

大規模 AI モデルのオープンソースのジレンマ: 独占、壁、コンピューティング能力の悲しみ

この記事はAI New Media Qubit(公開アカウントID:QbitAI)の許可を得て転載していますので、転載については出典元にご連絡ください。
2020年6月、OpenAIはGPT-3をリリースし、その数千億ものパラメータ規模と驚異的な言語処理能力は国内のAIコミュニティに大きな衝撃を与えました。しかし、GPT-3は国内市場に開放されていないため、海外でテキスト生成サービスを提供する営利企業がいくつも誕生すると、振り返ってため息をつくしかありません。
今年 8 月、ロンドンのオープンソース企業である Stability AI は、Vincent グラフ モデルである Stable Diffusion をリリースし、その重みとコードをオープンソース化しました。モデルを無料で提供したことで、AI ペイント アプリケーションが世界中で爆発的に普及するきっかけとなりました。
#今年下半期の AIGC ブームにおいて、オープンソースが直接の触媒的な役割を果たしたと言えます。
#そして、大規模なモデルが誰もが参加できるゲームになると、恩恵を受けるのは AIGC だけではありません。
01
大規模モデルのオープンソースが進行中
4 年前、というプロジェクトがありました。 BERT 言語モデルが登場し、3 億パラメータを持つ AI モデルのゲームルールを変えました。
今日、AI モデルの量は 1 兆規模に急増していますが、大規模モデルの「独占」もますます顕著になってきています。
大企業、大きなコンピューティング能力、強力なアルゴリズム、および大きなモデルが一緒になって、一般の開発者や中小企業には困難な壁を築きました。突破する。
技術的な障壁、および大規模なモデルのトレーニングと使用に必要なコンピューティング リソースとインフラストラクチャ。これは、大規模モデルの「洗練」から大規模モデルの「使用」への道を示しています。したがって、オープンソースは急務です。オープンソースを通じてより多くの人が大規模モデルのゲームに参加できるようにし、大規模モデルを新興の AI テクノロジーから堅牢なインフラストラクチャに変換することが、多くの大規模モデル作成者のコンセンサスになりつつあります。
# また、この合意に基づいて、Alibaba Damo Academy は、つい最近の Yunqi Conference で中国モデルのオープンソース コミュニティ「ModelScope」を立ち上げ、大きな注目を集めました。現在、一部の国内機関はコミュニティにモデルを提供したり、独自のオープンソース モデル システムを確立したりし始めています。
# 海外の大型モデルのオープンソースのエコロジー構築は現在、国内のものよりも進んでいます。 Stability AI は非公開企業として誕生しましたが、独自のオープンソース遺伝子を持ち、独自の大規模な開発者コミュニティを持ち、オープンソースでありながら安定した収益モデルを持っています。
今年 7 月にリリースされた BLOOM には、1,760 億のパラメータがあり、現在最大のオープンソース言語モデルです。その背後にある BigScience は、オープンソースの精神に完全に適合しています。 . つま先からはテクノロジー大手と競合する勢いがうかがえる。 BigScience は、Huggingface が主導するオープンな共同組織であり、正式に設立された組織ではありません。BLOOM の誕生は、70 か国以上から集まった 1,000 人以上の研究者が 117 日間スーパーコンピューターで訓練した結果です。
#さらに、テクノロジー大手は大規模モデルのオープンソースに関与していないわけではありません。今年の 5 月に、Meta は 1,750 億のパラメータを持つ大規模モデル OPT をオープンソース化し、OPT の非営利目的での使用を許可することに加えて、そのコードとトレーニング プロセスを記録する 100 ページのログも公開しました。オープンソースは非常に徹底していると述べた。
研究チームは、OPT の論文の要約の中で、「計算コストを考慮すると、これらのモデルは多額の資金がなければ再現するのが困難です。」と率直に指摘しました。 API を通じて利用できるいくつかのモデルは完全なモデルの重みにアクセスできないため、研究が困難です。」モデルの正式名称「Open Pre-trained Transformers」も、Meta のオープンソースの姿勢を示しています。これは、「オープン」ではない(APIの有料サービスを提供するだけ)OpenAIがリリースしたGPT-3や、Googleが今年4月に立ち上げた5400億パラメータの大規模モデルPaLM(オープンソースではない)を匂わせたものと言える。 。
常に独占意識が強い大企業の中で、Meta のオープンソース化への動きは新風を吹き込むものです。当時、スタンフォード大学の基礎モデル研究センター所長であるパーシー・リャン氏は次のようにコメントした。「これは、新たな研究の機会を開くための刺激的な一歩です。一般的に言えば、オープン性が高まることで研究者は問題を解決できるようになると考えられます。より深い問題."
02
大型モデルの想像力は AIGC にとどまるべきではありません
パーシーLiang 氏の言葉は、なぜ大規模なモデルを学術レベルからオープンソースにしなければならないのかという疑問にも答えています。
#独自の結果を生み出すには、土壌を提供するオープンソースが必要です。
研究開発チームは大規模なモデルをトレーニングします。トップカンファレンスでの論文発表で止まってしまうと、他の研究者は論文のさまざまな側面を得ることができます。モデルトレーニングテクノロジーの詳細を確認せずにこの種の「筋肉を見せる」フィギュアは、再現に時間がかかるだけで、成功しない可能性があります。再現性は、科学研究の結果が信頼でき、信頼できるものであることを保証します。オープン モデル、コード、データ セットを使用すると、科学研究者は、よりタイムリーに最先端の研究に追いつくことができ、巨人の肩の上に立って世界に触れることができます。スター. 高い場所から果物を収穫すると、時間とコストを大幅に節約し、技術革新をスピードアップできます。
中国の大規模モデル作業における独創性の欠如は、主にモデル サイズの盲目的な追求に反映されていますが、基礎となるアーキテクチャには革新がほとんどありません。 #これは、大規模モデルの研究に携わる業界専門家の間での一般的な合意です。
清華大学コンピューターサイエンス学部のLiu Zhiyuan准教授は、AI Technology Reviewで次のように指摘しました: 大規模モデルのアーキテクチャに関する比較的革新的な研究がいくつかあります中国にはまだ Transformer がベースになっていますが、中国には Transformer のような基本的なアーキテクチャや、この分野に大きな変化を引き起こす可能性のある BERT や GPT-3 のようなモデルがまだありません。
IDEA 研究所 (広東・香港・マカオ大湾区デジタル経済研究所) の首席研究員である張嘉興博士も、AI テクノロジーについて次のように語っています。数百億から数千億、数兆に及ぶさまざまなシステムおよびエンジニアリングの課題を克服した後、単にモデルを大きくするのではなく、新しいモデルの構造を検討する必要があることを確認してください。
一方、大規模モデルが技術を進歩させるには、一連のモデル評価基準が必要であり、基準の生成にはオープン性と透明性が必要です。最近の研究では、多くの大規模モデルに対してさまざまな評価指標を提案しようとしていますが、一部の優れたモデルはアクセスできないため除外されています。たとえば、Pathways アーキテクチャでトレーニングされた Google の大規模モデル PaLM は、超言語理解能力を備えています。それは冗談で、DeepMind の大規模言語モデル Chinchilla はオープンソースではありません。
#しかし、モデル自体の優れた機能からであっても、これらの大手メーカーの地位からであっても、これらのメーカーがそのような公正な取引から欠席することはできません。分野。
Percy Liang らによる最近の研究では、非オープンソース モデルと比較して、現在のオープンソース モデルには次のような特徴があることが示されたのは悲しい事実です。多くのコアシーンでパフォーマンスに一定のギャップが生じます。清華大学の OPT-175B、BLOOM-176B、GLM-130B などのオープンソースの大規模モデルは、OpenAI の InstructGPT、Microsoft/NVIDIA の TNLG-530B などを含むさまざまなタスクにおいて、非オープンソースの大規模モデルにほぼ完全に負けています (図を参照)。下に)。
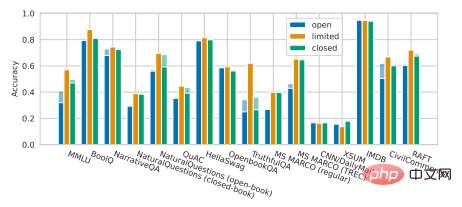
キャプション: Percy Liang et al. 言語モデルの総合的評価
##この恥ずかしい状況を解決するには、各リーダーが独自の高品質な大規模モデルをオープンソース化し、大規模モデルの分野における全体的な進歩がより早くより高いレベルに到達できるようにする必要があります。大規模モデルの産業実装に関しては、オープンソースが唯一の方法です。 GPT-3 のリリースを出発点として考えると、大規模なモデルは次のようになります。研究開発技術は比較的成熟していると思いますが、世界規模で見ると大型モデルの実用化はまだ初期段階にあります。国内大手メーカーが開発する大型モデルは、社内での事業導入シナリオはあるものの、全体としてはまだ成熟した商品化モデルを持っていない。 #大規模モデルの実装が勢いを増しているとき、オープンソースで適切な作業を行うことで、大規模な実装エコロジーの基礎を築くことができます。未来。 #大規模なモデルの性質によって、実装にオープンソースが必要かどうかが決まります。アリババ・ダモ・アカデミーの副所長、周静仁氏はAI Technology Reviewに対し、「大規模なモデルは人間の知識システムを抽象化して洗練させたものであるため、適用できるシナリオと生成される価値は膨大である。そしてオープンソースを通じてのみ、大規模なモデルは、多くのクリエイティブな開発者によってアプリケーションの可能性を最大限に引き出すことができます。 #これは、大規模モデルの内部技術的な詳細をクローズする API モデルでは実行できないことです。 まず、このモデルは、開発能力の低いモデル ユーザーに適しています。彼らにとって、大規模モデルの実装の成否は研究開発の手に完全に委ねられているのと同じです。機関。 大規模モデル API の有料サービスを提供する最大の勝者である OpenAI を例に挙げると、OpenAI の統計によると、世界中で 300 社以上の企業が利用しています。 GPT-3. テクノロジーのアプリケーションですが、この事実の前提は、OpenAI の研究開発力が強力であり、GPT-3 が十分に強力であるということです。モデル自体のパフォーマンスが悪い場合、そのような開発者は無力です。 #さらに重要なのは、大規模なモデルがオープン API を通じて提供できる機能が限られているため、複雑で多様なアプリケーション要件を処理することが困難になっているということです。現在、市場にはクリエイティブなアプリがいくつかあるだけですが、全体としてはまだ「おもちゃ」の段階にあり、大規模な産業化の段階には程遠いです。 「生成される価値はそれほど大きくなく、コストも回収できないため、GPT-3 API に基づくアプリケーション シナリオは非常に限られています。実際のところ、私はこのアプローチには同意しません」と張嘉興氏は語った。実際、copy.ai や Jasper などの外資系企業は、AI 支援ライティング ビジネスに取り組むことを選択しており、ユーザー市場が比較的大きいため比較的大きな商業価値を生み出すことができますが、小規模なアプリケーションが多くなります。 #対照的に、オープンソースは「人々に魚の釣り方を教える」ことを行います。 オープンソース モデルでは、企業はオープンソース コードを利用して、既存のビジネス ニーズに基づいたトレーニングや二次トレーニングを実施します。大型モデルの汎用性の利点を最大限に発揮できる開発は、現状のレベルをはるかに超える生産性を解放し、最終的には大型モデル技術の真の業界実装をもたらします。 現時点で大型モデルの商業化に向けた最も明確な道筋として、AIGC の離陸により大型モデルのオープンソース モデルの成功が確認されました。ただし、他のアプリケーション シナリオでは、大規模なモデルのオープンソースは国内外でまだ少数派です。西湖大学深層学習研究室の所長、Lan Zhenzhong 氏はかつて AI Technology Review に対し、大規模モデルに関する多くの結果があるものの、オープンソースは非常に少なく、一般の研究者がアクセスできるのは非常に残念である、と語った。 貢献、参加、コラボレーションこれらのキーワードを核とするオープンソースは、多数の情熱的な開発者を結集させ、潜在的に変革をもたらす可能性のある大規模な開発者を共同で作成することができます。モデル プロジェクトにより、大規模なモデルを研究室から産業に迅速に移行できるようになります。 大規模モデルにおけるオープンソースの重要性これはコンセンサスですが、オープンソースへの道には依然としてコンピューティング能力という大きな障害があります。 これは、大規模モデルの現在の実装が直面している最大の課題でもあります。 Meta は OPT をオープンソース化しましたが、これまでのところ、アプリケーション市場に大きな波紋を広げているようには見えません。最終的には、大規模なモデルの微調整はもちろん、小規模な開発者にとってコンピューティング能力のコストはまだ耐えられないのです。 , 推理するだけでも非常に難しいです。 このため、パラメータへの反省の波を受けて、多くの研究開発機関は、軽量モデルを作成し、パラメータを制御するというアイデアに目を向けるようになりました。モデルの数億から数十億まで。蘭州科技が発売した「Mencius」モデルとアイデア研究所がオープンソース化した「Fengshen Bang」シリーズのモデルは、いずれもこの路線の国内代表モデルである。彼らは、非常に大規模なモデルのさまざまな機能を比較的小さいパラメータを持つモデルに分割し、いくつかの単一タスクで数千億のモデルを超える能力を証明しました。 #しかし、大規模モデルへの道がここで止まらないことは間違いありません。多くの業界専門家が AI Technology Review に語ったところによると、大規模モデルのパラメータは次のとおりです。まだ改善の余地があり、誰かがより大規模なモデルを探索し続ける必要があります。したがって、私たちはオープンソースの大規模モデルのジレンマに直面しなければなりません。 まず、コンピューティング能力自体の観点から検討します。大規模なコンピュータ クラスタやコンピューティング パワー センターの構築は、今後確実にトレンドとなるでしょうが、結局のところ、末端のコンピューティング リソースでは需要を満たすことができません。しかし現在、ムーアの法則の勢いは鈍化しており、業界ではムーアの法則が終焉を迎えているという議論が後を絶たない。あなたの短期的な渇き。 「これで、1 枚のカードで (推論の観点から) 10 億のモデルを実行できるようになります。現在のコンピューティング能力の成長率によれば、1 枚のカードがカードは 1,000 億のモデルを実行できます。つまり、コンピューティング能力を 100 倍に高めるには 10 年かかる可能性があります。」と Zhang Jiaxing 氏は説明しました。 #大型モデルの発売が待ち遠しいですね。 もう 1 つの方向性は、大規模モデルの推論を高速化し、計算電力コストを削減し、エネルギー消費を削減して、大規模なモデルの推論を改善するためのトレーニング テクノロジについて大騒ぎすることです。使いやすさを追求したモデル。 たとえば、Meta の OPT (GPT-3 と比較して) では、完全なモデル コード ベースをトレーニングしてデプロイするために 16 個の NVIDIA v100 GPU のみが必要です。この数は 1 です。 GPT-3の7番目。最近、清華大学と Zhipu AI が共同でバイリンガル大型モデル GLM-130B を公開しましたが、高速推論手法により、このモデルは A100 (40G*8) または A100 (40G*8) でスタンドアロン推論に使用できる点まで圧縮されました。 V100(32G*8)サーバーです。 # もちろん、この方向に一生懸命取り組むのは理にかなっていますが、大手メーカーが大規模モデルのオープンソース化に消極的である理由は明らかです。料金。専門家らは以前、GPT-3 のトレーニングに数万個の Nvidia v100 GPU が使用され、総コストは最大 2,760 万米ドルに達すると見積もっていましたが、個人が PaLM をトレーニングしたい場合は、900 万から 1,700 万米ドルかかると考えられます。大規模モデルのトレーニングコストを削減できれば、オープンソースへの意欲も自然に高まります。 #しかし、最終的には、これはエンジニアリングの観点からコンピューティング リソースの制約を軽減できるだけで、究極の解決策ではありません。数千億、数兆レベルの大規模モデルの多くが「低エネルギー消費」の利点を宣伝し始めていますが、コンピューティング能力の壁は依然として高すぎます。 #最終的には、ブレークスルー ポイントを見つけるために大規模なモデル自体に戻る必要があります。非常に有望な方向性はスパースです。ダイナミックな大型モデル。 # 疎大モデルは非常に大容量であるという特徴がありますが、特定のタスク、サンプル、またはラベルの特定の部分のみがアクティブになります。言い換えれば、この疎な動的構造により、大規模なモデルのパラメータ量を莫大な計算コストを支払うことなく数レベル上げることができ、一石二鳥になります。これは、GPT-3 のような高密度の大規模モデルに比べて大きな利点です。GPT-3 では、最も単純なタスクでも完了するためにニューラル ネットワーク全体をアクティブにする必要があり、リソースが膨大に浪費されます。 Google はスパース動的構造のパイオニアであり、2017 年に初めて MoE (Sparsely-Gated Mixture-of-Experts Layer、スパースゲート エキスパート ミキシング レイヤー) を提案し、昨年 16,000 の MoE をリリースしました。 10 億パラメータの大規模モデル Switch Transformers には MoE スタイルのアーキテクチャが組み込まれており、以前の高密度モデル T5-Base Transformer と比較してトレーニング効率が 7 倍向上しました。 今年の PaLM のベースとなる Pathways 統合アーキテクチャは、スパース動的構造のモデルです。モデルは、ネットワークの特定の部分がどの部分に適しているかを動的に学習できます。タスクの場合、タスクを完了するためにニューラル ネットワーク全体をアクティブにすることなく、必要に応じてネットワークを介して小さなパスを呼び出すことができます。 #注: Pathways アーキテクチャ これは人間の脳の仕組みと本質的に似ています。人間の脳には数百億個のニューロンがありますが、特定のタスクを実行するときに特定の機能を持つニューロンだけが活性化されます。そうしないと、膨大なエネルギー消費が耐えられなくなります。 大規模で多用途で効率的なこの大規模モデルルートは、間違いなく非常に魅力的です。 「将来的にはスパースダイナミクスのサポートにより、計算コストはそれほど高くならないでしょう「しかし、モデルのパラメータは確実にますます大きくなり、疎な動的構造は大規模モデルに新しい世界を開く可能性があります。10 兆や 1,000 億に達しても問題はありません。」 Zhang Jiaxing 氏は、疎な動的構造は、大きなモデル サイズとコンピューティング能力の問題の解決策、コスト間の矛盾を解決する究極の道。しかし、この種のモデル構造がまだ一般的ではない場合、やみくもにモデルを大きくし続けることはあまり意味がないとも付け加えました。 #現時点では、この方向への国内の試みは比較的少なく、Google ほど徹底的ではありません。大規模モデル構造の探求と革新とオープンソースは相互に促進しており、大規模モデル技術の変化を刺激するにはさらに多くのオープンソースが必要です。 # 大規模モデルのオープンソースを妨げているのは、大規模モデルの計算能力コストによる可用性の低さだけでなく、セキュリティの問題もあります。 大規模モデル、特に大規模モデルのオープンソース化によってもたらされる悪用のリスクについては、海外からの懸念がさらに高まっているようで、多くの議論が巻き起こっています。これは、多くの機関が大規模モデルの認証情報をオープンソース化しないことを選択することになりましたが、それは寛大さに抵抗する言い訳にもなる可能性があります。 #OpenAI はこの点で多くの批判を集めています。 2019年にGPT-2をリリースしたとき、彼らはこのモデルのテキスト生成機能が強力すぎて倫理的危害を引き起こす可能性があり、オープンソースにはふさわしくないと主張した。 1 年後に GPT-3 がリリースされたときは、API トライアルのみが提供されましたが、現在の GPT-3 のオープンソース バージョンは、実際にはオープンソース コミュニティ自体によって再現されています。 #実際、大規模モデルへのアクセスを制限すると、大規模モデルの堅牢性の向上やバイアスと毒性の軽減に悪影響を及ぼします。 Meta AI の責任者である Joelle Pineau 氏は、OPT をオープンソースにする決定について語ったとき、テキスト生成プロセス中に発生する可能性のある倫理的偏見や悪意のある言葉など、自分のチームだけではすべての問題を解決することはできないと真摯に述べました。彼らは、十分な下調べが行われれば、責任を持って大規模なモデルを公的にアクセスできるようにできると信じています。 # 悪用のリスクを防ぎながらオープンアクセスと適切な透明性を維持することは簡単な作業ではありません。 「パンドラの箱」を開けた張本人として、Stability AI は積極的なオープンソースによって高い評価を得てきましたが、最近ではオープンソースの反動にも遭遇し、著作権所有権などの面で物議を醸しています。 オープンソースの背後にある「自由と安全」という弁証法的な古代の命題は、長い間存在していました。絶対に正しい答えはないかもしれませんが、大きなモデルの始まり 実装に向けて進むにつれて、明らかな事実は、大規模モデルのオープンソース化がまだ十分ではないということです。 2年以上が経過し、すでに独自の兆レベルの大規模モデルが完成しました。何千マイルも」、オープンソース これは避けられない選択です。 最近、GPT-4 が登場し、その機能の飛躍に誰もが大きな期待を寄せていますが、それがどのようになるかはわかりません。将来的には、何人でどれくらいの生産性が解放されるでしょうか? 03
耐えられない重さ: コンピューティングパワー

以上が大規模 AI モデルのオープンソースのジレンマ: 独占、壁、コンピューティング能力の悲しみの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
暗号通貨市場での突入は投資家の間でパニックを引き起こし、Dogecoin(Doge)は最も困難なヒット分野の1つになりました。その価格は急激に下落し、分散財務財務(DEFI)(TVL)の総価値が激しく減少しました。 「ブラックマンデー」の販売波が暗号通貨市場を席巻し、ドゲコインが最初にヒットしました。そのdefitVLは2023レベルに低下し、通貨価格は過去1か月で23.78%下落しました。 DogecoinのDefitVLは、主にSOSO値指数が26.37%減少したため、272万ドルの安値に低下しました。退屈なDAOやThorchainなどの他の主要なDefiプラットフォームも、それぞれ24.04%と20減少しました。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Binanceは、グローバルデジタルアセット取引エコシステムの大君主であり、その特性には次のものが含まれます。1。1日の平均取引量は1,500億ドルを超え、500の取引ペアをサポートし、主流の通貨の98%をカバーしています。 2。イノベーションマトリックスは、デリバティブ市場、Web3レイアウト、教育システムをカバーしています。 3.技術的な利点は、1秒あたり140万のトランザクションのピーク処理量を伴うミリ秒のマッチングエンジンです。 4.コンプライアンスの進捗状況は、15か国のライセンスを保持し、ヨーロッパと米国で準拠した事業体を確立します。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
