

自動運転システムを実装するためにPythonを学ぶ


インストール環境
gym は強化学習アルゴリズムの開発と比較を行うためのツールキットで、Python で Gym ライブラリとそのサブシナリオをインストールするのは比較的簡単です。
ジムのインストール:
pip install gym
自動運転モジュールをインストールします。ここでは、Edouard Leurent が github で公開したパッケージ Highway-env を使用します:
pip install --user git+https://github.com/eleurent/highway-env
これには 6 つのシーンが含まれています:
- 高速道路 - "highway-v0"
- 合流 - "merge-v0"
- ラウンドアバウト交差点 - "roundabout-v0"
- 駐車場 - " parking-v0"
- 交差点 - "intersection-v0"
- レーシング トラック - "racetrack-v0"
詳細 ドキュメントはここにあります:
https://www.php.cn/link/c0fda89ebd645bd7cea60fcbb5960309
構成環境
インストールされたら、コードで実験を行うことができます(高速道路のシーンを例にします):
import gym
import highway_env
%matplotlib inline
env = gym.make('highway-v0')
env.reset()
for _ in range(3):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, done, info = env.step(action)
env.render()
実行後、シミュレータで次のシーンが生成されます:
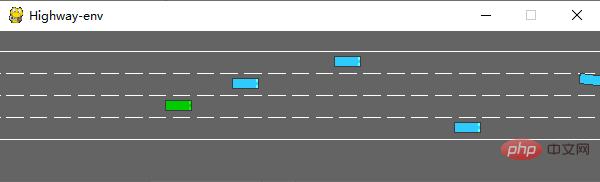
env クラスには多くのものが含まれます。設定可能なパラメータ詳細についてはオリジナルドキュメントを参照してください。
トレーニング モデル
1. データ処理
(1)状態
highway-env パッケージにはセンサーが定義されておらず、すべての状態 (車両のデータはすべて基礎となるコードから読み取られるため、多くの予備作業が省かれます。ドキュメントによると、状態 (観察) には、キネマティクス、グレースケール イメージ、占有グリッドという 3 つの出力方法があります。
運動学
V*F の行列を出力します。V は観察する必要がある車両の数 (自我車両自体を含む) を表し、F は観察する必要がある特徴の数を表します。数えられる。例:
データが生成されると、デフォルトで正規化されます。値の範囲は: [100, 100, 20, 20]です。また、自車車両以外の車両属性を地図の絶対座標または自車両の相対座標 相対座標。
環境を定義するときは、機能のパラメーターを設定する必要があります:
config =
{
"observation":
{
"type": "Kinematics",
#选取5辆车进行观察(包括ego vehicle)
"vehicles_count": 5,
#共7个特征
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
グレースケール イメージ
W*H のグレースケール イメージを生成します (W は幅を表します)。 H は画像の高さを表します
占有グリッド
WHF の 3 次元行列を生成し、W*H テーブルを使用して自車の周囲の車両状況を表します。グリッドには F フィーチャが含まれています。
(2) action
Highway-env パッケージのアクションは、連続アクションと離散アクションの 2 種類に分かれています。連続アクションはスロットルとステアリング角度の値を直接定義できます、離散アクションには 5 つのメタ アクションが含まれます:
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) 報酬
Highway-env パッケージは駐車シーンを除くすべてを使用します同じ報酬関数:

この関数はソース コード内でのみ変更でき、重みは外側の層でのみ調整できます。
(駐車シーンの報酬関数は元のドキュメントに含まれています)
2. モデル
DQN ネットワークを構築します。最初の状態表現方法である運動学を使用します。デモンストレーション用です。状態データの量が少ないため (5 車 * 7 特徴)、CNN の使用を無視して、2 次元データのサイズ [5,7] を [1,35] に直接変換できます。モデルは 35 です。出力は個別のアクションの数、合計 5 です。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0# epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
3. 実行結果
すべてのパーツが完成したら、それらを組み合わせてモデルをトレーニングします。プロセスは CARLA のプロセスと似ているため、詳細は説明しません。
初期化環境 (DQN クラスを追加するだけ):
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config =
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
トレーニング モデル:
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300)#随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
実行プロセス中にコードにいくつかの描画関数を追加しました。主要な指標を設定し、40 回のトレーニングごとに平均値を計算します。
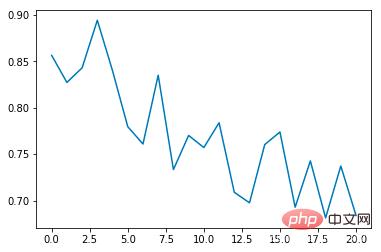
平均衝突率:
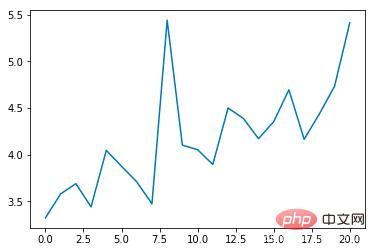
平均エポック期間 (秒):
平均報酬:
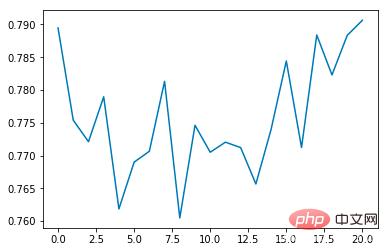
トレーニング回数が増加するにつれて、平均衝突発生率は徐々に減少し、各エポックの継続時間は徐々に延長されることがわかります (衝突が発生した場合) 、エポックはすぐに終了します)
概要
シミュレーター CARLA と比較して、highway-env 環境パッケージは大幅に抽象化されており、アルゴリズムをトレーニングできるようにゲームのような表現を使用しています。理想的な仮想環境でデータ取得方法、センサーの精度、計算時間などの現実的な問題を考慮する必要はありません。エンドツーエンドのアルゴリズムの設計とテストには非常に適していますが、自動制御の観点から見ると、開始する要素が少なく、研究にはあまり柔軟性がありません。
以上が自動運転システムを実装するためにPythonを学ぶの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7807
7807
 15
1646
14
1402
52
1300
25
1236
29
15
1646
14
1402
52
1300
25
1236
29

 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 OKXオンラインOKX Exchange公式Webサイトオンライン
Apr 22, 2025 am 06:45 AM
OKXオンラインOKX Exchange公式Webサイトオンライン
Apr 22, 2025 am 06:45 AM
OKX Exchangeの詳細な紹介は次のとおりです。1)開発履歴:2017年に設立され、2022年にOKXと改名。 2)セイシェルに本社を置く。 3)ビジネススコープは、さまざまな取引製品をカバーし、350を超える暗号通貨をサポートしています。 4)ユーザーは200か国以上に広がっており、数千万人のユーザーがいます。 5)ユーザー資産を保護するために、複数のセキュリティ対策が採用されています。 6)取引手数料はマーケットメーカーモデルに基づいており、取引量の増加とともに料金率が低下します。 7)「今年の暗号通貨交換」など、多くの栄誉を獲得しました。
 主要な仮想通貨取引プラットフォームのための特別なサービスのリスト
Apr 22, 2025 am 08:09 AM
主要な仮想通貨取引プラットフォームのための特別なサービスのリスト
Apr 22, 2025 am 08:09 AM
機関投資家は、Coinbase ProやGenesis Tradingなどの準拠したプラットフォームを選択して、コールドストレージ比と監査の透明性に焦点を当てる必要があります。小売投資家は、ユーザーのエクスペリエンスとセキュリティに焦点を当てて、BinanceやHuobiなどの大規模なプラットフォームを選択する必要があります。コンプライアンスに敏感な分野のユーザーは、サークルトレードとHuobiグローバルを通じてフィアット通貨取引を行うことができ、中国本土のユーザーは、コンプライアンスな店頭チャネルを通過する必要があります。
 バルクトランザクション用の仮想通貨取引プラットフォームのトップ10の最新リリース
Apr 22, 2025 am 08:18 AM
バルクトランザクション用の仮想通貨取引プラットフォームのトップ10の最新リリース
Apr 22, 2025 am 08:18 AM
バルク取引プラットフォームを選択する際には、次の要因を考慮する必要があります。1。流動性:平均1日の取引量が50億米ドルを超えるプラットフォームに優先順位が与えられます。 2。コンプライアンス:プラットフォームが、米国のFincen、欧州連合のMICAなどのライセンスを保持しているかどうかを確認します。 3。セキュリティ:コールドウォレットの保管比と保険メカニズムが重要な指標です。 4。サービス機能:独占的なアカウントマネージャーとカスタマイズされたトランザクションツールを提供するかどうか。
 複数の通貨をサポートする上位10の仮想通貨取引プラットフォームのリスト
Apr 22, 2025 am 08:15 AM
複数の通貨をサポートする上位10の仮想通貨取引プラットフォームのリスト
Apr 22, 2025 am 08:15 AM
OKXやCoinbaseなどの準拠プラットフォームが優先され、多要素検証が可能になり、資産の自己義が依存関係を削減できます。 2。2FAのホワイトリストをオンにし、引き出します。 3.ハードウェアウォレットまたは自立をサポートするプラットフォームを使用します。
 デジタル通貨取引アプリに簡単にアクセスできるように推奨されるトップ10(最新のランキング25)
Apr 22, 2025 am 07:45 AM
デジタル通貨取引アプリに簡単にアクセスできるように推奨されるトップ10(最新のランキング25)
Apr 22, 2025 am 07:45 AM
gate.io(グローバルバージョン)コアアドバンテージは、インターフェイスがミニマリストであり、中国語をサポートしており、フィアット通貨取引プロセスが直感的であることです。 Binance(Simpliedバージョン)コアの利点は、世界の取引量が世界で最初であり、シンプルなバージョンモデルがスポット取引のみを保持することです。 OKX(Hong Kongバージョン)コアアドバンテージは、インターフェイスがシンプルで、広東/マンダリンをサポートし、派生取引のしきい値が低いことです。 Huobi Global Station(Hong Kongバージョン)コアアドバンテージは、それが古い取引所であり、Meta-Universe Tradingターミナルを発売することです。 Kucoin(Chinese Community Edition)コアアドバンテージは、800通貨をサポートしており、インターフェイスがWeChatの相互作用を採用していることです。 Kraken(Hong Kongバージョン)コアアドバンテージは、香港SVFライセンスを保持しており、シンプルなインターフェイスを持っている古いアメリカの交換であることです。ハッシュキーエクスチェンジ(香港ライセンス)コアアドバンテージは、香港で有名な認可された取引所であり、法律を支持しています
 通貨サークル2025の上位10の市場Webサイトのヒントと推奨事項
Apr 22, 2025 am 08:03 AM
通貨サークル2025の上位10の市場Webサイトのヒントと推奨事項
Apr 22, 2025 am 08:03 AM
国内のユーザー適応ソリューションには、コンプライアンスチャネルとローカリゼーションツールが含まれます。 1。コンプライアンスチャネル:サークルトレードなどのOTCプラットフォームを介したフランチャイズ通貨交換、国内では、香港や海外のプラットフォームを通過する必要があります。 2。ローカリゼーションツール:Currency Circleネットワークを使用して中国の情報を取得し、Huobi Global Stationはメタユニバース取引端末を提供します。
 デジタル通貨交換アプリ向けのトップ10のAppleバージョンダウンロードポータルの概要
Apr 22, 2025 am 09:27 AM
デジタル通貨交換アプリ向けのトップ10のAppleバージョンダウンロードポータルの概要
Apr 22, 2025 am 09:27 AM
さまざまな複雑な取引ツールと市場分析を提供します。 100か国以上をカバーし、1日の平均デリバティブ取引量は300億米ドルを超え、300を超える取引ペアと200倍のレバレッジをサポートし、強力な技術的強さ、巨大なグローバルユーザーベース、専門的な取引プラットフォーム、安全なストレージソリューション、豊富な取引ペアを提供します。
