

スタンフォード、メタ AI 研究: AGI への道では、データのプルーニングが私たちが思っているよりも重要です

視覚、言語、音声などの機械学習の多くの分野では、ニューラル スケーリングでは、一般にトレーニング データ、モデル サイズ、計算数が増加するにつれてテスト エラーが減少すると述べています。この比例的な改善により、ディープ ラーニングは大幅なパフォーマンス向上を実現しました。ただし、スケーリングだけでこれらの改善を達成するには、計算とエネルギーの点でかなりのコストがかかります。
この比例スケーリングは持続不可能です。たとえば、誤差を 3% から 2% に減らすために必要なデータ、計算、またはエネルギーの量は指数関数的に増加します。以前の研究では、大規模な Transformer を使用した言語モデリングでクロス エントロピー損失を 3.4 から 2.8 に削減するには、10 倍のトレーニング データが必要であることが示されています。さらに、大規模なビジュアル トランスフォーマーの場合、追加の 20 億の事前トレーニング データ ポイント (10 億から開始) は、ImageNet で数パーセントの精度向上にとどまりました。
これらの結果はすべて、ディープラーニングにおけるデータの性質を明らかにすると同時に、巨大なデータセットを収集する行為が非効率的である可能性があることを示しています。ここでの議論は、もっと改善できるかどうかということです。たとえば、トレーニング サンプルを選択するための適切な戦略を使用して、指数関数的なスケーリングを達成できるでしょうか?
最近の記事で、研究者らは、慎重に選択したトレーニング サンプルをいくつか追加するだけで、10 倍以上のランダム サンプルを収集しなくても誤差を 3% から 2% に減らすことができることを発見しました。一言で言えば、「売ればいいというものではない」ということです。


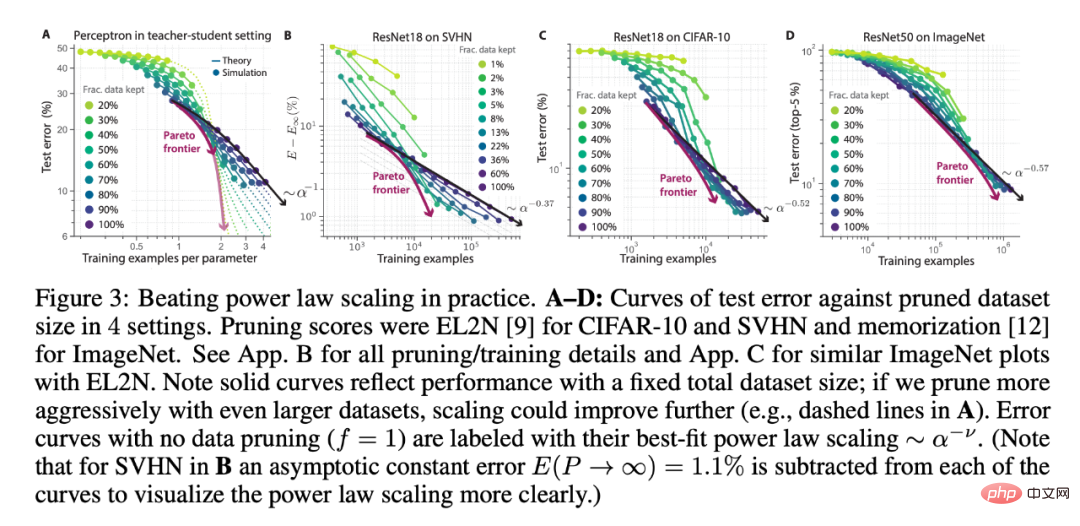
さらに、研究者らは、データの枝刈りによって転移学習のパフォーマンスが向上することを発見しました。彼らはまず、ImageNet21K で事前トレーニングされた ViT を分析し、次に CIFAR-10 のプルーニングされたさまざまなサブセットで微調整しました。興味深いことに、事前トレーニング済みモデルでは、より積極的なデータ プルーニングが可能であり、CIFAR-10 微調整のわずか 10% のみが、すべての CIFAR-10 微調整によって達成されるパフォーマンスと一致またはそれを超えていました (図 4A)。さらに、図 4A は、微調整された設定におけるべき乗則スケーリングの破壊のサンプルを示しています。

ImageNet1K のプルーニングされたさまざまなサブセット (図 3D を参照) で ResNet50 を事前トレーニングすることで、研究者らは事前トレーニングされたデータのプルーニングの有効性を調べ、その後 CIFAR を使用しました。 -10 で微調整します。図 4B に示すように、ImageNet の少なくとも 50% での事前トレーニングは、すべての ImageNet での事前トレーニングで達成される CIFAR-10 のパフォーマンスと同等またはそれを超えることができます。
したがって、上流タスクの事前トレーニング データをプルーニングしても、さまざまな下流タスクで高いパフォーマンスを維持できます。全体として、これらの結果は、事前トレーニングおよび微調整段階での転移学習における枝刈りの可能性を示しています。
ImageNet での教師付き枝刈りメトリクスのベンチマーク実施
研究者らは、データ枝刈り実験のほとんどが小規模のデータセット (つまり、 MNIST と CIFAR の亜種) 上で行われていることに気づきました。したがって、ImageNet に対して提案されているいくつかの枝刈りメトリクスが、より小さなデータセットで設計されたベースラインと比較されることはほとんどありません。
したがって、ほとんどのプルーニング方法が ImageNet にどのように対応するか、またどの方法が最適であるかは不明です。パフォーマンスに対する枝刈りメトリクスの品質の理論的な影響を調査するために、ImageNet 上の 8 つの異なる教師あり枝刈りメトリクスの体系的な評価を実行することで、この知識のギャップを埋めることにしました。

研究者らは、メトリクス間のパフォーマンスに大きな違いがあることを観察しました。図 5BC は、各メトリクスで最も困難なサンプルの一部がトレーニング セットに保持された場合のテスト パフォーマンスを示しています。多くのメトリクスは小規模なデータセットで成功を収めますが、大幅に小さなトレーニング サブセット (Imagenet の 80% など) を選択した場合、完全なデータセットでトレーニングした場合でも同等のパフォーマンスを達成できるメトリクスはわずかです。
それにもかかわらず、ほとんどの対策は依然としてランダム枝刈りよりも優れたパフォーマンスを示します (図 5C)。研究者は、すべての枝刈りメトリクスがクラスの不均衡を増幅し、パフォーマンスの低下を引き起こすことを発見しました。この問題に対処するために、著者らはすべての ImageNet 実験で単純な 50% のクラス バランス レートを使用しました。
プロトタイプ メトリクスによる自己監視型データ プルーニング
図 5 に示すように、多くのデータ プルーニング メトリクスは ImageNet に合わせて適切に拡張できず、その一部は確かに計算負荷が高くなります。さらに、これらのメトリクスはすべてアノテーションを必要とするため、ラベルのない大規模なデータセットで大規模なベース モデルをトレーニングするためのデータ プルーニング機能が制限されます。したがって、シンプルでスケーラブルな自己監視型枝刈りメトリクスが明らかに必要です。

メトリックによって検出されたクラスターが ImageNet クラスと一致しているかどうかを評価するために、図 6A でそれらの重複を比較しました。データの 70% 以上を保持する場合、自己監視型と監視型の測定のパフォーマンスは同等であり、自己監視型枝刈りの可能性が示されています。
研究の詳細については、元の論文を参照してください。
以上がスタンフォード、メタ AI 研究: AGI への道では、データのプルーニングが私たちが思っているよりも重要ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1668
1668
 14
1428
52
1329
25
1273
29
1256
24
14
1428
52
1329
25
1273
29
1256
24

 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
 CでDMA操作を理解する方法は?
Apr 28, 2025 pm 10:09 PM
CでDMA操作を理解する方法は?
Apr 28, 2025 pm 10:09 PM
CのDMAとは、直接メモリアクセステクノロジーであるDirectMemoryAccessを指し、ハードウェアデバイスがCPU介入なしでメモリに直接データを送信できるようにします。 1)DMA操作は、ハードウェアデバイスとドライバーに大きく依存しており、実装方法はシステムごとに異なります。 2)メモリへの直接アクセスは、セキュリティリスクをもたらす可能性があり、コードの正確性とセキュリティを確保する必要があります。 3)DMAはパフォーマンスを改善できますが、不適切な使用はシステムのパフォーマンスの低下につながる可能性があります。実践と学習を通じて、DMAを使用するスキルを習得し、高速データ送信やリアルタイム信号処理などのシナリオでその効果を最大化できます。
 Cのリアルタイムオペレーティングシステムプログラミングとは何ですか?
Apr 28, 2025 pm 10:15 PM
Cのリアルタイムオペレーティングシステムプログラミングとは何ですか?
Apr 28, 2025 pm 10:15 PM
Cは、リアルタイムオペレーティングシステム(RTOS)プログラミングでうまく機能し、効率的な実行効率と正確な時間管理を提供します。 1)Cハードウェアリソースの直接的な動作と効率的なメモリ管理を通じて、RTOのニーズを満たします。 2)オブジェクト指向の機能を使用して、Cは柔軟なタスクスケジューリングシステムを設計できます。 3)Cは効率的な割り込み処理をサポートしますが、リアルタイムを確保するには、動的メモリの割り当てと例外処理を避ける必要があります。 4)テンプレートプログラミングとインライン関数は、パフォーマンスの最適化に役立ちます。 5)実際のアプリケーションでは、Cを使用して効率的なロギングシステムを実装できます。
 フィールドをMySQLテーブルに追加および削除する手順
Apr 29, 2025 pm 04:15 PM
フィールドをMySQLテーブルに追加および削除する手順
Apr 29, 2025 pm 04:15 PM
MySQLでは、AlterTabletable_nameaddcolumnnew_columnvarchar(255)afterexisting_columnを使用してフィールドを追加し、andtabletable_namedopcolumncolumn_to_dropを使用してフィールドを削除します。フィールドを追加するときは、クエリのパフォーマンスとデータ構造を最適化する場所を指定する必要があります。フィールドを削除する前に、操作が不可逆的であることを確認する必要があります。オンラインDDL、バックアップデータ、テスト環境、および低負荷期間を使用したテーブル構造の変更は、パフォーマンスの最適化とベストプラクティスです。
 Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスの測定は、標準ライブラリのタイミングツール、パフォーマンス分析ツール、およびカスタムタイマーを使用できます。 1.ライブラリを使用して、実行時間を測定します。 2。パフォーマンス分析にはGPROFを使用します。手順には、コンピレーション中に-pgオプションを追加し、プログラムを実行してGmon.outファイルを生成し、パフォーマンスレポートの生成が含まれます。 3. ValgrindのCallGrindモジュールを使用して、より詳細な分析を実行します。手順には、プログラムを実行してCallGrind.outファイルを生成し、Kcachegrindを使用して結果を表示することが含まれます。 4.カスタムタイマーは、特定のコードセグメントの実行時間を柔軟に測定できます。これらの方法は、スレッドのパフォーマンスを完全に理解し、コードを最適化するのに役立ちます。
 トップ10のデジタル通貨取引プラットフォーム:トップ10の安全で信頼できるデジタル通貨交換
Apr 30, 2025 pm 04:30 PM
トップ10のデジタル通貨取引プラットフォーム:トップ10の安全で信頼できるデジタル通貨交換
Apr 30, 2025 pm 04:30 PM
上位10のデジタル仮想通貨取引プラットフォームは次のとおりです。1。Binance、2。Okx、3。Coinbase、4。Kraken、5。HuobiGlobal、6。Bitfinex、7。Kucoin、8。Gemini、9。Bitstamp、10。Bittrex。これらのプラットフォームはすべて、さまざまなユーザーニーズに適した高度なセキュリティとさまざまな取引オプションを提供します。
 定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
交換に組み込まれた量子化ツールには、1。Binance:Binance先物の定量的モジュール、低い取り扱い手数料を提供し、AIアシストトランザクションをサポートします。 2。OKX(OUYI):マルチアカウント管理とインテリジェントな注文ルーティングをサポートし、制度レベルのリスク制御を提供します。独立した定量的戦略プラットフォームには、3。3Commas:ドラッグアンドドロップ戦略ジェネレーター、マルチプラットフォームヘッジアービトラージに適しています。 4。Quadency:カスタマイズされたリスクしきい値をサポートするプロフェッショナルレベルのアルゴリズム戦略ライブラリ。 5。Pionex:組み込み16のプリセット戦略、低い取引手数料。垂直ドメインツールには、6。cryptohopper:クラウドベースの定量的プラットフォーム、150の技術指標をサポートします。 7。BITSGAP:
 DeepSeekの公式Webサイトは、マウススクロールイベントの浸透の影響をどのように達成していますか?
Apr 30, 2025 pm 03:21 PM
DeepSeekの公式Webサイトは、マウススクロールイベントの浸透の影響をどのように達成していますか?
Apr 30, 2025 pm 03:21 PM
マウススクロールイベントの浸透の効果を実現する方法は? Webを閲覧すると、いくつかの特別なインタラクションデザインに遭遇することがよくあります。たとえば、DeepSeekの公式ウェブサイトでは、...
