
52
81
11
21
68
15
1378
52
81
11
21
68

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 AI スタートアップ企業は一斉に OpenAI に転職し、イリヤが去った後にセキュリティ チームが再編成されました。
Jun 08, 2024 pm 01:00 PM
AI スタートアップ企業は一斉に OpenAI に転職し、イリヤが去った後にセキュリティ チームが再編成されました。
Jun 08, 2024 pm 01:00 PM
先週、社内の辞任と社外からの批判が相次ぐ中、OpenAIは内外のトラブルに見舞われた。 - 未亡人姉妹への侵害が世界中で白熱した議論を巻き起こした - 「覇権条項」に署名した従業員が次々と暴露 - ネットユーザーがウルトラマンの「」をリストアップ噂の払拭: Vox が入手した漏洩情報と文書によると、アルトマンを含む OpenAI の上級幹部はこれらの株式回収条項をよく認識しており、承認しました。さらに、OpenAI には、AI セキュリティという深刻かつ緊急の課題が直面しています。最近、最も著名な従業員2名を含むセキュリティ関連従業員5名が退職し、「Super Alignment」チームが解散したことで、OpenAIのセキュリティ問題が再び注目を集めている。フォーチュン誌は OpenA を報じた。
