

Kuaishou の両面市場における複雑な実験計画の問題


1. 問題の背景
1. 二国間市場実験の概要
両面市場、つまりプラットフォームには、生産者と消費者の 2 つの参加者が含まれており、双方がお互いを促進します。たとえば、Kuaishou にはビデオ制作者とビデオ消費者がおり、この 2 つのアイデンティティはある程度重複する可能性があります。
#双方向実験とは、生産者側と消費者側のグループを組み合わせた実験方法です。
双方向実験には次の利点があります:
(1) 2 つの側面に対する新しい戦略の影響を同時に検出できます。商品DAUやアップロード作品など人数が変動します。二国間プラットフォームにはクロスサイドネットワーク効果があり、読者が増えれば増えるほど著者の活動が活発になり、著者の活動が活発になればなるほど、より多くの読者がフォローするようになります。
#(2) エフェクトのオーバーフローと転送を検出できます。
(3) 作用機序の理解を深めるのに役立ちます。AB 実験自体は、原因と結果の関係を伝えることはできませんが、ただ知ることができます。何が行われたのか、何が起こるのか、データはどのように変化するのか。ただし、生産側と消費側の間の作用メカニズムでは、これらの問題を明確に理解するために、より複雑な実験計画とより多くの実験指標が必要です。
#2. 双方向実験の例
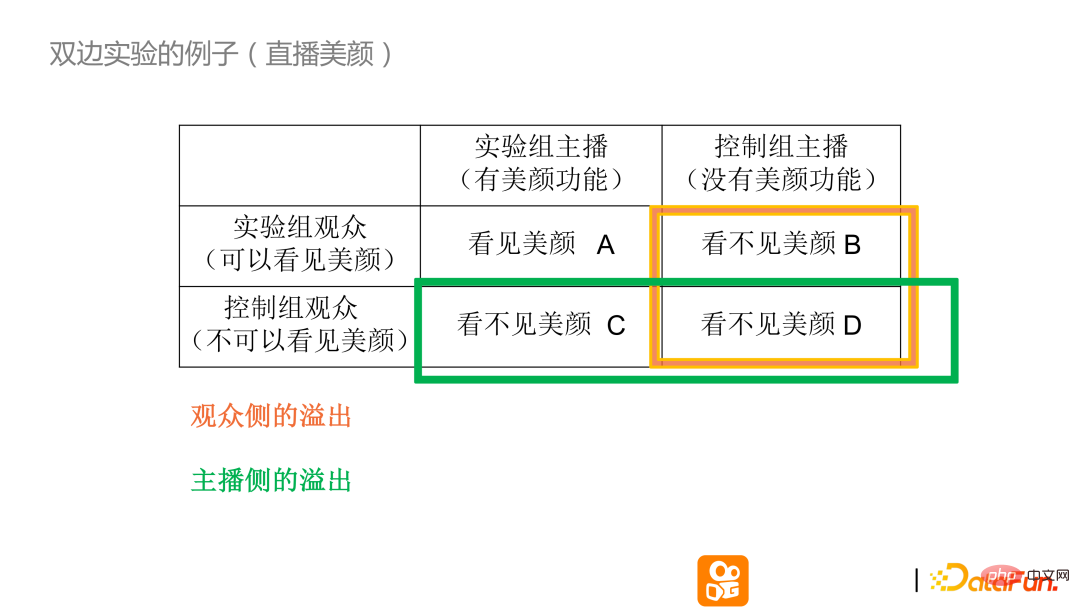
#このでは、誰もが双方向の実験をさらに理解できるように、生きた美しさの例を使用しています。
ライブ配信シーンに美容効果を追加するとします。テーブルを横から見ると、2 列の実験的な聴衆グループが、ライブ美容トリートメントの前後で違いが分かるかどうかをコントロールします。表の列は、アンカーに美しさがあるかどうかの実際の影響を表しています。上記の 2 つの側面を組み合わせると、実験グループのアンカーが実験グループの視聴者と比較した場合にのみ、ビデオの美化機能が有効になります。実際、他の 3 つのグループには美容機能が見えません。しかし、美しさを感じないBCと美しさを感じないDの間には違いがあります。 AD の区別は、通常の AB 実験における一般的なシナリオです。このシーンでは、観客側でオーバーフローがあるかどうかを観察するためにバイラテラル設計が使用されています。
アンカーの美しさについては、美化機能はありません。視聴者のオーバーフローがなければ BD データは一貫しているはずですが、実際には、アンカーに美容機能がない場合、データ BD の違いは、視聴者が他のアンカーの美容機能を見た場合、実際の効果はプラスまたはマイナスの影響を及ぼします。同様に、アンカー側のオーバーフローもこの種の両側実験を通じて行うことができ、実験のメカニズムと実験の両側でオーバーフローがあるかどうかをよりよく理解できます。
# 2. インセンティブ戦略の課題
(2) 一部の企業は、特定のタイプの作成者をマイニングする トラフィック分散を強化するために、いくつかのマクロ制御トラフィック サポートが提供されます;
#(3) プラットフォームのシナリオでは、次のようになります。プラットフォームが一定の方向に発展すると考え、トラフィック分散方法を変更し、対応する特定のコンテンツの供給を強化します。
上記のシナリオでは、多くの場合、これはオンライン学習の方法ではなく、人間の観点から見たプラットフォーム トラフィックのマクロ制御です。比較的長期に注目するものについては、学習効果(生産促進など)を観察する必要があり、タイムスライスローテーションなどの手法は試みられない。たとえば、次のシナリオ: ある種の方向性トラフィックを使用して作成者にトラフィック サポートを提供し、そのようなトラフィックの相互作用と生成が長期シナリオで長く続くことができるかどうかを調査します。 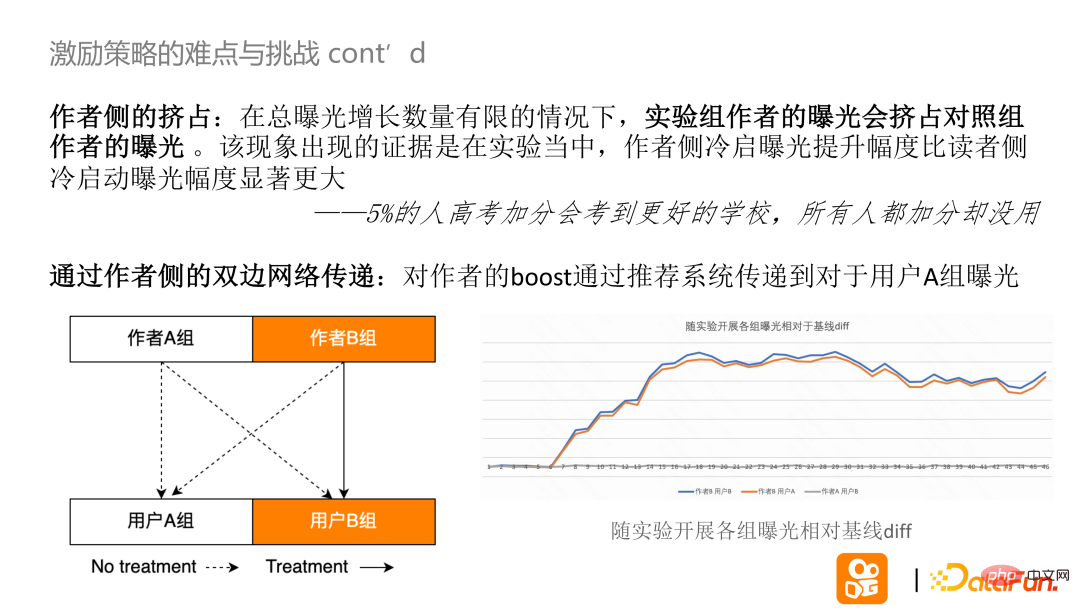
第一は、著者側の混雑です。これらの実験のほとんどは、総暴露量です。プラットフォームの数は限られており、プラットフォームサポートのシナリオでは、実験グループの著者の露出が増加する一方、サポートされていない対照グループの露出は減少します。著者のコールド スタート エクスポージャが読者のコールド スタート エクスポージャよりも増加する場合、それはクラウディングが発生していることを証明します。
上の図によると、実験グループと対照グループの関係および各グループの曝露の相対ベースライン差に基づいて、次のことがわかります。実験が始まると、作成者のブーストは最終的には合格します。推奨システムはそれをユーザー グループ B だけでなくユーザー グループ A にも渡します。また、作成者 B、ユーザー B、作成者 B、およびユーザー A の露出差は基本的に一貫しています。 。従来の実験は、この戦略によって歪められた交通状況を修正することに専念してきました。

#STVA 個人 i は、実験中、それ自身とともに実験グループにのみ割り当てられると仮定します。あるいは、それは対照グループに関連しており、他のノードが協力関係にあるか競合関係にあるかに関係なく、実験システムの下で他のノードがどのグループに属しているかには関係がありません。 SUTVA は、AB 実験で効果的な結論を得るための最も基本的な仮定です。
#実際の二国間ネットワークは STVA の仮定に違反しています。

短いビデオのシナリオでは、各録画戦略が並べ替えアルゴリズムとみなされる場合。異なるインセンティブ戦略は、短いビデオの異なるランキング結果を表します。上図の RC はコントロール グループを表し、RT_25% は実験グループのトラフィックが 25% の場合のアルゴリズム ソートの組み合わせ、RT は実験グループの実験プッシュ 100% アルゴリズム ソートの組み合わせを表します。 BCDE は実験対象のユーザー タイプ、つまり、選択されたインセンティブ作成者の作品です。そして D は、実験による推論が 25% の場合、まさに実験グループに該当することを意味します。推奨重み付け方法により、D が最前位にランクされたとします。戦略が100%になるとBCDEが重み付けされるため、D作品の順位が下がります。このシナリオは、実験グループの混雑と混雑の理由です。
3. オプションのソリューション1. オプション 1: 徐々に拡張する
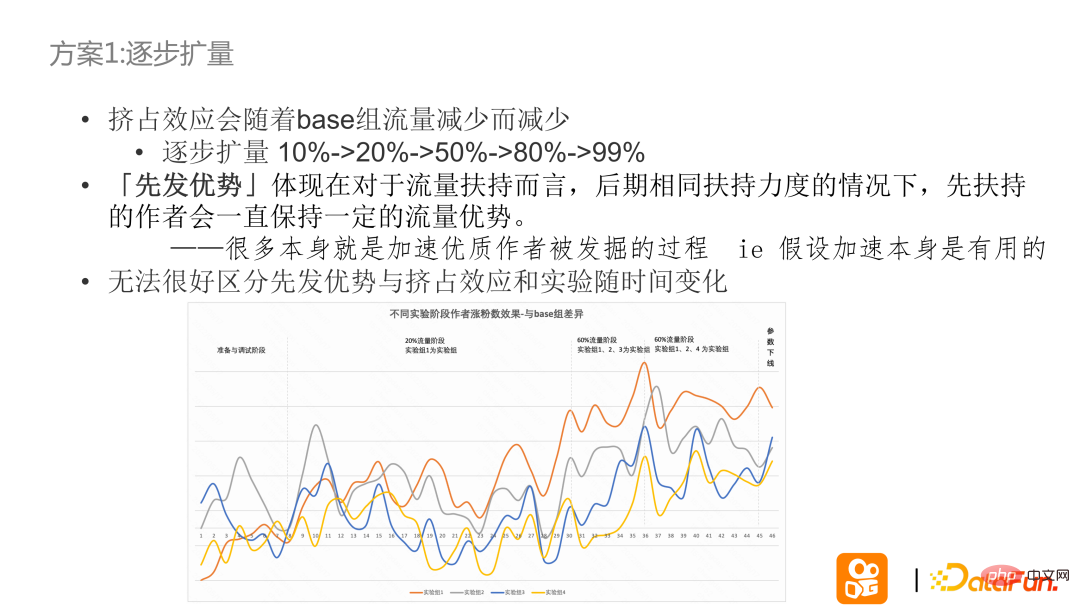
実験グループのデータ割合が拡大するにつれて、実験グループのソートギャップは徐々に近づき、トラフィックが増加するにつれて絞り出し効果は減少します。対照群は減少します。
#[先行者利益] 実験中、トラフィック サポートのシナリオでは、同じサポート強度で、最初に作成者をサポートすることが常に効果的であることがわかりました。交通上の優位性を維持します。早期の支援と掘削プロセスの加速のロジックは一貫しています。 段階的拡張の実験の詳細: 上の図は段階的拡張を示し、縦軸はベース グループと比較した粉末成長データの差です。実験の開始時には、実験グループの 20% が実験グループ 1 のみを支持し、実験グループ 1 のデータ指標が上昇し始めましたが、実験が 60% に増加すると、実験グループ 123 が支持し始め、実験指標は他の 2 つのグループも上昇し始めましたが、まだ実験グループ 1 を超えることはありませんでした。その後、実験グループを 124 に変更したところ、4 も改善し始めましたが、4 はまだ実験グループ 3 を超えることができませんでした。
このことから、次の結論が得られます: 段階的な拡張が有効です。拡張に応じて指標は増加します。トラフィックが拡張するにつれて増加が小さくなるかどうかを確認することはできません。現在の実験結果は、最初にトラフィック サポートを受けた実験グループのデータ パフォーマンスが、後でトラフィック サポートを受けた実験グループのデータ パフォーマンスよりも優れていると結論付けることができます。
2. プラン 2: 小さな世界を分割する上図に示すように、実験グループと対照グループは完全に分離されており、実験グループの読者は実験グループの作品のみを見ることができ、対照グループの読者はのみ閲覧できます。コントロールグループの作品をご覧ください。これにより、著者と読者の間の圧迫が回避されます。
同様のアプローチは、作成者と読者の間のトラフィック分散をネットワーク図として扱うことです。このネットワーク図はどこにでも接続されているわけではなく、一部の読者のみが接続することを好みます。この種の研究に基づいて、実験グループと対照グループは、このようなネットワーク図に基づいてセグメント化できます。上記のアプローチは、小さな世界を分割する方法と一致しており、実際の結果はより優れていますが、同時に計算コストも高くなります。

小さな世界を分割する際の主な問題は次のとおりです:
(1) アルゴリズム推奨システムシステムのサイズが桁違いである場合にのみコールド スタートを実行できるため、シャーディング プールを小さくする必要がある場合、実際のパーソナライズされた配布スペースに影響を与えます。レコメンデーションの柔軟な効果を維持するという前提の下、ビジネスやプラットフォームが異なれば、セグメンテーション構造の最も細かい粒度に対する要件も異なります。ほとんどの場合、限界効果を減少させることが推奨されます。
# (2) 明確な交通分離には、実験回数やサンプルの検査方法に一定の制限があります。並行実験シナリオでは、分離されたユーザーを常に再編成し、再分割する必要があります。

実験計画法ではなく分析法による修正:
- によると実際のネットワーク効果に対して補正分析を実行します。
- 実験結果に基づいて、いくつかの線形仮定とその他の条件付き仮定を作成します。
実験的補正を使用する理由:
まず、実際の解析補正手法の仮定は検証することが困難です。実験ではネットワーク効果の波及やクラウディングアウトが様々であり、短時間でルールをまとめるのは難しく、一般的な手法を得るのは不可能です。実際、私たちのソリューションは、多くの問題を解決することを目指しています。
#4. 包括的な計画を立てる
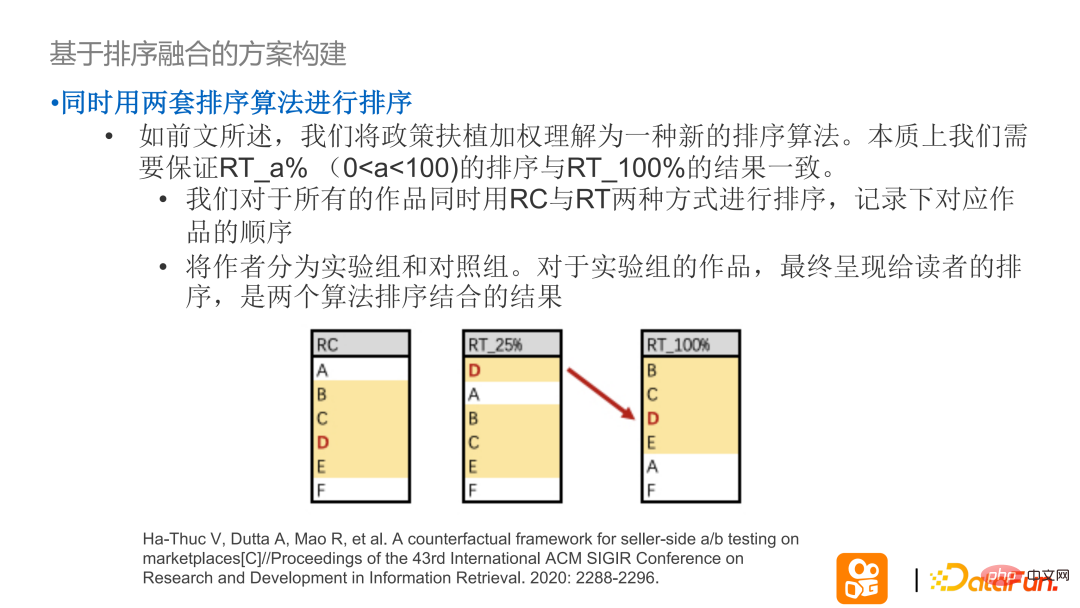
##ランキングの融合に基づいたソリューションの構築 - 本質的に、実験グループ RT_a% のランキングと実験グループ RT_100% の実際のランキングが一貫した結果を維持できるようにしたいと考えています。
実装方法: まず、2 セットの RT/RC ソート アルゴリズムを使用して同時にソートし、対応する作品の順序を記録し、著者を分割します。実験グループと対照グループに分けます。実験グループの場合、読者には 2 つのアルゴリズムのソートと融合の順序が示されます。
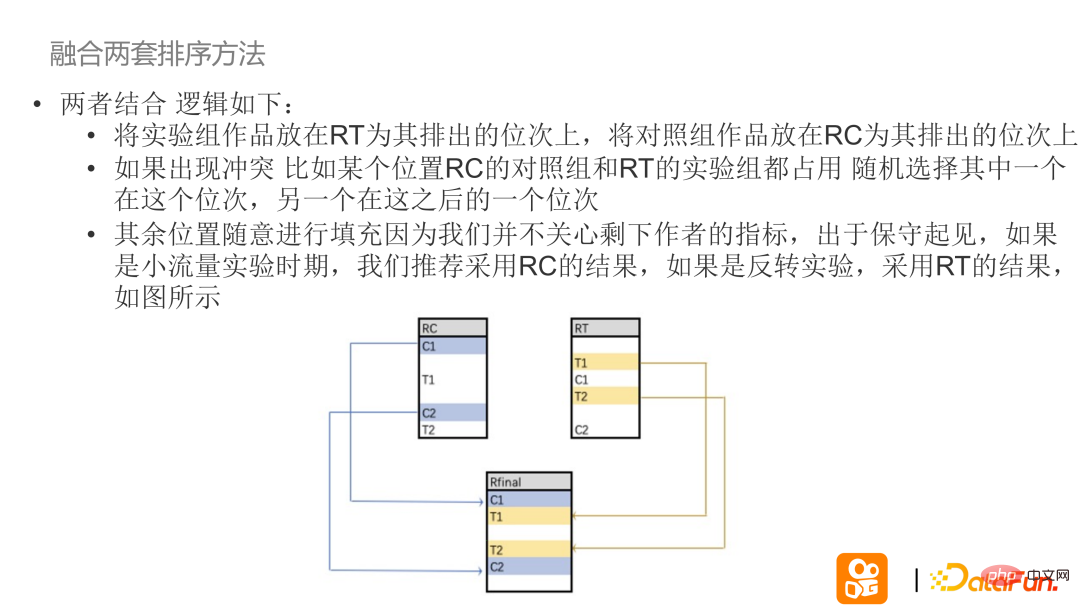
RC は、現在すべての作成者によってサポートされていないオンライン並べ替えソリューションであると考えてください。すべてのナレッジ著者の権利。 RC と RT のソート結果を融合するには、まず実験グループの RT に対応する著者 (T1T2) を最終グループの対応するソート位置に配置し、対照グループの著者を元のソートとは無関係な順序に保ちます。実験。保守的に、トラフィックが少ない期間中は、実験的な作品を除いて、他の作品を元の順序で埋めることをお勧めします。実験が外挿されている場合、RT の結果が完全に使用されます。

上記の実験計画に従って、実験グループの作品と対照グループの作品が同じ位置をめぐって競合する場合、最も簡単な方法はランダムに選択することです。このようなことが起こる確率は非常に低いです。
実験グループとコントロール グループの両方が総トラフィックの % を持っている場合、a=2 と仮定すると、 一度に 10 作品を昇格すると仮定すると、実験グループと対照グループの両方から上位 10 作品が出現する確率は上記のように計算され、約 3.3% となります。 2 つのアルゴリズムが完全に独立している場合、同じ上位 10 位で競合が発生する可能性は低くなります。 多くの場合、改善は段階的に行われ、RC と RT には高い相関関係があり、競合が少なくなります。同時に、オフラインテストを通じて競合の確率を事前に推定することもできます。 上記の双方向実験の主な指標評価は、次の 3 つのカテゴリに分類できます。
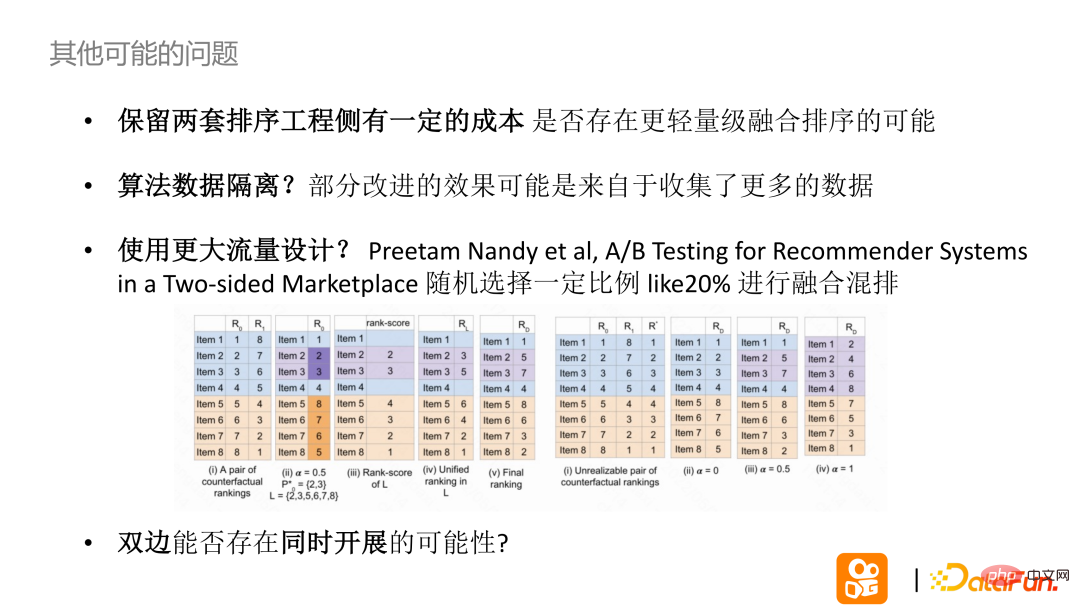
このソリューションには他にも問題がある可能性があります:
まず、どんな計画にも問題はつきものです。両面市場の強い波及効果により、すべての問題を 1 つの解決策で解決することが困難になります。
現在の実験計画における主な問題には次の側面が含まれます:
(1 ) まず第一に、2 つのソート セットを維持するにはエンジニアリング側から一定のコストがかかります。政策的なインセンティブが提供されれば、より効果的に促進されるでしょう。アルゴリズムの観点からは、2 つのソート セットを維持するのは簡単ではありません。融合;
(2) 次に、アルゴリズム データ分離の観点から見ると、改善の一部はデータ自体からもたらされます。モデルには大きな変更があります。その結果、並べ替えアルゴリズムのロジックが成り立たなくなります。
#(3) 第三に、計算では a=2% と仮定します。小さな効果をテストするためにより多くのトラフィックが使用される場合、a の値を増やすことができますか?比例混合をランダムに選択して、大規模なトラフィック競合の可能性を低くします。最後に、二国間問題は一方的に解決されるが、二国間で解決できるかどうかは今後検討される。
以上がKuaishou の両面市場における複雑な実験計画の問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
31
15
1377
52
77
11
19
31

 Kuaishou の両面市場における複雑な実験計画の問題
Apr 15, 2023 pm 07:40 PM
Kuaishou の両面市場における複雑な実験計画の問題
Apr 15, 2023 pm 07:40 PM
1. 問題の背景 1. 両面市場実験の概要 両面市場、つまりプラットフォームには、生産者と消費者の 2 つの参加者が含まれ、双方がお互いを促進します。たとえば、Kuaishou にはビデオ制作者とビデオ消費者がおり、この 2 つのアイデンティティはある程度重複する可能性があります。バイラテラル実験とは、生産者側と消費者側のグループを組み合わせた実験手法です。双方向実験には以下のようなメリットがあります。 (1) 製品の DAU や作品アップロード者数の変化など、新たな戦略による 2 つの側面への影響を同時に検出できます。二国間プラットフォームには多くの場合クロスサイドネットワーク効果があり、読者が増えれば増えるほど著者の活動が活発になり、著者の活動が活発になればなるほど、より多くの読者がフォローするようになります。 (2) エフェクトのオーバーフローや転送を検出できます。 (3) 作用機序をより深く理解するのに役立ちます。AB 実験自体は、原因と結果の関係を伝えることはできません。
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 Google は AI を使用して 10 年間にわたるランキング アルゴリズムの封印を破りました。このアルゴリズムは毎日何兆回も実行されていますが、ネチズンはこれが最も非現実的な研究だと主張していますか?
Jun 22, 2023 pm 09:18 PM
Google は AI を使用して 10 年間にわたるランキング アルゴリズムの封印を破りました。このアルゴリズムは毎日何兆回も実行されていますが、ネチズンはこれが最も非現実的な研究だと主張していますか?
Jun 22, 2023 pm 09:18 PM
並べ替え | Nuka-Cola、Chu Xingjuan 基本的なコンピューター サイエンスのコースを受講した友人なら、並べ替えアルゴリズムを個人的に設計したはずです。つまり、コードを使用して、順序なしリスト内の項目を昇順または降順に並べ替えます。これは興味深い挑戦であり、実現する方法はたくさんあります。並べ替えタスクをより効率的に実行する方法を見つけるために、多くの時間が費やされてきました。基本的な操作として、並べ替えアルゴリズムはほとんどのプログラミング言語の標準ライブラリに組み込まれています。オンラインで大量のデータを整理するために、世界中のコードベースでさまざまなソート手法やアルゴリズムが使用されていますが、少なくとも LLVM コンパイラで使用される C++ ライブラリに関する限り、ソート コードは 10 年以上変わっていません。 。最近、Google DeepMindAI チームは、
 Vue テクノロジー開発でデータをフィルターおよび並べ替える方法
Oct 09, 2023 pm 01:25 PM
Vue テクノロジー開発でデータをフィルターおよび並べ替える方法
Oct 09, 2023 pm 01:25 PM
Vue テクノロジ開発でデータをフィルタリングおよび並べ替える方法 Vue テクノロジ開発では、データのフィルタリングと並べ替えは非常に一般的で重要な機能です。データのフィルタリングと並べ替えを通じて、必要な情報を迅速にクエリして表示できるため、ユーザー エクスペリエンスが向上します。この記事では、Vue でデータをフィルターおよび並べ替える方法を紹介し、読者がこれらの関数をよりよく理解して使用できるように具体的なコード例を示します。 1. データのフィルタリング データのフィルタリングとは、特定の条件に基づいて要件を満たすデータをフィルタリングすることを指します。 Vue では、comp を渡すことができます
 C# で選択ソート アルゴリズムを実装する方法
Sep 20, 2023 pm 01:33 PM
C# で選択ソート アルゴリズムを実装する方法
Sep 20, 2023 pm 01:33 PM
選択ソート アルゴリズムを C# で実装する方法 選択ソート (SelectionSort) は、単純で直感的なソート アルゴリズムであり、その基本的な考え方は、毎回ソートする要素から最小 (または最大) の要素を選択し、それを最後に配置することです。ソートされたシーケンス。すべての要素が並べ替えられるまで、このプロセスを繰り返します。 C# で選択並べ替えアルゴリズムを実装する方法と、具体的なコード例について詳しく学びましょう。選択ソートメソッドの作成 まず、選択ソートを実装するメソッドを作成する必要があります。このメソッドは、
 Swoole Advanced: マルチスレッドを使用して高速ソート アルゴリズムを実装する方法
Jun 14, 2023 pm 09:16 PM
Swoole Advanced: マルチスレッドを使用して高速ソート アルゴリズムを実装する方法
Jun 14, 2023 pm 09:16 PM
Swoole は、PHP 言語をベースとした高性能ネットワーク通信フレームワークで、複数の非同期 IO モードと複数の高度なネットワーク プロトコルの実装をサポートしています。 Swoole をベースとして、そのマルチスレッド機能を使用して、高速ソート アルゴリズムなどの効率的なアルゴリズム操作を実装できます。高速ソートアルゴリズム (QuickSort) は一般的なソートアルゴリズムであり、ベンチマーク要素を配置すると、要素が 2 つの部分列に分割され、ベンチマーク要素より小さいものは左側に配置され、ベンチマーク以上の要素は左に配置されます。要素が右側に配置され、次に左右のサブシーケンスが配置されます。
 配列のソートアルゴリズムは何ですか?
Jun 02, 2024 pm 10:33 PM
配列のソートアルゴリズムは何ですか?
Jun 02, 2024 pm 10:33 PM
配列ソートアルゴリズムは、要素を特定の順序で配置するために使用されます。一般的なアルゴリズムの種類は次のとおりです。 バブル ソート: 隣接する要素を比較して位置を交換します。選択ソート: 最小の要素を見つけて、それを現在の位置に入れ替えます。挿入ソート: 要素を 1 つずつ正しい位置に挿入します。クイックソート: 分割統治法。配列を分割するピボット要素を選択します。マージソート: 分割統治、再帰的ソート、およびサブ配列のマージ。
 C++ で基数ソート アルゴリズムを使用する方法
Sep 19, 2023 pm 12:15 PM
C++ で基数ソート アルゴリズムを使用する方法
Sep 19, 2023 pm 12:15 PM
C++ で基数ソート アルゴリズムを使用する方法 基数ソート アルゴリズムは、並べ替える要素を限られた桁のセットに分割することによって並べ替えを完了する非比較並べ替えアルゴリズムです。 C++ では、基数ソート アルゴリズムを使用して整数のセットをソートできます。以下では、特定のコード例を使用して、基数ソート アルゴリズムを実装する方法を詳しく説明します。アルゴリズムのアイデア 基数ソート アルゴリズムのアイデアは、ソート対象の要素を限られたデジタル ビットのセットに分割し、各ビットで順番に要素をソートすることです。各ビットのソートが完了しました
