

drop() 関数は、特徴エンジニアリングを実行し、データ セットを分割するときに便利です。データ、演算列、演算行などを簡単に削除できます。
drop() の詳細な構文は次のとおりです。
行の削除はインデックス、列の削除は列です:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
パラメータ:
ラベル:削除される行または列のラベル (単一ラベルまたはラベルのリスト)。
axis: 削除する行または列の軸。0 は行、1 は列を意味します。
index: 削除する行のインデックス。単一のインデックスまたはインデックスのリストを指定できます。
columns: 削除する列の列名。単一の列名または列名のリストを指定できます。
inplace: 元の DataFrame で操作するかどうか。デフォルトは False で、元の DataFrame で操作が実行されないことを意味します。
使用シナリオ 1: 不要な機能を削除します。
例: 一部の特徴が結果にほとんど影響を与えない場合は、従属変数に関連しない独立変数を削除できます。多重共線性を回避するには、強い影響を与える独立変数を削除する必要があります。相関。
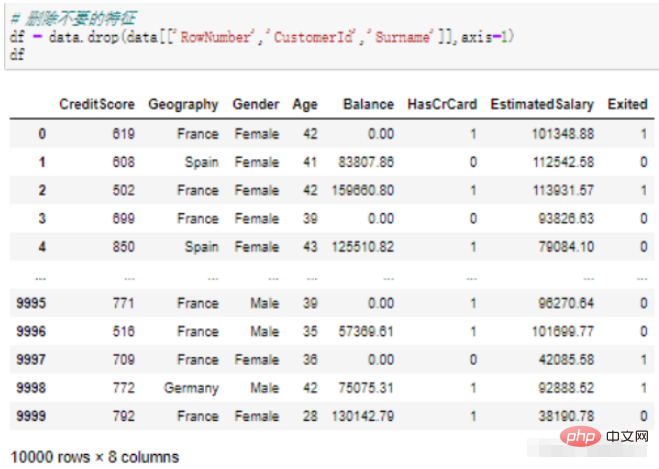
df = data.drop(data[['RowNumber','CustomerId','Surname']],axis=1) df
コードの説明:
data はデータ セットで、2 つの角かっこは、削除する 3 つのフィールドを除外する DataFrame 形式を表します。
axis=1 は、操作列;
実行結果:
使用シナリオ 2: 従属変数の削除
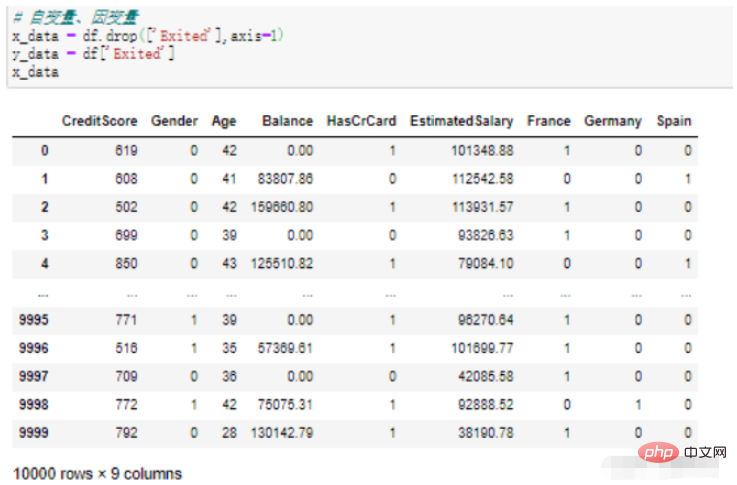
# 自变量、因变量 x_data = df.drop(['Exited'],axis=1) y_data = df['Exited'] x_data
コードの説明:
drop() 関数で削除するフィールドを入力します。これは、「Exited」という名前の列を df から削除することを意味します;
['Exited'] このフィールドは、削除したい従属変数です、単一のフィールドは次のことを意味します;
実行結果:
使用シナリオ 3: データ セットを分割するとき、トレーニング セットが生成され、トレーニング セットに割り当てられたサンプルが削除され、残りがテスト セットになります。
#划分训练集 train_data = data.sample(frac = 0.8, random_state = 0) #测试集 test_data = data.drop(train_data.index)
コードの説明:
drop() 関数に行インデックスを入力して行を削除します。
train_data は分割したトレーニング セット、train_data.index です。行インデックス ;
axis=0 を表します。これは、行を削除するか、行を書き込まないことを意味します。これがデフォルト値です。;
以上が行や列を削除するためのPythonのdrop()の操作メソッドは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



