

MySQL の高パフォーマンスのインデックスを作成する方法

1 インデックスの基本
1.1 インデックス関数
MySQL では、データを検索するときに、まずインデックス内の対応する値を見つけます。次に、一致するインデックス レコードに従って、対応するデータ行を検索します。次のクエリ ステートメントを実行する場合:
SELECT * FROM USER WHERE uid = 5;
uid に構築されたインデックスがある場合、MySQL は最初にそのインデックスを使用して行を検索します。 uid 5 の場合、つまり、MySQL は最初にインデックスの値で検索し、次にその値を含むすべての行を返します。
1.2 MySQL インデックスで一般的に使用されるデータ構造
MySQL インデックスは、サーバーではなくストレージ エンジン レベルで実装されます。したがって、統一されたインデックス標準は存在せず、ストレージ エンジンが異なればインデックスの動作も異なります。
1.2.1 B ツリー
ほとんどの MySQL エンジンは、この種のインデックス B ツリーをサポートしています。複数のストレージ エンジンが同じタイプのインデックスをサポートしている場合でも、基礎となる実装は異なる場合があります。たとえば、InnoDB は B Tree を使用します。
ストレージ エンジンは、さまざまな方法で B ツリーを実装し、さまざまなパフォーマンスと利点を備えています。たとえば、MyISAM はプレフィックス圧縮テクノロジを使用してインデックスを小さくしますが、InnoDB は元のデータ形式に従ってデータを保存します。MyISAM インデックスはデータの物理的な場所によってインデックス付けされた行を参照しますが、InnoDB はインデックス付けされた行をデータの物理的な場所に従って適用します。成分。
すべての B ツリー値は順番に格納され、各リーフ ページからルートまでの距離は同じです。次の図は、InnoDB インデックスの仕組みを大まかに示していますが、MyISAM で使用される構造は異なります。ただし、基本的な実装は似ています。
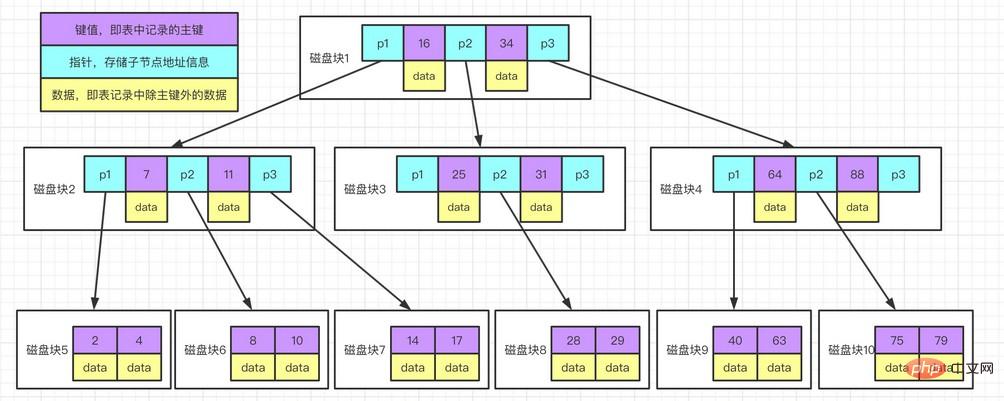
図の説明例:
各ノードは 1 つのディスク ブロックを占有し、1 つのノードには 2 つの昇順ソート キーと 3 つのポインティング サブツリーがあります。ルート ノード。子ノードが配置されているディスク ブロックのアドレスが保存されます。 2つのキーワードで分割された3つの範囲フィールドは、3つのポインタが指すサブツリーのデータの範囲フィールドに対応する。ルートノードを例にとると、キーワードは 16 と 34、P1 ポインタが指すサブツリーのデータ範囲は 16 未満、P2 ポインタが指すサブツリーのデータ範囲は 16 ~ 34、データはP3 ポインタが指すサブツリーの範囲が 34 を超えています。キーワード検索プロセス:
ルート ノードに基づいてディスク ブロック 1 を検索し、メモリに読み込みます。 [ディスク I/O 操作 1 回目]
比較キーワード 28 区間 (16,34) で、ディスク ブロック 1 のポインタ P2 を見つけます。
P2 ポインタに基づいてディスク ブロック 3 を見つけ、それをメモリに読み取ります。 [ディスク I/O 操作 2 回目]
比較キーワード 28 区間 (25,31) で、ディスク ブロック 3 のポインタ P2 を見つけます。
P2 ポインタに基づいてディスク ブロック 8 を見つけ、それをメモリに読み取ります。 [ディスク I/O 操作 3 回目]
ディスク ブロック 8 のキーワード リストにキーワード 28 が見つかりました。
#欠点:
- 各ノードにはキーがあり、データも含まれており、各ページには記憶域があります。データが比較的大きい場合、各ノードに格納されるキーの数は少なくなり、格納されるデータの量が多い場合、深さは大きくなり、増加します。クエリ中のディスク IO 回数は、クエリのパフォーマンスに影響します。
- 1.2.2 B ツリー インデックスB ツリーは、B ツリーのバリアントです。 B ツリーとの違い: B ツリーはリーフ ノードにデータのみを格納し、非リーフ ノードはキー値とポインタのみを格納します。
1.2.3 ハッシュ インデックス
ハッシュ インデックスはハッシュ テーブルに基づいており、インデックスのすべての列と正確に一致するクエリのみが有効です。データの各行に対して、ストレージ エンジンはすべてのインデックス列のハッシュ コードを計算します。ハッシュ コードはより小さい値であり、キー値が異なる行に対して計算されるハッシュ コードも異なります。ハッシュ インデックスには、インデックス内のすべてのハッシュ コードと、ハッシュ テーブル内の各データ行へのポインタが格納されます。 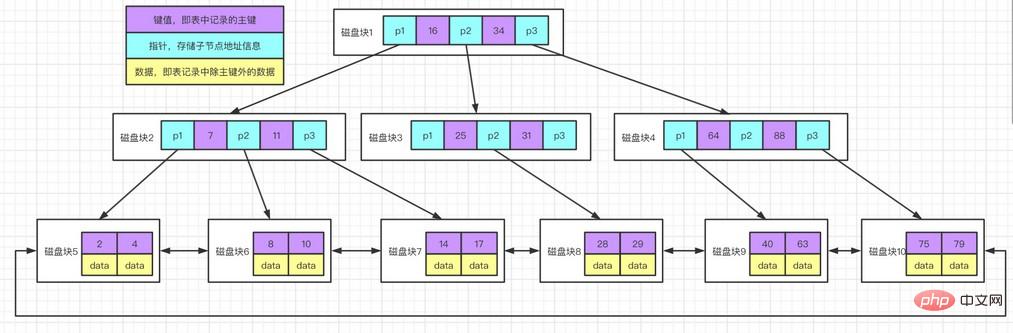
: インデックス自体は対応するハッシュ値を格納するだけでよいため、インデックスの構造は非常にコンパクトであり、ハッシュ検索を非常に高速化します。
インデックス自体は対応するハッシュ値を格納するだけでよいため、インデックスの構造は非常にコンパクトであり、ハッシュ検索を非常に高速化します。
欠点:
ハッシュストレージを使用する場合、すべてのデータファイルをメモリに追加する必要があるため、より多くのメモリスペースを消費します;
- ハッシュ インデックス データは順序どおりに格納されないため、並べ替えには使用できません;
すべてのクエリが同等のクエリである場合、ハッシュ化は確かに非常に高速ですが、企業環境や実際の作業環境では、同等のクエリよりも多くのデータが範囲内で検索されるため、ハッシュ化はあまり適していません。
ハッシュの競合が多い場合、インデックスの保守作業のコストも非常に高くなりますが、これは後の段階で赤黒ツリーを追加することで解決されるハッシュの競合の問題でもあります。 HashMap の;
2 高パフォーマンスのインデックス戦略
2.1 クラスター化インデックスと非クラスター化インデックス
クラスター化インデックス
は別個のインデックス タイプではなく、データ ストレージ方式であり、InnoDB ストレージ エンジンでは、クラスター化インデックスは実際にはキー値とデータ行を同じ構造に格納します。テーブルにクラスター化インデックスがある場合、そのデータ行は実際にはインデックスのリーフ ページに格納されます。データ行を異なる場所に同時に格納できないため、テーブル内に存在できるクラスター化インデックスは 1 つだけです (インデックス カバレッジにより、複数のクラスター化インデックスの状況をシミュレートできます)。
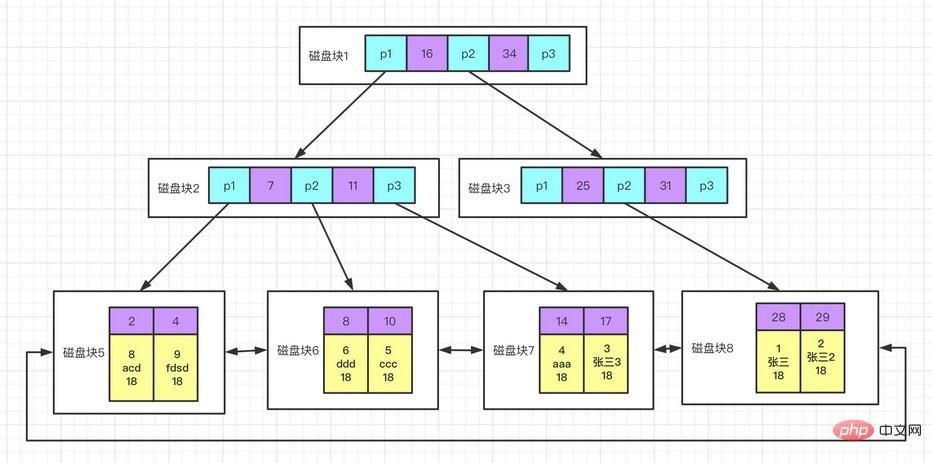
クラスター化インデックスの利点:
関連データをまとめて保存できる; インデックスとデータが同じツリーに保存されるため、データ アクセスが高速になる; を使用したクエリカバー インデックス スキャンでは、ページ ノードの主キー値を直接使用できます。
欠点:
クラスタ化されたデータにより、IO 集約型アプリケーションのパフォーマンスが最大化されます。データがすべてメモリ内にある場合、クラスター化インデックスには利点がありません。挿入速度は挿入順序に大きく依存し、主キーの順序で挿入するのが最も速い方法です。更新された各行は強制的に移動されるため、クラスター化インデックス列の更新は非常にコストがかかります。新しい場所、クラスター化インデックスに基づくテーブルは、新しい行が挿入されるとき、または主キーが更新されて行を移動する必要があるときにページ分割が発生する可能性があります。クラスター化インデックスにより、テーブル全体のスキャンが遅くなる可能性があります (特に行の比較がスパース)。ページ分割によりデータ ストレージが不連続な場合;
非クラスター化インデックス
データ ファイルとインデックス ファイルは別々に保存されます
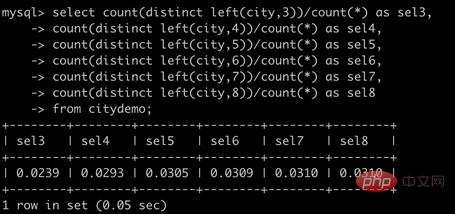
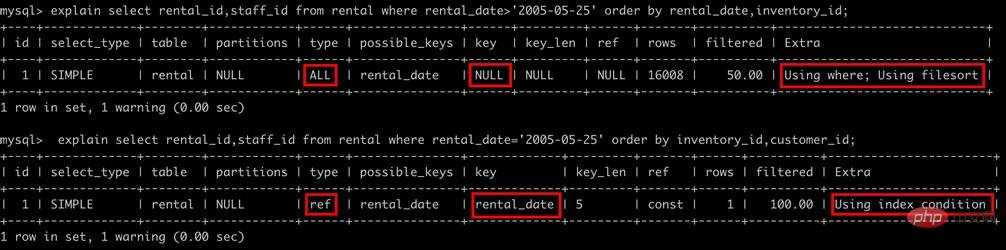
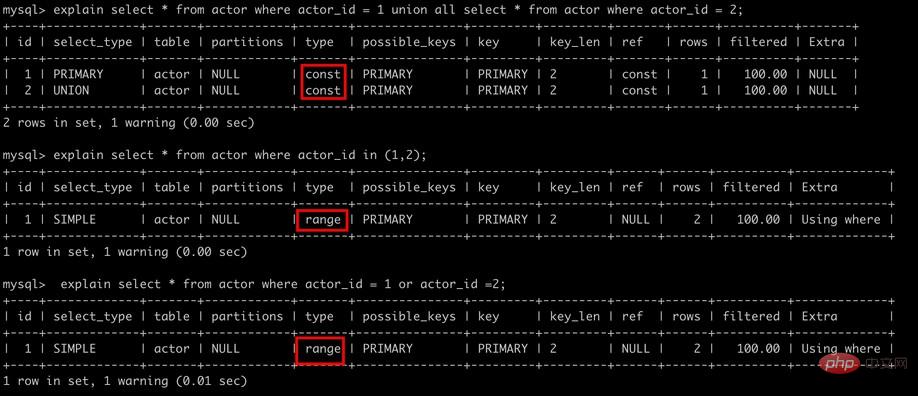
2.2 プレフィックス インデックス
場合によっては非常に長い文字列のインデックスを作成する必要があるため、インデックスが大きくなり遅くなります。通常、文字列の一部を列の先頭に使用すると、インデックスのスペースが大幅に節約され、インデックスの効率が向上しますが、インデックスの選択性が低下します。インデックス選択性とは、データ テーブル レコードの総数に対する一意のインデックス値 (カーディナリティとも呼ばれます) の比率を指し、範囲は 1/#T から 1 です。インデックスの選択性が高いほど、MySQL は検索時により多くの行を除外できるため、クエリ効率も高くなります。
一般に、特定の列プレフィックスの選択性はクエリのパフォーマンスを満たすのに十分な高さがありますが、BLOB、TEXT、および VARCHAR 型の列については、MySQL ではインデックス作成が許可されていないため、プレフィックス インデックスを使用する必要があります。カラムの全長 この方法のコツは、高い選択性を確保するのに十分な長さのプレフィックスを選択することですが、長すぎないことです。
例
テーブル構造とデータは、MySQL 公式 Web サイトまたは GitHub からダウンロードします。
city テーブルの列
| フィールド名 | 意味 |
|---|---|
| city_id | 都市主キー ID |
| city | 都市名 |
| 国 ID | |
| 作成時間または最終更新時間 |








| 参数 | 说明 |
|---|---|
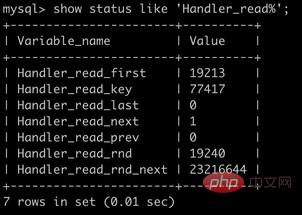
| Handler_read_first | 读取索引第一个条目的次数 |
| Handler_read_key | 通过index获取数据的次数 |
| Handler_read_last | 读取索引最后一个条目的次数 |
| Handler_read_next | 通过索引读取下一条数据的次数 |
| Handler_read_prev | 通过索引读取上一条数据的次数 |
| Handler_read_rnd | 从固定位置读取数据的次数 |
| Handler_read_rnd_next | 从数据节点读取下一条数据的次数 |
以上がMySQL の高パフォーマンスのインデックスを作成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7653
7653
 15
1393
52
91
11
37
110
15
1393
52
91
11
37
110

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
