

ChatGPT の背後にある動作原理を簡単に説明する

ChatGPT は OpenAI によってリリースされた最新の言語モデルであり、以前の GPT-3 に比べて大幅に改善されています。多くの大規模言語モデルと同様に、ChatGPT はさまざまなスタイルやさまざまな目的に合わせてテキストを生成でき、精度、物語の詳細、文脈の一貫性のパフォーマンスが向上します。これは OpenAI の大規模言語モデルの最新世代を表しており、対話性に重点を置いて設計されています。
OpenAI は、教師あり学習と強化学習を組み合わせて ChatGPT を調整し、強化学習コンポーネントによって ChatGPT を独自のものにします。 OpenAI は、トレーニングに人間のフィードバックを使用して、役に立たない、歪んだ、または偏った出力を最小限に抑える「ヒューマン フィードバックによる強化学習」(RLHF) トレーニング手法を使用します。
この記事では、GPT-3 の制限と、それがトレーニング プロセスから生じる理由を分析し、RLHF の原理を説明し、ChatGPT が RLHF を使用して問題を克服する方法を理解します。 GPT-3 の既存の問題点について質問し、最後にこのアプローチの限界について検討します。
大規模言語モデルにおける能力と一貫性
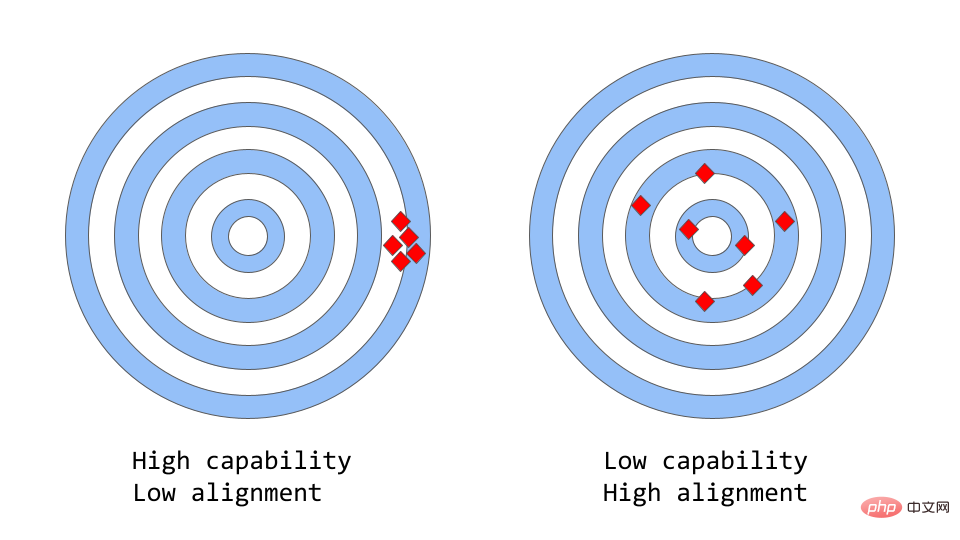
「一貫性と能力」は次のように考えることができます。これは、「精度 vs 精度」のより抽象的な例えです。
#機械学習では、モデルの能力とは、特定のタスクまたは一連のタスクを実行するモデルの能力を指します。モデルの能力は通常、目的関数を最適化できる程度によって評価されます。たとえば、市場価格の予測に使用されるモデルには、モデルの予測の精度を測定する目的関数が含まれる場合があります。時間の経過に伴う運賃の変化を正確に予測できるモデルは、高いパフォーマンスを発揮すると考えられます。
一貫性は、モデルが何をするようにトレーニングされたかではなく、モデルに実際に何をさせたいかに焦点を当てます。それが提起する問題は、モデルの目標と行動が人間の期待をどの程度満たしているかに基づいて、「目的関数が期待を満たしているかどうか」です。対数損失をトレーニング目標として使用して、鳥を「スズメ」または「コマドリ」に分類する鳥分類器をトレーニングしたいとします。最終的な目標は、非常に高い分類精度です。モデルの対数損失が低い可能性があります。つまり、モデルの能力は向上していますが、テスト セットでは精度が低くなります。これは、モデルがトレーニング目標を最適化できるものの、最終目標とは一致しない、不一致の一例です。
オリジナルの GPT-3 は一貫性のないモデルです。 GPT-3 のような大規模な言語モデルは、インターネットからの大量のテキスト データでトレーニングされ、人間のようなテキストを生成できますが、常に人間の期待に一致する出力を生成するとは限りません。実際、その目的関数は一連の単語にわたる確率分布であり、一連の単語の次の単語が何になるかを予測するために使用されます。
しかし、実際のアプリケーションでは、これらのモデルの目的は、何らかの形で価値のある認知作業を実行することであり、これらのモデルのトレーニング方法とモデルがどのように期待されるかの間にはギャップがあります。使用済み 重大な違い。数学的に言えば、単語シーケンスの統計的分布を計算する機械は言語をモデル化するのに効率的な選択である可能性がありますが、人間は既知の背景知識と常識を使用して、特定の状況に最も適合するテキストシーケンスを選択することによって言語を生成し、このプロセスを支援します。これは、会話システムやインテリジェントパーソナルアシスタントなど、高度な信頼性を必要とするアプリケーションで言語モデルが使用される場合に問題になる可能性があります。
膨大な量のデータでトレーニングされたこれらの大規模なモデルは、過去数年間で非常に強力になりましたが、実際に使用すると、その可能性を十分に発揮できないことがよくあります。人々の生活が楽になります。大規模な言語モデルにおける一貫性の問題は、次のような形で現れることがよくあります:
- #効果のないヘルプを提供する: ユーザーからの明示的な指示に従わない。
- コンテンツはでっち上げられており、存在しない、または間違った事実をでっち上げたモデルです。
- 説明可能性の欠如: モデルがどのようにして特定の決定や予測に至ったのかを理解するのは困難です。
- 有害なコンテンツ バイアス: 偏見のある有害なデータに基づいてトレーニングされた言語モデルは、明示的に指示されていない場合でも、出力でこの動作を示す可能性があります。
しかし具体的には、一貫性の問題はどこから来るのでしょうか?言語モデルのトレーニング方法自体に矛盾が生じやすいですか?
言語モデルのトレーニング戦略によってどのように矛盾が生じるのでしょうか?
次のトークン予測とマスクされた言語モデリングは、言語モデルをトレーニングするためのコア テクノロジです。最初のアプローチでは、モデルに一連の単語が入力として与えられ、そのシーケンス内の次の単語を予測するように求められます。モデルに次の入力文を提供すると、
「猫は上に座りました」
次の単語が「マット」、「椅子」、または「」と予測される可能性があります。 「floor」は、これらの単語が前のコンテキストで高い確率で出現するためです。言語モデルは実際に、前のシーケンスを考慮して、考えられる各単語の可能性を評価できます。
マスクされた言語モデリング手法は、次のトークン予測のバリエーションであり、入力文内の一部の単語が [MASK] などの特別なトークンに置き換えられます。次にモデルは、マスク位置に挿入されるべき正しい単語を予測するように求められます。モデルに次のような文を与えると:
「[MASK] は "
にありました。」という文を与えると、MASK の位置に埋められる単語は次のとおりであると予測される可能性があります。 「猫」と「犬」。
これらの目的関数の利点の 1 つは、モデルが一般的な単語シーケンスや単語の使用パターンなどの言語の統計構造を学習できることです。これは多くの場合、モデルがより自然で流暢なテキストを生成するのに役立ち、すべての言語モデルの事前トレーニング段階における重要なステップです。
ただし、これらの目的関数は、主にモデルが重要なエラーと重要でないエラーを区別できないために問題を引き起こす可能性もあります。非常に単純な例は、モデルに次の文を入力した場合です:
「アウグストゥス統治下のローマ帝国 [MASK]」
これは MASK を予測する可能性があります。これら 2 つの単語が出現する可能性が非常に高いため、この位置には「begin」または「end」を入力する必要があります。
一般に、これらのトレーニング戦略は、一連のテキスト内の次の単語を予測することのみを目的としてトレーニングされたモデルであるため、より複雑なタスクで言語モデルのパフォーマンスに一貫性がなくなる可能性があります。それらの意味のより高いレベルの表現は必ずしも学習されるとは限りません。したがって、このモデルを言語のより深い理解を必要とするタスクに一般化することは困難です。
研究者たちは、大規模な言語モデルにおける一貫性の問題を解決するためのさまざまな方法を研究しています。 ChatGPT は元の GPT-3 モデルに基づいていますが、モデル内の不一致に対処する学習プロセスを導くために人間のフィードバックを使用してさらにトレーニングされました。使用される具体的な技術は、前述の RLHF です。 ChatGPT は、このテクノロジーを現実のシナリオで使用する最初のモデルです。
それでは、ChatGPT は人間のフィードバックをどのように利用して一貫性の問題を解決するのでしょうか?
人間のフィードバックからの強化学習
この方法は通常、次の 3 つの異なるステップで構成されます:
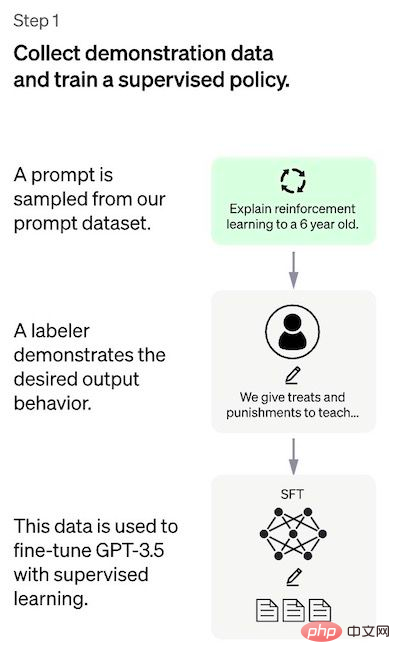
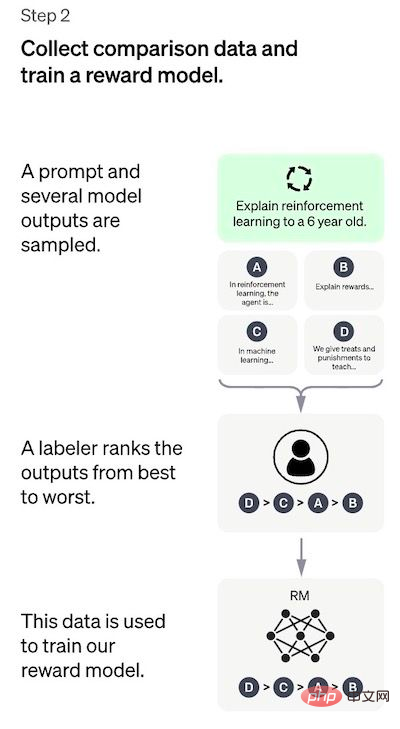
- はい 教師ありチューニング: 事前トレーニングされた言語モデルは、与えられたプロンプトのリストから出力を生成する教師ありポリシー (つまり、SFT モデル) を学習するために、少量のラベル付きデータに基づいて調整されます。人間の好み: アノテーターは比較的多数の SFT モデル出力に投票し、比較データの新しいデータセットを作成します。新しいモデルは、トレーニング報酬モデル (RM) と呼ばれる、このデータ セットでトレーニングされます。
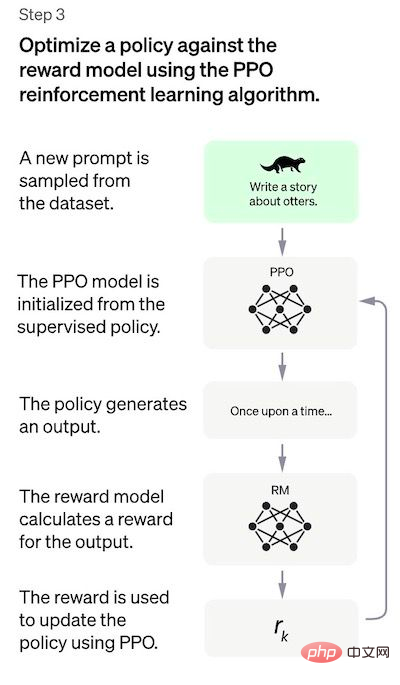
- 近接ポリシー最適化 (PPO): RM モデルは、さらなる調整と、 SFTモデル、PPOの出力結果が戦略モデルです。
- ステップ 1 は 1 回のみ実行されますが、ステップ 2 と 3 は継続的に繰り返すことができます。新しい RM モデルをトレーニングするために、現在最適なポリシー モデルに関するさらに多くの比較データを収集します。新しいポリシーをトレーニングします。次に、各ステップの詳細について説明する。
#ステップ 1: 教師ありチューニング モデル
## 最初のステップは、教師ありポリシー モデルをトレーニングするためのデータを収集することです。 ChatGPT のようなユニバーサル チャットボットを作成するには、開発者はプレーン テキスト モデルではなく「コード モデル」を調整します。 このステップのデータ量は限られているため、このプロセスで取得された SFT モデルは、まだユーザーにとって関心のないテキストを出力する可能性があります。そして、しばしば矛盾の疑問に悩まされることになります。ここでの問題は、教師あり学習ステップのスケーラビリティ コストが高いことです。 この問題を克服するために使用される戦略は、ヒューマン・アノテーターに大規模で洗練されたモデルを作成させるのではなく、SFT モデルのさまざまな出力をソートして RM モデルを作成させることです。モデル データセットを選択します。 #ステップ 2: 戻りモデルのトレーニング このステップの目標は、目的関数を直接学習することです。データ。この関数の目的は、SFT モデルの出力をスコアリングすることです。これは、これらの出力が人間にとってどれだけ望ましいかを表します。これは、選ばれたヒューマン・アノテーターの特定の好みと、彼らが従うことに同意した共通のガイドラインを強く反映しています。最終的に、このプロセスにより、データから人間の好みを模倣するシステムが完成します。 その仕組みは次のとおりです: アノテーターにとって、最初からタグ付けするよりも出力を並べ替えるほうがはるかに簡単で、プロセスの拡張がより効率的になります。 。実際には、選択されるプロンプトの数は約 30 ~ 40,000 で、並べ替えられた出力のさまざまな組み合わせが含まれます。 ステップ 3: PPO モデルを使用して SFT モデルを微調整する このステップでは強化学習が適用されますRM モデルを最適化して SFT モデルを調整します。使用される特定のアルゴリズムは近接ポリシー最適化 (PPO) と呼ばれ、調整モデルは近接ポリシー最適化モデルと呼ばれます。 PPO とは何ですか?このアルゴリズムの主な特徴は次のとおりです: パフォーマンス評価 モデルは 3 つの基準に基づいて評価されます。 有用性: ユーザーの指示に従い、指示を推定するモデルの能力を判断します。 これらのデータセットのパフォーマンス回帰は、事前トレーニング混合と呼ばれる手法によって大幅に軽減できます。勾配降下法による PPO モデルのトレーニング中に、SFT モデルと PPO モデルの勾配が調整されます。勾配更新を混合することによって計算されます。 この方法の欠点 デモ データを生成した手動アノテーターの好み; この明らかな「内因性」制限に加えて、この方法には解決すべき他の欠点や問題もあります。 関連書籍:
以上がChatGPT の背後にある動作原理を簡単に説明するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェント カスタマー サービス チャットボットの作成 はじめに: 今日の情報化時代において、インテリジェント カスタマー サービス システムは企業と顧客の間の重要なコミュニケーション ツールとなっています。より良い顧客サービス体験を提供するために、多くの企業が顧客相談や質問応答などのタスクを完了するためにチャットボットに注目し始めています。この記事では、OpenAI の強力なモデル ChatGPT と Python 言語を使用して、インテリジェントな顧客サービス チャットボットを作成し、顧客サービスを向上させる方法を紹介します。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
この記事では、ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法を紹介し、いくつかの具体的なコード例を示します。 ChatGPT は、OpenAI によって開発された生成事前トレーニング トランスフォーマーの最新バージョンです。これは、自然言語を理解し、人間のようなテキストを生成できるニューラル ネットワーク ベースの人工知能テクノロジーです。 ChatGPT を使用すると、適応型チャットを簡単に作成できます
 中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
chatgpt は中国でも使用できますが、香港やマカオでも登録できません。ユーザーが登録したい場合は、外国の携帯電話番号を使用して登録できます。登録プロセス中にネットワーク環境を切り替える必要があることに注意してください。外国のIP。
 ChatGPTとPythonを使ってユーザー意図認識機能を実装する方法
Oct 27, 2023 am 09:04 AM
ChatGPTとPythonを使ってユーザー意図認識機能を実装する方法
Oct 27, 2023 am 09:04 AM
ChatGPT と Python を使用してユーザー意図認識機能を実装する方法 はじめに: 今日のデジタル時代において、人工知能技術はさまざまな分野で徐々に不可欠な部分になりました。その中で、自然言語処理 (Natural Language Processing、NLP) テクノロジーの開発により、機械が人間の言語を理解して処理できるようになります。 ChatGPT (Chat-GeneratingPretrainedTransformer) は、
 ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法 はじめに: 人工知能技術の発展に伴い、顧客サービスの分野でロボットの使用が増えています。 ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築すると、企業はより効率的でパーソナライズされた顧客サービスを提供できるようになります。この記事では、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法を紹介し、具体的なコード例を示します。 1. ChatGPTPHP をインストールし、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築します。
 SearchGPT: Open AI が独自の AI 検索エンジンで Google に対抗
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI が独自の AI 検索エンジンで Google に対抗
Jul 30, 2024 am 09:58 AM
オープン AI がついに検索に進出します。サンフランシスコの同社は最近、検索機能を備えた新しい AI ツールを発表した。今年 2 月に The Information によって初めて報告されたこの新しいツールは、まさに SearchGPT と呼ばれ、次のような機能を備えています。
