

MySQL の基本的な問題は何ですか?


一般章
1. データベースの 3 つの主要なパラダイムについて話しましょう。
第 1 正規形: フィールドのアトミック性、第 2 正規形: 主キー列を含む一意の行、第 3 正規形: 各列は主キー列に関連付けられます。
実際のアプリケーションでは、関連テーブルの数を減らし、クエリ効率を向上させるために、少数の冗長フィールドが使用されます。
2. 1 つのデータのみがクエリされますが、実行が非常に遅いです。一般的な理由は何ですか?
MySQL データベース自体がブロックされています。たとえば、システムまたはネットワーク リソースが不十分です。
SQL ステートメントがブロックされています。たとえば、次のとおりです。テーブル ロック、行ロックなどにより、ストレージ エンジンが対応する SQL ステートメントを実行できなくなります。
-
インデックスが不適切に使用されており、インデックスが使用されていません。
テーブル内のデータの特性により、インデックスは削除されますが、テーブルの戻り値の数は膨大です
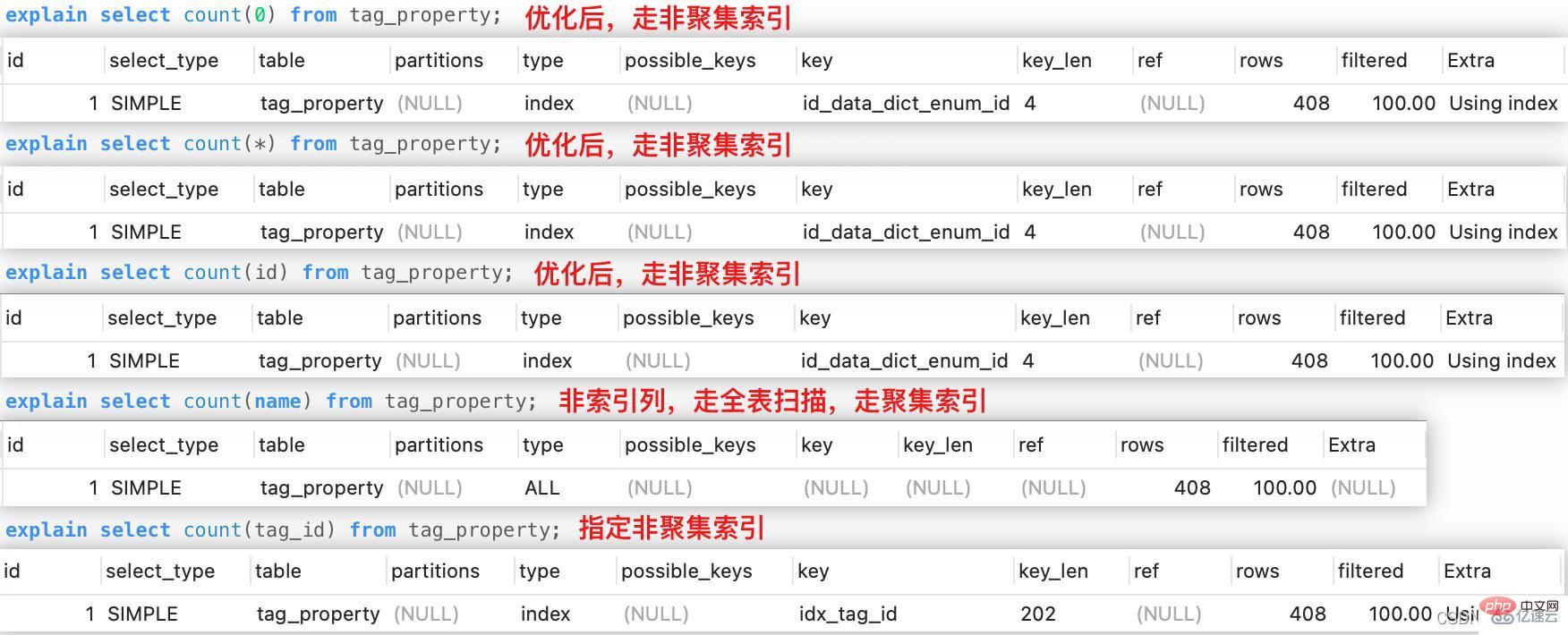
3, count(*)、count(0)、count(id)の実装メソッドの違いは?
count(*)、count(定数)、count(主キー)フォームの場合count 関数の場合、オプティマイザはスキャン コストが最小のインデックスを選択してクエリを実行できるため、効率が向上します。これらの実行プロセスは同じです。count (非インデックス列)の場合、オプティマイザは全テーブル スキャンを選択します。これは、クラスター化インデックスのリーフ ノードのみを順次スキャンできることを意味します。 。count (セカンダリ インデックス列)指定した列を含むインデックスのみを選択してクエリを実行できます。これにより、選択したインデックスの実行コストが発生する可能性があります。オプティマイザによって一貫性がなくなるため、最小ではありません。
#4. 誤ってデータを削除してしまった場合はどうすればよいですか?
1) データ量が比較的大きい場合は、物理バックアップ xtrabackup を使用します。データベースの完全バックアップを定期的に実行します。また、増分バックアップを実行することもできます。 2) データ量が少ない場合は、mysqldump または mysqldumper を使用して、binlog を使用してデータを回復するか、マスター/スレーブ方式を設定してデータを回復します。- #DML 誤操作ステートメント: フラッシュバックを使用して、最初に binlog イベントを解析し、次にそれを元に戻すことができます。
- DDL ステートメントの誤操作: データは完全バックアップとバイナリログ アプリケーションを通じてのみ復元できます。データの量が比較的多くなると、回復時間が特に長くなります。
- rm 削除: コンピュータ ルーム全体、できれば都市全体でバックアップを使用します。
- DELETE ステートメントはテーブルからの削除処理を実行します。毎回行を削除し、ロールバック操作のために行の削除をトランザクション レコードとしてログに保存します。
- TRUNCATE TABLE は、テーブルからすべてのデータを一度に削除し、個々の削除操作レコードをログに記録しません。削除された行は復元できません。また、削除処理中にテーブルに関連する削除トリガーが起動されず、実行速度が速くなります。
- drop ステートメントは、テーブルによって占められていたすべてのスペースを解放します。
- MySQL は「読み取り中に送信」しているため、クライアントの受信が遅い場合、MySQL サーバーはこのトランザクションにより結果を送信できません。時間が長くなります。
- サーバーは完全な結果セットを保存する必要はありません。データの取得および送信のプロセスはすべて next_buffer を通じて操作されます。
- メモリ データ ページはバッファ プール (BP) で管理されます。
- InnoDB は、リンク リストを使用して実装された、改良された LRU アルゴリズムを使用してバッファ プールを管理します。 InnoDB の実装では、コールド データが大規模なバッチでロードされたときにホット データが流されないように、LRU リンク リスト全体が 5:3 の比率に従って若いエリアと古いエリアに分割されます。
- ID 最適化を使用する: 最初に検索します。最後のページング 最大 ID を指定し、select * from user where id>1000000 limit 100 と同様に、ID のインデックスを使用してクエリを実行します。
カバリング インデックスによる最適化: MySQL クエリがインデックスに完全にヒットすると、それはカバリング インデックスと呼ばれます。クエリはインデックス上で検索するだけでよく、その後直接返すことができるため、非常に高速です。なし その後、テーブルに戻ってデータを取得するため、まずインデックスの ID を確認し、その ID に基づいてデータを取得できます。
ビジネスが許可する場合はページ数を制限します
8. 日々の開発で SQL をどのように最適化していますか?
- 適切なインデックスの追加: クエリ条件として使用されるフィールドのインデックスを作成し、並べ替えます。複数のクエリ フィールドを考慮して結合インデックスを確立し、順序に注意してください。結合されたインデックス フィールド。制限条件として最もよく使用される列を左端に降順で配置します。インデックスは多すぎてはならず、通常は 5 以内にします。
- テーブル構造の最適化: 数値フィールドは文字列型よりも優れています。通常は、データ型が小さいほど優れています。NOT NULL を使用してみてください。
- 最適化クエリステートメント: SQL の実行計画、インデックスがヒットしたかどうかなどを分析します。SQL が非常に複雑な場合は、SQL 構造を最適化します。テーブルのデータ量が大きすぎる場合は、テーブルの分割を検討してください。
##9、MySQL 同時接続と同時クエリの違いは何ですか?
show processlist を実行した結果、同時接続を意味する数千の接続が表示されました。
ステートメント「現在実行中」は同時クエリです。
同時接続の数はメモリに影響します。
同時クエリが多すぎると、CPU に悪影響を及ぼします。マシンの CPU コアの数は限られており、すべてのスレッドが殺到すると、コンテキスト切り替えのコストが高くなりすぎます。
スレッドがロック待機に入った後は、同時スレッド数が 1 つ減るため、行ロックやギャップ ロックを待機しているスレッドはカウント範囲に含まれないことに注意してください。 。つまり、ロックを待機しているスレッドが CPU を消費しないため、システム全体のロックが防止されます。
#10. フィールド値を元の値に更新するとき、MySQL は内部的にどのように動作しますか?
- #同じデータを使用する場合、更新は行われません。
- ただし、ログ処理方法はバイナリログ形式ごとに異なります:
- 1) 行モードに基づく場合、サーバーレイヤーは、更新されるレコードと一致し、新しい値が古い値と一致することを検出し、更新せずに直接返し、バイナリログを記録しません。
- 2) ステートメントまたは混合形式に基づく場合、MySQL は更新ステートメントを実行し、更新ステートメントを binlog に記録します。
#11. 日時とタイムスタンプの違いは何ですか?
- datetime の日付範囲は 1001 ~ 9999、タイムスタンプの時間範囲は 1970 ~ 2038です
- datetime storage Time は次のとおりです。タイムゾーンとは関係ありません。タイムスタンプの保存時間はタイムゾーンに関連しており、表示される値もタイムゾーンに依存します。
- 日時の保存スペースは 8 バイトです。タイムスタンプは 4 バイトです
- 日時のデフォルト値は null、タイムスタンプ フィールドのデフォルト値は null ではなく (null ではない)、デフォルト値は現在の時刻 (current_timestamp)
12. トランザクションの分離レベルは何ですか?
- 「Read Uncommitted」は最低レベルであり、いかなる状況でも保証されません
- 「Read Uncommitted」 (Read Committed)ダーティ リードの発生を回避できます。 # 「Repeatable Read」は、ダーティ リードと Non-Repeatable Read の発生を回避できます。##「Serializable」ダーティ リード、非反復読み取り、ファントム リードの発生を回避できます。
- Mysql のデフォルトのトランザクション分離レベルは「反復読み取り」です)
- 13. MySQL には 2 つの kill コマンドがあります
kill クエリ スレッド ID は、このスレッドを終了することを意味します # で実行されるステートメント
##kill 接続スレッド ID (接続はデフォルトにすることができます) は、このスレッドを切断することを意味します##インデックス
- 1.インデックスカテゴリ?
リーフ ノードの内容に応じて、インデックス タイプは主キー インデックスと非主キー インデックスに分かれます。
主キー インデックスのリーフ ノードには、データ行全体が格納されます。 InnoDB では、主キー インデックスはクラスター化インデックスとも呼ばれます。
非主キー インデックスのリーフ ノードの内容は、主キーの値です。 InnoDB では、主キー以外のインデックスはセカンダリ インデックスとも呼ばれます。
#2. クラスター化インデックスと非クラスター化インデックスの違いは何ですか?
-
クラスター化インデックス: クラスター化インデックスは、主キーを使用して作成されるインデックスであり、テーブル内のデータをリーフ ノードに格納します。

-
##非クラスター化インデックス: 非主キーを使用して作成されたインデックスは、主キーとインデックス列をリーフ ノードに保存します。 -クラスター化インデックス: クラスター化インデックスがデータをクエリするとき、リーフの主キーを取得して、検索するデータを検索します。 (主キーを取得して検索するプロセスは、テーブル リターンと呼ばれます)。
カバーインデックス: クエリ対象の列がたまたまインデックスに対応する列であると仮定すると、その必要はありません。このインデックス列をカバーインデックスと呼びます。
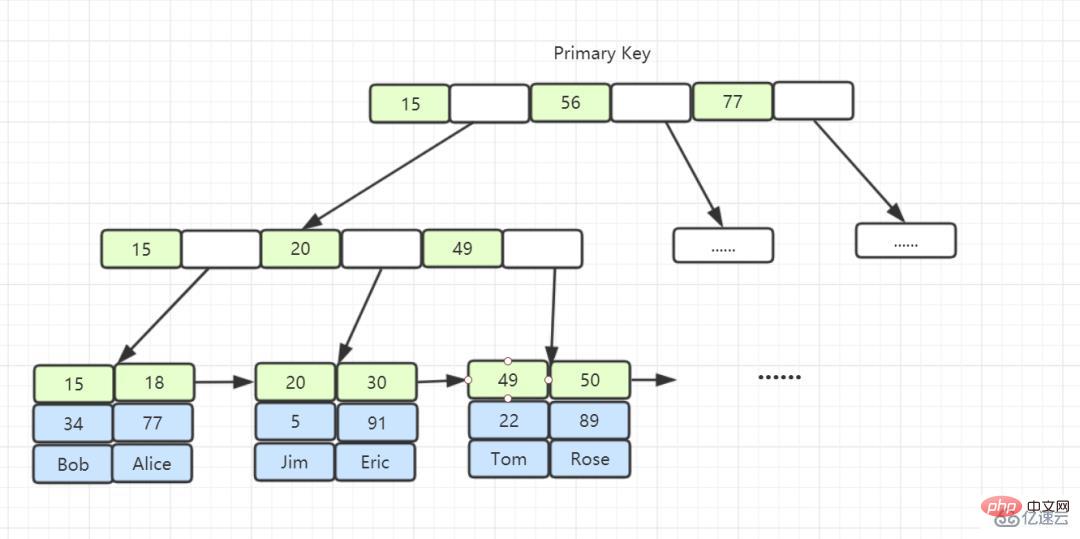
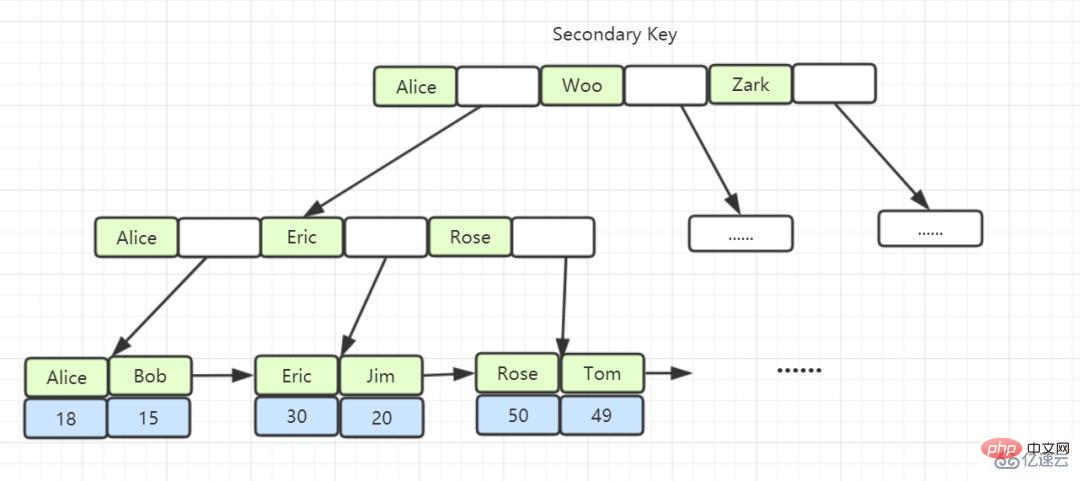
3. InnoDB が B ツリー、ハッシュ、バイナリ ツリー、赤黒ツリーではなく B ツリーを設計するのはなぜですか?
- ハッシュ インデックスは、単一データ行の追加、削除、変更、クエリを O(1) の速度で処理できますが、範囲クエリや並べ替えに直面すると、フルテーブルスキャンが発生します。
- B ツリーは非リーフ ノードにデータを保存できます。すべてのノードにターゲット データが含まれている可能性があるため、ルート ノードからサブツリーを下にたどって、条件を満たすものを見つける必要があります。データ行の場合、この機能により大量のランダム I/O が発生し、パフォーマンスの低下を引き起こします。
- B ツリーのすべてのデータ行はリーフ ノードに格納されており、これらのリーフ ノードは「ポインター」を介して順番に接続できます。複数の子ノード間を直接ジャンプできるため、ディスク I/O 時間を大幅に節約できます。
- 二分木: 木の高さは不均一であり、自己平衡をとることができません。検索効率はデータ (木の高さ) に関係し、IO コストは高い。
- 赤黒ツリー: データ量が増えるとツリーの高さが増し、IO コストが高くなります。
#4. クラスター化インデックスと非クラスター化インデックスについて話しましょう。
- InnoDB では、データの行全体を格納するインデックス B ツリーのリーフ ノードが主キー インデックスであり、クラスター化インデックスとも呼ばれます。つまり、データ ストレージです。インデックスとインデックスが配置されています 断片に到達すると、インデックスが見つかり、データが見つかります。
- インデックス B ツリーのリーフ ノードには、主キーの値が格納されます。主キーは非主キー インデックスであり、非クラスター化インデックスおよびセカンダリ インデックスとも呼ばれます。
- 最初のインデックスは通常シーケンシャル IO で、テーブルに戻る操作はランダム IO です。テーブルに戻る必要がある回数が増えるほど、つまりランダム IO が必要な回数が増えるほど、テーブル全体のスキャンを使用する傾向が高くなります。
5. 非クラスター化インデックスは確実にテーブル クエリを返しますか?
- これには、クエリ ステートメントで必要なすべてのフィールドがインデックスにヒットするかどうかが含まれます。すべてのフィールドがインデックスにヒットする場合、クエリを実行する必要はありません。テーブルに戻ります。インデックスにはクエリが必要なすべてのフィールドの値が含まれ (カバーされ)、「カバーインデックス」と呼ばれます。
#6. MySQL の一番左のプレフィックス原則について話してください。
- 左端のプレフィックスの原則は左端優先です。ビジネス ニーズに応じて複数列のインデックスを作成する場合、where 句で最も頻繁に使用される列が左端に配置されます。側。
- MySQL は、範囲クエリ (>、<、between、like) に遭遇し、a = 1 と b = 2 などのマッチングを停止するまで、右に向かってマッチングを続けます。 c > 3 かつ d = 4 (a, b, c, d) の順にインデックスを作成した場合、d のインデックスは使用されません (a, b, d, c のインデックスを作成した場合) )、a と b の両方を使用できます。d の順序は任意に調整できます。
- = と in は、a = 1、b = 2、c = 3 のように順序が異なっていても構いません。(a, b, c) インデックスは任意の順序で作成できます。 、MySQL クエリ オプティマイザーは、インデックスで認識できる形式にクエリを最適化するのに役立ちます。
7. インデックス プッシュダウンとは何ですか?
- 左端のプレフィックスの原則が満たされている場合、左端のプレフィックスを使用してインデックス内のレコードを検索できます。
MySQL 5.6 より前では、ID から開始してテーブルを 1 つずつ返すことしかできませんでした。主キー インデックスでデータ行を検索し、フィールド値を比較します。
MySQL 5.6 で導入されたインデックス プッシュダウン最適化 (インデックス条件プッシュダウン) を使用すると、インデックス トラバーサル プロセス中に最初にインデックスに含まれるフィールドを判断し、影響を受けるフィールドを直接フィルタリングすることができます。条件を満たしていないレコードを削除して、テーブルが返される数を減らします。
#8. Innodb が主キーとして自動インクリメント ID を使用するのはなぜですか?
- テーブルで自動インクリメント主キーが使用されている場合、新しいレコードが挿入されるたびに、レコードは現在のインデックス ノードの後続の位置に追加されます。ページがいっぱいになると、自動的に新しいページが開きます。自動増加しない主キー (ID 番号や学生番号など) が使用される場合、毎回挿入される主キーの値はほぼランダムであるため、新しいレコードはそれぞれ、レコードの中央のどこかに挿入する必要があります。既存のインデックス ページが頻繁に使用されていました。移動操作やページング操作により大量の断片化が発生し、その結果インデックス構造が十分にコンパクトではなくなりました。その後、テーブルを再構築し、埋められたページを最適化するために OPTIMIZE TABLE (テーブルの最適化) を使用する必要がありました。
#9. トランザクション ACID 特性の実装原理は何ですか?
- 「アトミシティ」: アンドゥログを使用して実装されており、トランザクション実行中にエラーが発生したり、ユーザーがロールバックを実行した場合、システムはトランザクション開始のステータスをアンドゥログです。
- 「永続性」: REDO ログを使用してこれを実現します。REDO ログが永続的である限り、システムがクラッシュした場合でも、REDO ログを通じてデータを回復できます。
- 「分離」: トランザクションはロックと MVCC を通じて互いに分離されます。
- 「一貫性」: 同時状況でのロールバック、リカバリ、分離を通じて一貫性を実現します。
10. B ツリー インデックスの実装方法における MyISAM と InnoDB の違いは何ですか?
- InnoDB ストレージ エンジン: B ツリー インデックスのリーフ ノードはデータ自体を保存します;
- MyISAM ストレージ エンジン: B ツリー インデックスの葉 ノードがデータを保存する物理アドレス;
- InnoDB、そのデータ ファイル自体がインデックス ファイルです MyISAM、インデックス ファイルとデータ ファイルとの比較は分離されており、そのテーブル データ ファイル自体は B ツリーによって編成されたインデックス構造です。ツリーのノード データ フィールドには完全なデータ レコードが保存されます。このインデックスのキーはデータ テーブルの主キーです。したがって、InnoDB テーブルはデータ ファイル自体がプライマリ インデックスです。これは「クラスター化インデックス」またはクラスタリング インデックスと呼ばれ、残りのインデックスは補助インデックスとして使用されます。補助インデックスのデータ フィールドには、対応するレコードの主キーの値が格納されます。これもMyISAMとは異なります。
#11. インデックスのカテゴリは何ですか?
- リーフ ノードの内容に応じて、インデックス タイプは主キー インデックスと非主キー インデックスに分かれます。
- 主キー インデックスのリーフ ノードには、データ行全体が格納されます。 InnoDB では、主キー インデックスはクラスター化インデックスとも呼ばれます。
- 非主キー インデックスのリーフ ノードの内容は、主キーの値です。 InnoDB では、主キー以外のインデックスはセカンダリ インデックスとも呼ばれます。
#12. インデックスの失敗はどのようなシナリオで発生する可能性がありますか?
背景: B ツリーによって提供される高速測位機能は、同じレイヤー上の兄弟ノードの順序性によって実現されるため、この順序性が破壊されると、B ツリーは失敗する可能性が高くなります。この状況:- インデックスに対して左または左のファジー マッチングを使用します。つまり、%xx または %xx% のようにします。これらの方法はどちらもインデックス エラーの原因となります。その理由は、クエリ結果が「Chen Lin、Zhang Lin、Zhou Lin」などになる可能性があるため、どのインデックス値と比較を開始すればよいかわからないため、フル テーブル スキャンを通じてのみクエリを実行できるためです。
- インデックスに関数を使用する/インデックスに式計算を使用する: インデックスは、関数によって計算された値ではなく、インデックス フィールドの元の値を保存するため、索引。 。
- インデックスの暗黙的な型変換: 新しい関数を使用するのと同等 WHERE 句で
- OR: 条件を満たす限り 2 を意味しますしたがって、条件付き列が 1 つだけインデックス列である場合は意味がありません。条件付き列がインデックス列でない限り、テーブル全体のスキャンが実行されます。 ###
提案
1. データベースとテーブルに分かれていないシステムがあるのですが、動的にデータベースとテーブルに切り替わるように設計するにはどうすればよいでしょうか?
拡張の停止 (非推奨)
二重書き込み移行計画: 拡張されたテーブル構造計画を設計し、単一の移行計画を実行します。 -write migration ライブラリとサブライブラリは二重書き込みを実装しており、1週間程度観察して問題がないことを確認後、単体ライブラリのリードトラフィックをオフにし、一定期間観察後、安定状態が続いてから、ライトマイグレーションを実行します。単一ライブラリの書き込みトラフィックをオフにして、サブデータベースとテーブルにスムーズに切り替えます。
#2. 容量を動的に拡張および削減できるサブデータベースとテーブルのスキームを設計するにはどうすればよいですか?
原則1. MySQL ステートメントを実行する手順は何ですか?
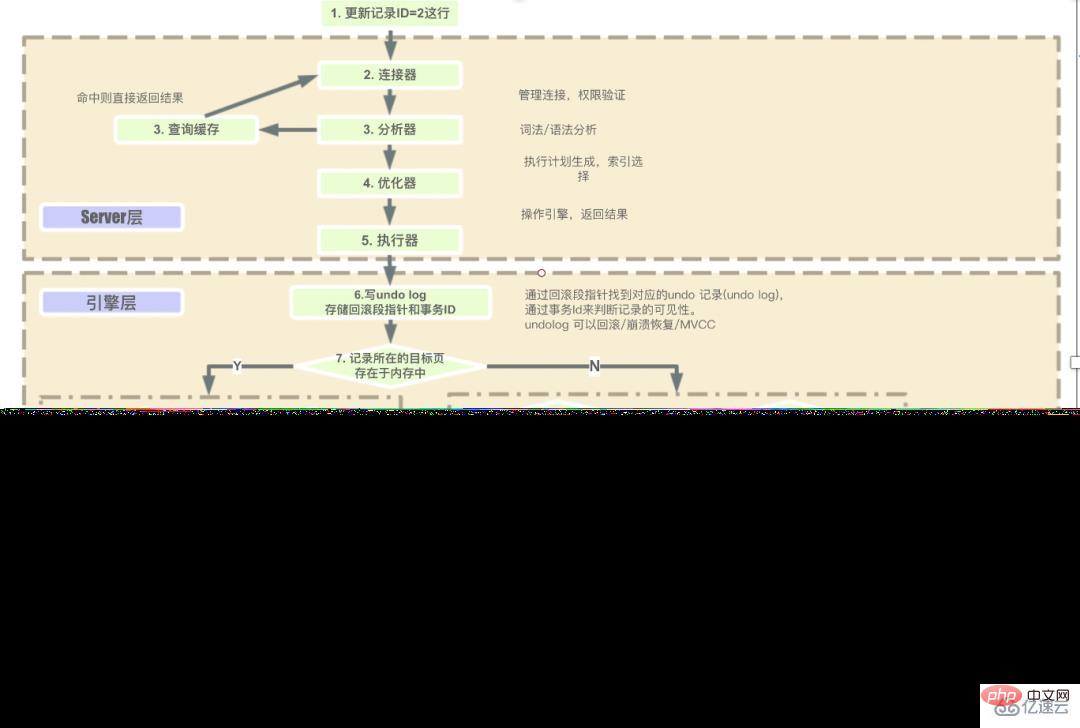
- サーバー層が SQL を順番に実行する手順は次のとおりです。
- クライアントリクエスト - > コネクタ (ユーザー ID を確認し、権限を付与) -> クエリ キャッシュ (キャッシュが存在する場合は直接返し、存在しない場合は後続の操作を実行) -> アナライザー (SQL の字句解析と構文解析を実行) -> ; オプティマイザー (主に SQL 最適化を実行するための最適な実行計画方法を選択します) -> エグゼキューター (実行中、まずユーザーに実行権限があるかどうかを確認し、その後でのみこのエンジンが提供するインターフェイスを使用できます) -> Goエンジン層に返すデータを取得します (クエリ キャッシュがオンになっている場合、クエリ結果はキャッシュされます)。
#2. ソートによる順序付けの内部原理は何ですか?
- #MySQL はソートのために各スレッドにメモリ (sort_buffer) を割り当てます。メモリ サイズは sort_buffer_size です。
- ソートするデータの量がsort_buffer_size未満の場合、ソートはメモリ内で完了します。
- 並べ替えられたデータの量が多く、メモリに格納できない場合は、ディスク上の一時ファイルを使用して並べ替えが行われます (外部並べ替えとも呼ばれます)。
- 外部ソートを使用する場合、MySQL はソートされたデータを保存するために外部ソートをいくつかの個別の一時ファイルに分割し、これらのファイルを 1 つの大きなファイルにマージします。
3. MVCC 実装原則?
- MVCC (マルチバージョン同時実行制御) は、同じデータの複数のバージョンを保持することで同時実行制御を実現する方法です。クエリを実行するときは、読み取りビューとバージョン チェーンを通じて、対応するバージョンのデータを検索します。
- 機能: 同時実行パフォーマンスを向上させます。同時実行性の高いシナリオの場合、MVCC は行レベルのロックよりも安価です。
- MVCC の実装は、テーブルの 3 つの非表示フィールドを通じて実装されるバージョン チェーンに依存します。
- #1) DB_TRX_ID: 現在のトランザクション ID。トランザクションの時系列はトランザクション ID のサイズによって判断されます。
- 2) DB_ROLL_PRT: ロールバック ポインタは、現在の行レコードの前のバージョンを指します。このポインタを通じて、データの複数のバージョンが結合され、UNDO ログ バージョン チェーンが形成されます。
- 3) DB_ROLL_ID: 主キー データ テーブルに主キーがない場合、InnoDB は自動的に主キーを生成します。
#4. 変更バッファとは何ですか?またその機能は何ですか?
5. MySQL はどのようにしてデータが失われないことを保証しますか?
- redolog と binlog が永続ディスクを保証する限り、MySQL は再起動後のデータ回復バイナリログ書き込みメカニズムにより、例外が保証されます。
- redolog は、システム例外の後に失われたデータを確実にやり直すことができるようにし、binlog はデータをアーカイブして、失われたデータを確実に回復できるようにします。
-
トランザクション実行前に redolog を書き込みます。トランザクション実行中、ログは最初に binlog キャッシュに書き込まれます。トランザクションが送信されると、binlog キャッシュは
binlog ファイルに書き込まれます。 . . ######
6. テーブルを削除した後もテーブル ファイルのサイズが変わらないのはなぜですか?
データ項目が削除されると、InnoDB はページ A にマークを付け、再利用可能としてマークされます。表全体のデータ 毛糸?その結果、すべてのデータ ページが再利用可能としてマークされます。ただし、ディスク上ではファイルは小さくなりません。
多数の追加、削除、変更が行われたテーブルには穴がある可能性があります。これらの穴もスペースを占めるため、これらの穴を削除できれば、テーブルのスペースを縮小するという目的を達成できます。
テーブルを再構築すると、この目的を達成できます。 alter table A Engine=InnoDB コマンドを使用してテーブルを再構築できます。
- 7. binlog の 3 つの形式の比較
binlog に記録される操作行の主キー ID行の binlog 形式と各行の主キー ID 各フィールドの実際の値なので、主操作データと副操作データに不整合はありません。
statement: 記録されたソース SQL ステートメント
mixed: 最初の 2 つは混合されています。混合形式のファイルが必要なのはなぜですか。一部のステートメント binlog 形式はプライマリ サーバーとセカンダリ サーバー間で不整合を引き起こす可能性があるため、行形式を使用する必要があります。ただし、行形式の欠点は、多くのスペースを必要とすることです。 MySQL は妥協をとりました。この SQL ステートメントがプライマリ サーバーとセカンダリ サーバー間で不整合を引き起こす可能性があるかどうかを MySQL 自体が判断します。可能であれば行形式を使用し、そうでない場合はステートメント形式を使用します。
- 8. MySQL ロック ルール
原則 1: ロックの基本単位はネクスト キー ロックです。・キーロックは開閉間隔です。
- #原則 2: 検索プロセス中にアクセスされたオブジェクトのみがロックされます
- 最適化 1: インデックスに対する同等のクエリ、一意の When を与えるインデックスがロックされると、ネクストキー ロックは行ロックに縮退します。
- 最適化 2: インデックス上の等価クエリの場合、右にトラバースし、最後の値が等価条件を満たさない場合、次のキー ロックはギャップ ロックに縮退します
- #バグ: 一意のインデックスに対する範囲クエリは、条件を満たさない最初の値にアクセスします。
#9. ダーティ リード、ノンリピータブル リード、ファントム リードとは何ですか?
「ダーティ リード」: ダーティ リードとは、コミットされていないデータを他のトランザクションから読み取ることを指します。コミットされていないということは、データがロールバックされる可能性があることを意味します。つまり、データがロールバックされる可能性があることを意味します。データベースに保存される、つまり存在しないデータになります。最終的には存在しない可能性のあるデータの読み取りは、ダーティ リードと呼ばれます。
- 「反復不可能な読み取り」: 反復不可能な読み取りとは、トランザクション内で、最初に読み取られたデータが、終了前の任意の時点で読み取られた同じデータのバッチと矛盾していることを意味します。取引のケース。
- 「ファントム読み取り」: ファントム読み取りは、2 つの読み取りによって取得された結果セットが異なることを意味するものではありません。ファントム読み取りの焦点は、特定の選択によって取得された結果のデータ ステータスです。その後の業務運営をサポートできなくなります。具体的には、あるレコードが存在するかどうかを選択し、存在しない場合は、レコードを挿入する準備をしますが、挿入を実行すると、すでにレコードが存在していることがわかり、挿入できません。このとき、ファントムリードが発生します。が発生します。
- 10. MySQL にはどのような種類のロックがありますか?上記のようなロックは同時実行効率の妨げになりませんか?
ロックのカテゴリに関しては、共有ロックと排他ロックがあります。
- 1) 共有ロック: 読み取りロックとも呼ばれます。ユーザーがデータを読み取りたい場合、共有ロックがデータに追加されます。複数の共有ロックは、同時 。
- ロックの粒度は特定のストレージ エンジンによって異なります。InnoDB は行レベルのロック、ページレベルのロック、およびテーブルレベルのロックを実装します。
- フレームワーク
- 1. MySQL マスター/スレーブ レプリケーションの原理は何ですか?
- 2) 排他ロック: 書き込みロックとも呼ばれます。ユーザーがデータを書き込みたいとき、データに排他ロックを追加します。追加できる排他ロックは 1 つだけです。ユーザーと他の排他ロックのみです。ロックと共有ロックは相互に排他的です。
マスターの更新イベント (更新、挿入、削除) は、bin-log に順番に書き込まれます。スレーブがマスターに接続されると、マスター マシンはスレーブの binlog dump スレッドを開き、このスレッドが bin-log ログを読み取ります。
スレーブがマスターに接続された後、スレーブ ライブラリには I/O スレッドがあり、binlog ダンプ スレッドを要求して bin-log ログを読み取ります。次に、それをスレーブ ライブラリの リレー ログ ログに書き込みます。
スレーブには SQL スレッド もあり、リレーログのログ内容の更新をリアルタイムで監視し、ファイル内の SQL ステートメントを解析して実行します。スレーブデータベース内。
2. Mysql のマスター/スレーブ レプリケーション同期方法は何ですか?
非同期レプリケーション: Mysql マスター/スレーブ同期 デフォルトは非同期レプリケーションです。つまり、上記の 3 つのステップのうち、最初のステップのみが同期的です (つまり、Mater が bin ログ ログを書き込みます)。つまり、マスター ライブラリは、binlog ログを書き込んだ後、binlog を待たずにクライアントに正常に戻ることができます。スレーブライブラリに転送されるログ。
同期レプリケーション: 同期レプリケーションの場合、マスター ホストがスレーブ ホストにイベントを送信した後、すべてのスレーブ ノード (スレーブ ノードがある場合) が送信されるまで待機がトリガーされます。複数のスレーブ) は、成功したデータ複製に関する情報をマスターに返します。
準同期レプリケーション: 半同期レプリケーションの場合、マスター ホストがスレーブ ホストにイベントを送信した後、次のいずれかが行われるまで待機がトリガーされます。スレーブ ノード (複数のスレーブがある場合) は、成功したデータ レプリケーションに関する情報をマスターに返します。
3. Mysql のマスターとスレーブの同期遅延の原因は何ですか? 最適化するにはどうすればよいですか?
マスター ノードが大規模なトランザクションを実行すると、マスター/スレーブ遅延に大きな影響を及ぼします
ネットワーク遅延、大規模なログ、多すぎるスレーブ
マスターではマルチスレッド書き込み、スレーブ ノードでは単一スレッドの同期のみ
マシンのパフォーマンススレーブ ノードが「不良マシン」を使用しているかどうかの問題。 ## 4. Mysql のマスターとスレーブの同期遅延の原因は何ですか? 最適化するにはどうすればよいですか?
-
大規模なトランザクション: 大規模なトランザクションを小さなトランザクションに分割し、バッチでデータを更新します。
スレーブの数を以下に減らします。 5 を使用して単一トランザクションのサイズを削減します
- Mysql 5.7 以降では、マルチスレッド レプリケーションと MGR レプリケーション アーキテクチャを使用できます
- ディスク、RAID カードまたはスケジューリング戦略に問題がある場合、単一の IO 遅延が非常に大きくなる可能性があります。iostat コマンドを使用して DB データ ディスクの IO 状況を確認し、さらに判断することができます
- ロックの問題については、processlist を取得し、information_schema の下にあるロックとトランザクションに関連するテーブルを確認することで確認できます。
6. bin ログ/redo ログ/undo ログとは何ですか?
-
bin ログは、Mysql データベース レベルのファイルです。Mysql データベースを変更するすべての操作が記録されます。select ステートメントと show ステートメントは記録されません。
REDO ログに記録されるのは、更新されるデータです。たとえば、データが正常に送信された場合、そのデータはすぐにはディスクに同期されません。トランザクションの耐久性を実現するために、最初に REDO ログに記録され、機会があればディスクが適切に更新されるまで待機します。
- アンドゥ ログはデータの呼び出し操作に使用され、レコードが変更される前の内容を保持します。トランザクションのロールバックはアンドゥ ログを通じて実現でき、MVCC はアンドゥ ログに基づいてデータの特定のバージョンまでトレースバックすることで実装できます。
マスターの更新イベント (更新、挿入、削除) は、bin-log に順番に書き込まれます。スレーブがマスターに接続されると、マスター マシンはスレーブの binlog dump スレッドを開き、このスレッドが bin-log ログを読み取ります。
スレーブがマスターに接続された後、スレーブ ライブラリには I/O スレッドがあり、binlog ダンプ スレッドを要求して bin-log ログを読み取ります。次に、それをスレーブ ライブラリの リレー ログ ログに書き込みます。
スレーブには SQL スレッド もあり、リレーログのログ内容の更新をリアルタイムで監視し、ファイル内の SQL ステートメントを解析して実行します。スレーブデータベース内。
非同期レプリケーション: Mysql マスター/スレーブ同期 デフォルトは非同期レプリケーションです。つまり、上記の 3 つのステップのうち、最初のステップのみが同期的です (つまり、Mater が bin ログ ログを書き込みます)。つまり、マスター ライブラリは、binlog ログを書き込んだ後、binlog を待たずにクライアントに正常に戻ることができます。スレーブライブラリに転送されるログ。
同期レプリケーション: 同期レプリケーションの場合、マスター ホストがスレーブ ホストにイベントを送信した後、すべてのスレーブ ノード (スレーブ ノードがある場合) が送信されるまで待機がトリガーされます。複数のスレーブ) は、成功したデータ複製に関する情報をマスターに返します。
準同期レプリケーション: 半同期レプリケーションの場合、マスター ホストがスレーブ ホストにイベントを送信した後、次のいずれかが行われるまで待機がトリガーされます。スレーブ ノード (複数のスレーブがある場合) は、成功したデータ レプリケーションに関する情報をマスターに返します。
マスター ノードが大規模なトランザクションを実行すると、マスター/スレーブ遅延に大きな影響を及ぼします
ネットワーク遅延、大規模なログ、多すぎるスレーブ
マスターではマルチスレッド書き込み、スレーブ ノードでは単一スレッドの同期のみ
マシンのパフォーマンススレーブ ノードが「不良マシン」を使用しているかどうかの問題。 ## 4. Mysql のマスターとスレーブの同期遅延の原因は何ですか? 最適化するにはどうすればよいですか?
6. bin ログ/redo ログ/undo ログとは何ですか?
以上がMySQL の基本的な問題は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは、Webアプリケーションを簡単に構築するためのPHPフレームワークです。次のような強力な機能を提供します。インストール:Laravel CLIを作曲家にグローバルにインストールし、プロジェクトディレクトリにアプリケーションを作成します。ルーティング:ルート/web.phpのURLとハンドラーの関係を定義します。ビュー:リソース/ビューでビューを作成して、アプリケーションのインターフェイスをレンダリングします。データベース統合:MySQLなどのデータベースとのすぐ外側の統合を提供し、移行を使用してテーブルを作成および変更します。モデルとコントローラー:モデルはデータベースエンティティを表し、コントローラーはHTTP要求を処理します。
 MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLとPHPMyAdminは、強力なデータベース管理ツールです。 1)MySQLは、データベースとテーブルを作成し、DMLおよびSQLクエリを実行するために使用されます。 2)PHPMyAdminは、データベース管理、テーブル構造管理、データ操作、ユーザー許可管理のための直感的なインターフェイスを提供します。
 MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
他のプログラミング言語と比較して、MySQLは主にデータの保存と管理に使用されますが、Python、Java、Cなどの他の言語は論理処理とアプリケーション開発に使用されます。 MySQLは、データ管理のニーズに適した高性能、スケーラビリティ、およびクロスプラットフォームサポートで知られていますが、他の言語は、データ分析、エンタープライズアプリケーション、システムプログラミングなどのそれぞれの分野で利点があります。
 データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
小さなアプリケーションを開発する際には、軽量データベース操作ライブラリをすばやく統合する必要性という厄介な問題に遭遇しました。複数のライブラリを試した後、私はそれらがあまりにも多くの機能を持っているか、あまり互換性がないかのどちらかであることがわかりました。最終的に、私は問題を完全に解決したYii2に基づいた単純化されたバージョンであるMinii/DBを見つけました。
 Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
記事の概要:この記事では、Laravelフレームワークを簡単にインストールする方法について読者をガイドするための詳細なステップバイステップの指示を提供します。 Laravelは、Webアプリケーションの開発プロセスを高速化する強力なPHPフレームワークです。このチュートリアルは、システム要件からデータベースの構成とルーティングの設定までのインストールプロセスをカバーしています。これらの手順に従うことにより、読者はLaravelプロジェクトのための強固な基盤を迅速かつ効率的に築くことができます。
 初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
MySQLの基本操作には、データベース、テーブルの作成、およびSQLを使用してデータのCRUD操作を実行することが含まれます。 1.データベースの作成:createdatabasemy_first_db; 2。テーブルの作成:createTableBooks(idintauto_incrementprimarykey、titlevarchary(100)notnull、authorvarchar(100)notnull、published_yearint); 3.データの挿入:InsertIntoBooks(タイトル、著者、公開_year)VA
 MySQLモードの問題を解決する問題:TheliamySQLModescheckerモジュールの使用経験
Apr 18, 2025 am 08:42 AM
MySQLモードの問題を解決する問題:TheliamySQLModescheckerモジュールの使用経験
Apr 18, 2025 am 08:42 AM
Theliaを使用してeコマースWebサイトを開発するとき、私はトリッキーな問題に遭遇しました:MySQLモードが適切に設定されていないため、いくつかの機能が適切に機能しません。いくつかの調査の後、TheliamysQlModescheckerというモジュールを見つけました。これは、Theliaが必要とするMySQLパターンを自動的に修正できるため、問題を完全に解決できます。
