

mysqlファントムリーディングとは何ですか?

mysql では、ファントム読み取りとは、ユーザーが特定の範囲のデータ行を読み取るときに、別のトランザクションがその範囲に新しい行を挿入することを意味します。ユーザーが範囲内のデータ行を読み取ると、新しい「ファントム」行です。いわゆるファントム読み取りとは、SELECT でクエリされたデータ セットが実際のデータ セットではないことを意味し、ユーザーは SELECT ステートメントを通じて、特定のレコードが存在しないが、実際のテーブルには存在する可能性があることをクエリします。

このチュートリアルの動作環境: Windows7 システム、mysql8 バージョン、Dell G3 コンピューター。
ファントム読み取りとは
まずトランザクションの分離レベルを見てみましょう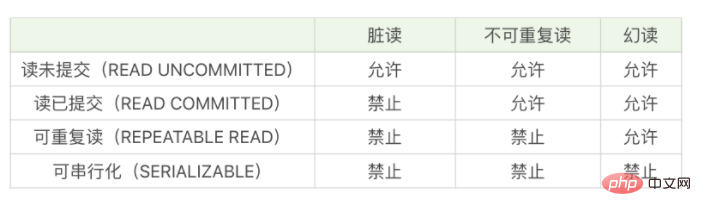
次に、ファントム リーディングについて話します その前に、ファントム リーディングについての私の理解を話させてください:
いわゆるファントム リーディングは、「ファントム」という言葉に焦点を当てています。本当でも嘘でも、まるで霧がかかったように、相手の姿が見えなくなり、人に錯覚を与える、これが「錯覚」です。いわゆるファントム読み取りとは、SELECT でクエリを実行したデータ セットが実際のデータ セットではないことを意味します。SELECT ステートメントでクエリを実行した特定のレコードは存在しませんが、実際のテーブルには存在する可能性があります。
これが、私がファントム・リーディングと反復不可能なリーディングを理解する方法です:
-
ファンタジー・リーディングは、それが存在するかどうかの問題です。それは存在しませんでした。以前は存在しませんでしたが、現在は存在します。存在する場合、それはファントム read -
Non-repeatable readは変更されない問題です。以前は A でしたが、現在は A になっています。 B、その場合、それは反復不可能な読み取りです
ファンタジーの読み取り、これまでのところ私が理解している理論は 2 つあります:
最初のステートメント: トランザクション A は、条件付きクエリに基づいて N 個のデータを取得しましたが、このとき、トランザクション B は、トランザクション A のクエリ条件を満たす M 個のデータを削除または追加します。 このように、トランザクション A が再度クエリを実行すると、実際のデータ セットは変更されましたが、A はこの変更をクエリできないため、錯覚が発生します。
このステートメントは、ファントム読み取りが特定の範囲内の多かれ少なかれデータ行によって引き起こされることを強調しており、異なるデータセットがファントム読み取りにつながることを強調しています。
ステートメント 2: ファントム読み取りは、2 つの読み取りによって得られた結果セットが異なることを意味するものではなく、ファントム読み取りの焦点は、特定の選択操作の結果によって表されます。データの状態ではその後の業務運用をサポートできません。具体的には、トランザクション A で、あるレコードが存在するかどうかを選択し、その結果、存在しないことがわかり、このレコードを挿入する準備が整いましたが、挿入を実行すると、このレコードはすでに存在していることがわかり、挿入できません。このときファントムリードが発生します。その理由は、別のトランザクションがテーブルにデータを挿入したためです。
個人的には最初のステートメントの方が好きです。
The 2 番目の引数もファントム読み取りです。2 番目の引数は、データ セットが変更されており、クエリによって取得されたデータ セットが実際のデータ セットと一致しないことを示します。
ステートメント 2 について: INSERT を実行する場合、暗黙的な読み取りも必要です。たとえば、データを挿入する場合、主キーの競合があるかどうかを読み取り、挿入を実行できるかどうかを判断する必要があります。このレコードが既に存在することが判明した場合は、挿入できません。したがって、SELECT では存在しないと表示されますが、INSERT では存在することがわかります。これは、条件を満たすデータ行が変更されたことを意味し、これがファントム読み取りの場合であり、非反復読み取りは、データの内容が変更されたことを意味します。同じレコードが変更されました。
例で説明します。 2 番目のステートメントは、次の状況について説明します。
2 つのトランザクション A と B があります。最初にトランザクションが開かれ、次に A は、次のようなデータがあるかどうかのクエリを開始します。 id = 30 in the data set. クエリ 結果は、データ内に id = 30 のデータが存在しないことを示しています。その直後、別のトランザクション B がオープンされ、トランザクション B は id = 30 のデータをテーブルに挿入し、トランザクションを送信しました。次に、A は、id = 30 のデータをテーブルに挿入し始めます。トランザクション B は既に id = 30 のデータを挿入しているため、挿入できません。その後、A が再度クエリを実行すると、テーブルに id = 30 のデータが存在しないことがわかります。 table. 、トランザクション A は非常に混乱していますが、データを挿入できないのはなぜですか?トランザクション A が送信された後、再度クエリを実行すると、ID = 30 のデータがテーブルに存在することがわかります。しかし、トランザクション A が送信される前に、それを知ることができなかったのですか?
実際、これは 繰り返し読める読書 の役割です。
プロセスを次の図に示します。

上図で操作される t テーブルの作成ステートメントは次のとおりです。
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
MySQL で使用される InnoDB エンジンのデフォルトの分離レベルは Repeatable Read です。これは、同じトランザクション内で同じクエリを 2 回実行しても、結果は同じになるはずであることを意味します。したがって、トランザクション A が終了する前にトランザクション B がテーブルにデータを追加しましたが、反復読み取りを維持するために、新しく追加されたデータは、トランザクション A でどのようにクエリしてもクエリできません。しかし、実際のテーブルでは、テーブル内のデータは確かに増加しています。
A查询不到这个数据,不代表这个数据不存在。查询得到了某条数据,不代表它真的存在。这样是是而非的查询,就像是幻觉一样,似真似假,故为幻读。
产生幻读的原因归根到底是由于查询得到的结果与真实的结果不匹配。
幻读 VS 不可重复读
幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。
可重复读隔离下为什么会产生幻读?
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在 当前读 下才会出现。
什么是快照读,什么是当前读?
快照读读取的是快照数据。不加锁的简单的 SELECT都属于快照读,比如这样:
SELECT * FROM player WHERE ...
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
说多了,我们继续来看,如下的操作都会进行 当前读。
SELECT * FROM player LOCK IN SHARE MODE; SELECT * FROM player FOR UPDATE; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
说白了,快照读就是普通的读操作,而当前读包括了 加锁的读取 和 DML(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
比如在可重复读的隔离条件下,我开启了两个事务,在另一个事务中进行了插入操作,当前事务如果使用当前读 是可以读到最新的数据的。

MySQL中如何实现可重复读
当隔离级别为可重复读的时候,事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View。也就是说:对于A事务而言,不管其他事务怎么修改数据,对于A事务而言,它能看到的数据永远都是第一次SELECT时看到的数据。这显然不合理,如果其它事务插入了数据,A事务却只能看到过去的数据,读取不了当前的数据。
既然都说到 Read View 了,就不得不说 MVCC (多版本并发控制) 机制了。MVCC 其实字面意思还比较好理解,为了防止数据产生冲突,我们可以使用时间戳之类的来进行标识,不同的时间戳对应着不同的版本。比如你现在有1000元,你借给了张三 500 元, 之后李四给了你 500 元,虽然你的钱的总额都是 1000元,但是其实已经和最开始的 1000元不一样了,为了判断中途是否有修改,我们就可以采用版本号来区分你的钱的变动。
如下,在数据库的数据表中,id,name,type 这三个字段是我自己建立的,但是除了这些字段,其实还有些隐藏字段是 MySQL 偷偷为我们添加的,我们通常是看不到这样的隐藏字段的。

我们重点关注这两个隐藏的字段:
db_trx_id: このデータ行を操作するトランザクション ID、つまり、データを挿入または更新した最後のトランザクション ID。トランザクションを開始するたびに、データベースからトランザクション ID (トランザクションのバージョン番号) が取得されますが、このトランザクション ID は自己増加し、ID のサイズによってトランザクションの時系列を判断できます。
db_roll_ptr: このレコードの Undo Log 情報を指すロールバック ポインター。アンドゥログとは何ですか?特定のレコードを変更する必要がある場合、MySQL は将来その変更が取り消されて前の状態にロールバックされることを懸念しているため、変更する前に現在のデータをファイルに保存してから変更する必要があることがわかります。 . Undo Log このアーカイブファイルとして理解できます。これはゲームをプレイするときと同じで、一定のレベルに到達したら、ファイルを保存してから次のレベルに挑戦し、次のレベルに挑戦できなかった場合は、セーブポイントに戻るのではなく、前のセーブポイントに戻ります。ゼロから始める。
MVCC (複数バージョン同時実行制御) メカニズムでは、同じ行レコードを更新する複数のトランザクションによって複数の履歴スナップショットが生成され、これらの履歴スナップショットは Undo Log ## に保存されます。 # 内部。次の図に示すように、現在の行に記録されている ロールバック ポインタ はその前の状態を指し、その前の状態のロールバック ポインタはその前の状態の前の状態を指します。このようにして、理論的には、ロールバック ポインタ をトラバースすることで、データ行のあらゆる状態を見つけることができます。
Undo ログの概略図
Read View メカニズムを使用する必要があります。 Read View は、現在のトランザクションが開かれているときに、すべてのアクティブな (まだコミットされていない) トランザクションのリストを保存します。
- trx_ids、システムで現在アクティブなトランザクション ID のコレクション
- low_limit_id、アクティブなトランザクションの最大のトランザクション ID
- up_limit_id、アクティブなトランザクションの最小のトランザクション ID
- creator_trx_id、この Read View のトランザクション ID
db_trx_id があり、このデータ行を操作するトランザクション ID を表します。 トランザクション ID は自己増加するため、ID のサイズによってトランザクションの時系列を判断できます。 トランザクションを開始し、特定のレコードをクエリする準備をすると、そのレコードの
db_trx_id< up_limit_id がわかります。これは何を意味しますか?これは、このレコードは、このトランザクションが開始される前に送信されている必要があることを意味します。現在のトランザクションでは、これは履歴データであり、参照できます。したがって、select を通じてこのレコードを確実に見つけることができます。 ただし、見つかった場合は、レコードの
db_trx_id> up_limit_id が照会されます。これはどういう意味ですか? それは、トランザクションを開いたとき、このレコードはまだ存在していないはずです。後で作成されたもので、現在のトランザクションには表示されないはずです。この時点では、 ロール ポインターを介して戻ることができます。 Undo Log はレコードの履歴バージョンを検索し、それを現在のトランザクションに返します。この記事では ファントムリーディングとは? この章では例を示します。トランザクション A が開始されたとき、データベースにはレコード (30, 30, 30) がありません。トランザクションAが開始された後、トランザクションBはデータベースにレコード(30, 30, 30)を挿入しますが、このときトランザクションAはロックを行わずにselectを使用しますからを読み取るときスナップショットでは、この新しく挿入されたレコードをクエリすることはできません。これは予想どおりです。トランザクション A の場合、このレコードの db_trx_id (30, 30, 30) は、トランザクション A の開始時に up_limit_id より大きくなければならないため、このレコードはトランザクション A によって認識されるべきではありません。 。 クエリ対象のレコードの trx_id
が条件up_limit_id < trx_id < low_limit_id を満たしている場合、現在の creator_trx_id トランザクションが作成されたときに、この行が記録されているトランザクション trx_id がまだアクティブである可能性があるため、これを trx_ids コレクションで行う必要があることを示します。トラバーサルでは、trx_id が trx_ids コレクションに存在する場合、トランザクション trx_id がまだアクティブであり、表示されていないことが証明されます。レコードに Undo ログがある場合は、次のことができます。 pass ロールバック ポインタをたどって、レコードの履歴バージョン データをクエリします。 trx_id が trx_ids コレクションに存在しない場合は、トランザクション trx_id が送信され、行レコードが表示されていることを証明します。
从图中你能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。
最后,再来强调一遍:事务只在第一次 SELECT 的时候会获取一次 Read View
因此,如下图所示,在 可重复读 的隔离条件下,在该事务中不管进行多少次 以WHERE heigh > 2.08为条件 的查询,最终结果得到都是一样的,尽管可能会有其它事务对这个结果集进行了更改。

如何解决幻读
即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。
为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。
表 t 主键索引上的行锁和间隙锁
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
- 间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。也就是说,我们的表 t 初始化以后,如果用
SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。 - 间隙锁是在可重复读隔离级别下才会生效的
怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。
如下图所示,如果在事务A中执行了SELECT * FROM t WHERE d = 5 FOR UPDATE以后,事务B则无法插入数据了,因此就避免了产生幻读。
数据表的创建语句如下
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
需要注意的是,由于创建数据表的时候仅仅只在c字段上创建了索引,因此使用条件WHERE id = 5查找时是会扫描全表的。因此,SELECT * FROM t WHERE d = 5 FOR UPDATE实际上锁住了整个表,如上图所示,产生了七个间隙,这七个间隙都不允许数据的插入。
因此当B想插入一条数据(1, 1, 1)时就会被阻塞住,因为它的主键位于位于(0, 5]这个区间,被禁止插入。
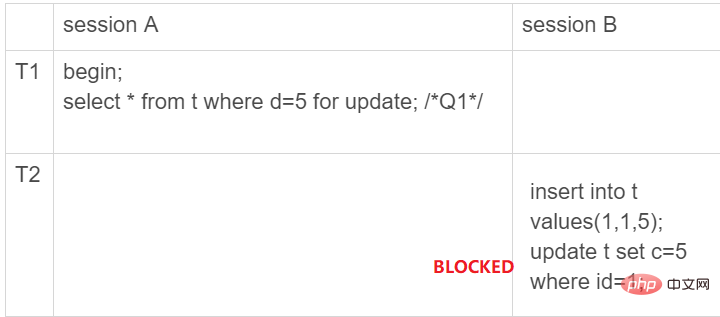
还需要注意的一点是,间隙锁和间隙锁是不会产生冲突的。读锁(又称共享锁,S锁)和写锁会冲突,写锁和写锁也会产生冲突。但是间隙锁和间隙锁是不会产生冲突的
如下:
A事务对id = 5的数据加了读锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁则会成功。读锁和读锁可以兼容,读锁和写锁则不能兼容。
A事务对id = 5的数据加了写锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁同样也会失败。
在加了间隙锁以后,当A事务开启以后,并对(5, 10]这个区间加了间隙锁,那么B事务则无法插入数据了。

但是当A事务对(5, 10]加了间隙锁以后,B事务也可以对这个区间加间隙锁。
ギャップ ロックの目的は、この間隔にデータが挿入されるのを防ぐことです。したがって、トランザクション A が追加された後、トランザクション B はギャップ ロックを追加し続けます。これは矛盾しません。ただし、書き込みロックと読み取りロックでは異なります。
書き込みロックでは他のトランザクションによる読み取りまたは書き込みが許可されませんが、読み取りロックでは書き込みが許可されるため、セマンティックの競合が発生します。当然のことながら、これら 2 つのロックを同時に追加することはできません。
同じことが、書き込みロックと書き込みロックにも当てはまります。書き込みロックでは、読み取りも書き込みも許可されません。考えてみましょう。トランザクション A は、データに書き込みロックを追加します。これは、他のトランザクションがそのデータに対して操作することを望まないことを意味します。このデータに書き込みロックを追加することは、データに対して操作を実行することと同じであり、書き込みロックの意味に違反するため、当然許可されません。
[関連する推奨事項: mysql ビデオ チュートリアル ]
以上がmysqlファントムリーディングとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7685
7685
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
