

画像前処理ライブラリ CV-CUDA はオープンソースであり、前処理のボトルネックを解消し、推論スループットを 20 倍以上向上させます。

今日の情報化時代において、画像やビジュアル コンテンツは長い間、日常生活における最も重要な情報伝達手段となってきました。深層学習モデルは、ビジュアル コンテンツを理解するその強力な能力に依存しており、さまざまな処理と最適化を行うことができます。
ただし、これまでのビジュアル モデルの開発と適用では、モデル自体の最適化により速度と効果を向上させることに重点を置いていました。それどころか、画像の前処理段階と後処理段階では、画像を最適化する方法についてはほとんど考慮されていません。したがって、モデルの計算効率がますます高くなっているときに、画像の前処理と後処理を振り返ってみると、それらが画像タスク全体のボトルネックになっているとは予想していませんでした。
このようなボトルネックを解決するために、NVIDIA は ByteDance 機械学習チームと協力して、多くの画像前処理オペレーター ライブラリ CV-CUDA をオープンソース化しました。これらは GPU 上で効率的に実行でき、オペレーターの速度は OpenCV の速度に達します。 (CPU上で実行)約100回。 OpenCV と TorchVision を置き換えるバックエンドとして CV-CUDA を使用すると、推論全体のスループットは元の 20 倍以上に達する可能性があります。また、速度の向上だけでなく効果の点でも、CV-CUDAは計算精度においてOpenCVと一致しているため、学習と推論をシームレスに接続することができ、エンジニアの負担を大幅に軽減します。
画像の背景ぼかしアルゴリズムを例に挙げると、CV-CUDA は画像のプリ/ポストのバックエンドとして OpenCV を置き換えます。 -processing を使用すると、推論プロセス全体のスループットを 20 倍以上に向上させることができます。
#高速かつ優れたビジュアル前処理ライブラリを試してみたい場合は、このオープン ソース ツールを試してみてください。 オープンソースアドレス: https://github.com/CVCUDA/CV-CUDA
画像の前処理/後処理は CV ボトルネック
エンジニアリングや製品に携わる多くのアルゴリズム エンジニアは、私たちはモデル構造やトレーニング タスクなどの「最先端の研究」についてのみ議論することが多いものの、信頼性の高い製品を構築するには、その過程で多くのエンジニアリング上の問題が発生しますが、モデルのトレーニングが最も簡単な部分です。
画像の前処理は工学的な問題です。実験やトレーニング中に画像の幾何学的変換、フィルタリング、色変換などを実行するためにいくつかの API を呼び出すだけで、特に気にする必要はないかもしれません。しかし、推論プロセス全体を再考すると、特に複雑な前処理プロセスを伴う視覚的なタスクの場合、画像の前処理がパフォーマンスのボトルネックになっていることがわかります。
このようなパフォーマンスのボトルネックは主に CPU に反映されます。一般的に、従来の画像処理プロセスでは、最初に CPU で前処理を実行し、次にそれを GPU に配置してモデルを実行し、最後に CPU に戻り、場合によっては後処理を実行する必要があります。
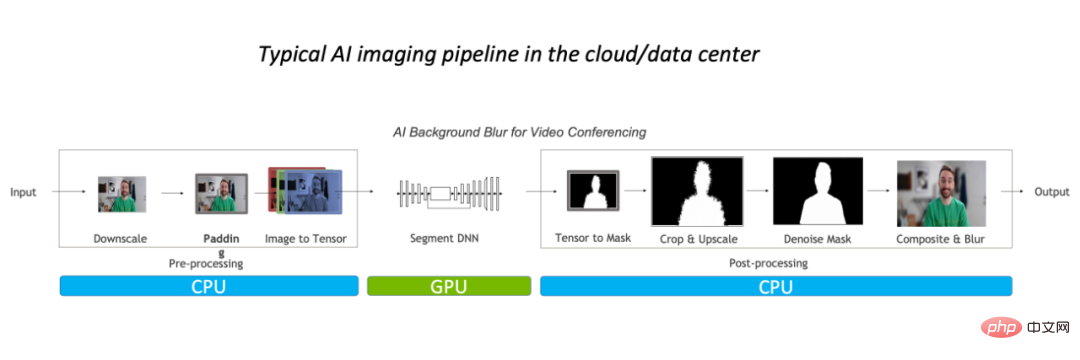
# 画像の背景ぼかしアルゴリズムを例に取ると、従来の画像処理プロセスでは主に予測処理が完了します。 CPU がワークロードの 90% 全体を占有しており、タスクのボトルネックになっています。
ビデオ アプリケーションや 3D 画像モデリングなどの複雑なシーンの場合、画像フレームまたは画像情報の数が十分に大きいため、前処理プロセスは十分に複雑になります。レイテンシー要件が十分に低い場合は、前処理/後処理オペレーターの最適化が差し迫っています。もちろん、より良いアプローチは、OpenCV をより高速なソリューションに置き換えることです。
OpenCV がまだ十分ではないのはなぜですか? CV で最も広く使用されている画像処理ライブラリは、もちろん長年維持されている OpenCV であり、画像処理の範囲が非常に広く、基本的にさまざまなビジュアルに対応できます。タスク。前処理/後処理が必要です。しかし、画像タスクの負荷が増加するにつれて、OpenCV の画像操作のほとんどが CPU によって実装され、GPU 実装が不足していたり、GPU 実装に問題が発生したりするため、その速度が徐々に追いつかなくなりました。
NVIDIA および ByteDance アルゴリズムの学生の研究開発経験では、OpenCV の GPU によって実装されたいくつかの演算子に 3 つの大きな問題があることがわかりました。- 一部のオペレーターの CPU と GPU の結果の精度を調整できません;
- 一部のオペレーターの GPU パフォーマンスは、 CPU パフォーマンス;
- さまざまな CPU オペレーターとさまざまな GPU オペレーターが同時に存在します。処理プロセスで両方を同時に使用する必要がある場合、追加のスペース アプリケーションと要件が必要になります。データ移行/データコピー;
たとえば、最初の質問の結果の精度を揃えることはできません。 NVIDIA および ByteDance アルゴリズムの学生は、トレーニング中に OpenCV の特定のオペレーターが CPU を使用することに気づくでしょうが、推論段階でのパフォーマンスの問題により、代わりに OpenCV に対応する GPU オペレーターが使用されます。 GPU の結果を調整することができず、推論プロセス全体で精度に異常が発生します。このような問題が発生すると、CPU 実装に戻すか、精度を再調整するために多大な労力を費やす必要があり、対処が難しい問題です。
OpenCV はまだ十分ではないため、読者の中には、Torchvision はどうなるのでしょうか?と尋ねる人もいるかもしれません。実際には、OpenCV と同じ問題に直面します。さらに、モデルをデプロイするエンジニアは、効率化のために推論プロセスの実装に C を使用する可能性が高いため、Torchvision を使用できず、C ビジョン ライブラリに頼る必要があります。これにより、Torchvision の精度を OpenCV と調整するという別のジレンマが生じます。
一般に、現在の CPU 上でのビジュアル タスクの前後処理がボトルネックになっていますが、OpenCV などの従来のツールではこれをうまく処理できません。したがって、演算を GPU に移行し、完全に CUDA に基づいて実装された効率的な画像処理演算子ライブラリである CV-CUDA を使用することが、新しいソリューションになりました。
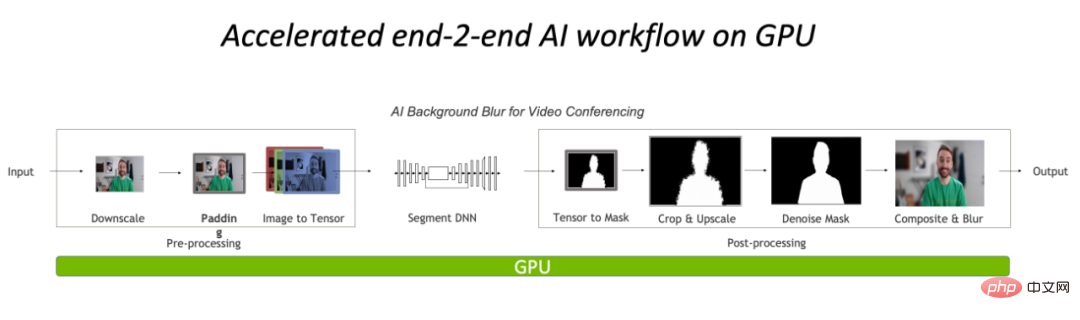
前処理と後処理をすべて GPU 上で実行することで、画像処理部分の CPU ボトルネックが大幅に軽減されます。 。
GPU 画像処理高速化ライブラリ: CV-CUDA
CUDA ベースとしてプリプロセッサ / ポストプロセッシング オペレータ ライブラリにおいて、アルゴリズム エンジニアは、十分な速度、十分な汎用性、そして使いやすさという 3 つのことを最も期待しているかもしれません。 NVIDIA と ByteDance の機械学習チームが共同開発した CV-CUDA は、GPU の並列計算能力を利用してオペレーターの速度を向上させ、OpenCV の演算結果を十分に汎用性のあるものに調整し、簡単に使用できるという 3 つのポイントを正確に満たしています。 C/Python インターフェイス。
CV-CUDA の速度
CV-CUDA速度はまず効率的なオペレーターの実装に反映されますが、結局のところ、NVIDIA によって書かれたものであり、CUDA 並列計算コードには多くの最適化が行われているはずです。次に、GPU デバイスの計算能力を最大限に活用できるバッチ操作をサポートしており、CPU 上で画像をシリアル実行する場合と比較して、バッチ操作は確実に高速です。最後に、CV-CUDA が適応している Volta、Turing、Ampere などの GPU アーキテクチャのおかげで、パフォーマンスは各 GPU の CUDA カーネル レベルで高度に最適化され、最良の結果が得られます。言い換えれば、使用する GPU カードが優れているほど、その加速能力はさらに強化されます。
前の背景ブラー スループット加速率のグラフに示されているように、CV-CUDA を使用して OpenCV と TorchVision の前処理と後処理を置き換えると、推論プロセス全体のスループットが 20 倍以上増加します。このうち、前処理は画像に対して Resize、Padding、Image2Tensor などの操作を実行し、後処理は予測結果に対して Tensor2Mask、Crop、Resize、Denoise などの操作を実行します。
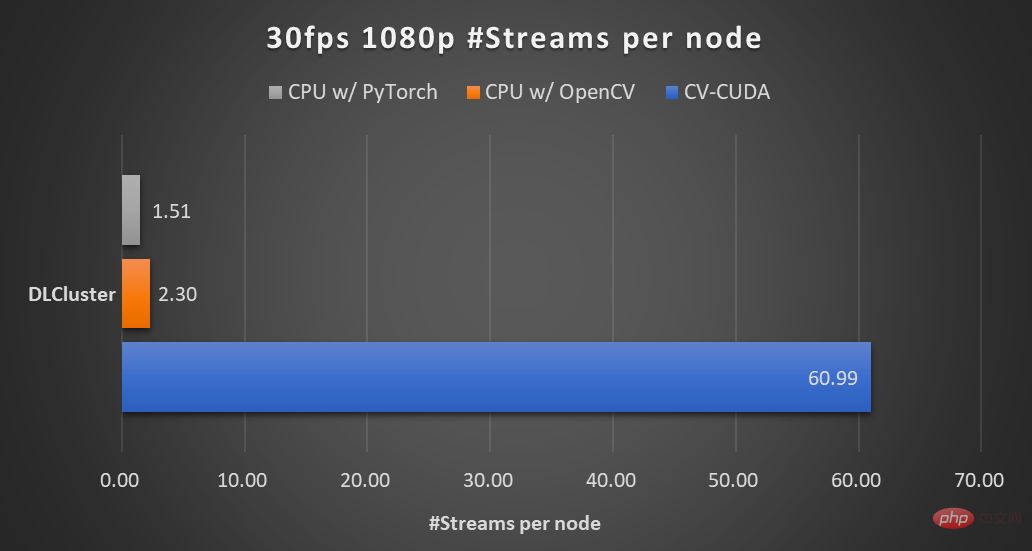
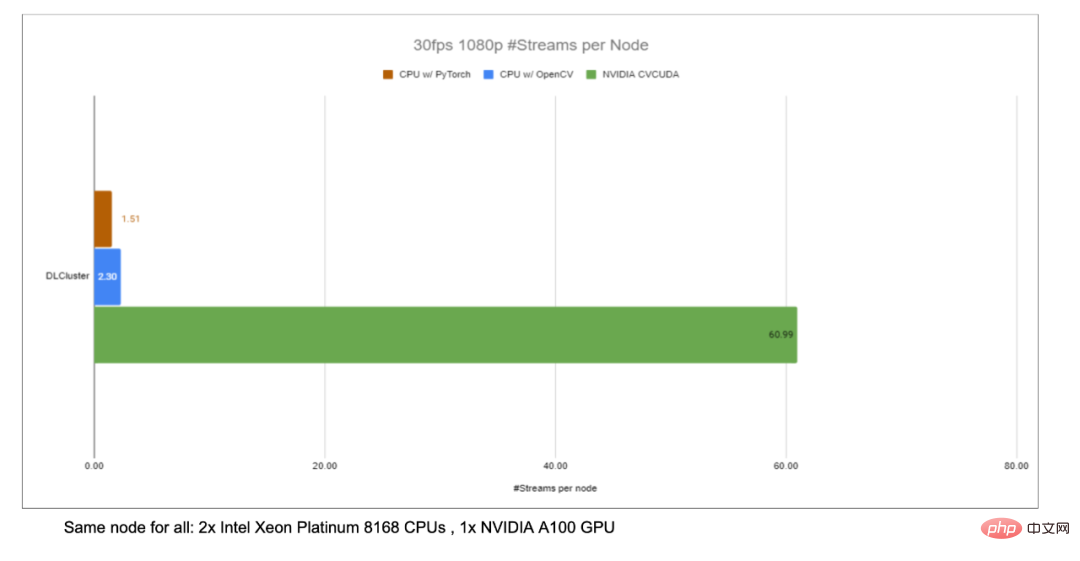
#同じコンピューティング ノード (Intel Xeon Platinum 8168 CPU 2 基、NVIDIA A100 GPU 1 基) 上で、プロセスさまざまな CV ライブラリでサポートされている最大数の並列ストリームを使用した、30 fps の 1080p ビデオ。テストでは 4 つのプロセスが使用され、各プロセスのバッチサイズは 64 です。 単一オペレーターのパフォーマンスに関しては、NVIDIA と ByteDance のパートナーもパフォーマンス テストを実施しており、GPU 上の多数のオペレーターのスループットは CPU のスループットの 100 倍に達する可能性があります。 . .
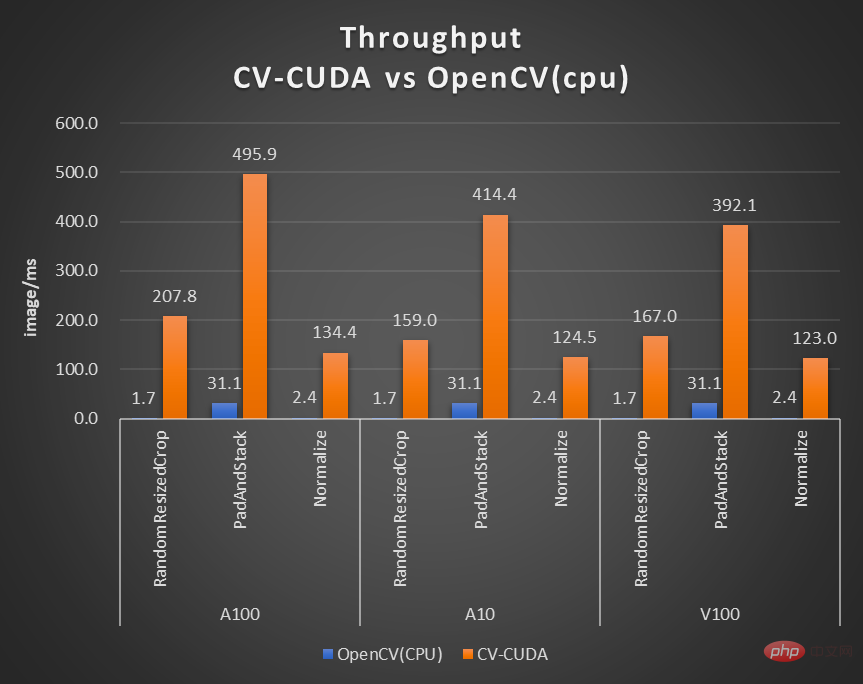
#画像サイズは 480*360、CPU は Intel(R) Core(TM) i9-7900X、BatchSize サイズは 1、プロセス数は 1
前処理/後処理演算子の多くは単純な行列の乗算などの演算ではありませんが、上記の効率的なパフォーマンスを実現するために、CV-CUDA は実際に多くの処理を行っています。オペレーターレベルでの最適化。たとえば、カーネルの起動とグローバル メモリのアクセス時間を短縮するために多数のカーネル フュージョン戦略が採用されており、メモリ アクセスはデータの読み取りと書き込みの効率を向上させるために最適化されており、すべてのオペレータは同期待機時間を短縮するために非同期的に処理されています。 。
##CV-CUDA の汎用的で柔軟な操作
#実際のプロジェクトでは、結果の安定性が非常に重要です。たとえば、一般的なサイズ変更操作、OpenCV、OpenCV-gpu、Torchvision は異なる方法で実装されているため、トレーニングからデプロイメントまで、結果を調整するためにさらに多くの作業が必要になります。 。 CV-CUDAの設計当初は、多くの技術者が現在の画像処理ライブラリのCPU版OpenCVの使用に慣れていると考えられていたため、演算子を設計する際には関数パラメータであっても画像処理であってもその結果、OpenCV のオペレーターの CPU バージョンを可能な限り揃えます。したがって、OpenCV から CV-CUDA に移行する場合、一貫したコンピューティング結果を得るために必要な変更はわずかであり、モデルを再トレーニングする必要はありません。 また、CV-CUDAはオペレータレベルで設計されているため、モデルの前後処理プロセスがどのようなものであっても自由に組み合わせることができ、柔軟性が高いです。
ByteDance 機械学習チームは、企業内には多くのモデルがトレーニングされており、必要な前処理ロジックも多様で、多くのカスタマイズされた前処理ロジック要件があると述べました。 CV-CUDA の柔軟性により、各 OP がストリーム オブジェクトとビデオ メモリ オブジェクト (ビデオ メモリ ポインタを内部的に格納する Buffer クラスと Tensor クラス) の受信を確実にサポートできるため、対応する GPU リソースをより柔軟に構成できます。各オペレーションを設計および開発する際には、汎用性を考慮するだけでなく、画像前処理のさまざまなニーズをカバーするカスタマイズされたインターフェイスもオンデマンドで提供します。
CV-CUDA の使いやすさ
エンジニアは、CV-CUDA には基礎となる CUDA オペレーターが関与するため、使用がより困難になるはずだと考えるでしょう。しかしそうではなく、上位 API に依存しなくても、CV-CUDA の最下層自体が や Allocator クラスなどの構造を提供するので、C で調整するのはそれほど面倒ではありません。さらに、上位レベルに進むと、CV-CUDA は PyTorch、OpenCV、および Pillow 用のデータ変換インターフェイスを提供するため、エンジニアは使い慣れた方法でオペレーターをすぐに交代したり呼び出すことができます。 さらに、CV-CUDA には C インターフェイスと Python インターフェイスの両方があるため、トレーニングとサービス展開シナリオの両方で使用できます。Python インターフェイスはトレーニング中にモデルの機能を迅速に検証するために使用され、C インターフェイスはより効率的な展開のために使用されます。 CV-CUDA は、煩雑な前処理結果の調整プロセスを回避し、プロセス全体の効率を向上させます。
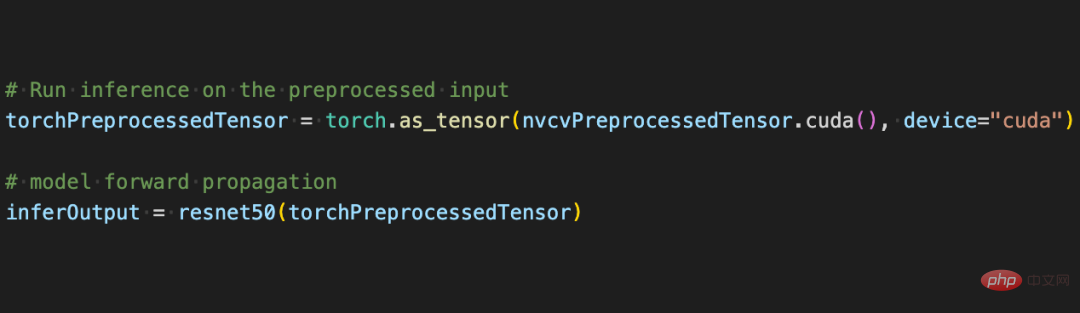
#サイズ変更用の CV-CUDA C インターフェイス 実践的な戦闘、CV-CUDA
使い方訓練プロセス中に CV-CUDA の Python インターフェイスを使用すると、実際には非常に簡単になります。を使用するには、最初に CPU で実行されたすべての前処理操作を GPU に移行するための簡単な手順をいくつか行うだけです。
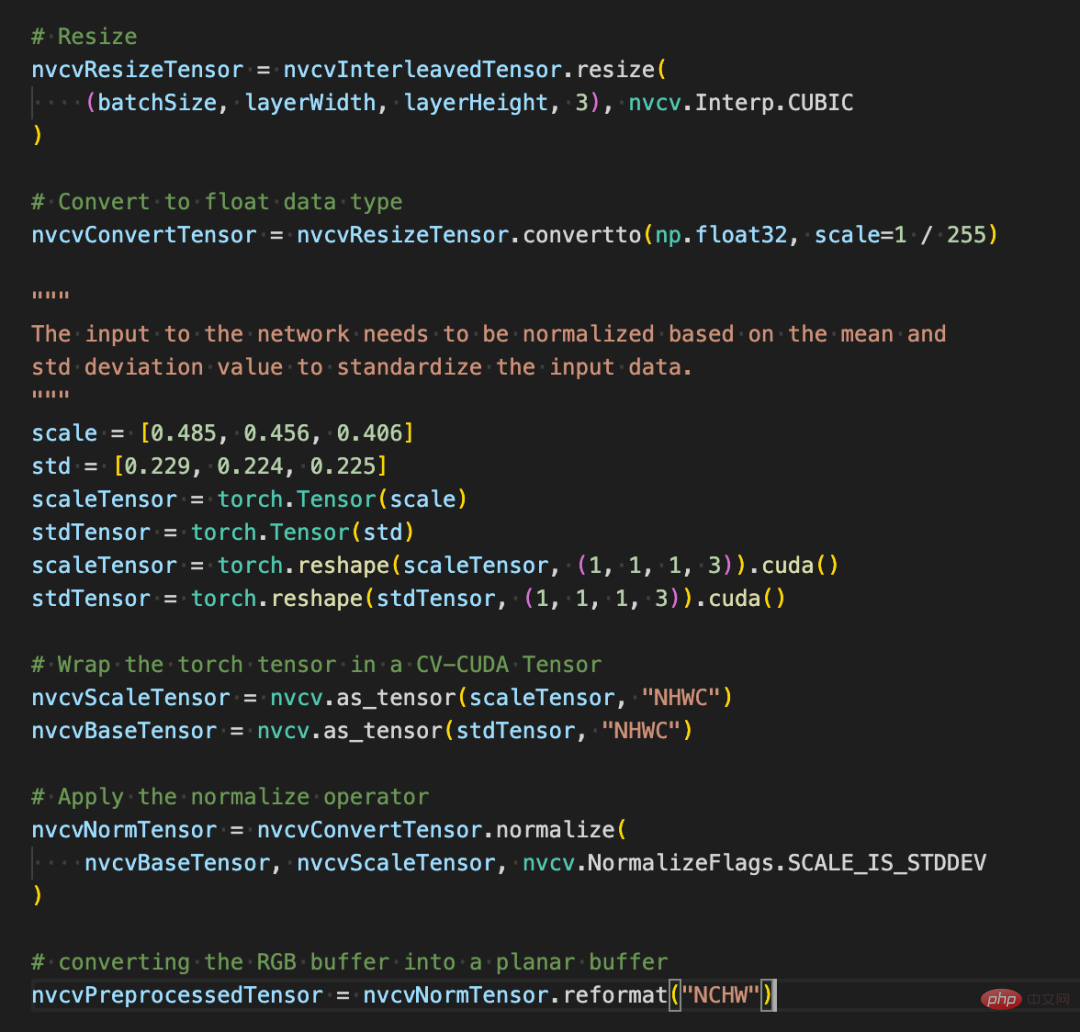
画像分類を例にとると、基本的には前処理段階で画像をテンソルにデコードし、モデルの入力サイズに合わせてトリミングする必要があります。トリミング後、ピクセル値を浮動小数点データ型に変換する必要があります正規化後、順伝播のために深層学習モデルに渡すことができます。以下では、いくつかの簡単なコード ブロックを使用して、CV-CUDA がどのように画像を前処理し、Pytorch と対話するかを体験します。

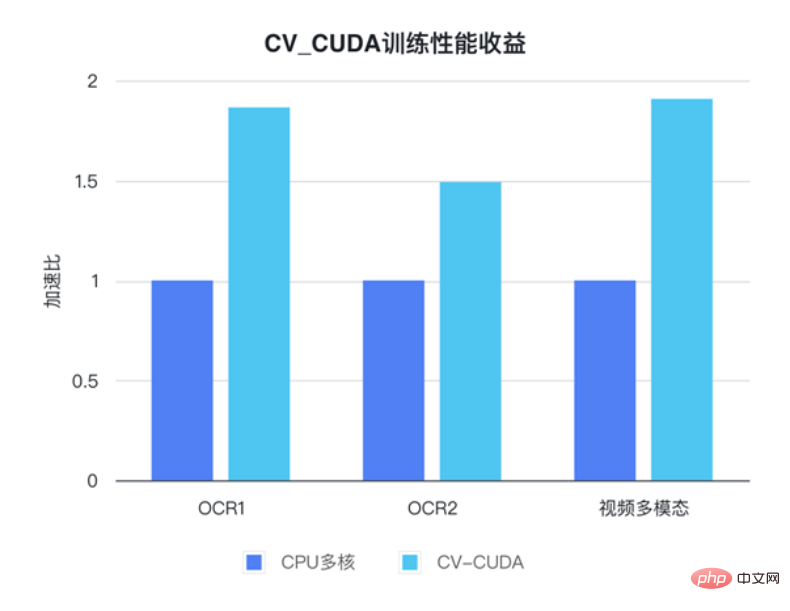
以下のように、torchvision API を使用して画像を GPU にロードした後、Torch Tensor タイプを as_tensor を通じて CV-CUDA オブジェクト nvcvInputTensor に直接変換できるため、CV の API CUDA の前処理操作を直接呼び出すことができ、画像のさまざまな変換が GPU 内で完了します。 次のコード行は CV-CUDA を使用して、GPU での画像認識の前処理プロセスを完了します。画像を作成し、ピクセルを正規化します。このうち、resize() は画像テンソルをモデルの入力テンソル サイズに変換し、convertto() はピクセル値を単精度浮動小数点値に変換し、normalize() はピクセル値を正規化して値の範囲をモデルの入力テンソル サイズに変換します。模型、電車。 CV-CUDA 各種前処理の使い方はOpenCVやTorchvisionと大きく変わりませんが、方法を簡単に調整するだけで、背後のGPU上ですでに処理が完了しています。 #これで、CV-CUDA のさまざまな API を利用して、画像分類タスクの前処理が完了しました。 GPU 上で並列コンピューティングを効率的に完了でき、PyTorch などの主流の深層学習フレームワークのモデリング プロセスに簡単に統合できます。残りについては、CV-CUDA オブジェクト nvcvPreprocessedTensor をトーチ テンソル タイプに変換してモデルにフィードするだけです。このステップも非常に簡単です。変換には 1 行のコードのみが必要です: この単純な例を通して、CV-CUDA が実際に通常のモデル トレーニング ロジックに簡単に埋め込まれることが簡単にわかります。読者が使用方法の詳細を知りたい場合は、上記の CV-CUDA のオープンソース アドレスを確認できます。 CV-CUDA は実際に実際の業務改善テストを実施しました。ビジュアルタスク、特に比較的複雑な画像前処理プロセスを伴うタスクでは、前処理に GPU の膨大な計算能力を使用することで、モデルのトレーニングと推論の効率を効果的に向上させることができます。 CV-CUDA は現在、Douyin Group 内のマルチモーダル検索、画像分類などの複数のオンラインおよびオフラインのシナリオで使用されています。 ByteDance 機械学習チームは、CV-CUDA の内部使用によりトレーニングと推論のパフォーマンスが大幅に向上すると述べました。たとえば、トレーニングの観点から見ると、ByteDance はビデオ関連のマルチモーダル タスクであり、前処理部分にはマルチフレーム ビデオのデコードと大量のデータ拡張が含まれており、この部分のロジックは非常に複雑になっています。前処理ロジックが複雑なため、トレーニング中に CPU のマルチコア パフォーマンスが追いつかないため、CV-CUDA を使用して CPU 上のすべての前処理ロジックを GPU に移行し、全体のトレーニング速度が 90% 高速化されました。これは前処理部分だけでなく、全体的なトレーニング速度の向上であることに注意してください。 同じことが推論プロセスにも当てはまります。学習チームは、検索マルチモーダル タスクで CV-CUDA を使用した後、前処理に CPU を使用した場合と比較して、全体的なオンライン スループットが 2 倍以上向上したと述べています。ここでの CPU ベースラインの結果はマルチコア向けに高度に最適化されており、このタスクに含まれる前処理ロジックは比較的単純ですが、CV-CUDA を使用した後の高速化効果は依然として非常に明白であることに注意してください。 この速度は、ビジュアル タスクの前処理のボトルネックを解消するのに十分効率的であり、シンプルかつ柔軟に使用できます。CV-CUDA は、実際のアプリケーション シナリオにおけるモデル推論とトレーニング効果を大幅に向上できることが証明されています。 ' 視覚的なタスクも前処理の効率によって制限されるため、最新のオープンソース CV-CUDA を試してください。 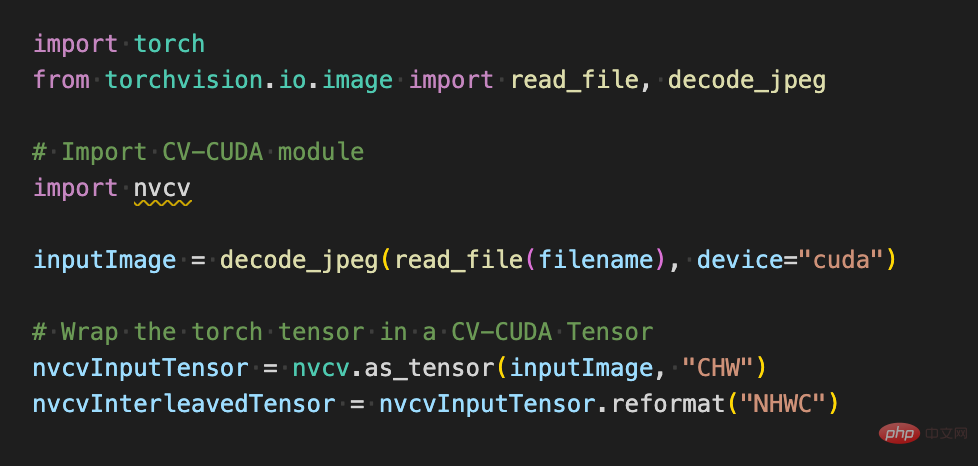
実際の業務改善
以上が画像前処理ライブラリ CV-CUDA はオープンソースであり、前処理のボトルネックを解消し、推論スループットを 20 倍以上向上させます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
