

TensorFlow アプリケーション技術の拡張 - 画像分類

1. 科学研究プラットフォーム環境の展開運用の拡張
機械学習のモデル トレーニングについては、中文大学 MOOC の 2 つのコースなど、TensorFlow の公式コースやリソースをさらに学習することをお勧めします 《TensorFlow 入門実践コース》 および 《TensorFlow 入門コース - デプロイメント》 科学研究や研究に関わるモデルの分散トレーニングの場合、リソース プラットフォームでは非常に時間がかかり、個々のニーズをタイムリーに満たすことができない場合があります。ここでは、前の記事 「TensorFlow フレームワーク学習の予備理解」 で説明した Jiutian Bisheng プラットフォームの使用法を具体的に拡張して、学生やユーザーがモデルをより迅速に実行できるようにします。トレーニング。このプラットフォームは、データ管理やモデルのトレーニングなどのタスクを実行でき、科学研究タスクの便利で高速な練習プラットフォームです。モデル トレーニングの具体的な手順は次のとおりです:
(1) Jiutian Bisheng プラットフォームに登録してログインします。後続のトレーニング タスクではコンピューティング パワー Bean の消費が必要であるため、新規ユーザーのコンピューティング パワー Bean の数は制限されています。 、ただし、友人や他のタスクによって共有して、コンピューティング パワー Bean の取得を完了することができます。同時に、大規模なモデル トレーニング タスクの場合、より多くのモデル トレーニング ストレージ スペースを取得するために、プラットフォームのスタッフに電子メールで連絡してコンソールをアップグレードすることができ、これにより、将来必要となるトレーニング ストレージ要件を満たすことができます。ストレージとコンピューティング能力の詳細は次のとおりです。

(2) データ管理インターフェイスに入り、科学研究プロジェクト モデルで使用されるデータ セットを展開し、科学研究タスクに必要なデータ セット。パッケージ化してアップロードすると、プラットフォームでのモデル トレーニングに必要なデータ セットの展開が完了します。
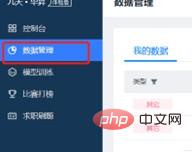
(3) モデル トレーニング ウィンドウに新しいプロジェクト トレーニング インスタンスを追加し、以前にインポートしたデータ セットと必要な CPU リソースを選択します。作成されたインスタンスは、科学研究用にトレーニングする必要がある単一のモデル ファイルです。新しいプロジェクト インスタンスの詳細は以下のとおりです。

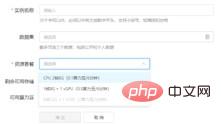

https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
この章は主に、画像分類を拡張することで学生にこのコースを紹介することを目的としていますユーザーは画像分類についてより深く理解できるようになります。 2.1 畳み込み演算は何に役立ちますか? 画像を処理または分類する場合、避けて通れない操作が 1 つあります。この操作が畳み込みです。具体的な畳み込み演算は基本的に学習動画で理解できますが、多くの読者は畳み込み演算をどのように実行するかというレベルにしか留まらず、なぜ畳み込みを行うのか、畳み込み演算を何に使うのかがまだ不明瞭な方も多いかもしれません。ここでは、畳み込みをより深く理解するのに役立つ、すべての人向けの拡張機能を示します。 基本的な畳み込みプロセスを次の図に示します。画像を例にとると、画像を表すために行列が使用されます。行列の各要素は、画像内の対応するピクセル値です。 。コンボリューション演算は、コンボリューション カーネルに対応する行列を乗算して、これらの小領域の固有値を取得することです。抽出された特徴は、コンボリューション カーネルが異なると異なるため、画像のさまざまなチャネルでコンボリューション演算を実行して、画像のさまざまなチャネルの特徴を取得し、後続の分類タスクをより適切に実行することになります。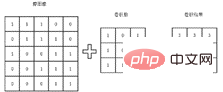
毎日のモデル トレーニングでは、特定のコンボリューション カーネルを手動で設計する必要はありませんが、画像の実際のラベルを与えることでネットワークを使用して自動的にトレーニングされます。ただし、このプロセスはコンボリューション カーネルについての人々の理解を助けません。カーネルと畳み込みのプロセスは直感的ではありません。そこで、畳み込み演算の意味を皆さんによく理解していただくために、畳み込み演算の例を示します。以下のマトリックスに示すように、数値はグラフィックのピクセルを表します。計算の便宜上、ここでは 0 と 1 のみを取ります。このマトリックス グラフィックの特徴は、上位の値であることがわかります。グラフィックの半分は明るく、グラフィックの下半分は黒であるため、画像には非常に明確な境界線があり、つまり、明らかな水平特性があります。

したがって、上記の行列の水平方向の特徴を適切に抽出するには、設計されたコンボリューション カーネルも水平方向の特徴抽出の属性を持たなければなりません。垂直特徴抽出属性を使用するコンボリューションカーネルは、特徴抽出の自明性が比較的不十分です。以下に示すように、水平特徴を抽出するコンボリューション カーネルが畳み込みに使用されます。
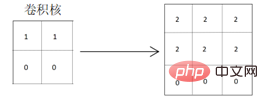
得られた畳み込み結果の行列から、元のグラフィックスの水平特徴が次のとおりであることがわかります。グラフィックスの色付き部分のピクセル値が深くなり、グラフィックスの水平方向の特徴をうまく抽出して強調表示できるため、グラフィックスの分割線がより明確になります。垂直方向の特徴を抽出するコンボリューションカーネルを使用してコンボリューションを実行した場合:
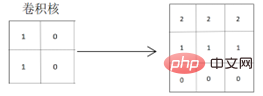
得られたコンボリューション結果の行列から、元のグラフィックスの水平方向の特徴も抽出できることがわかりますが、2本の分割線が生成されます グラフィックスは、非常に明るい→明るい→黒に変化します 実際のグラフィックスに反映される状況も、明るい→暗い→黒と変化し、本物のオリジナルの水平特性とは異なりますグラフィックスです。
上記の例から、コンボリューション カーネルが異なると最終的に抽出されるグラフィック特徴の品質に影響を与えることが容易にわかりますが、同時に、グラフィックによって反映される特性も異なります。畳み込みカーネルをより良く学習および設計するには、ネットワーク モデルを設計することも特に重要です。実際の地図分類プロジェクトでは、画像の違いに基づいて適切な特徴を選択して抽出する必要があり、多くの場合トレードオフを考慮する必要があります。
2.2 画像分類を改善するために畳み込みをどのように考慮するか?
前のセクションの畳み込み演算の役割からわかるように、画像に適応する畳み込みカーネルをよりよく学習するためにネットワーク モデルを設計することが特に重要です。ただし、実際のアプリケーションでは、指定された画像カテゴリの実際のラベルをマシンが理解できるベクトル データに変換することによって、自動学習とトレーニングが実行されます。もちろん、手動設定で改善することが完全に不可能というわけではありません。データ セットのラベルは固定されていますが、データ セットの画像タイプに基づいて異なるネットワーク モデルを選択できます。異なるネットワーク モデルの長所と短所を考慮すると、多くの場合、良好なトレーニング結果が得られます。
同時に、画像の特徴を抽出するときに、マルチタスク学習手法を使用することも検討できます。既存の画像データで、その画像データを再度使用して、いくつかの追加の画像特徴 ( (画像のチャネル特徴) や空間特徴など)、以前に抽出された特徴を補足または埋めて、最終的に抽出された画像特徴を改善します。もちろん、この操作により抽出された特徴が冗長になる場合もあり、得られる分類効果が逆効果になることも多いため、実際の学習分類結果に基づいて検討する必要があります。
2.3 ネットワーク モデルの選択に関するいくつかの提案
画像分類の分野は、元の古典的な AlexNet ネットワーク モデルから最近の人気のある ResNet ネットワーク モデルまで、長い間発展してきました。近年、画像分類技術は比較的順調に発展しており、一般的に使用される一部の画像データ セットの分類精度は 100% になる傾向があります。現在、この分野では、ほとんどの人が最新のネットワーク モデルを使用しており、ほとんどの画像分類タスクでは、最新のネットワーク モデルを使用すると確かに明らかな分類効果が得られます。そのため、この分野では多くの人が最新のネットワーク モデルを使用しています。以前のネットワーク モデルを参照し、最新の人気のあるネットワーク モデルを直接学習します。
ここでも、テクノロジーの更新と反復が非常に速く、将来的には最新のネットワーク モデルさえも使用されるため、読者にはグラフ分類の分野におけるいくつかの古典的なネットワーク モデルに慣れておくことをお勧めします。削除される可能性もありますが、基本的なネットワーク モデルの動作原理はほぼ同じです。クラシック ネットワーク モデルをマスターすると、基本原理をマスターできるだけでなく、異なるネットワーク モデル間の違いや、異なるタスクを処理する利点も理解できます。 。 劣等感。たとえば、画像データ セットが比較的小さい場合、最新のネットワーク モデルを使用したトレーニングは非常に複雑で時間がかかる可能性がありますが、改善効果は最小限であるため、無視できる効果のために自分自身のトレーニング時間のコストを犠牲にしても、利益を得る価値はありません。 。したがって、画像分類ネットワーク モデルをマスターするには、将来画像分類モデルを選択するときに真の対象となるように、画像分類ネットワーク モデルが何であるか、またその理由を知る必要があります。
著者紹介:
Rice、51CTO コミュニティ編集者は、かつて電子商取引人工知能研究開発センターのビッグデータ テクノロジー部門で推奨アルゴリズムを担当していました。現在は自然言語処理の研究に従事、主な専門分野は推薦アルゴリズム、NLP、CV、使用コーディング言語はJava、Python、Scalaなど。 ICCC 会議論文を 1 件出版しました。
以上がTensorFlow アプリケーション技術の拡張 - 画像分類の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 iPhoneのホーム画面から削除を元に戻す方法
Apr 17, 2024 pm 07:37 PM
iPhoneのホーム画面から削除を元に戻す方法
Apr 17, 2024 pm 07:37 PM
ホーム画面から重要なものを削除してしまい、元に戻そうとしていますか?さまざまな方法でアプリのアイコンを画面に戻すことができます。 iPhoneでホーム画面から削除を元に戻す方法 前述したように、iPhoneでこの変更を復元する方法はいくつかあります。方法 1 – App ライブラリのアプリ アイコンを置き換える App ライブラリから直接ホーム画面にアプリ アイコンを配置できます。ステップ 1 – 横にスワイプして、アプリ ライブラリ内のすべてのアプリを見つけます。ステップ 2 – 前に削除したアプリのアイコンを見つけます。ステップ 3 – アプリのアイコンをメインライブラリからホーム画面上の正しい場所にドラッグするだけです。これが応用図です
 PHP における矢印記号の役割と実際の応用
Mar 22, 2024 am 11:30 AM
PHP における矢印記号の役割と実際の応用
Mar 22, 2024 am 11:30 AM
PHP における矢印記号の役割と実際の応用 PHP では、通常、オブジェクトのプロパティとメソッドにアクセスするために矢印記号 (->) が使用されます。オブジェクトとは、PHP におけるオブジェクト指向プログラミング (OOP) の基本概念の 1 つで、実際の開発においては、矢印記号がオブジェクトを操作する上で重要な役割を果たします。この記事では、矢印記号の役割と実際の応用例を紹介し、読者の理解を深めるために具体的なコード例を示します。 1. オブジェクトのプロパティにアクセスするための矢印シンボルの役割 矢印シンボルは、オブジェクトのプロパティにアクセスするために使用できます。ペアをインスタンス化するとき
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 初心者から熟練者まで: Linux tee コマンドのさまざまなアプリケーション シナリオを探索する
Mar 20, 2024 am 10:00 AM
初心者から熟練者まで: Linux tee コマンドのさまざまなアプリケーション シナリオを探索する
Mar 20, 2024 am 10:00 AM
Linuxtee コマンドは、既存の出力に影響を与えることなく、出力をファイルに書き込んだり、別のコマンドに出力を送信したりできる、非常に便利なコマンド ライン ツールです。この記事では、入門から習熟まで、Linuxtee コマンドのさまざまな応用シナリオを詳しく見ていきます。 1. 基本的な使い方 まずは、teeコマンドの基本的な使い方を見てみましょう。 tee コマンドの構文は次のとおりです。 tee[OPTION]...[FILE]...このコマンドは、標準入力からデータを読み取り、データを保存します。
 レビュー!深いモデルの融合 (LLM/基本モデル/フェデレーテッド ラーニング/ファインチューニングなど)
Apr 18, 2024 pm 09:43 PM
レビュー!深いモデルの融合 (LLM/基本モデル/フェデレーテッド ラーニング/ファインチューニングなど)
Apr 18, 2024 pm 09:43 PM
9 月 23 日、論文「DeepModelFusion:ASurvey」が国立国防技術大学、JD.com、北京理工大学によって発表されました。ディープ モデルの融合/マージは、複数のディープ ラーニング モデルのパラメーターまたは予測を 1 つのモデルに結合する新しいテクノロジーです。さまざまなモデルの機能を組み合わせて、個々のモデルのバイアスとエラーを補償し、パフォーマンスを向上させます。大規模な深層学習モデル (LLM や基本モデルなど) での深層モデルの融合は、高い計算コスト、高次元のパラメーター空間、異なる異種モデル間の干渉など、いくつかの課題に直面しています。この記事では、既存のディープ モデル フュージョン手法を 4 つのカテゴリに分類します。 (1) 「パターン接続」。損失低減パスを介して重み空間内の解を接続し、より適切な初期モデル フュージョンを取得します。
 Go 言語の利点と応用シナリオを探る
Mar 27, 2024 pm 03:48 PM
Go 言語の利点と応用シナリオを探る
Mar 27, 2024 pm 03:48 PM
Go 言語は、Google によって開発され、2007 年に初めてリリースされたオープンソース プログラミング言語です。シンプルで習得しやすく、効率的で同時実行性の高い言語となるように設計されており、ますます多くの開発者に好まれています。この記事では、Go 言語の利点を探り、Go 言語に適したいくつかのアプリケーション シナリオを紹介し、具体的なコード例を示します。利点: 強力な同時実行性: Go 言語には、同時プログラミングを簡単に実装できる軽量スレッドのゴルーチンのサポートが組み込まれています。 Goroutin は go キーワードを使用して開始できます
 単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要
Jun 02, 2024 pm 06:57 PM
単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要
Jun 02, 2024 pm 06:57 PM
上記と著者の個人的な理解は、画像ベースの 3D 再構成は、一連の入力画像からオブジェクトまたはシーンの 3D 形状を推測することを含む困難なタスクであるということです。学習ベースの手法は、3D形状を直接推定できることから注目を集めています。このレビュー ペーパーは、これまでにない新しいビューの生成など、最先端の 3D 再構成技術に焦点を当てています。入力タイプ、モデル構造、出力表現、トレーニング戦略など、ガウス スプラッシュ メソッドの最近の開発の概要が提供されます。未解決の課題と今後の方向性についても議論します。この分野の急速な進歩と 3D 再構成手法を強化する数多くの機会を考慮すると、アルゴリズムを徹底的に調査することが重要であると思われます。したがって、この研究は、ガウス散乱の最近の進歩の包括的な概要を提供します。 (親指を上にスワイプしてください
 Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たすかを探る
Mar 19, 2024 pm 06:15 PM
Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たすかを探る
Mar 19, 2024 pm 06:15 PM
Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たしているかを調べるには、具体的なコード例が必要です。インターネットとモバイル アプリケーションの急速な発展に伴い、フロントエンド テクノロジーの重要性がますます高まっています。この分野では、強力なバックエンド プログラミング言語としての Golang も重要な役割を果たします。この記事では、Golang がどのようにフロントエンド テクノロジーと組み合わされるかを検討し、具体的なコード例を通じてフロントエンド分野での可能性を実証します。フロントエンド分野における Golang の役割は、効率的で簡潔かつ学びやすいものとしてです。
