

コンピュータビジョンのネットワーク構造は新たな革新を起こそうとしているのでしょうか?
畳み込みニューラル ネットワークからアテンション メカニズムを備えたビジュアル トランスフォーマーまで、ニューラル ネットワーク モデルは入力画像をグリッドまたはパッチ シーケンスとして扱いますが、この方法ではオブジェクトの変化や複雑さを捉えることができません。
例えば、人は絵を観察するとき、自然に絵全体を複数の物体に分割し、物体間の空間的位置関係などを確立します。つまり、人間にとって絵全体は非常に重要です。これは実際にはグラフであり、オブジェクトはグラフ上のノードです。
最近、中国科学院ソフトウェア研究所、ファーウェイのノアの方舟研究所、北京大学、マカオ大学の研究者が共同で新しいモデル アーキテクチャ Vision GNN (ViG) を提案すると、ビジョン タスクのために画像からグラフ レベルの特徴を抽出できます。

論文リンク: https://arxiv.org/pdf/2206.00272.pdf
まず、画像を次のように複数のパッチに分割する必要があります。 Figure ノードを結合し、最近傍パッチを接続してグラフを構築し、ViG モデルを使用してグラフ全体のすべてのノードの情報を変換および交換します。
ViG は 2 つの基本モジュールで構成されています。Grapher モジュールはグラフの畳み込みを使用してグラフ情報を集約および更新し、FFN モジュールは 2 つの線形層を使用してノードの特徴を変換します。
画像認識および物体検出タスクで行われた実験でも、ViG アーキテクチャの優位性が証明されています。一般的な視覚タスクに関する GNN の先駆的な研究は、将来の研究に有益なインスピレーションと経験を提供するでしょう。
この論文の著者は、中国科学院ソフトウェア研究所の博士指導教員であり、マカオ大学の名誉教授でもある呉恩華教授で、工学機械数学学科を卒業しています。 1970 年に清華大学で博士号を取得し、1980 年に英国のマンチェスター大学コンピュータ サイエンス学部で博士号を取得しました。主な研究分野はコンピュータ グラフィックスと仮想現実で、仮想現実、フォトリアリスティックなグラフィックスの生成、物理ベースのシミュレーションとリアルタイム コンピューティング、物理ベースのモデリングとレンダリング、画像とビデオの処理とモデリング、ビジュアル コンピューティングと機械の研究が含まれます。
ネットワーク構造は、多くの場合、パフォーマンスを向上させる上で最も重要な要素です。データの量と品質が保証できる限り、モデルを CNN から ViT に変更すると、より優れたパフォーマンスモデル。
しかし、ネットワークが異なれば入力画像の扱いも異なります。CNN は画像上でウィンドウをスライドさせ、変換不変性と局所特徴を導入します。
ViT と多層パーセプトロン (MLP) は、224×224 の画像をいくつかの 16×16 パッチに分割するなど、画像をパッチ シーケンスに変換し、最終的に長さ 196 シーケンスの入力を形成します。
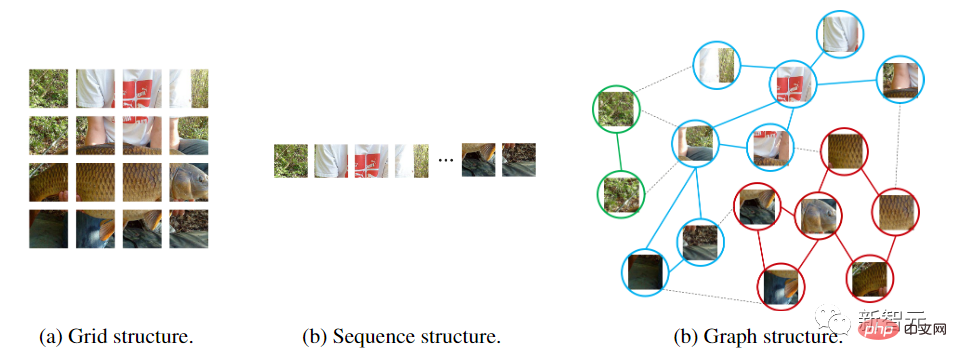
グラフ ニューラル ネットワークはより柔軟です。たとえば、コンピューター ビジョンでは、基本的なタスクは画像内のオブジェクトを識別することです。オブジェクトは通常四角形ではなく、不規則な形状をしている場合があるため、ResNet や ViT などの以前のネットワークで一般的に使用されていたグリッドまたはシーケンス構造は冗長であり、扱いに柔軟性がありません。
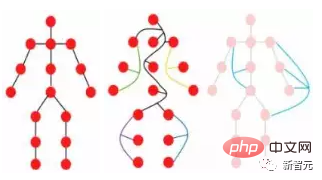
物体は複数の部分から構成されていると見ることができ、たとえば人間は頭、上半身、腕、脚に大別できます。
関節でつながったこれらのパーツは自然に図形構造を形成し、その図形を解析することで、最終的にその物体が人間である可能性があることが特定されます。
また、グラフは一般的なデータ構造であり、グリッドやシーケンスはグラフの特殊なケースとみなすことができます。画像をグラフとして考えると、視覚的により柔軟で効率的になります。
グラフ構造を使用するには、入力イメージをいくつかのパッチに分割し、各パッチをノードとして扱う必要があります。各ピクセルをノードとして扱うと、グラフ内のノードが多すぎます (>10K)。
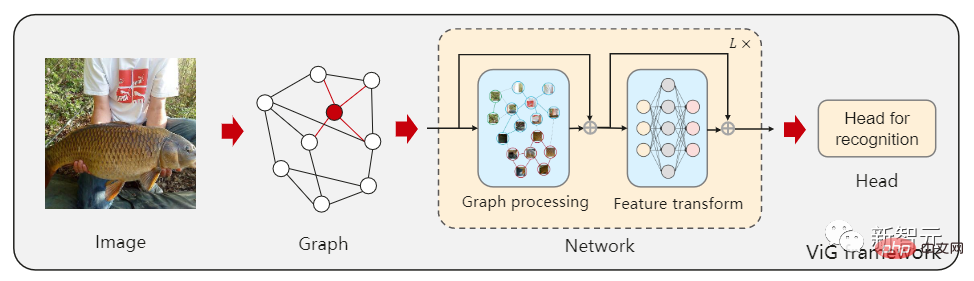
# グラフを確立した後、まずグラフ畳み込みニューラル ネットワーク (GCN) を通じて隣接するノード間の特徴を集約し、画像の表現を抽出します。
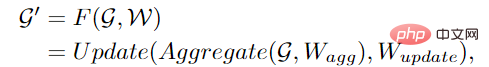
GCN がより多様な特徴を取得できるようにするために、著者はグラフの畳み込みにマルチヘッド操作を適用し、集約された特徴は異なる重みを持つヘッドによって更新されます。ステージ 接続はイメージです。
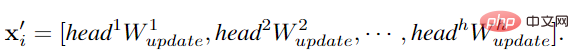
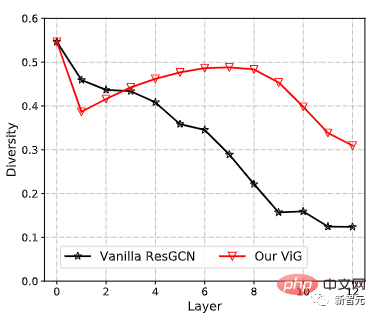
以前の GCN は通常、グラフ データの集合的な特徴を抽出するために複数のグラフ畳み込み層を再利用していましたが、深い GCN の過度の平滑化現象によりノードの特徴の一意性が低下し、結果としてパフォーマンスが低下します。視覚認識が低下します。
# この問題を軽減するために、研究者は、ViG ブロックにさらに多くの特徴変換と非線形活性化関数を導入しました。
まず、グラフの畳み込みの前後に線形レイヤーを適用して、ノードの特徴を同じドメインに投影し、特徴の多様性を高めます。層の崩壊を避けるために、グラフ畳み込みの後に非線形活性化関数を挿入します。
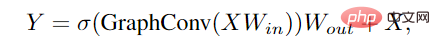
特徴変換機能をさらに向上させ、過剰平滑化現象を軽減するには、各ノードでフィードフォワード ネットワーク (FFN) を使用することも必要です。 FFN モジュールは、2 つの完全に接続された層を持つ単純な多層パーセプトロンです。
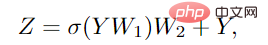
Grapher モジュールと FFN モジュールでは、全結合層またはグラフ畳み込み層の後にバッチ正規化が実行されます。Grapher モジュールと FFN モジュールのスタックは ViG ブロックを構成します大規模なネットワークを構築するための基本単位でもあります。
新しく提案された ViG は、オリジナルの ResGCN と比較して、特徴の多様性を維持することができ、より多くの層が追加されるにつれて、ネットワークはより強力な表現を学習することもできます。
コンピューター ビジョン ネットワーク アーキテクチャでは、一般的に使用される Transformer モデルは通常等方性構造 (ViT など) を持ちますが、CNN はピラミッド構造 (ResNet など) を使用することを好みます。
他のタイプのニューラル ネットワークと比較するために、研究者らは ViG 用に等方性とピラミッドという 2 つのネットワーク アーキテクチャを確立しました。
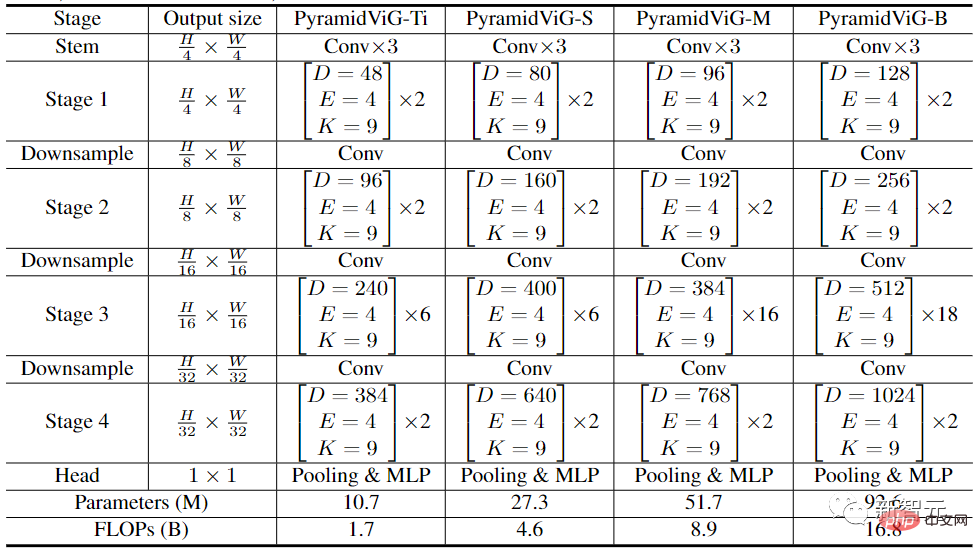
実験比較段階では、研究者らは画像分類タスクで ImageNet ILSVRC 2012 データセットを選択しました。これには、1000 のカテゴリ、1 億 2,000 万のトレーニング画像、および 50,000 の検証画像が含まれています。
ターゲット検出タスクでは、118,000 のトレーニング画像と 5,000 の検証セット画像を含む、80 のターゲット カテゴリを含む COCO 2017 データセットが選択されました。

等方性 ViG アーキテクチャでは、主要な計算プロセス中にフィーチャー サイズを変更しないで済むため、拡張が容易であり、ハードウェア アクセラレーションに適しています。既存の等方性 CNN、トランスフォーマー、MLP と比較すると、ViG が他のタイプのネットワークよりも優れたパフォーマンスを発揮することがわかります。その中で、ViG-Ti は、計算コストは同等でありながら、DeiT-Ti モデルより 1.7% 高い 73.9% というトップ 1 の精度を達成しました。
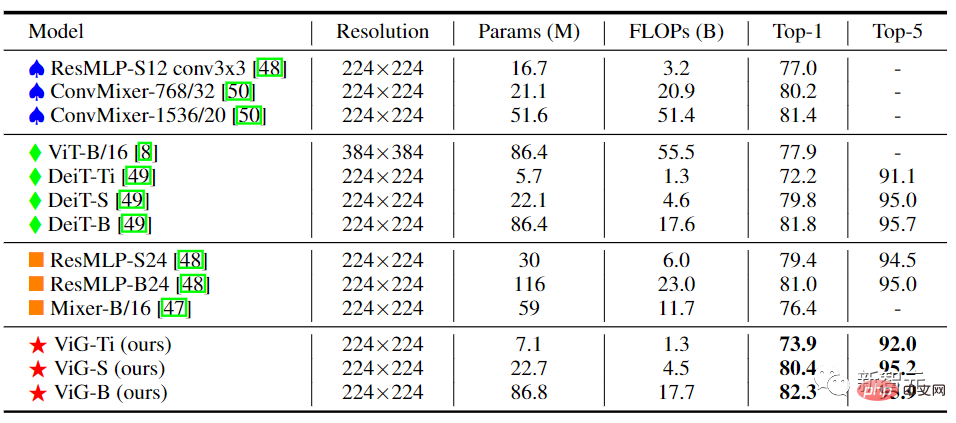
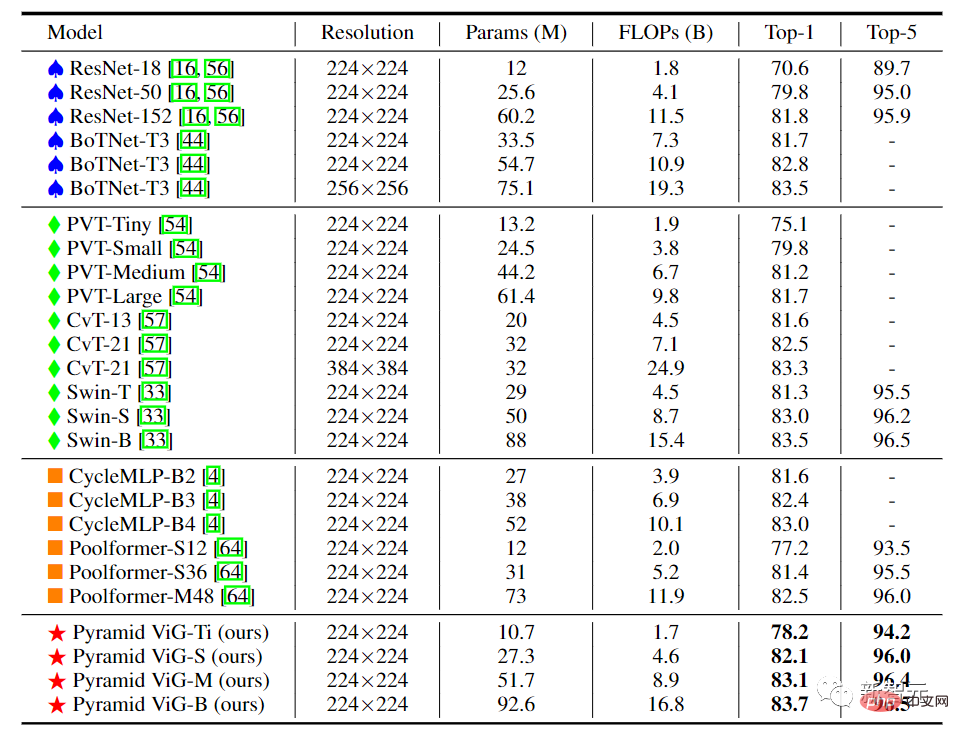
ピラミッド構造の ViG では、ネットワークが深くなるにつれて、特徴マップの空間サイズが徐々に小さくなり、画像のスケール不変特性を使用して画像の生成が行われます。マルチスケール機能を同時に実現します。
高性能ネットワークは、主に ResNet、Swin Transformer、CycleMLP などのピラミッド構造を使用します。 Pyramid ViG をこれらの代表的なピラミッド ネットワークと比較すると、Pyramid ViG シリーズは CNN、MLP、Transformer などの最先端のピラミッド ネットワークを上回る、または匹敵することがわかります。
結果は、グラフ ニューラル ネットワークが視覚タスクを適切に完了でき、コンピューター ビジョン システムの基本コンポーネントになる可能性があることを示しています。
ViG モデルのワークフローをより深く理解するために、研究者たちは ViG-S に構築されたグラフ構造を視覚化しました。 2 つの異なる深さ (ブロック 1 と 12) でのサンプルのプロット。五芒星が中心ノードであり、同じ色のノードがその隣接ノードです。すべてのエッジを描画すると乱雑に見えるため、中央の 2 つのノードのみが視覚化されます。

ViG モデルがコンテンツ関連ノードを 1 次近傍ノードとして選択できることがわかります。浅いレベルでは、色やテクスチャなどの低レベルのローカルな特徴に基づいて隣接ノードが選択されることがよくあります。深いレベルでは、中央ノードの近隣ノードはよりセマンティックであり、同じカテゴリに属します。 ViG ネットワークは、コンテンツとセマンティック表現を通じてノードを徐々に接続し、オブジェクトをより適切に識別するのに役立ちます。
以上が中国科学院ソフトウェアはViTを上回る性能を持つ新しいCVモデルViGをリリース、将来的にはグラフニューラルネットワークの代表となるでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



