

MySQL インデックス作成原則の分析例

1. インデックスの作成に適しています
1. フィールドの値には一意性の制限があります
Alibaba の仕様によれば、これは次のことを示していますビジネス要件があること 固有の特性を持つフィールド (結合フィールドであっても) は、一意にインデックス付けする必要があります。

たとえば、学生テーブルの学生番号は一意のフィールドです。このフィールドに一意のインデックスを作成すると、特定の学生の情報をすばやくクエリできます。名前 その場合、同じ名前が存在する可能性があり、クエリ速度が遅くなります。
2. Where クエリ条件として頻繁に使用されるフィールド
フィールドが Select ステートメントの Where 条件で頻繁に使用される場合、特にこのフィールドのインデックスを作成する必要があります。データ量が多い場合、共通インデックスを作成するとクエリ効率が大幅に向上します。
たとえば、テスト テーブルstudent_info には 100 万のデータがあります。student_id=112322 のユーザー情報がクエリされるとします。student_id フィールドにインデックスが作成されていない場合、クエリの結果は次のようになります:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
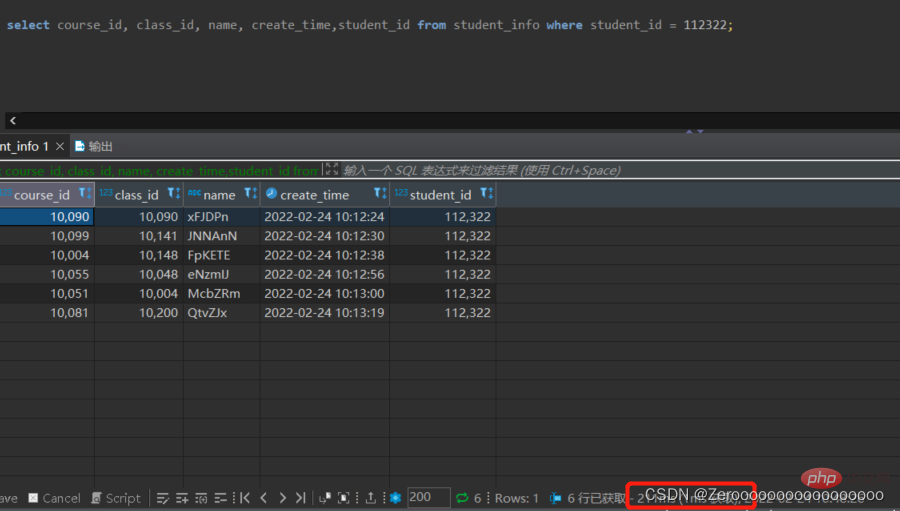
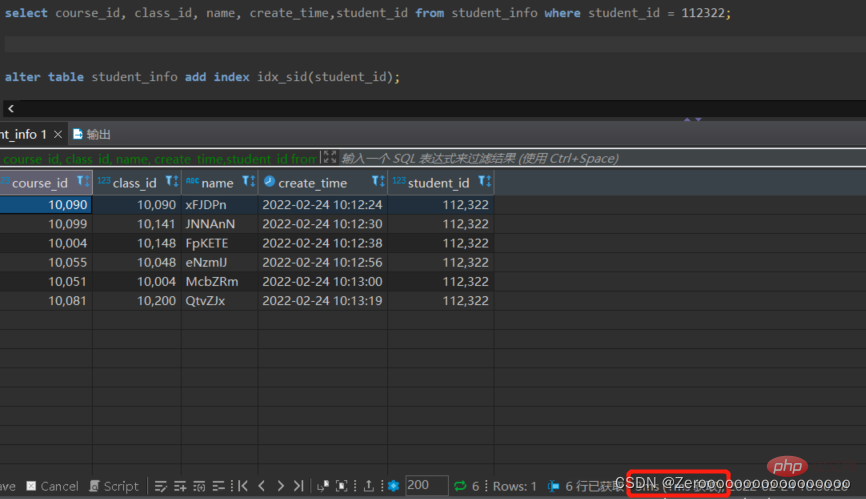
student_id のインデックスを作成した後のクエリ結果は次のとおりです:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
3. 多くの場合、グループ化と順序付けが行われます。 by columns
インデックスは、特定の条件に従ってデータを作成することです。そのため、Group by を使用してクエリ データをグループ化する場合、または Order by を使用してデータを並べ替える場合は、グループ化または並べ替えられたフィールドにインデックスを付ける必要があります。並べ替える列が複数ある場合は、これらの列に対して結合インデックスを構築できます。
たとえば、学生が選択したコースを Student_id に従ってグループ化し、異なる Student_id とコース数を表示し、100 件を表示します。 Student_id のインデックスを作成しない場合、クエリの結果は次のようになります:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
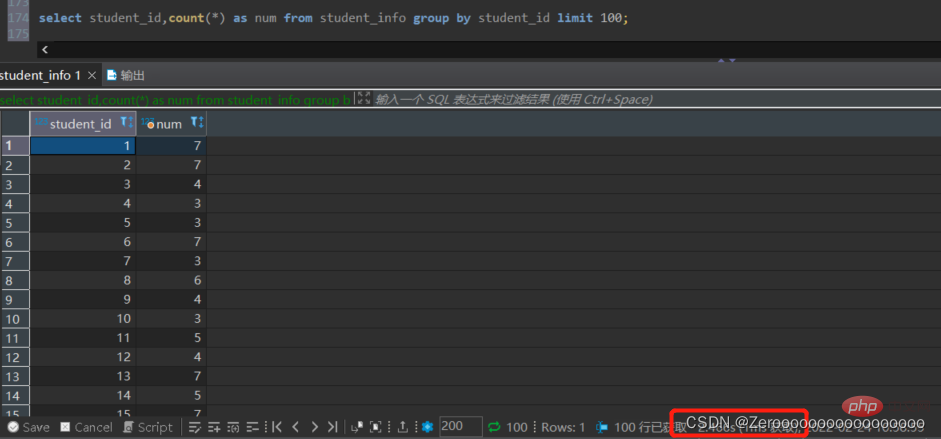
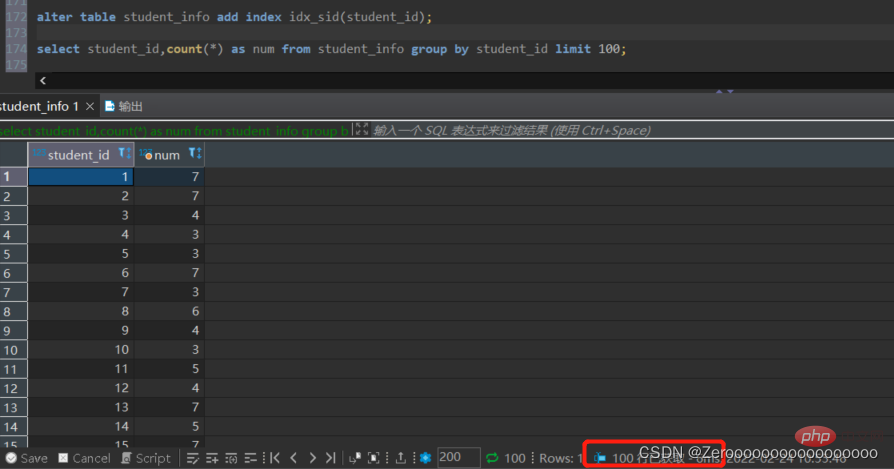
student_id のインデックスを作成した後のクエリの結果は次のようになります:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
group by と order by の両方を含むクエリ ステートメントの場合は、結合インデックスを確立し、order by フィールドの前に group by のフィールドを配置することをお勧めします。 「左端プレフィックス一致原則」を満たすため、インデックス使用率が高く、自然なクエリ効率が高くなりますが、同時に 8.0 以降のバージョンでは降順インデックスがサポートされています。順序を変更する場合は、降順インデックスを直接作成することを検討してください。これにより、クエリの効率も向上します。
4. Update および Delete の Where 条件列
Where フィールドにインデックスが作成されている場合、特定の条件に従ってデータをクエリし、Update または Delete 操作を実行します。 , 返信できるので効率が上がります。その理由は、最初に Where 条件列に基づいてこのレコードを取得し、その後更新または削除する必要があるためです。更新時に更新されるフィールドが非インデックス フィールドである場合、インデックス フィールドの更新にメンテナンスが必要ないため、効率の向上がより顕著になります。
たとえば、student_info テーブルの name フィールドが sdfasdfas123123 の場合、student_id は 110119 に変更されます。name フィールドにインデックスを作成しない場合、実行状況は次のようになります。
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
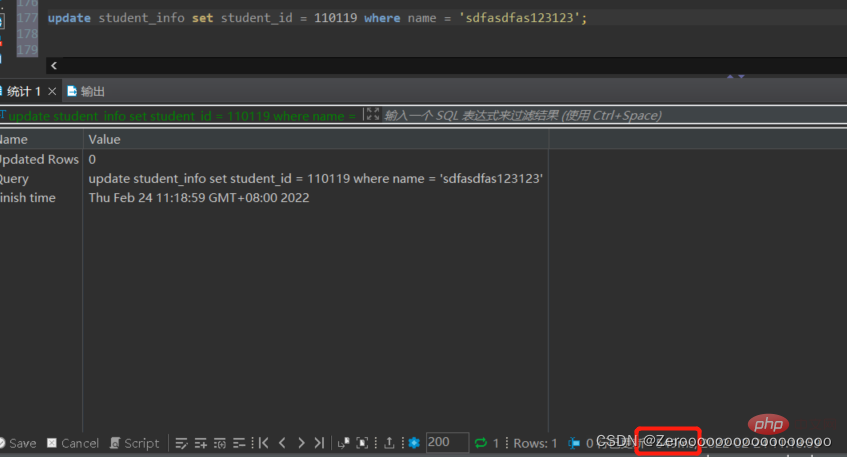
インデックスを追加した後の実行状況は次のとおりです:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
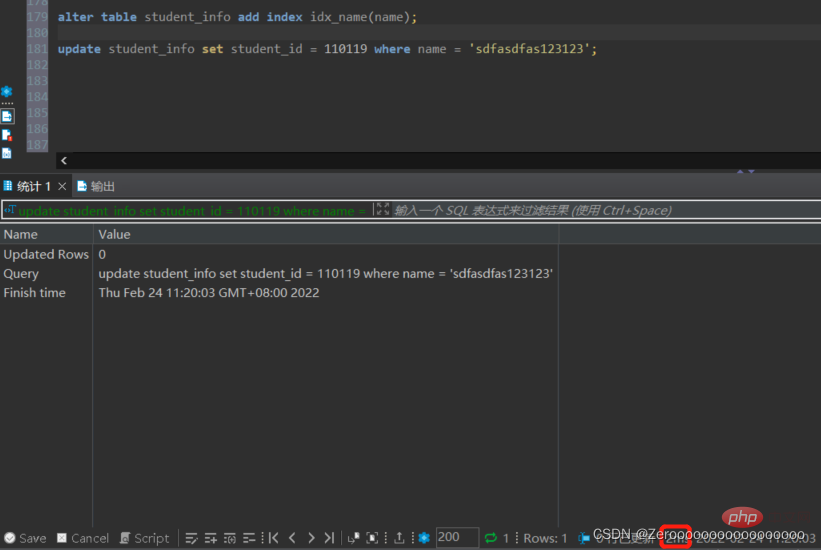
5. 個別のフィールドはインデックスを作成する必要があります
場合によっては、特定のフィールドを削除するには、が必要です。 Distinct を使用する場合、これに対するインデックスを作成すると、クエリの効率も向上します。
たとえば、コース スケジュール内のさまざまな Student_id をクエリします。student_id のインデックスが作成されていない場合、実行状況は次のようになります:
select distinct(student_id) from student_id;#花费2ms
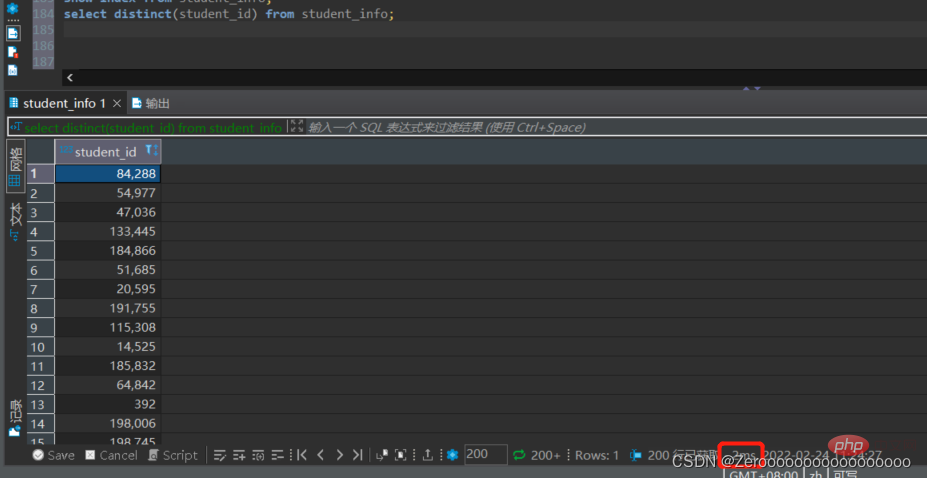
Afterインデックス作成、実行状況は以下の通り:
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms
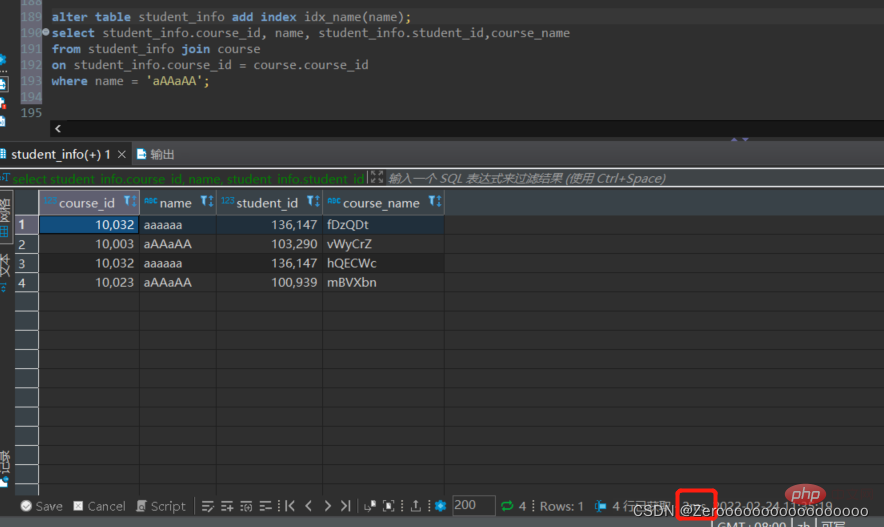
6. 複数テーブルの結合接続オペレーションを作成する場合、インデックス作成時の注意点
まず、インデックスの量接続されたテーブル内のデータは 3 を超えてはなりません。これは、テーブルを追加するたびにネストされたループが追加され、その桁数が急速に増加し、クエリの効率に重大な影響を与えるためです。次に、Where 条件のインデックスを作成します。Where はデータ条件のフィルターなので、データ量が非常に多い場合、フィルターするための Where 条件がないと非常に不安になります。最後に、接続されたデータのインデックスを作成します。複数のテーブルの型は一貫している必要があります。

たとえば、student_id のみのインデックスを作成した場合、クエリの結果は次のようになります。
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
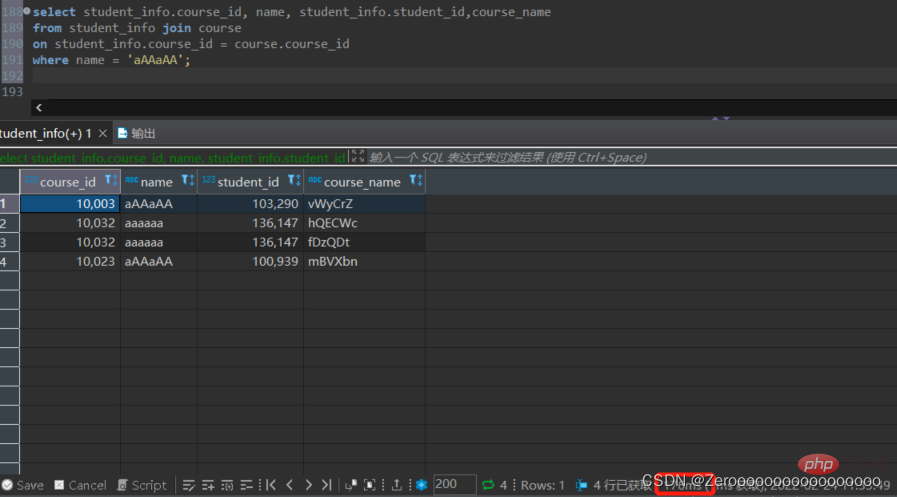
名前フィールドのインデックスを作成した後のクエリ結果は次のようになります:
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9. 冗長または重複したインデックスを定義しないでください
以上がMySQL インデックス作成原則の分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7496
7496
 15
1377
52
77
11
19
52
15
1377
52
77
11
19
52

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
