

最近、マルチスレッドを使用してファイルをダウンロードする例を見ました。非常に興味深いと思いました。調べて、マルチスレッドを使用してファイルをローカルにコピーしようとしました。書き終えた後、この 2 つは実際には非常に似ていることがわかりました。ローカル ファイルのコピーであっても、ネットワーク マルチスレッドのダウンロードであっても、ストリームの使用方法は同じです。 ローカル ファイル システムの場合、入力ストリームはローカル ファイル システム内のファイルから取得され、ネットワーク リソースの場合は、リモート サーバー上のファイルから取得されます。
注: このマルチスレッドのダウンロード コードは多くの人が書いていますが、誰もが理解できるわけではありません。ここでもう一度書きます。
マルチスレッドを使用することの明白な利点は次のとおりです。 アイドル状態の CPU を使用して速度を向上します。 ただし、スレッドが多いほど良いことに注意してください。n 個のスレッドがまとめてダウンロードされるように見えますが、各スレッドがダウンロードするのはごく一部であり、ダウンロード時間は 1/n になります。これは非常に単純な理解で、一人の家を建てるには100日かかりますが、1万人であれば1/10日しかかかりません。 (大げさです(笑))
スレッド間の切り替えにもシステムのオーバーヘッドが必要であり、スレッド数を適切な範囲内に制御する必要があります。
このクラスは比較的ユニークで、ファイルからデータを読み取り、ファイルにデータを書き込むことができます。ただし、これは OutputStream と InputStream のサブクラスではなく、これら 2 つのインターフェイス DataOutput と DataInput を実装するクラスです。
API の概要:
このクラスのインスタンスは、ランダム アクセス ファイルの読み取りと書き込みをサポートします。ファイルにランダムにアクセスすると、ファイル システムに大量のバイトが保存されているように動作します。ファイル ポインタと呼ばれるカーソル、つまり暗黙的な配列へのインデックスの種類があり、入力操作はファイル ポインタから始まるバイトを読み取り、読み取ったバイトを超えてファイル ポインタを拡張します。出力操作は、ランダム アクセス ファイルが読み取り/書き込みモードで作成されている場合にも使用できます。出力操作では、ファイル ポインタからバイトを書き込み、書き込まれたバイトまでファイル ポインタを進めます。暗黙的な配列の現在の側に書き込む出力操作により、配列が拡張されます。ファイル ポインタは、getFilePointer メソッド によって読み取られ、seek メソッド によって設定されます。
で、このクラスで一番重要なのがseekメソッドなんですが、seekメソッドを使うと書き込み位置を制御できるので、マルチスレッドの実装が非常に楽になります。したがって、ローカル ファイルのコピーであっても、ネットワーク マルチスレッド ダウンロードであっても、このクラスが必要です。
具体的なアイデアは次のとおりです。 まず、RandomAccessFile を使用して File オブジェクトを作成し、次にファイルのサイズを設定します。 (はい、ファイル サイズを直接設定できます。) このファイルを、コピーまたはダウンロードするファイルと同じに設定します。 (このファイルにはデータを書き込んでいませんが、このファイルは作成されています。) ファイルをいくつかの部分に分割し、スレッドを使用して各部分の内容をコピーまたはダウンロードします。
これはファイルの上書きに似ています。既存のファイルがファイルの先頭からデータを書き込み始めてファイルの最後まで書き込むと、元のファイルは存在しなくなり、新しいファイルが書き込まれます。
ファイル サイズを設定します:
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
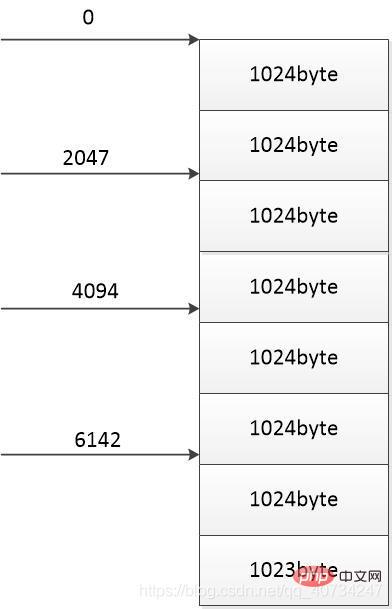
}画像を使用して説明します: この画像は、サイズが 8191 バイトのファイルを表します。各部分のサイズは次のとおりです: 8191 / 4 = 2047 バイト
このファイルを 4 つの部分に分割します。各部分はスレッドを使用してコピーまたはダウンロードされ、各矢印はスレッドのダウンロード開始位置を表します。ファイルが正確に 1024 バイトで割り切れることはほとんどないため、意図的に最後の部分を 1024 バイトに設定しないままにしました。 (1024 バイトを使用する理由は、毎回 1024 バイトを読み取るためです。1024 バイトが読み取られると、読み取られた対応するバイト数が書き込まれます。)
この図によると、各スレッドは 2047 バイトをダウンロードし、ダウンロードされる合計バイト数は次のようになります: 2047 * 4 = 8188 バイト < 8191 バイト (ファイルの合計サイズ) これは問題を引き起こします。ダウンロードされたバイト数が合計バイト数より少ないです。これは問題であるため、ダウンロードされたバイト数は合計バイト数より大きくなければなりません。 ( これ以上あっても、ダウンロードされる部分は後から上書きされるので問題ありません。 )
つまり、それぞれのサイズはこの部分は 8191 / 4 1 = 2048 バイトである必要があります。 (こうすることで、4 つの部分のサイズの合計が合計サイズを超えるため、データの損失は発生しません。)
したがって、ここに 1 を追加する必要があります。
long size = len / FileCopyUtil.THREAD_NUM + 1;
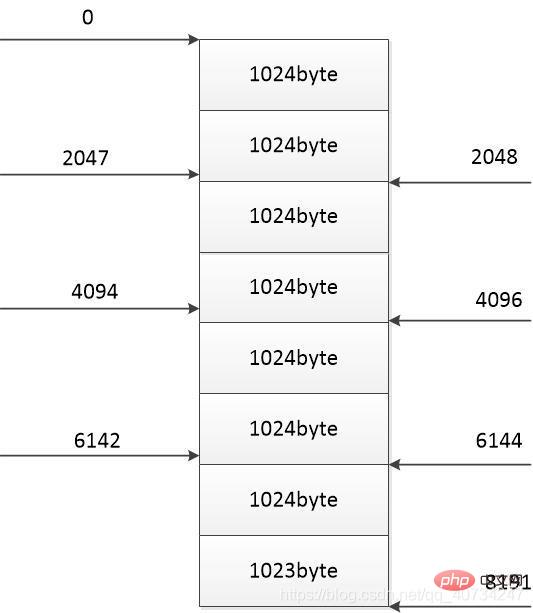
各スレッドがダウンロードを完了する位置 (右側) 各スレッドはダウンロードの自分の部分のみをコピーするため、 need すべてのコンテンツがダウンロードされているため、ファイルデータをファイルに読み書きする部分に追加判定が追加されます。
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h2000%2F20180113%2F0bdc-fyqrewh6850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
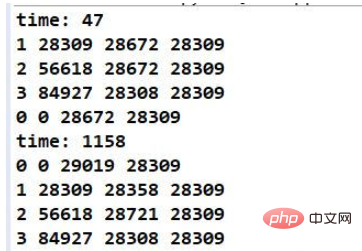
}运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)
产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了。
以上がJava マルチスレッドおよび IO ストリームのアプリケーション シナリオとテクニックの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



