

機械学習と制約付き最適化に基づくデジタル ツイン モデリング

翻訳者 | Zhu Xianzhong
査読者 | Sun Shujuan
はじめに
今日、データ サイエンスはデジタル ツイン (デジタル ツイン)、つまりデジタル ツインを作成するために広く使用されています。現実世界の物理システムまたはプロセスのデジタル版であり、入力動作のシミュレーションと予測、監視、メンテナンス、計画などに使用できます。コグニティブ カスタマー サービス ボットなどのデジタル ツインは日常的なアプリケーションで一般的ですが、この記事では、業界のツイン データ サイエンス テクノロジにおける 2 つの異なるタイプのデジタル ツインを示し、モデリングのために 2 つの異なるタイプを比較します。
この記事で説明するデジタル ツインの 2 つの広く使用されているデータ サイエンス分野は次のとおりです:
a) 診断分析と予測分析: この分析方法では、A シリーズが与えられているとします。デジタルツインが原因を診断したり、システムの将来の動作を予測したりするために使用される入力の数。 IoT ベースの機械学習モデルは、スマートなマシンや工場を構築するために使用されます。このモデルにより、センサー入力をリアルタイムで分析して、将来の問題や障害が発生する前に診断、予測、防止することができます。
b) 規範的分析: この分析方法はネットワーク全体をシミュレートするため、遵守すべき一連の変数と制約を考慮して、多数のソリューションの中から最適なソリューションまたは実現可能なソリューションを決定します。通常、スループット、使用率、生産量などの定められたビジネス目標を最大化することを目的としています。これらの最適化問題は、物流プロバイダーが納期厳守を最大化するためにリソース (車両、人員) のスケジュールを作成する場合や、メーカーがスケジュールを作成する場合など、サプライ チェーンの計画とスケジューリングの分野で広く使用されています。機械とオペレーターの使用を最適化し、最大限の OTIF (On Time In Full) 納品を達成します。ここで使用されるデータ サイエンスの手法は、制約付き数学的最適化であり、強力なソルバーを使用して複雑な意思決定主導の問題を解決するアルゴリズムです。
要約すると、ML モデルは、履歴データに基づいて、特定の入力特徴セットに対して起こり得る結果を予測します。また、最適化モデルは、予測された結果が発生した場合に、それをどのように解決/軽減/活用する計画を立てるかを決定するのに役立ちます。なぜなら、あなたのビジネスには、限られたリソースの中で追求することを選択する可能性のある競合する可能性のある目標がいくつかあるからです。
データ サイエンスのこれら 2 つの分野は、一部のツール (Python ライブラリなど) を共有していますが、まったく異なるスキル セットを備えたデータ サイエンティストを動員しています。多くの場合、異なる考え方やビジネス問題のモデル化方法が必要です。したがって、あるドメインで経験を積んだデータ サイエンティストが、別のドメインで適用できる可能性のあるスキルやテクニックを理解し、相互利用できるように、関連する手法を理解して比較してみましょう。
デジタル ツイン モデルの適用ケース
比較のために、ML ベースの実稼働根本原因分析 (RCA: Root Cause Analysis) プロセスのツイン モデルを考えてみましょう。その目的は次のとおりです。完成品を診断するか、製造中に発見された欠陥や異常の根本原因を診断します。これにより、部門管理者はツールの予測に基づいて最も可能性の高い根本原因を排除し、最終的に問題を特定してCAPA(Corrective & Preventive action:是正措置と予防措置)を実行し、多くの人手を費やすことなくすべての機械保守記録を迅速に閲覧できるようになります。, オペレーター履歴記録、プロセスSOP(Standard Operation Procedure:標準作業手順書)、IoTセンサー入力など目標は、機械のダウンタイムと生産損失を最小限に抑え、リソースの利用率を向上させることです。
技術的には、これは複数カテゴリの分類問題と考えることができます。この問題では、特定の欠陥が存在すると仮定して、モデルは、機械関連、オペレーター関連、プロセス指示関連、原材料関連、などの考えられる一連の根本原因ラベルのそれぞれの確率を予測しようとします。これらの第 1 レベルの分類ラベルには、機械の校正、機械のメンテナンス、オペレーターのスキル、オペレーターのトレーニングなどの詳細な理由も含まれます。この状況に対する最適な解決策には、いくつかの複雑な ML モデルの評価が必要ですが、この記事の目的を強調するために、少し単純化してみましょう。これは多項ロジスティック回帰問題であると仮定します (理由は次のセクションで明らかになります)。
比較のために、生産計画プロセスの最適化されたツイン モデルを考えてみましょう。このモデルは、機械、オペレーター、プロセス ステップ、期間、原材料の到着スケジュール、期日などに基づいてスケジュールを生成します。生産高や収益などの目標を最大化します。このような自動化されたタイムラインは、組織が市場からの新たな機会 (新型コロナウイルス感染症による医薬品需要など) に対応するため、または原材料、サプライヤー、物流プロバイダー、顧客と市場の組み合わせの影響を最大化するためにリソースを迅速に調整するのに役立ちます。最近のサプライチェーンのボトルネックなど、予期せぬ出来事の影響を最小限に抑えます。
ビジネス上の問題をモデル化するための基本レベルでは、このようなデジタル ツインを開発するには次の要素を考慮する必要があります:
A. 入力機能またはディメンション
B. 入力データ— —これらの次元の値
C、入力から出力への変換ルール
D、出力またはターゲット
次に、機械学習をさらに詳しく分析して比較してみましょう(ML) を使用して、制約の下でモデル内のこれらの要素を最適化します:
A. 入力特徴: これらはシステム内のデータ ディメンションであり、ML と最適化の両方に適しています。生産プロセスの問題を診断しようとする ML モデルの場合、考慮すべき機能には、IoT 入力、機械保守データの履歴、オペレータのスキルとトレーニング情報、原材料の品質情報、従った SOP (標準作業手順)、およびその他のコンテンツが含まれます。 。
同様に、制約のある最適化環境では、考慮する必要がある特性には、機器の可用性、オペレーターの可用性、原材料の可用性、労働時間、生産性、スキルなどが含まれます。これらは、製品の開発に通常必要となります。最適生産計画機能。
B. 入力データ: これは、上記の 2 つの方法が大幅に異なる方法で固有値を使用する場所です。その中でも、ML モデルはトレーニングのために大量の履歴データを必要とします。ただし、多くの場合、データをモデルにフィードする前に、データの準備、管理、正規化に関連する多大な作業が必要になります。履歴は、実際に発生したイベント (不十分な出力をもたらした機械の故障やオペレーターのスキルの問題など) の記録ですが、通常は、これらの値がすべて考えられる単純な組み合わせではないことに注意することが重要です。特性が得られます。つまり、トランザクション履歴には、頻繁に発生するシナリオではより多くのレコードが含まれますが、他の一部のシナリオでは比較的少数のレコードが含まれます (まれに発生するシナリオではおそらく少なくなります)。モデルをトレーニングする目的は、トレーニング データに特徴値または特徴値の組み合わせがほとんどまたはまったくない場合でも、特徴と出力ラベルの間の関係を学習し、正確なラベルを予測することです。
一方、最適化手法の場合、特性値は通常、日数、バッチ、期限、日付ごとの原材料の入手可能性、メンテナンススケジュール、機械の切り替え時間、プロセスなどの実際のデータに維持されます。手順、オペレーターのスキルなど。 ML モデルとの主な違いは、入力データ処理では、マスター データの特徴値 (日数、スキル、マシン、オペレーター、プロセス タイプなど) の考えられるすべての有効な組み合わせに対してインデックス テーブルを生成して、リストを形成する必要があることです。実現可能な解決策の部分。たとえば、オペレータ A が週の初日にマシン M1 を使用して、プロセスのステップ 1 をスキル レベル S1 で実行するか、オペレータ B が週の 2 日目にマシン M1 を使用して、ステップ 1 をスキル レベル S2 で実行します。オペレーター、マシン、スキルレベル、日付などの考えられるすべての組み合わせについても、それらの組み合わせが過去に実際に発生したかどうかは関係ありません。これにより、非常に大規模な入力データ レコードのセットが最適化エンジンに提供されることになります。最適化モデルの目標は、目的の方程式を最大化 (または最小化) しながら、指定された制約を満たす固有値の特定の組み合わせを選択することです。
C. 入力から出力への変換ルール: これも 2 つの方法の大きな違いです。 ML モデルと最適化モデルはどちらも高度な数学理論に基づいていますが、最適化手法における複雑なビジネス問題の数学的モデリングとプログラミングには、通常、ML と比べてより多くの労力が必要であり、これについては次の概要で反映されます。
その理由は、ML では、scikit-learn などのオープンソース ライブラリ、Pytorch や Tensorflow などのフレームワーク、さらにはクラウド サービス プロバイダーの ML/深層学習モデルの助けを借りて、入力をこれには、最適なルール (重み、バイアス、活性化関数など) を導出するために損失を修正するタスクも含まれます。データ サイエンティストの主な責任は、入力特徴とその値の品質と完全性を保証することです。
これは、最適化メソッドの場合には当てはまりません。入力がどのように相互作用し、出力に変換されるかについてのルールは、詳細な方程式を使用して記述し、Gurobi、CPLEX などのソルバーに順番に入力する必要があるからです。最適な解決策または可能な解決策を見つけるため。さらに、ビジネス上の問題を数式として定式化するには、モデリング プロセスの相互関係を深く理解し、データ サイエンティストがビジネス アナリストと緊密に連携する必要があります。
以下では、問題のある RCA (根本原因分析) アプリケーションのロジスティック回帰モデルの概略図を使用してこれを説明します。
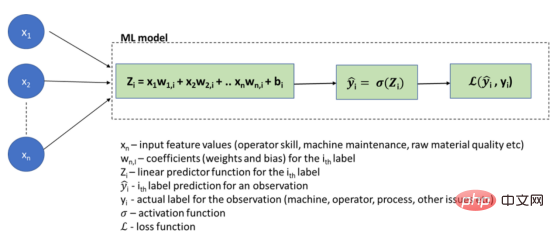
ロジスティック回帰 MLモデル
この場合、入力データに基づいて結果を生成するためのルール (Zᵢ) を計算するタスクは推定するモデルに任されており、データ サイエンティストは通常、明確に定義された混同行列を使用することに忙しいことに注意してください。 、RMSE およびその他の測定技術を視覚的にアプローチして、正確な予測を実現します。
これを、最適化手法を通じて生産計画が生成される方法と比較できます。
(I) 最初のステップは、計画プロセスをカプセル化するビジネス ルール (制約) を定義することです。 。
以下は生産計画の例です:
まず、いくつかの入力変数を定義します (その一部は目標を達成するために使用される決定変数になる可能性があります):
- Bᵦ,p,ᵢ——製品 p (製品テーブル内) のバッチ β (バッチ テーブル内) が i 日目にスケジュールされているかどうかを示すバイナリ変数。
- Oₒ,p,ᵢ - (演算子テーブル内の) インデックス o の演算子が i 日に製品 p のバッチを処理するようにスケジュールされているかどうかを示すバイナリ変数。
- Mm,p,ᵢ——(マシン テーブル内の) インデックス m を持つマシンが i でバッチを処理するようにスケジュールされているかどうかを示すバイナリ変数-日目 商品ページ
およびいくつかの係数:
- TOₒ,p - オペレーター o が製品 p のバッチを処理するのにかかる時間。
- TMm,p——マシン m が製品 p のバッチを処理するのにかかる時間。
- OAvₒ,ᵢ——i 日目にオペレーター インデックス o が使用できる時間数。
- MAvm,ᵢ——インデックス m のマシンが i 日に利用できる時間数。
この場合、いくつかの制約 (ルール) は以下を使用して実装できます:
a) プランでは、特定のバッチは 1 回だけ開始できます。
ここで、製品の各バッチについて、Bt はバッチの合計数、Pr は製品の合計数、D は計画の日数です。
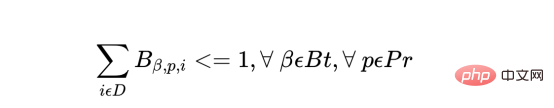
b) 1 つの製品 オペレーターまたはマシンで 1 日に 1 回のみ起動できます。
各製品の毎日。ここで、Op はすべてのオペレーターのセット、Mc はすべてのマシンのセットです。
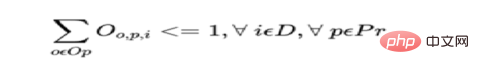
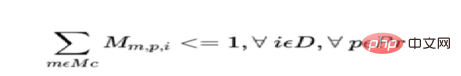
##c) バッチ (すべての製品) に費やされる合計時間は、その日に利用可能なオペレーターおよび機械の時間数を超えてはなりません。
各オペレーターには次の制約があります:
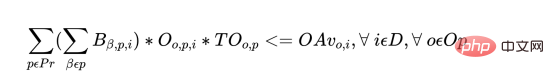
各マシンの毎日には次の制約があります:
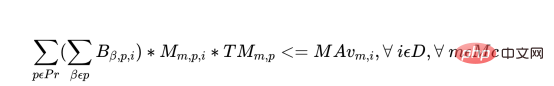
d) オペレーターがスケジュールの最初の 5 日以内に製品のバッチを処理する場合、同じ製品の他のすべてのバッチを同じオペレーターに割り当てる必要があります。これにより、オペレーターの継続性と生産性が維持されます。
各事業者および各製品について、各日 d (6 日目以降) に次の制約が存在します。
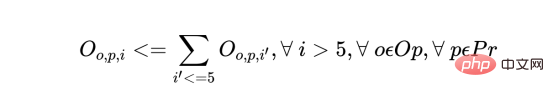
上記は、プログラム 実際の生産スケジューリング シナリオのビジネス ルールを数式で形成するために記述された数百の制約のうちのいくつか。これらの制約は線形方程式 (より具体的には混合整数方程式) であることに注意してください。ただし、それらとロジスティック回帰 ML モデルの間の複雑さの違いは依然として非常に明白です。
(II) 制約が決定したら、出力ターゲットを定義する必要があります。 これは重要なステップであり、次のセクションで説明するように、複雑なプロセスになる可能性があります。
(III) 最後に、入力された決定変数、制約、および目的がソルバーに送信され、解決策 (スケジュール) が取得されます。
#最適化手法に基づいたデジタル ツインを説明する概略図は次のとおりです。
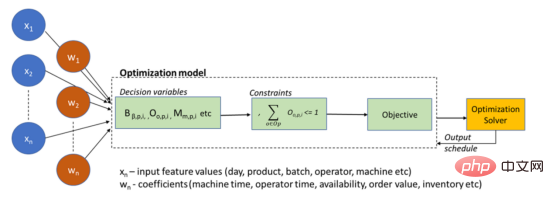
最適化モデル
D、出力または目標: ML モデルの場合、問題の種類 (分類、回帰、クラスタリング) に応じて、出力とその精度を測定するための指標を適切に確立することができます。入手可能な情報が豊富にあるため、この記事ではこれらの問題については詳しく説明しませんが、主要な CSP (AWS Sagemaker、Azure など) のような高度な自動化により、さまざまなモデルの出力を評価できることは注目に値します。 MLなど)。
最適化されたモデルが正しい出力を生成するかどうかを評価することは、より困難です。最適化モデルは、「目的」と呼ばれる計算式を最大化または最小化しようとすることによって機能します。制約と同様に、目標セクションは、ビジネスが達成しようとしている内容に基づいてデータ サイエンティストによって設計されます。より具体的には、これは、オプティマイザがその合計を最大化しようとする決定変数に報酬条件とペナルティ条件を付加することによって実現されます。現実の問題では、場合によっては矛盾する目標の間で適切なバランスを見つけるために、さまざまな目標に適切な重みを見つけるには多くの反復が必要です。
上記の生産スケジュールの例をさらに詳しく説明するには、次の 2 つの目標を設計することもできます:
a) スケジュールは事前にロードする必要があり、バッチはできるだけ早くスケジュールする必要があります。可能であり、プランの残りの容量はプランの最後にある必要があります。これを行うには、バッチに 1 日のペナルティを付加し、スケジュール内で毎日徐々にペナルティを増やします。
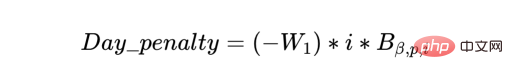
b) 一方、同じ製品のバッチをグループ化して、バッチが納期を守り、グループが 1 回の実行であれば、リソース (オペレーターとマシン) が部分的に最適に利用されるようにしたいとも考えています。機械の能力を超えないこと。したがって、バッチが小さなグループではなく大きなグループに配置されている場合に、より高いボーナス (したがって、以下の式の指数関数) を提供する Batch_group_bonus を定義します。今日開始される一部のバッチは、数日以内に利用可能になるさらに多くのバッチで開始され、スケジュールの早い段階で未達成のリソースが残る可能性があるため、これは以前の目標と交差する場合があることに注意することが重要です。
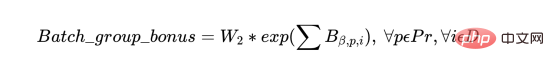
#ソルバーの動作方法に応じて、実際の実装ではバッチ グループ決定変数が必要になることがよくあります。ただし、これは次の概念を表しています:
ソルバーは目標を最大化します。つまり:
Objective=Batch_group_bonus Day_penalty
目標の上記 2 つのコンポーネントのうち、どれスケジュールの特定の日に大きな影響を与える方法は、重み W₁、W₂、およびスケジュールの日付に依存します。これは、日ペナルティ値がスケジュールの後半段階で徐々に大きくなる (i 値が高くなるほど) ためです。ある時点で日数ペナルティ値が Batch_group_bonus よりも大きい場合、計画ソルバーはバッチをスケジュールしないことが賢明であると判断します。したがって、計画にリソース キャパシティがある場合でも、ペナルティはゼロになります。正味マイナスのペナルティとなり、目標が最大化されます。これらの問題は、データ サイエンティストによってトラブルシューティングされ、解決される必要があります。
ML 手法と最適化手法の間の相対的な作業負荷の比較
上記の議論に基づいて、一般的に、最適化プロジェクトは ML プロジェクトよりも多くの労力を必要とすることが推測できます。最適化には、開発プロセスのほぼすべての段階で広範なデータ サイエンス作業が必要です。具体的な概要は次のとおりです:
a) 入力データ処理: ML と最適化では、これはデータ サイエンティストによって行われます。 ML データ処理には、関連する機能の選択、標準化、離散化などが必要です。テキストなどの非構造化データの場合、特徴抽出、トークン化などの NLP ベースの手法を含めることができます。現在、特徴の統計分析や PCA などの次元削減手法に使用できる複数の言語に基づくライブラリがあります。
最適化では、すべてのビジネスと計画に、モデルに組み込む必要のあるニュアンスがあります。最適化問題は履歴データを扱うのではなく、考えられるすべてのデータ変更と識別された特徴を、決定変数と制約が依存する必要があるインデックスに結合します。ただし、ML とは異なり、データ処理には多くの開発作業が必要です。
b) モデル開発: 上で述べたように、最適化ソリューションのモデルを定式化するには、データ サイエンティストとビジネス アナリストが制約と目標を定式化するために多大な労力を必要とします。ソルバーは数学的アルゴリズムを実行し、数百、場合によっては数千の方程式を同時に解いて解を見つけるという任務を負っていますが、ビジネスの背景はありません。
ML では、モデルのトレーニングが高度に自動化されており、アルゴリズムはオープンソース ライブラリ API としてパッケージ化されるか、クラウド サービス プロバイダーによってパッケージ化されます。ビジネス固有のデータに基づいた、非常に複雑な事前トレーニング済みのニューラル ネットワーク モデルにより、トレーニング タスクが最後の数層まで簡素化されます。 AWS Sagemaker Autopilot や Azure AutoML などのツールを使用すると、入力データの処理、特徴の選択、さまざまなモデルのトレーニングと評価、および出力生成のプロセス全体を自動化することもできます。
c) テストと出力処理: ML では、モデルの出力を最小限の処理で利用できます。結果の解釈可能性など、他の側面を導入するには多少の努力が必要な場合もありますが、一般に理解するのは簡単です (さまざまなラベルの確率など)。出力とエラーの視覚化にもある程度の労力が必要になる場合がありますが、入力処理に比べればそれほど大きなことではありません。
ここでも、最適化の問題では、進捗状況を評価するために、計画専門家の訓練された目による反復的な手動テストと検証が必要です。ソルバーは目的を最大化しようとしますが、これ自体はスケジュール品質の観点からはほとんど意味がありません。 ML とは異なり、しきい値を上回るか下回る目標値に、正しい計画が含まれているのか、間違った計画が含まれているのかを判断することはできません。スケジュールがビジネス目標と矛盾していることが判明した場合、その問題は制約、決定変数、または目的関数に関連している可能性があり、大規模で複雑なスケジュールの異常の原因を見つけるには慎重な分析が必要です。
さらに、考慮すべき点は、ソルバーの出力を人間が読める形式に解釈するために必要な開発です。ソルバーは、バッチ グループ インデックス、バッチ優先順位インデックス、オペレーターおよびマシン インデックスなど、計画内の実際の物理エンティティのインデックス値である入力決定変数を受け取り、選択された値を返します。これらのインデックス値をそれぞれのデータ フレームから、専門家が視覚的に表示および分析できる一貫したタイムラインに変換するには、逆処理が必要です。
d) 最後に、運用フェーズであっても、ML モデルはトレーニング フェーズと比較して、観測予測を生成するために必要な計算量と時間が大幅に少なくなります。ただし、スケジュールは毎回最初から作成されるため、実行ごとに同じリソースが必要になります。
次の図は、ML および最適化プロジェクトの各段階における相対的なワークロードの大まかな図です。
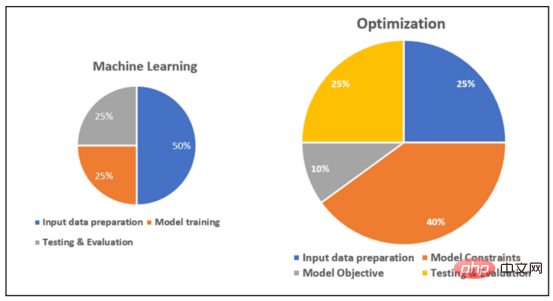
ML と最適化の相対的なワークロードを比較する概略図
#ML と最適化は連携できますか?
機械学習と最適化は企業にとって相補的な問題を解決するため、ML モデルの出力と最適化は相互に強化し合い、その逆も同様です。 IoT の予知保全や障害検出、AR/VR リモート メンテナンス、前述の生産プロセス RCA などの AI/ML アプリケーションは、メーカーのコネクテッド ファクトリー戦略の一部を形成しています。
最適化アプリケーションはサプライ チェーン計画の基礎を形成し、ビジネス戦略を運用に結び付けるものと考えることができます。これらは、組織が予期せぬイベントに対応し、計画を立てるのに役立ちます。たとえば、生産ラインで問題が検出された場合、RCA (根本原因分析) ツールは、生産ライン管理者が考えられる原因を迅速に絞り込み、必要な措置を講じるのに役立ちます。ただし、これにより、予期しないマシンのシャットダウンや操作命令の再割り当てが発生する場合があります。したがって、削減された利用可能な容量を使用して生産計画を再作成する必要がある場合があります。
ML の一部のテクニックは最適化に適用できますか?またその逆も可能ですか?
ML プロジェクトの経験は最適化プロジェクトに適用でき、その逆も同様です。たとえば、出力の最適化に重要な目的関数の場合、ビジネス ユニットが数学的モデリングの観点から制約ほど明確に定義されていない場合があります。制約は従う必要があるルールであり、したがって通常はよく知られています。たとえば、ビジネス目標は次のとおりです。
a) 納期を厳守しながら、バッチの優先順位をできるだけ早く設定する必要があります。
b) スケジュールは事前にロードする必要があります。時間間隔はできるだけ短く、リソース使用率を低く設定する必要があります。
c) 容量を効率的に利用するには、バッチをグループ化する必要があります。
d) 高価値製品に関してより高いスキル レベルを持つオペレータには、そのようなバッチを割り当てるのが最適です。
これらの目標の中には、適切にバランスを取る必要がある競合する優先順位がある場合があります。そのため、データ サイエンティストは、影響を与える要素 (ボーナスや罰金など) の複雑な組み合わせを記述するときに、どの目標に当てはまりそうなものに焦点を当てることがよくあります。最も一般的な計画シナリオは試行錯誤によって達成されますが、欠陥が発生すると、ロジックの理解や維持が困難になる場合があります。最適化ソルバーはサードパーティ製品を使用することが多いため、デバッグ対象のモデルを構築するデータ サイエンティストがそのコードを利用できないことがよくあります。これにより、スケジュール生成プロセスの特定の時点で特定のボーナスやペナルティがどのような値になったかを確認することができなくなります。これらの値によってスケジュールが正しく動作するため、説得力のあるターゲット表現を作成することが非常に重要になります。
したがって、上記のアプローチは、ML で広く使用されているボーナスと罰金の標準化を採用するのに役立ちます。正規化された値は、構成パラメーターまたはその他の手段を使用して、制御された方法でスケーリングし、各要素の影響、相互の関係、および各要素内の前後の要素の値を制御できます。
結論
要約すると、機械学習と制約付き最適化はどちらも、組織や日常生活におけるさまざまな問題を解決するための高度な数学的手法です。これらはすべて、物理機器、プロセス、またはネットワーク リソースのデジタル ツインを展開するために使用できます。どちらのタイプのアプリケーションも同様の高レベルの開発プロセスに従いますが、ML プロジェクトはライブラリやクラウドネイティブ アルゴリズムで利用可能な高度な自動化を活用できますが、最適化には複雑な計画プロセスを完全に実装するためにビジネス サイエンティストとデータ サイエンティストの緊密な連携が必要です。モデリング。一般的に、最適化プロジェクトはより多くの開発作業を必要とし、リソースを大量に消費します。実際の開発では、企業内で ML ツールと最適化ツールを連携させる必要があることが多く、どちらのテクノロジーもデータ サイエンティストにとって役立ちます。
翻訳者紹介
Zhu Xianzhong 氏、51CTO コミュニティ編集者、51CTO エキスパートブロガー、講師、濰坊市の大学のコンピューター教師、フリーランスプログラミング業界のベテラン。
原題: 機械学習と制約付き最適化を使用したデジタル ツイン モデリング 、著者: Partha Sarkar
以上が機械学習と制約付き最適化に基づくデジタル ツイン モデリングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7536
7536
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 2024 年の AEC/O 業界の 5 つの主要な開発トレンド
Apr 19, 2024 pm 02:50 PM
2024 年の AEC/O 業界の 5 つの主要な開発トレンド
Apr 19, 2024 pm 02:50 PM
AEC/O(Architecture, Engineering & Construction/Operation)とは、建設業界における建築設計、工学設計、建設、運営を提供する総合的なサービスを指します。 2024 年、AEC/O 業界は技術の進歩の中で変化する課題に直面しています。今年は先進技術の統合が見込まれ、設計、建設、運用におけるパラダイムシフトが到来すると予想されています。これらの変化に対応して、業界は急速に変化する世界のニーズに適応するために、作業プロセスを再定義し、優先順位を調整し、コラボレーションを強化しています。 AEC/O 業界の次の 5 つの主要なトレンドが 2024 年の主要テーマとなり、より統合され、応答性が高く、持続可能な未来に向けて進むことが推奨されます: 統合サプライ チェーン、スマート製造
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
