

中国のチームががん患者に適した薬剤を予測するAIの開発に成功し、その結果がネイチャーサブジャーナルに掲載された。

たった 1 つの AI で、9,808 人のがん患者の薬剤に対する臨床反応を完全に予測できます。
そして、結果は臨床観察と一致しています。
これは、ニューヨーク市立大学の Lei Xie のチームによってもたらされた CODE-AE (コンテキスト認識型脱交絡オートエンコーダー) の最新の成果です。

これは、薬物に対するさまざまな患者の特定の反応を予測できる、新しいコンテキスト自動エンコード モデルを提案します。
これは新薬開発と臨床試験に重大な影響を及ぼします。
従来のモデルでは、新薬の開発、試験、完全市販までに 10 年近くかかり、消費される資金は前例のない巨額で、ゆうに 10 億米ドルに達することを知っておく必要があります。
新薬の人体での反応は予測が難しく、テストには繰り返しの試行が必要になることが多いため、サイクルが非常に長くなります。
AI がデータを使用して予測できるようになれば、新薬の市場投入までの時間が大幅に短縮され、コストが削減されます。
現在、この研究はNatureサブジャーナル「Nature Machine Intelligence」に掲載されています。
簡単に言うと、CODE-AE は、新薬の in vitro 細胞検証のデータを使用して、人体内での薬剤の反応を予測します。
これにより、AI モデルのトレーニングが患者の臨床データに依存することが回避されます。
これまで AI が臨床反応予測にあまり効果的でなかった最大の理由は、大量かつ継続的な臨床反応データを収集することが難しすぎるためです。
メカニズムの観点から、研究者は薬物バイオマーカーをソースドメインとターゲットドメインに分割します。
ソース ドメインはテスト サンプルとは異なるドメインを表しますが、インビトロ細胞検証データとして理解できる豊富な監視情報が含まれています。
ターゲット ドメインは、テスト サンプルが配置されているドメインであり、ラベルがないか、少数のラベルしかありません (患者データ)。
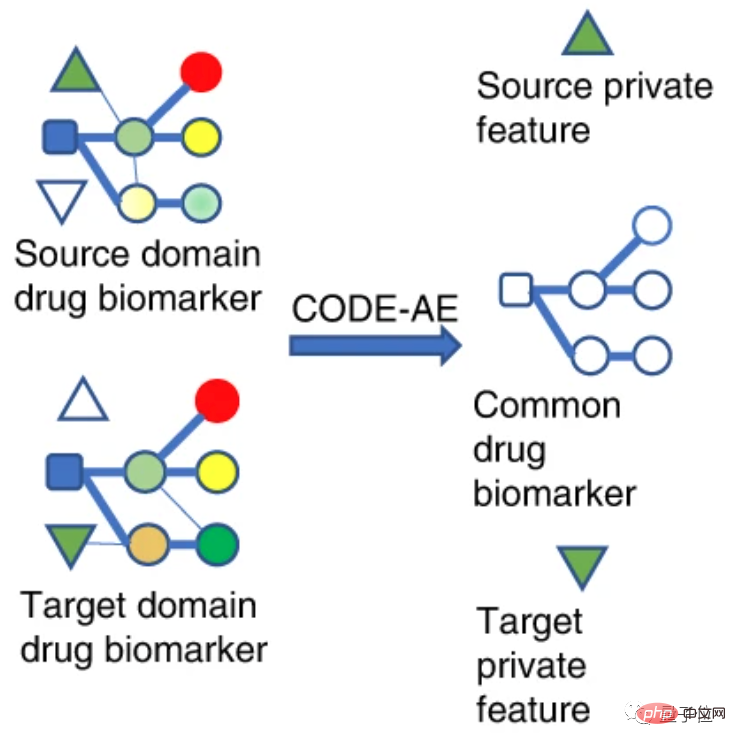
異なるフィールドのデータ特徴を同じ特徴空間にマッピングして、この空間内での距離ができるだけ近くなるようにします。
したがって、特徴空間内のソース ドメインでトレーニングされた目的関数をターゲット ドメインに転送して、ターゲット ドメインの精度を向上させることができます。
この研究の文脈では、ソースドメインとターゲットドメインは両方とも薬物バイオマーカーのデータ特性、つまり薬物ターゲットのデータ特性です。
モデル フレームワークを具体的に見ると、主に事前トレーニング、微調整、推論の 3 つの部分に分かれています。
事前トレーニングでは主に自己教師あり学習を使用して、インビトロ細胞データと患者データの標識されていない遺伝子発現プロファイルを埋め込み空間にマッピングする特徴エンコードモジュールを構築します。このようにして、いくつかの交絡因子を排除し、2 つのデータの潜在的な分布を一貫して系統的な偏りを排除することができます。
微調整段階では、事前トレーニングに基づいて教師ありモデルを追加し、ラベル付きの in vitro 細胞データをトレーニングに使用します。
最後に、推論段階では、事前トレーニングから取得した患者が最初に曖昧さが解消されて埋め込まれ、次に調整されたモデルを使用して薬物に対する患者の反応が予測されます。

このモードでは、CODE-AE には 2 つの特徴があります。
まず、インコヒーレントなサンプルに含まれる共通の生物学的信号とプライベートな表現を抽出できるため、さまざまなデータ パターンによって引き起こされる干渉を排除できます。
第二に、薬物応答シグナルと交絡因子を分離した後、局所的なアライメントも達成できます。
要約すると、CODE-AE は、ラベル付きデータとラベルなしデータのインコヒーレントなデータ パターン埋め込み空間内で固有の特徴を選択するプロセスとして理解できます。
モデルの有効性を実証するために、研究者らは9,808人のがん患者の薬剤適合性を予測した。
患者の状態のモデルによって予測された部位の結果が、患者が使用する薬剤標的に関連している場合、予測が正しいことが証明されます。
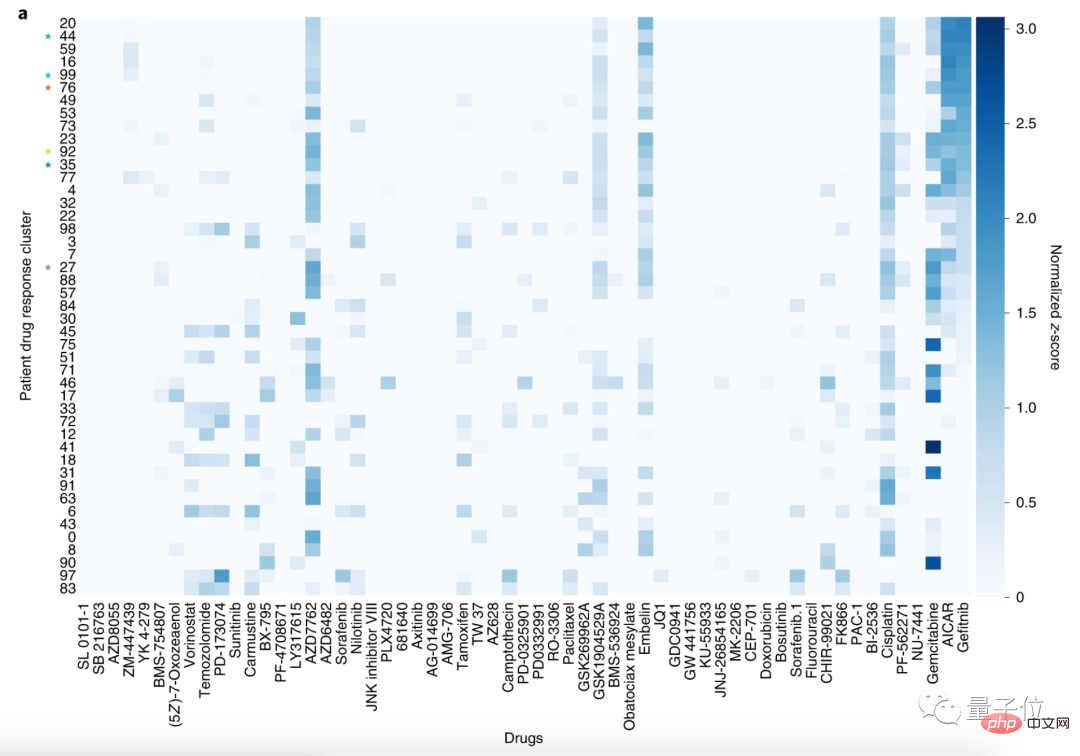
研究者らはその後、患者を 100 のクラスターに分け、59 種類の薬剤を 30 のクラスターに分けました。
この分析方法により、同様の薬物反応プロファイルを持つ患者をグループ化できます。
ここでは、肺扁平上皮癌 (LSCC) と非小細胞肺癌 (NSCLC) の患者のクラスター化を例に挙げます。
59 の薬剤の中で、LSCC に対して最も感受性の高い薬剤は、ゲフィチニブ、AICAR、ゲムシタビンです。
ゲフィチニブとAICARの標的はどちらも上皮成長因子受容体(EGFR)であり、ゲムシタビンはEGFR変異のない非小細胞肺がんの治療によく使用されます。
論文では、これらの薬剤の作用機序と一致して、ゲフィチニブとAICARを使用した患者は同様の薬剤反応プロファイルを有することがCODE-AEで判明したと述べられています。
言い換えれば、CODE-AE は患者治療の正しいターゲットを発見しました。つまり、適用可能な薬剤を予測できます。
上記の研究チームはニューヨーク市立大学の出身です。
責任著者は、中国科学技術大学で高分子物理学を卒業したLei Xie氏です。
彼はラトガース大学でコンピュータ サイエンスの修士号を取得して卒業し、博士号もラトガース大学で取得しましたが、化学の学位を取得しました。

研究チームの次のステップは、新薬の臨床反応の濃度と代謝に関する CODE-AE の予測機能を開発することであると理解されています。
研究者らは、AI モデルは人体に対する薬の副作用を予測するためにも応用できる可能性があると述べています。
Nature のサブジャーナル「Nature Machine Intelligence」は、人工知能と生命科学の学際的な応用研究に特化しており、毎年平均掲載論文数が約 60 件であることは注目に値します。
論文アドレス: https://www.nature.com/articles/s42256-022-00541-0
参考リンク: https://phys.org/news/2022-10 -ai-accurately-human-response-drug.html
以上が中国のチームががん患者に適した薬剤を予測するAIの開発に成功し、その結果がネイチャーサブジャーナルに掲載された。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
