

Javaで要素がコレクション内にあるかどうかをすばやく判断する方法

1. ブルーム フィルターとは何ですか?
ブルーム フィルターは、1970 年にブルームという名前の人によって提案されました。
実際には、バイナリ ベクトル (またはビット配列) と一連のランダム マッピング関数 (ハッシュ関数) で構成されるデータ構造として見ることができます。
長所はスペース効率とクエリ時間が通常のアルゴリズムよりも優れていることですが、短所は一定の誤認識率と削除の難しさです。

#2. 実装原理
まずは写真を撮りましょう

ブルーム フィルター アルゴリズム メインn 個のハッシュ関数を使用してハッシュを実行し、異なるハッシュ値を取得するというアイデアです。ハッシュに従って、それらは配列の異なるインデックス位置にマッピングされ (この配列の長さは非常に長い場合があります)、対応するインデックス ビットは次のようになります。 on の値は 1 に設定されます。
要素がセットに含まれるかどうかを判断するには、k 個の異なるハッシュ関数を使用してハッシュ値を計算し、ハッシュ値の対応するインデックス位置の値が 1 であるかどうかを確認します。 not 1 は、要素がコレクションに存在しないことを示します。
ただし、この要素はセットに含まれているが、要素はセットに含まれていないと判断することも可能です。この要素のすべてのインデックス位置の上の 1 は他の要素によって設定されているため、一定の確率で誤判定が発生します。 (これが、上記がライブである理由です。特定のハッシュの競合が発生するため、根本的な原因はコレクションにある可能性があります)。
注: 誤検知率が低いほど、対応するパフォーマンスも低下します。
3. 機能
ブルーム フィルターは、要素が (おそらく) セット内にあるかどうかを判断するために使用でき、他のデータ構造と比較して、ブルーム フィルターには両方に大きな利点があります。空間と時間。
上の言葉に注意してください: 可能です。ここには保留されたサスペンスがあり、それについては以下で詳細に分析します。
指定されたデータが存在するかどうかの判定
キャッシュ侵入防止(キャッシュを直接バイパスしてデータベースを要求することを避けるために、要求されたデータが有効かどうかを判定)など、メールボックススパムフィルタリング、ブラックリスト機能、など待ってください。
4. 具体的な実装
ブルームフィルターのアルゴリズムの考え方を読んだ後、具体的な実装について説明していきます。
まず例を挙げます。Wangcai と Xiaoqiang という 2 つの文字列があるとします。これらはそれぞれ 3 回ハッシュされ、対応する配列のインデックス (配列の長さが 16 であると仮定します) が次の値に基づいて計算されます。ハッシュ結果の位置の値は 1 に設定されます。まず Wangcai というフレーズを見てみましょう:
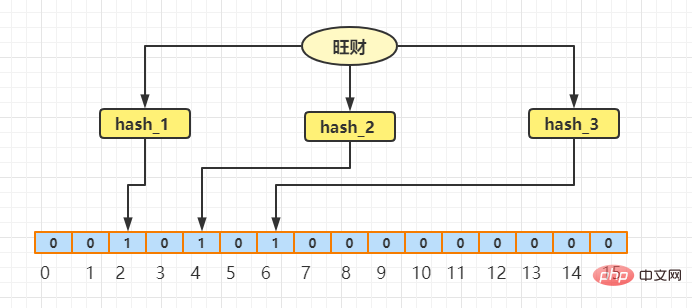
Wangcai を 3 回ハッシュした後の値インデックス値はそれぞれ 2、4、6 であるため、配列のインデックス (2、4、6) 位置の値は 1 に設定されます。 、残りは 0 とみなされます。 ここで、Wangcai を見つける必要があり、これらの 3 つのハッシュも通過すると、インデックス 2、4、および 6 に対応する位置の値がすべて 1 であることがわかります。 、その場合、豊かな富が存在する可能性があると判断できます。
続いてブルームフィルターにXiaoqiangを挿入します。実際の処理は上記と同じです。得られた添字が1、3、5
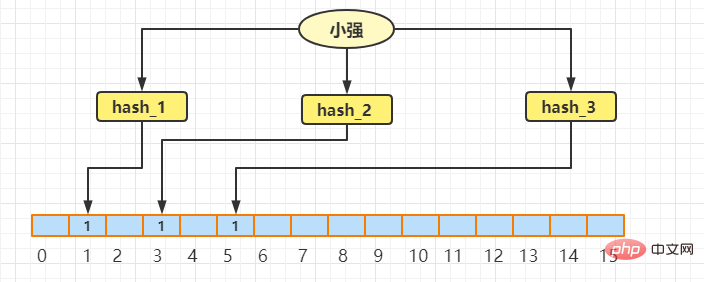
 # データができました: 9527現在の要件は、9527 が存在するかどうかを判断することです。9527 を 3 回ハッシュして得られた添え字が 5、6、7 であると仮定します。添字7の位置の値は0であることが分かり、9527は存在しないはずであると判断できます。
# データができました: 9527現在の要件は、9527 が存在するかどうかを判断することです。9527 を 3 回ハッシュして得られた添え字が 5、6、7 であると仮定します。添字7の位置の値は0であることが分かり、9527は存在しないはずであると判断できます。
次に、別の国内の 007 が来ました。 3 つのハッシュの後、得られた添え字は 2、3、および 5 でした。添え字 2、3、および 5 に対応する値はすべて 1 であることが判明しました。なのでおおよそ国内の007は存在する可能性があると判断されます。しかし、実際には、先ほどのデモンストレーションの後、国内の 007 はまったく存在せず、インデックス位置 2、3、5 の値が 1 になっているのは、他のデータ設定によるものです。
そういえば、ブルームフィルターの役割を皆さんは理解されているでしょうか。
5. コードの実装
Java プログラマとして、私たちは本当に満足しています。私たちは多くのフレームワークやツールを使用していますが、それらは基本的にカプセル化されています。ブルーム フィルター、Google によってパッケージ化されたツール クラスを使用します。 。もちろん、他の方法も検討できます。
まず依存関係を追加します
<!--布隆过滤依赖-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>コード実装
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterDemo {
public static void main(String[] args) {
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
* 不存在一定不存在
* 存在不一定存在
* ----------------
* Funnel 对象:预估的元素个数,误判率
* mightContain :方法判断元素是否存在
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("死");
bloomFilter.put("磕");
bloomFilter.put("Redis");
System.out.println(bloomFilter.mightContain("Redis"));
System.out.println(bloomFilter.mightContain("Java"));
}
}具体的な説明はコメントに書いてあります。もう、誰もがブルーム フィルターとその使用方法を理解しているはずだと思います。
6. 実践的な戦闘
このシナリオをシミュレートしてみましょう: ブルーム フィルターによるキャッシュの侵入を解決します。
まず、キャッシュペネトレーションとは何かご存知ですか?
キャッシュの侵入とは、ユーザーがキャッシュまたはデータベースにないデータにアクセスすることを意味します。キャッシュには存在しないため、同時実行性が高い場合はデータベースにアクセスします。データベースを破るのは簡単です
それでは、ブルーム フィルターはこの問題をどのように解決するのでしょうか?彼###
的原理是这样子的:将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
其代码如下:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}以上がJavaで要素がコレクション内にあるかどうかをすばやく判断する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29



 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
