

コストは100ドル未満です!カリフォルニア大学バークレー校、ChatGPT のようなモデル「Koala」を再開: 大量のデータは役に立たず、高品質が重要

Meta が LLaMA を公開して以来、学術界ではさまざまな ChatGPT モデルが誕生し、リリースされ始めています。 まず、スタンフォード大学が 70 億パラメータの Alpaca を提案し、次に UC バークレーが CMU、スタンフォード大学、UCSD、MBZUAI と協力して 130 億パラメータの Vicuna をリリースしました。これは、90% 以上のケースで ChatGPT や Bard に匹敵する機能を実現しました。 . .最近、バークレーは新しいモデル "Koala" をリリースしました。これまで OpenAI の GPT データを使用して命令の微調整を行っていたのと比較して、Koala は異なります。高品質のデータを使用します。 トレーニング用に ネットワークから取得しました。

# ブログリンク: https://bair.berkeley.edu/blog/2023 /04/03/koala/Data前処理コード: https://github.com/young-geng/koala_data_pipeline 評価テストセット: https://github.com/arnav-gudibande/koala-test-set モデルのダウンロード: https://drive.google.com/ drive/folders/10f7wrlAFoPIy-TECHsx9DKIvbQYunCfl
公開されたブログ投稿で、研究者らはモデルのデータセット管理とトレーニングのプロセス、およびモデルを ChatGPT と比較したユーザー調査の結果について説明しました。スタンフォード大学のアルパカモデルが紹介されています。結果は、Koala がさまざまなユーザーのクエリに効果的に回答でき、多くの場合 Alpaca よりも人気のある回答を生成し、少なくとも半分の時間は ChatGPT と同じくらい効果的であることを示しています。研究者らは、この実験の結果によって、大規模なクローズドソース モデルと小規模な公開モデルの相対的なパフォーマンスに関する議論がさらに進むことを期待しています。特に、ローカルで実行できる小規模なモデルの場合、トレーニング データが注意深く収集されていれば、大型モデルのパフォーマンスを実現できます。
 これは、コミュニティが高品質のデータ セットのキュレーションにさらに多くの労力を投資する必要があることを意味する可能性があり、これは単に既存のシステムの規模を拡大するよりも役立つ可能性があります。 、より実用的でより機能的なモデル。 Koala は単なる研究プロトタイプにすぎず、研究者らはこのモデルのリリースが貴重なコミュニティ リソースを提供できることを望んでいますが、コンテンツのセキュリティと信頼性の点で依然として重大な欠点があり、研究分野以外では使用すべきではないことを強調しておく必要があります。使用。
これは、コミュニティが高品質のデータ セットのキュレーションにさらに多くの労力を投資する必要があることを意味する可能性があり、これは単に既存のシステムの規模を拡大するよりも役立つ可能性があります。 、より実用的でより機能的なモデル。 Koala は単なる研究プロトタイプにすぎず、研究者らはこのモデルのリリースが貴重なコミュニティ リソースを提供できることを望んでいますが、コンテンツのセキュリティと信頼性の点で依然として重大な欠点があり、研究分野以外では使用すべきではないことを強調しておく必要があります。使用。 Koala システムの概要
大規模な言語モデルのリリース後、仮想アシスタントとチャットボットはますます強力になり、チャットだけでなく、コードを書いたり、詩を書いたり、全能と呼ばれる。しかし、最も強力な言語モデルは、通常、モデルの学習に膨大なコンピューティング リソースを必要とし、大規模な専用データセットも必要となるため、一般の人が自力でモデルを学習させることは基本的に不可能です。言い換えれば、言語モデルは将来、少数の強力な組織によって管理されることになり、ユーザーや研究者はモデルを操作するために料金を支払うことになり、モデルの内部に直接アクセスして変更や改善を行うことはできなくなります。一方、ここ数か月で、一部の組織は、Meta の LLaMA など、比較的強力な無料または部分的にオープン ソース モデルをリリースしました。これらのモデルの機能は、クローズド モデル (ChatGPT など) の機能と比較することはできませんが、その機能はコミュニティの協力により急速に改善されています。
将来的には、少数のクローズド ソース コード モデルを中心とした統合がさらに進むのでしょうか?それとも、より小規模なモデル アーキテクチャを使用した、よりオープンなモデルでしょうか?同じアーキテクチャを持つモデルのパフォーマンスは、より大規模なクローズドソース モデルのパフォーマンスに近づくことができますか?
オープン モデルがクローズド ソース モデルの規模に匹敵する可能性は低いですが、慎重に選択されたトレーニング データを使用すると、微調整せずに ChatGPT のパフォーマンスに近づける可能性があります。実際、スタンフォード大学が公開した Alpaca モデルの実験結果と、OpenAI の GPT モデルに基づく LLaMA データの微調整により、正しいデータによりスケールが大幅に向上することが示されました。小規模なオープンソース モデルは、バークレーの研究者がコアラ モデルを開発してリリースするという当初の目的でもありましたが、この議論の結果のもう 1 つの実験的証拠を提供します。
Koala は、
インターネットから取得した無料のインタラクション データ を、次のような高性能クローズドソース モデルとの インタラクションを含むデータに特に注意を払って微調整します。 ChatGPT。
研究者らは、Web および公開データセットから抽出された会話データに基づいてベース LLaMA モデルを微調整しました。これには、他の大規模な言語モデルからのユーザー クエリや質問に対する質の高い応答が含まれます。データセットと人間のフィードバックデータセットによって訓練された Koala-13B モデルは、既存のモデルとほぼ同じパフォーマンスを示します。調査結果は、高品質のデータセットから学習することで小規模モデルの欠点の一部を軽減でき、将来的には大規模なクローズドソース モデルに匹敵する可能性さえあることを示唆しています。つまり、コミュニティは投資する必要があります。高品質のデータセットを厳選することにさらに努力することで、既存のモデルのサイズを単純に拡大するよりも、より安全で実用的で、より機能的なモデルを構築することができます。
研究者にコアラ モデルの系統的なデモンストレーションへの参加を奨励することで、研究者は将来モデルの評価に役立つ予期せぬ特徴や欠陥を発見したいと考えています。
データセットとトレーニング
会話モデルを構築する際の大きな障害は、ChatGPT、Bard、Bing Chat、Claude を含むすべてのチャット モデルのトレーニング データの管理です。すべて専用のデータを使用します。多数の手動アノテーションで構築されたデータ セット。Koala を構築するために、研究者らは Web および公開データセットから会話データを収集してトレーニング セットを編成しました。その一部には、ユーザーがオンラインに投稿した ChatGPT などの大規模な言語モデルが含まれています。対話。
研究者らは、データ量を最大化するためにできるだけ多くの Web データをクロールすることを追求するのではなく、公開データセットを使用して質問や人間のフィードバックに答えることで、小規模で高品質のデータセットを収集することに重点を置きました。肯定的と否定的の両方で評価されます)、既存の言語モデルとの対話。
ChatGPT の抽出データ
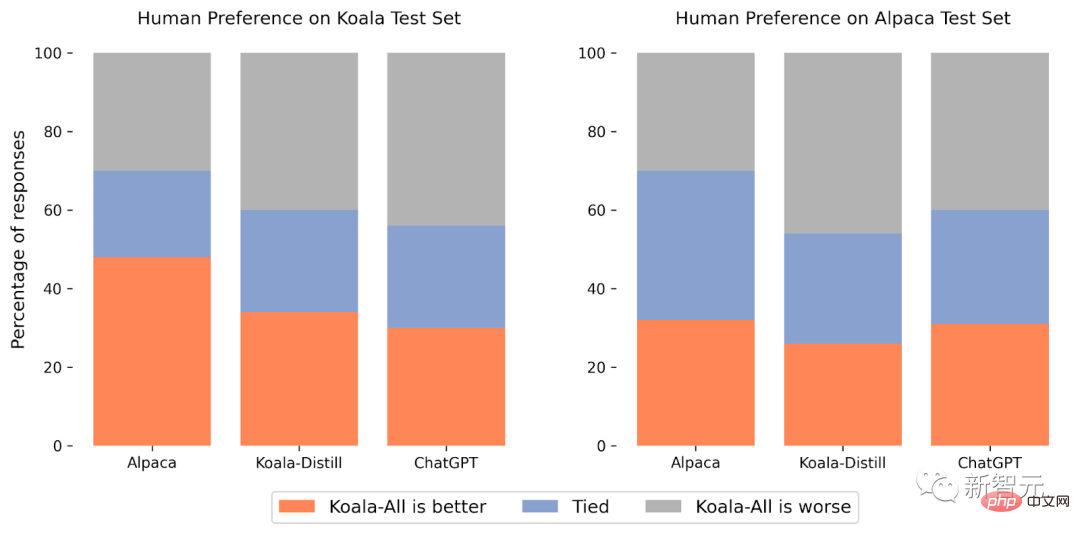
ChatGPT のパブリック ユーザーとの会話の共有 (ShareGPT): ShareGPT 上のユーザーによって共有された約 6 万の会話が、パブリック API を使用して収集されました。ウェブサイトのリンク: https://sharegpt.com/ データの品質を確保するため, 研究 スタッフは重複したユーザーのクエリを削除し、英語以外の会話をすべて削除し、約 30,000 のサンプルを残しました。 Human ChatGPT 比較コーパス (HC3): 人間と ChatGPT の応答結果を使用した HC3 英語データセットには、約 60,000 件の人間による回答と、約 24,000 件の質問のうち 27,000 件の ChatGPT の回答が含まれており、合計約87,000の質問と回答のサンプルが得られました。 オープン インストラクション ジェネラリスト (OIG): LAION が厳選したオープン インストラクション 一般データから手動で選択したコンポーネントのサブセットを使用する小学校の数学指導、詩から歌、プロット、脚本、本、会話のデータ セットを含むセットで、合計約 30,000 のサンプルが取得されました。 Stanford Alpaca: Stanford Alpaca モデルのトレーニングに使用されるデータセットが含まれています。 このデータ セットには、自己指示プロセスに従って OpenAI の text-davinci-003 によって生成された約 52,000 のサンプルが含まれています。 HC3、OIG、および Alpaca データ セットは 1 ラウンドの質問と回答であるのに対し、ShareGPT データ セットは複数ラウンドの会話であることに注意してください。 人間的 HH: モデル出力の有害性と有用性に関する人間による評価が含まれます。 データセットには人間が評価した約 160,000 の例が含まれており、各例はチャットボットからの応答のペアで構成されており、そのうちの 1 つは人間が好むものです。追加のセキュリティ。 OpenAI WebGPT: このデータセットには合計約 20,000 件の比較が含まれており、各例には質問、模範解答のペア、メタデータ、解答のスコア付けが含まれています。人間は自分の好みに基づいて行動します。 OpenAI 要約: モデルが生成した要約に対する人間からのフィードバックを含む約 93,000 の例が含まれており、人間の評価者が 2 つのオプションから選択します。 より良い要約結果。 オープン ソース データセットを使用する場合、一部のデータセットは、良いまたは悪いの評価に対応する 2 つの応答を提供する場合があります (AnthropicHH、WebGPT、OpenAI の概要)。 以前の研究結果では、人間の好みのラベル (役に立つ/役に立たない) に関する条件付き言語モデルがパフォーマンスを向上させる有効性を示しており、研究者は好みのラベルに基づいて肯定的なラベルまたは否定的なラベルにモデルを配置しました。 、人間のフィードバックがない場合は、データセットにポジティブなラベルを使用します。評価フェーズでは、ポジティブ タグを含むようにプロンプトが作成されます。 Koala は、オープンソース フレームワーク EasyLM (さまざまな大規模な言語モデルの事前トレーニング、微調整、提供および評価) に基づいており、トレーニング機器である JAX/Flax を使用して実装されています。は Nvidia DGX サーバーであり、8 つの A100 GPU では、2 エポックを完了するには 6 時間のトレーニングが必要です。 パブリック クラウド コンピューティング プラットフォームでは、予想されるトレーニング費用は 100 ドル以下です。 研究者らは実験で、蒸留データのみを使用する Koala-Distill と、蒸留データを含むすべてのデータを使用する Koala-All の 2 つのモデルを評価しました。そしてオープンソースデータ。 実験の目的は、モデルのパフォーマンスを比較し、抽出されたデータセットとオープンソースのデータセットが最終的なモデルのパフォーマンスに与える影響を評価することです。Koala モデルの人間による評価を実行し、比較します。 Koala-All with Koala- Distill、Alpaca、ChatGPT を比較します。 #実験のテスト セットは、スタンフォード大学の Alpaca テスト セットと Koala テスト セットで構成され、180 個のテスト クエリが含まれています Alpaca テスト セットは、自己構造データ セットからサンプリングされたユーザー プロンプトで構成され、Alpaca モデルの分散データを表します。より現実的な評価プロトコルを提供するために、Koala テスト セットには 180 人の実際のユーザーが含まれていますオンラインで公開されたクエリは、さまざまなトピックにまたがり、通常は会話形式ですが、チャット システムに基づく実際の使用例をよりよく表しており、テスト セットの漏洩の可能性を減らすために、BLEU スコアが 20% を超えるクエリは最終的にフィルタリングされて除外されます。トレーニングセット。 さらに、研究チームは英語に堪能であるため、より信頼性の高い注釈結果を提供するために英語以外のプロンプトやエンコーディング関連のプロンプトを削除し、最終的に結果を分析しました。 Amazon クラウドソーシング プラットフォーム約 100 人のアノテーターがブラインド テストを実施し、各評価者に入力プロンプトとスコアリング インターフェイスの両方のモデルの出力を提供し、応答の品質と正確さに関連する基準を使用してどちらの出力が優れているかを判断するよう求めます (同じように良いです)。 Alpaca テスト セットでは、Koala-All は Alpaca と同等のパフォーマンスを示します。 Koala テスト セット (実際のユーザーのクエリを含む) では、Koala-All はサンプルのほぼ半数で Alpaca よりも優れており、サンプルの 70% で Alpaca を超えるか、同じです。まあ、コアラのトレーニング セットとテスト セットがより類似しているのには理由があるはずなので、この結果は特に驚くべきことではありません。 しかし、これらのヒントがこれらのモデルの下流の使用例に似ている限り、Koala はアシスタントのようなアプリケーションでより良いパフォーマンスを発揮することを意味します。インターネットは、言語モデルと対話することと同等であり、これらのモデルに効果的な命令実行機能を与える効果的な戦略です。 さらに驚くべきことは、研究者らは、抽出されたデータ (Koala-All) に加えて、ChatGPT の抽出されたデータ (Koala-All) のみを使用したトレーニングよりも、オープン ソース データでのトレーニングの方が優れていることを発見したことです。蒸留)トレーニングのパフォーマンスがわずかに悪くなります。 その差はそれほど大きくないかもしれませんが、この結果は、ChatGPT の会話の品質が非常に高いため、2 倍のオープンソース データを含めても大幅な改善が得られないことを示唆しています。 最初の仮説は、Koala-All のパフォーマンスが向上するはずであるため、すべての評価で Koala-All が主要な評価モデルとして使用され、最終的には効果的な指示と補助が有効であることがわかります。これらのプロンプトがテスト段階でユーザーの多様性を表している限り、モデルは大規模な言語モデルから取得できます。 したがって、強力な会話パターンを構築する鍵は、高品質の会話データを管理することにある可能性があります。このデータは、ユーザーのクエリによって異なり、単に質問と回答に再フォーマットされたデータセットがあるわけではありません。 。 他の言語モデルと同様、Koala にも制限事項があり、誤用するとユーザーに損害を与える可能性があります。 研究者らは、おそらく対話の微調整の結果として、コアラが幻覚を起こし、非常に自信に満ちた口調で事実に反した反応をすることを観察しました。つまり、モデルが継承しているという事実より大きな言語モデルの自信に満ちたスタイルは、同じレベルを継承していないため、将来的に集中的な改善が必要です。 Koala のファントム リプライは悪用されると、誤った情報、スパム、その他のコンテンツの拡散を促進する可能性があります。 コアラは、自信に満ちた説得力のある口調で不正確な情報を幻覚で伝えることができます。幻覚に加えて、コアラには他のチャットボットもあります。言語モデルの欠点。これらには次のものが含まれます: 潜在的な悪用をさらに減らすために、安全でないコンテンツにフラグを立てて削除するために、OpenAI のコンテンツ モデレーション フィルターもデモに導入されました。 今後の取り組み : 
オープン ソース データ
初期評価
制限事項とセキュリティ
研究者らは、Koala モデルが大規模な言語モデルに関する将来の学術研究にとって有用なプラットフォームになることを望んでいます。このモデルは、最新の言語モデルの多くの機能を備えていますが、同時に、十分に小さいため、微調整したり、より少ない計算で使用したりできます。将来の研究の方向性には、次のものが含まれる可能性があります。 #セキュリティと一貫性
以上がコストは100ドル未満です!カリフォルニア大学バークレー校、ChatGPT のようなモデル「Koala」を再開: 大量のデータは役に立たず、高品質が重要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
76
15
1378
52
81
11
21
76

 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
