

AIGCの推進に適したネットワークの特徴は何でしょうか?

2023 年は、AI 人工知能技術が爆発的に普及する年です。
ChatGPT、GPT-4、Wen Xinyiyan に代表される AIGC 大型モデルは、テキスト作成、コード開発、詩作成などの機能を 1 つに統合し、強力なコンテンツ制作能力を示し、人々に大きな衝撃を与えます。
通信のベテランとして、Xiao Zaojun は、AIGC モデル自体に加えて、モデルの背後にある通信テクノロジにも関心を持っています。 AIGCの運営を支える強力なネットワークとはどのようなものなのでしょうか?また、AIの波は従来のネットワークにどのような変化をもたらすのでしょうか?
█ AIGC、どれくらいの計算能力が必要ですか?
ご存知のとおり、データ、アルゴリズム、コンピューティング能力は、人工知能の開発の 3 つの基本要素です。
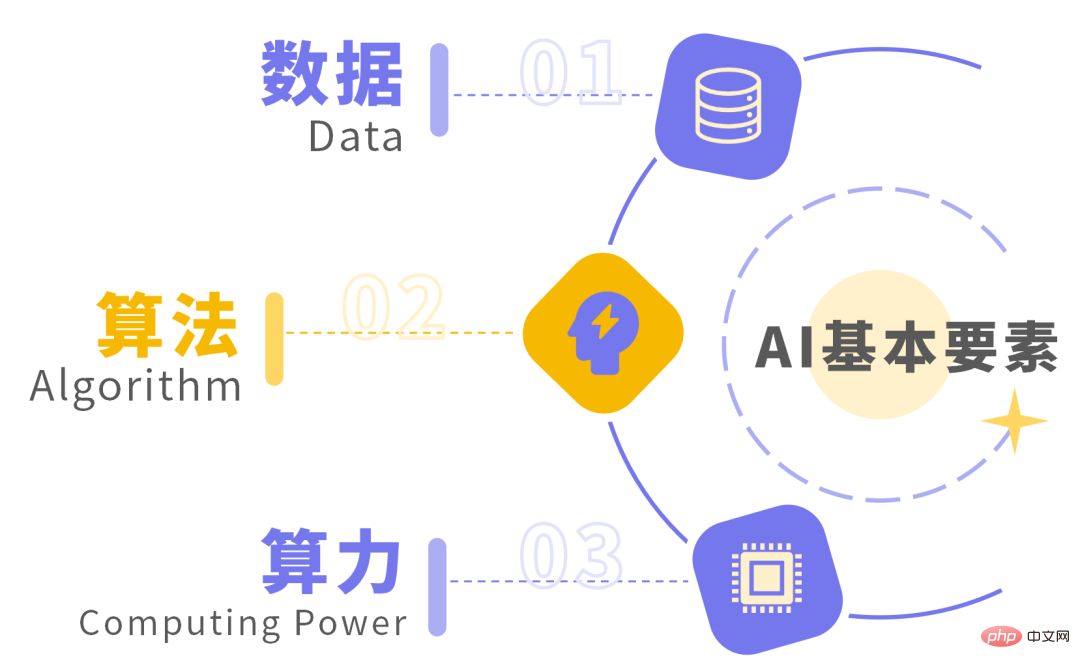
前述した AIGC の大規模モデルが非常に強力であるのは、背後に大量のデータが供給されているためだけでなく、アルゴリズムが常に進化し、アップグレードされているためでもあります。さらに重要なことは、人間のコンピューティング能力の規模がある程度まで発達したことです。強力なコンピューティング インフラストラクチャは、AIGC のコンピューティング ニーズを完全にサポートできます。
AIGC の発展により、トレーニング モデルのパラメータは数千億から兆へと急増しました。このような大規模なトレーニングを完了するために、基盤層でサポートされる GPU の数も 10,000 枚の規模に達しました。
ChatGPT を例に挙げると、トレーニングには Microsoft のスーパーコンピューティング インフラストラクチャが使用され、高帯域幅クラスターを形成したと言われています。 1 回のトレーニングには約 3640 PF 日の計算能力が必要です (つまり、1 秒あたり 1,000 兆回の計算を 3640 日間実行します)。
V100 の FP32 演算能力は 0.014 PFLOPS (演算能力単位、1 秒あたり 1 京回の浮動小数点演算に相当) です。 V100 が 1 万個、つまり 140 PFLOPS です。
つまり、GPU 使用率が 100% の場合、トレーニング セッションを完了するには 3640 ÷ 140 = 26 (日) かかります。
GPU 使用率が 100% に達することは不可能で、33% (OpenAI が提供する想定使用率) として計算すると、26 倍 3 回、つまり 78 日に相当します。
GPU の計算能力と GPU 使用率が大規模モデルのトレーニングに大きな影響を与えることがわかります。
それでは、GPU 使用率に影響を与える最大の要因は何でしょうか?
答えは「インターネット」です。
コンピューティング クラスターとしての 1 万または数万の GPU は、ストレージ クラスターと対話するために大量の帯域幅を必要とします。さらに、GPU クラスターがトレーニング計算を実行するとき、それらは独立ではなく、混合され、並列されます。 GPU 間で大量のデータ交換が行われるため、膨大な帯域幅も必要になります。
ネットワークが強くなく、データ送信が遅い場合、GPU はデータを待機する必要があり、その結果、使用率が低下します。使用率が低下すると、トレーニング時間が増加し、コストが増加し、ユーザー エクスペリエンスが低下します。
業界はかつて、以下の図に示すように、ネットワーク帯域幅のスループット、通信遅延、GPU 使用率の関係を計算するモデルを作成しました:

ご覧のとおり、ネットワーク スループットが強いほど、GPU の使用率が高くなります。使用率 使用率が高くなるほど、通信の動的遅延が大きくなり、GPU 使用率は低くなります。
一言で言えば、優れたネットワークなしで大きなモデルを操作しないでください。
█ AIGCの運営をサポートできるネットワークはどのようなものですか?
AI クラスターコンピューティングによるネットワーク調整に対処するために、業界もさまざまな方法を考えてきました。
従来の主な対応戦略には、Infiniband、RDMA、モジュラー スイッチの 3 つがあります。それぞれについて簡単に見てみましょう。
Infiniband ネットワーキング
Infiniband (直訳すると「無限帯域」技術、略称 IB) ネットワークは、データ通信に携わる子供たちにとって馴染みのあるものであるはずです。
これは、現在、高性能ネットワークを構築するための最良の方法であり、非常に高い帯域幅を備え、輻輳がなく、低遅延を実現できます。 ChatGPT と GPT-4 が使用しているのは Infiniband ネットワークであると言われています。
Infiniband ネットワークに欠点があるとすれば、それは一言で言えば、高価です。従来のイーサネット ネットワーキングと比較すると、Infiniband ネットワーキングのコストは数倍高価になります。このテクノロジーは現在、業界に成熟したサプライヤーが 1 社しかなく、ユーザーには選択肢がほとんどありません。
- RDMAネットワーク
RDMAの正式名称はRemote Direct Memory Accessです。新しいタイプの通信メカニズムです。 RDMA ソリューションでは、アプリケーション データは CPU や複雑なオペレーティング システムを経由せず、ネットワーク カードと直接通信するため、スループットが大幅に向上するだけでなく、遅延も短縮されます。
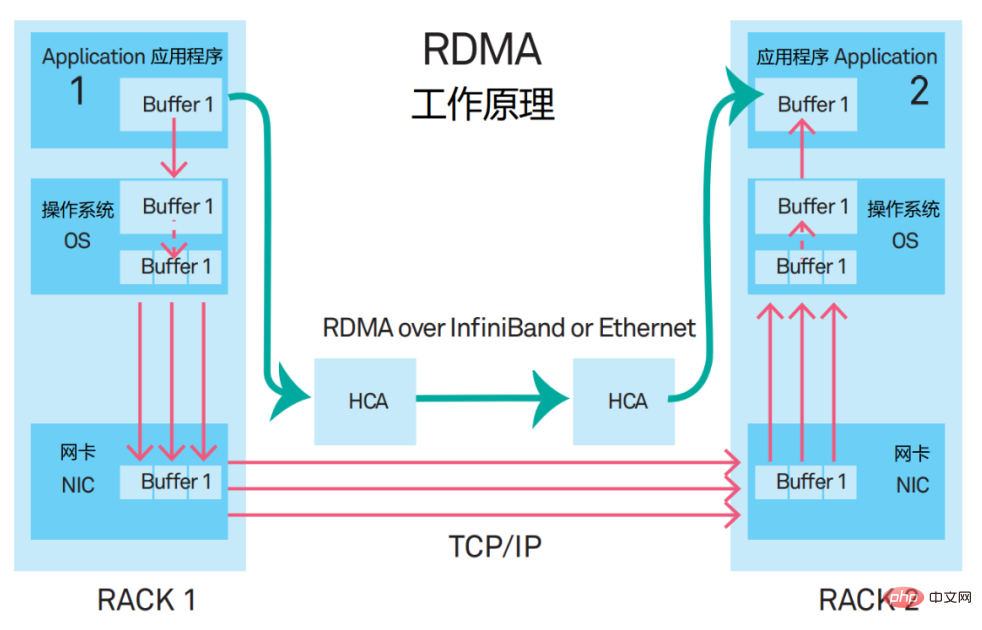
RDMA が最初に提案されたとき、それは InfiniBand ネットワーク上で運ばれました。現在、RDMA は徐々にイーサネットに移植されています。
現在、高性能ネットワーク向けの主流のネットワーキング ソリューションは、RoCE v2 (RDMA over Converged Ethernet、RDMA based on Converged Ethernet) プロトコルに基づく RDMA をサポートするネットワークを構築することです。
このソリューションには、PFC (Priority Flow Control、優先度ベースのフロー制御) と ECN (Explicit Congestion Notification、明示的な輻輳通知) という 2 つの重要なマッチング テクノロジーが含まれています。これらはリンクの輻輳を回避するために作成されたテクノロジーですが、頻繁にトリガーされると、送信側が送信を一時停止したり、送信速度が低下したりして、通信帯域幅が減少します。 (それらについては後述します)
- フレームスイッチ
一部の外国インターネット企業は、高性能ネットワーク構築の要件を満たすためにフレームスイッチ (DNX チップ + VOQ テクノロジー) の使用を望んでいます。
DNX:broadcom(ブロードコム)のチップシリーズ
VOQ:Virtual Output Queue、仮想出力キュー
この解決策は実現可能に見えますが、次のような課題にも直面しています。
まず第一に、モジュラースイッチの拡張機能は平均的です。シャーシのサイズにより、ポートの最大数が制限されます。より大きなクラスターを構築する場合は、複数のシャーシにわたって水平に拡張する必要があります。
第二に、モジュラースイッチの機器は大量の電力を消費します。シャーシには多数のラインカード チップ、ファブリック チップ、ファンなどが搭載されており、1 台のデバイスの消費電力は 20,000 ワットを超え、中には 30,000 ワットを超えるものもあります。高すぎる。
3 番目に、モジュラー スイッチには多数の単一デバイス ポートと大規模なフォールト ドメインがあります。
上記の理由に基づいて、モジュラースイッチ機器は AI コンピューティングクラスターの小規模な展開にのみ適しています。
█ DDC とは正確には何ですか
上記のものはすべて従来のソリューションです。これらの従来の解決策は機能しないため、当然のことながら、新しい方法を見つける必要があります。
そこで、DDC と呼ばれるまったく新しいソリューションがデビューしました。
DDC、正式名は Distributed Disaggregated Chassis です。
フロントシャーシスイッチの「分割バージョン」です。モジュラースイッチの拡張性は不十分なので、単純に分解して1つのデバイスを複数のデバイスにできますか?

フレームタイプの機器は、通常、スイッチング ネットワーク ボード (バックプレーン) とサービス ライン カード (ボード カード) の 2 つの部分に分かれており、それぞれがコネクタで接続されます。
DDC ソリューションは、スイッチング ネットワーク ボードを NCF 機器に、ビジネス ライン カードを NCP 機器に変えます。コネクタが光ファイバーになります。モジュラーデバイスの管理機能も、DDC アーキテクチャでは NCC になります。
NCF: ネットワーククラウドファブリック (ネットワーククラウド管理コントロールプレーン)
NCP: ネットワーククラウドパケット処理 (ネットワーククラウドパケット処理)
NCC: ネットワーククラウドコントローラー (ネットワーククラウドコントローラー)
DDC 後集中型から分散型に変更され、拡張性が大幅に強化されました。 AIクラスターの規模に応じてネットワーク規模を柔軟に設計できます。
2 つの例 (単一 POD ネットワーキングとマルチ POD ネットワーキング) を挙げてみましょう。
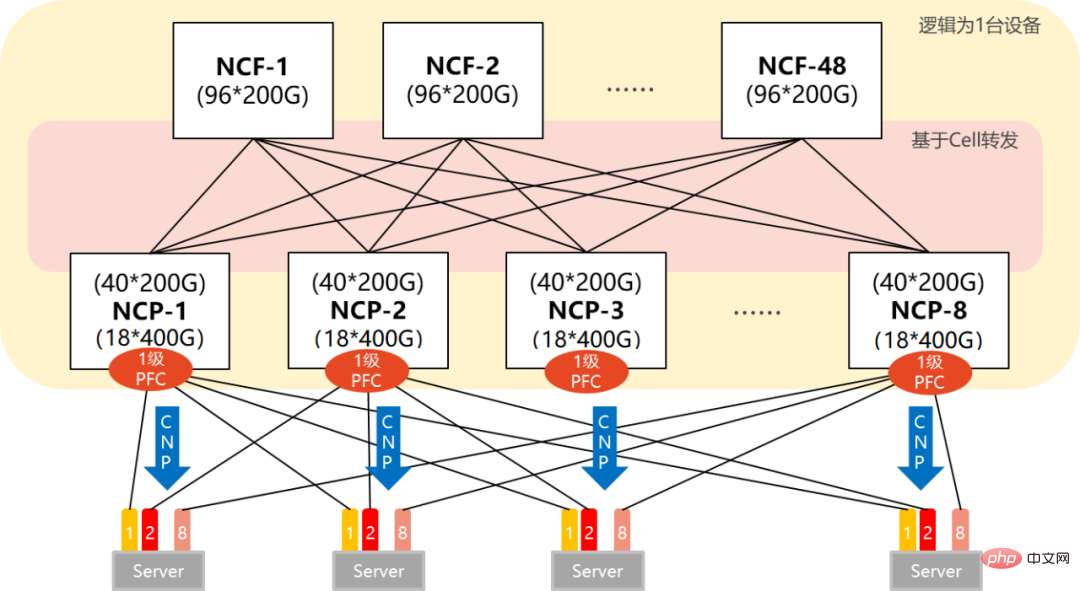
単一の POD ネットワークでは、96 個の NCP がアクセス ポイントとして使用され、そのうち NCP には合計 18 個の 400G ダウンストリーム インターフェイスがあり、AI コンピューティング クラスターのネットワーク カードの接続を担当します。アップリンクには合計 40 の 200G インターフェイスがあり、最大 40 の NCF が接続可能で、この規模のアップリンクとダウンリンクの帯域幅は 1.1:1 になります。 POD 全体は 1,728 個の 400G ネットワーク インターフェイスをサポートできます。8 個の GPU を搭載したサーバーに基づいて計算すると、216 台の AI コンピューティング サーバーをサポートできます。
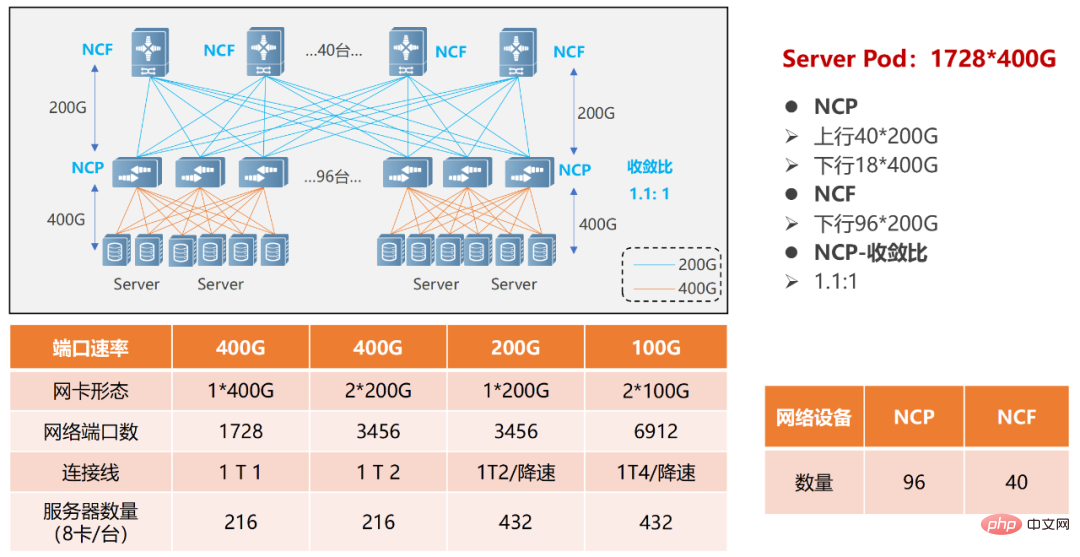
単一PODネットワーキング
マルチレベルPODネットワーキング、規模が大きくなる可能性があります。
マルチレベル POD ネットワークでは、NCF デバイスは第 2 レベルの NCF に接続するために SerDes の半分を犠牲にする必要があります。したがって、現時点では、単一の POD はアクセスに 48 個の NCP を使用し、ダウンリンクには合計 18 個の 400G インターフェイスが使用されます。
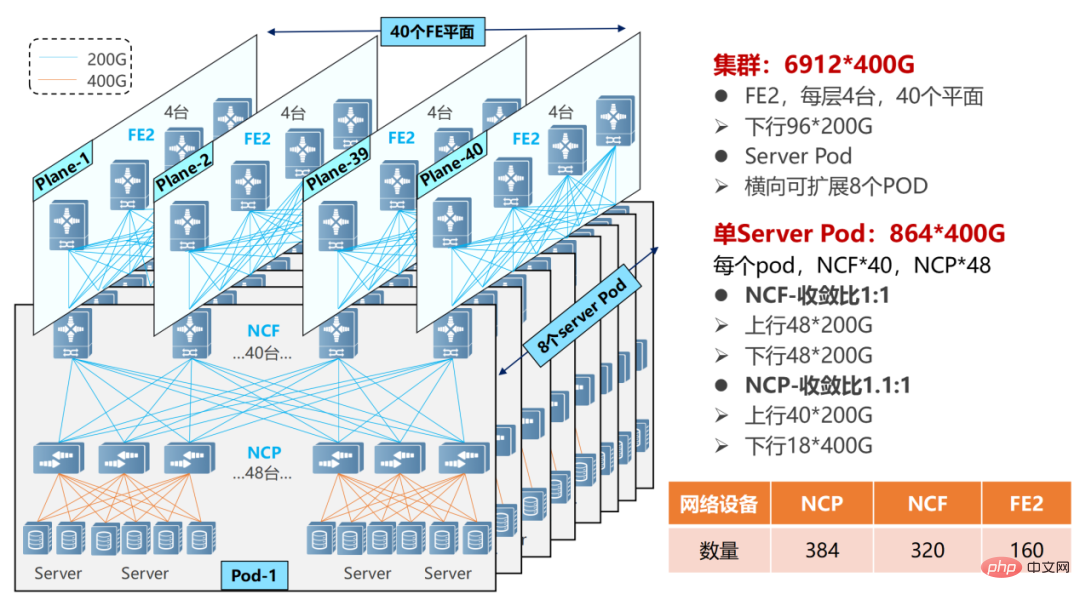
複数の POD ネットワーキング
単一の POD は 864 の 400G インターフェイス (48×18) をサポートできます。 POD(8個)を水平に追加することで規模を拡張でき、システム全体で最大6912個の400Gネットワークポート(864×8)をサポートできます。
NCP には 40 の 200G アップリンクがあり、POD 内の 40 の NCF に接続します。 POD の NCF は 48 の 200G インターフェイスを使用し、48 の 200G インターフェイスは第 2 レベルの NCF の上流で 12 個のグループに分割されます。第 2 レベルの NCF は 40 個のプレーン (プレーン) を使用し、各プレーンには 4 つの NCF-P があり、POD 内の 40 個の NCF に対応します。
ネットワーク全体の POD 内で 1.1:1 (ノースバウンド帯域幅がサウスバウンド帯域幅より大きい) のオーバースピード比を達成し、POD とセカンダリ NCF 帯域幅)。
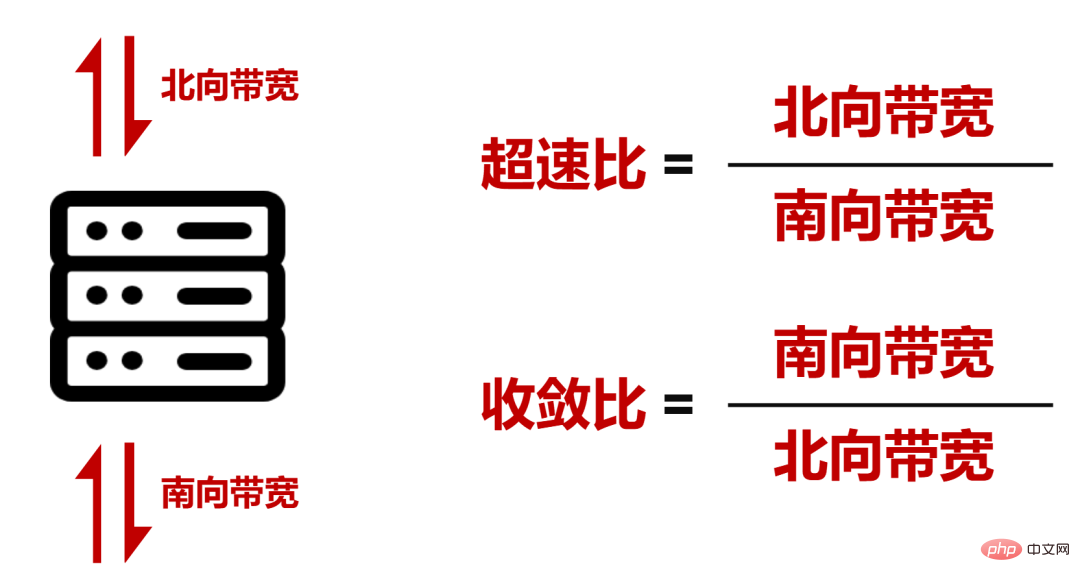
█ DDCの技術的特徴
規模と帯域幅スループットの観点から見ると、DDCはすでにAI大規模モデルトレーニングのネットワーク要件を満たすことができます。
しかし、ネットワークの運用プロセスは複雑であり、DDCも遅延耐性、負荷分散、管理効率の点で改善が必要です。
- パケット損失に対処するためのVOQ+セル転送メカニズムに基づいています
ネットワークの動作プロセス中に、バーストトラフィックが発生し、受信側で処理する時間がなくなり、輻輳が発生する可能性がありますそしてパケットロス。
この状況に対処するために、DDC は VOQ+Cell に基づく転送メカニズムを採用しています。
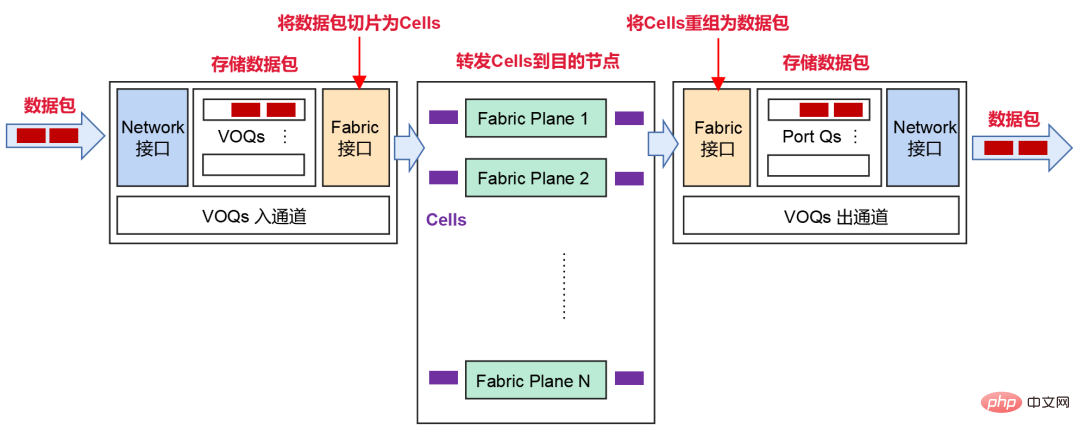
送信者がネットワークからデータパケットを受信した後、それはストレージのためにVOQ(仮想出力キュー)に分類されます。
データ パケットを送信する前に、NCP はまずクレジット メッセージを送信して、受信側にこれらのメッセージを処理するのに十分なバッファ スペースがあるかどうかを判断します。
受信側が正常であれば、パケットはセル (パケットの小さなスライス) に断片化され、中間ファブリック ノード (NCF) に対して動的に負荷分散されます。
受信側が一時的にメッセージを処理できない場合、メッセージは送信側のVOQに一時的に保存され、受信側に直接転送されません。
受信側で、これらのセルは再編成されて保存され、ネットワークに転送されます。
スライスされたセルはポーリングメカニズムを使用して送信されます。各アップリンクを最大限に活用し、すべてのアップリンクで送信されるデータ量がほぼ均等になるようにします。
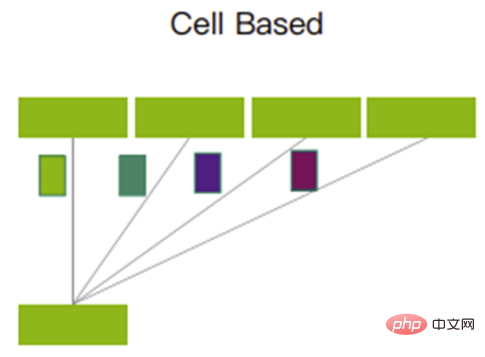
ポーリングメカニズム
このメカニズムはキャッシュを最大限に活用し、パケット損失を大幅に削減するか、場合によってはパケット損失を引き起こす可能性があります。データの再送信が減少し、全体的な通信遅延がより安定して低くなるため、帯域幅の使用率が向上し、ビジネスのスループット効率が向上します。
- デッドロックを回避するための PFC シングルホップ展開
前述したように、PFC (優先順位ベースのフロー制御) テクノロジーは、フロー制御のために RDMA ロスレス ネットワークに導入されています。
簡単に言うと、PFC はイーサネット リンク上に 8 つの仮想チャネルを作成し、各仮想チャネルに対応する優先順位を割り当てます。これにより、仮想チャネルのいずれか 1 つを独立して一時停止および再開できるようにしながら、他の仮想チャネルはチャネル内のトラフィックは中断されることなく通過します。
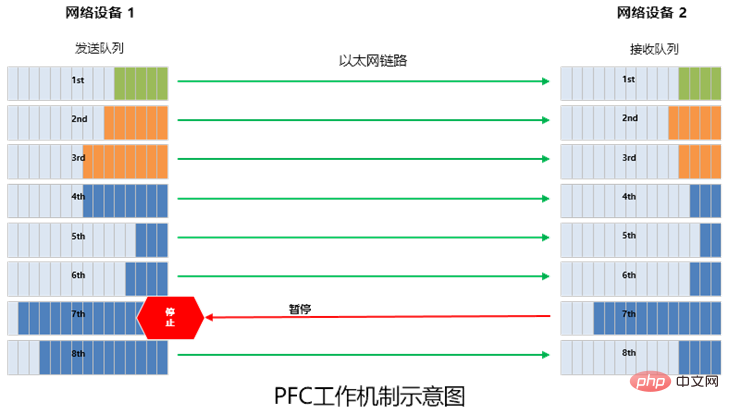
PFC はキューベースのフロー制御を実装できますが、デッドロックという問題もあります。
いわゆるデッドロックとは、ループなどによる複数のスイッチ間での輻輳(各ポートのキャッシュ消費量が閾値を超える)により発生する「行き詰まり」であり、全て相手の解放を待っている状態です。 」 (すべてのスイッチへのトラフィックは永続的にブロックされます)。
DDC ネットワークでは、PFC のデッドロックの問題はありません。ネットワーク全体の観点から見ると、すべての NCP と NCF は 1 つのデバイスと見なすことができるためです。 AI サーバーの場合、DDC 全体は単なるスイッチであり、マルチレベルのスイッチはありません。したがって、デッドロックは発生しません。
また、DDC のデータ転送メカニズムに従って、ECN (明示的輻輳通知) をインターフェースに導入できます。
ECN メカニズムでは、ネットワーク デバイスが RoCE v2 トラフィックの輻輳を検出すると (内部クレジットおよびキャッシュ メカニズムはバースト トラフィックをサポートできません)、CNP (輻輳通知パケット、輻輳通知メッセージ) をサーバーに送信します。 )、速度を下げる必要があります。
- 分散OS、信頼性の向上
最後に、管理コントロールプレーンを見てみましょう。
DDC アーキテクチャでは、モジュラー デバイスの管理機能が NCC (Network Cloud Controller) になると前述しました。 NCC は非常に重要です。シングルポイント方式を使用すると、何か問題が発生するとネットワーク全体に障害が発生します。
このような問題を回避するために、DDC は NCC の集中コントロールプレーンを廃止し、分散 OS (オペレーティングシステム) を構築することができます。
分散型OSをベースとし、SDN運用保守コントローラーに基づく標準インターフェース(Netconf、GRPCなど)を通じて機器の設定・管理が可能です。この場合、各 NCP と NCF は独立して管理され、独立したコントロール プレーンと管理プレーンを備えているため、システムの信頼性が大幅に向上し、導入が容易になります。
█ DDC の商業的進歩
要約すると、従来のネットワーキングと比較して、DDC はネットワークの規模、拡張機能、信頼性、コスト、導入速度の点で大きな利点があります。これはネットワーク技術のアップグレードの成果であり、元のネットワーク アーキテクチャを覆すアイデアを提供し、ネットワーク ハードウェアの分離、ネットワーク アーキテクチャの統合、転送容量の拡張を実現できます。
業界は、OpenMPI テスト スイートを使用して、フレーム機器と従来のネットワーク機器の間の比較シミュレーション テストを実施してきました。テストの結論は次のとおりです。All-to-All シナリオでは、従来のネットワーキングと比較して、フレーム タイプ デバイスの帯域幅使用率が約 20% 増加します (GPU 使用率の約 8% の増加に相当します)。
このテクノロジーが現在、業界の主要な開発方向となっているのは、まさに DDC の機能に大きな利点があるためです。たとえば、Ruijie Networks は、400G NCP スイッチ RG-S6930-18QC40F1 と 200G NCF スイッチ RG-X56-96F1 という 2 つの提供可能な DDC 製品の発売を主導しました。

RG-S6930-18QC40F1 スイッチは高さ 2U で、400G パネル ポート 18 個、200G ファブリック インライン ポート 40 個、ファン 4 個、電源 2 個を提供します。
RG-X56-96F1 スイッチは高さ 4U で、96 個の 200G ファブリック インライン ポート、8 個のファン、および 4 個の電源を提供します。
Ruijie Networks は 400G ポートの形で製品の開発と発売を継続すると報告されています。
█ 最後に
AIGCの台頭は、インターネット業界における技術革命の新たなラウンドを引き起こしました。
このトラックに参加し、競争に参加する企業がますます増えていることがわかります。これは、ネットワーク インフラストラクチャのアップグレードが急務であることを意味します。
DDC の出現は、ネットワーク インフラストラクチャの能力を大幅に強化するだけでなく、AI 革命によってネットワーク インフラストラクチャに生じる課題に効果的に対応するだけでなく、社会全体のデジタル変革も支援します。人類のデジタルインテリジェンス時代の到来を加速します。
以上がAIGCの推進に適したネットワークの特徴は何でしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

![WLAN拡張モジュールが停止しました[修正]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
Windows コンピュータの WLAN 拡張モジュールに問題がある場合、インターネットから切断される可能性があります。この状況はイライラすることがよくありますが、幸いなことに、この記事では、この問題を解決し、ワイヤレス接続を再び正常に動作させるのに役立ついくつかの簡単な提案を提供します。 WLAN 拡張モジュールが停止しました。 WLAN 拡張モジュールが Windows コンピュータで動作を停止した場合は、次の提案に従って修正してください。 ネットワークとインターネットのトラブルシューティング ツールを実行して、ワイヤレス ネットワーク接続を無効にし、再度有効にします。 WLAN 自動構成サービスを再起動します。 電源オプションを変更します。 変更します。詳細な電源設定 ネットワーク アダプター ドライバーを再インストールする いくつかのネットワーク コマンドを実行する それでは、詳しく見てみましょう
 win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
インターネットにアクセスするには、インターネットに接続するときに正しい DNS を使用する必要があります。同様に、間違った DNS 設定を使用すると、DNS サーバー エラーが発生しますが、このときは、ネットワーク設定で DNS を自動的に取得するように選択することで問題を解決できます。ソリューション。 win11 ネットワーク dns サーバー エラーを解決する方法. 方法 1: DNS をリセットする 1. まず、タスクバーの [スタート] をクリックして入力し、[設定] アイコン ボタンを見つけてクリックします。 2. 次に、左側の列の「ネットワークとインターネット」オプションコマンドをクリックします。 3. 次に、右側で「イーサネット」オプションを見つけ、クリックして入力します。 4. その後、DNSサーバーの割り当ての「編集」をクリックし、最後にDNSを「自動(D)」に設定します。
 Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
「ネットワーク エラーのダウンロードに失敗しました」問題とは何ですか?解決策を詳しく説明する前に、まず「ネットワーク エラーのダウンロードに失敗しました」問題が何を意味するのかを理解しましょう。このエラーは通常、ダウンロード中にネットワーク接続が中断された場合に発生します。この問題は、インターネット接続の弱さ、ネットワークの混雑、サーバーの問題など、さまざまな理由で発生する可能性があります。このエラーが発生すると、ダウンロードが停止し、エラー メッセージが表示されます。ネットワークエラーで失敗したダウンロードを修正するにはどうすればよいですか? 「ネットワーク エラー ダウンロードに失敗しました」というメッセージが表示されると、必要なファイルへのアクセスまたはダウンロード中に障害が発生する可能性があります。 Chrome などのブラウザを使用している場合でも、Google ドライブや Google フォトなどのプラットフォームを使用している場合でも、このエラーはポップアップ表示され、不便を引き起こします。この問題を解決し、解決するために役立つポイントを以下に示します。
 修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
WDMyCloud が Windows 11 のネットワーク上に表示されない場合、特にそこにバックアップやその他の重要なファイルを保存している場合は、大きな問題になる可能性があります。これは、ネットワーク ストレージに頻繁にアクセスする必要があるユーザーにとって大きな問題となる可能性があるため、今日のガイドでは、この問題を永久に修正する方法を説明します。 WDMyCloud が Windows 11 ネットワークに表示されないのはなぜですか? MyCloud デバイス、ネットワーク アダプター、またはインターネット接続が正しく構成されていません。パソコンにSMB機能がインストールされていません。 Winsock の一時的な不具合がこの問題を引き起こす場合があります。クラウドがネットワーク上に表示されない場合はどうすればよいですか?問題の修正を開始する前に、いくつかの予備チェックを実行できます。
 Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
この記事では、Win10のシステムネットワーク上に地球儀マークが表示されるがインターネットにアクセスできない問題の解決策を紹介します。この記事では、地球がインターネットにアクセスできないことを示す Win10 ネットワークの問題を読者が解決するのに役立つ詳細な手順を説明します。方法 1: 直接再起動する まず、ネットワーク ケーブルが正しく接続されていないこと、ブロードバンドが滞っていないかを確認します。ルーターまたは光モデムが停止している可能性があります。この場合は、ルーターまたは光モデムを再起動する必要があります。コンピュータ上で重要な作業が行われていない場合は、コンピュータを直接再起動できます。ほとんどの軽微な問題は、コンピュータを再起動することですぐに解決できます。ブロードバンドが滞っておらず、ネットワークが正常であると判断される場合は、別の問題です。方法 2: 1. [Win]キーを押すか、左下の[スタートメニュー]をクリックし、表示されるメニュー項目の電源ボタンの上にある歯車アイコンをクリックし、[設定]をクリックします。
 キャラクターを統一し、シーンを変更する、ビデオ生成アーティファクトである PixVerse がネチズンによって実行され、その超一貫性は「必殺技」となっています。
Apr 01, 2024 pm 02:11 PM
キャラクターを統一し、シーンを変更する、ビデオ生成アーティファクトである PixVerse がネチズンによって実行され、その超一貫性は「必殺技」となっています。
Apr 01, 2024 pm 02:11 PM
もう一度ダブルクリックすると、新しい機能がデビューします。写真の中の人物の背景を変更したいと思ったことはありますが、AI は常に「オブジェクトは人でも物でもない」ような効果を生み出します。 Midjourney や DALL・E などの成熟した生成ツールであっても、キャラクターの一貫性を維持するには、ある程度のプロンプト スキルが必要です。そうしないと、キャラクターがコロコロ変わり、望む結果が得られません。ただし、今回はチャンスです。 AIGC ツール PixVerse の新しい「Character-Video」機能は、これらすべてを実現するのに役立ちます。それだけでなく、キャラクターをより鮮やかにするダイナミックなビデオを生成することもできます。画像を入力すると、対応するダイナミックなビデオ結果を取得できます。キャラクターの一貫性を維持することに基づいて、豊富な背景要素とキャラクターのダイナミクスにより、生成された結果は
 修正: Windows 11 セーフ モードでインターネットにアクセスできないネットワーク接続の問題
Sep 23, 2023 pm 01:13 PM
修正: Windows 11 セーフ モードでインターネットにアクセスできないネットワーク接続の問題
Sep 23, 2023 pm 01:13 PM
セーフ モードとネットワークの Windows 11 コンピューターでインターネットに接続できないと、特にシステムの問題の診断とトラブルシューティングを行うときにイライラすることがあります。このガイドでは、問題の潜在的な原因について説明し、セーフ モードでインターネットにアクセスできるようにするための効果的な解決策をリストします。セーフ モードでネットワークを使用するとインターネットが利用できないのはなぜですか?ネットワーク アダプターに互換性がないか、正しく読み込まれていません。サードパーティ製のファイアウォール、セキュリティ ソフトウェア、またはウイルス対策ソフトウェアが、セーフ モードでのネットワーク接続を妨害する可能性があります。ネットワークサービスが実行されていません。マルウェア感染 Windows 11 でセーフ モードでインターネットが使用できない場合はどうすればよいですか?高度なトラブルシューティング手順を実行する前に、次のチェックを実行することを検討する必要があります。
 ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
LOL サーバーに接続できません。ネットワークを確認してください。 近年、オンラインゲームは多くの人にとって日常的な娯楽となっています。中でも、リーグ オブ レジェンド (LOL) は非常に人気のあるマルチプレイヤー オンライン ゲームであり、数億人のプレイヤーの参加と関心を集めています。ただし、LOL をプレイしているときに、「サーバーに接続できません。ネットワークを確認してください」というエラー メッセージが表示されることがあります。これは間違いなくプレイヤーに何らかの問題をもたらします。次に、このエラーの原因と解決策について説明します。まず、LOLがサーバーに接続できない問題として考えられるのは、
