

複数の ChatGPT API を使用した Tsinghua UltraChat マルチラウンド会話の実装

ChatGPT のリリース以来、この期間中、会話モデルの人気は高まるばかりです。これらのモデルの驚くべきパフォーマンスに感心する一方で、その背後にある巨大なコンピューティング能力と大規模なデータのサポートも推測する必要があります。
データに関する限り、高品質のデータは非常に重要です。このため、OpenAI はデータとアノテーションの作業に多大な労力を費やしてきました。 ChatGPT は人間よりも信頼性の高いデータ アノテーターであることが複数の研究で示されており、オープンソース コミュニティが ChatGPT などの強力な言語モデルから大量の対話データを取得できれば、対話モデルをより優れたパフォーマンスでトレーニングできるようになります。これは、アルパカ、ビキューナ、コアラなどのアルパカ ファミリーのモデルによって証明されています。たとえば、Vicuna は、ShareGPT から収集したユーザー共有データを使用して LLaMA モデルの命令を微調整することで、ChatGPT の 9 段階の成功を再現しました。 データが強力な言語モデルをトレーニングするための主要な生産性であることを示す証拠が増えています。
ShareGPT は、ユーザーが興味深いと思う ChatGPT の回答をアップロードする ChatGPT データ共有 Web サイトです。 ShareGPT 上のデータはオープンですが些細なものであり、研究者自身が収集して整理する必要があります。高品質で幅広いデータセットがあれば、オープンソース コミュニティは会話モデルの開発に半分の労力で 2 倍の結果を得ることができます。
これに基づいて、UltraChat と呼ばれる最近のプロジェクトにより、超高品質の会話データ セットが体系的に構築されました。プロジェクトの作成者は、2 つの独立した ChatGPT Turbo API を使用して会話を実行し、複数ラウンドの会話データを生成しようとしました。
- プロジェクトアドレス: https://github.com/thunlp/UltraChat
- データセット アドレス: http://39.101.77.220/
- データセット インタラクション アドレス: https://atlas. nomic.ai /map/0ce65783-c3a9-40b5-895d-384933f50081/a7b46301-022f-45d8-bbf4-98107eabdbac
具体的には、このプロジェクトの目的は、 Turbo API に基づくオープンソースの大規模なマルチラウンド対話データにより、研究者が普遍的な対話機能を備えた強力な言語モデルを開発できるようになります。なお、本プロジェクトではプライバシー保護等を考慮し、インターネット上のデータをプロンプトとして直接利用することはありません。生成されたデータの品質を保証するために、研究者らは生成プロセスで 2 つの独立した ChatGPT Turbo API を使用しました。1 つのモデルは質問や指示を生成するユーザーの役割を果たし、もう 1 つのモデルはフィードバックを生成します。

ChatGPT を直接使用して、いくつかのシード会話や質問に基づいて自由に生成すると、単一のトピックやコンテンツの繰り返しなどの問題が発生しやすくなります。データの多様性そのものを保証することが困難になります。この目的を達成するために、UltraChat は会話データの対象となるトピックとタスクのタイプを体系的に分類して設計し、次の 3 つの部分で構成されるユーザー モデルと応答モデルの詳細なプロンプト エンジニアリングも実施しました。 世界についての質問: 会話のこの部分は、現実世界の概念、エンティティ、オブジェクトに関する幅広い質問から生まれています。取り上げられるトピックは、テクノロジー、アート、金融、その他の分野に及びます。
- 執筆と作成: 対話データのこの部分は、AI に完全なテキスト資料を一から作成するよう指示することに重点を置き、これに基づいてフォローアップの質問やさらなるガイダンスを提供します。文章を上達させるために、コンテンツ タイプには記事、ブログ、詩、物語、演劇、電子メールなどが含まれます。
- 既存データの書き換え支援(書き込みと作成):対話データは既存データに基づいて生成されます。指示には、書き換え、継続、翻訳、帰納、推論、などなど、取り上げられるテーマも多岐にわたります。
- データのこれら 3 つの部分は、AI モデルに対するほとんどのユーザーの要件をカバーします。同時に、これら 3 種類のデータは異なる課題に直面し、異なる構築方法が必要になります。
たとえば、データの最初の部分の主な課題は、合計数十万の会話の中で人間社会の共通知識をできるだけ広範囲にカバーする方法です。この目的のために、研究者らは自動的にウィキデータから生成されたトピックとソース エンティティの 2 つの側面がフィルタリングされ、構築されます。
第 2 部と第 3 部の課題は主に、最終的な目標から逸脱することなく、ユーザーの指示をシミュレートし、後続の会話でユーザー モデルの生成をできるだけ多様にする方法にあります。会話 (必要に応じてマテリアルを生成するか、マテリアルを書き換えます)。これについて研究者は、ユーザー モデルの入力プロンプトを完全に設計し、実験しました。構築が完了した後、著者らは幻覚の問題を弱めるためにデータを後処理しました。
現在、プロジェクトはデータの最初の 2 つの部分をリリースしており、そのデータ量は 124 万件で、これはオープンソース コミュニティで最大の関連データ セットとなるはずです。コンテンツには現実世界での豊かで多彩な会話が含まれており、データの最終部分は今後公開される予定です。
#世界の問題データは、以下の図に示すように、30 の代表的で多様なメタテーマから得られます。

- 上記のメタテーマに基づいて、このプロジェクトではデータ構築用に 1,100 のサブテーマが生成されました。テーマ では、最大 10 個の特定の質問を生成します;
- 次に、Turbo API を使用して、10 個の質問ごとに新しい関連質問を生成します;
- 質問ごとに、2 つのモデルが繰り返し使用され、上記のように 3 ~ 7 ラウンドの対話が生成されます。
- さらに、このプロジェクトは、ウィキデータから最も一般的に使用される 10,000 の名前付きエンティティを収集しました。ChatGPT API を使用して、エンティティごとに 5 つのメタ質問を生成しました。メタ質問ごとに、10 個のメタ質問が生成されました。より具体的な質問と関連するが一般的な 20 の質問が生成され、200,000 の具体的な質問、250,000 の一般的な質問、および 50,000 のメタ質問がサンプリングされ、質問ごとに 3 ~ 7 の対話ラウンドが生成されました。
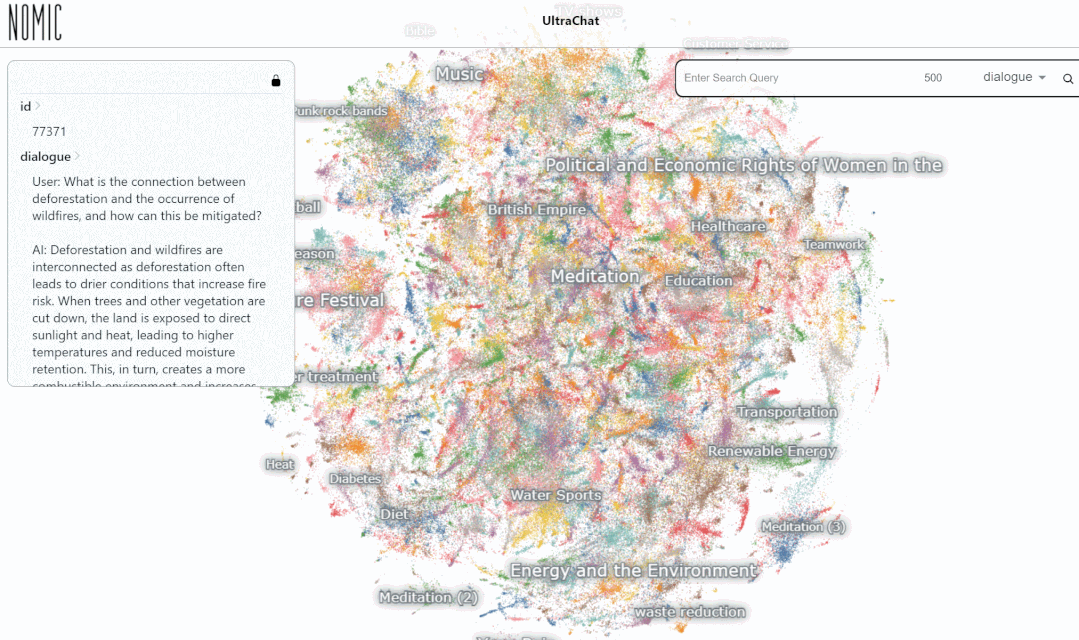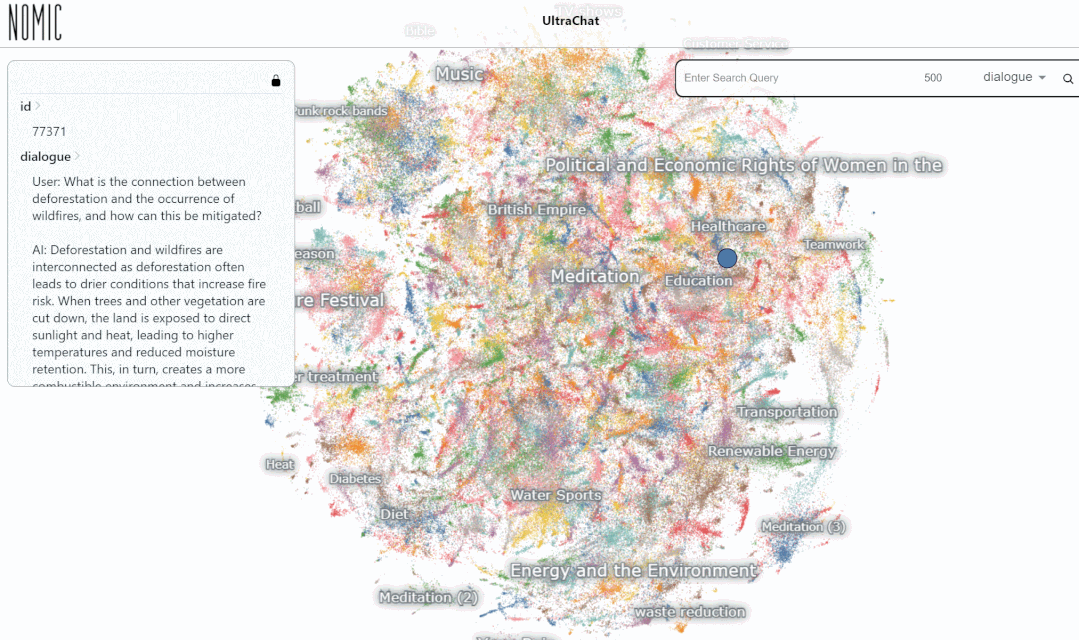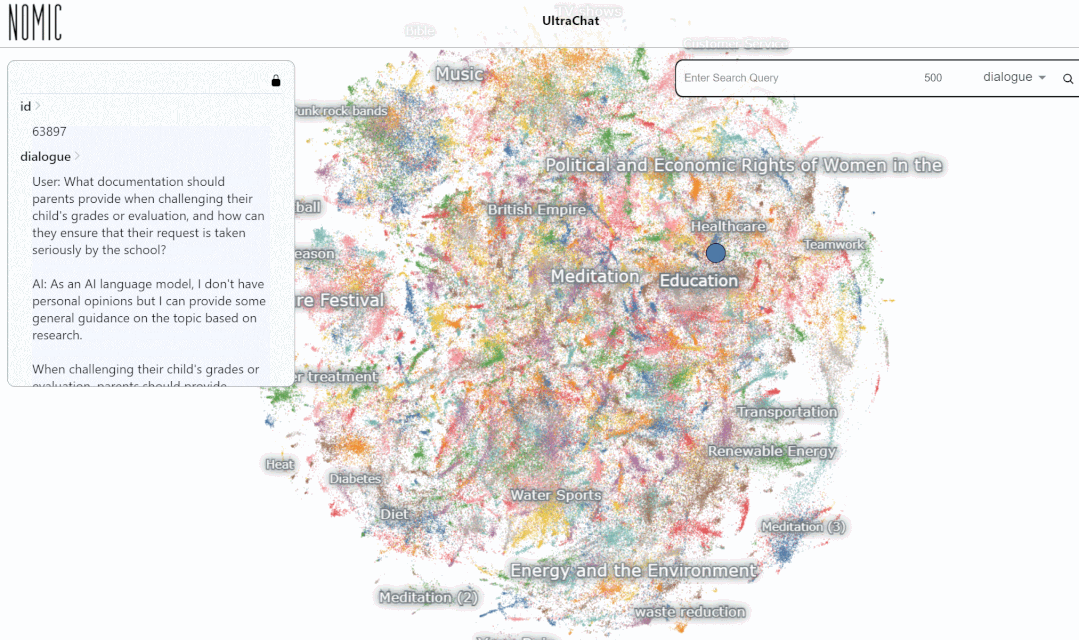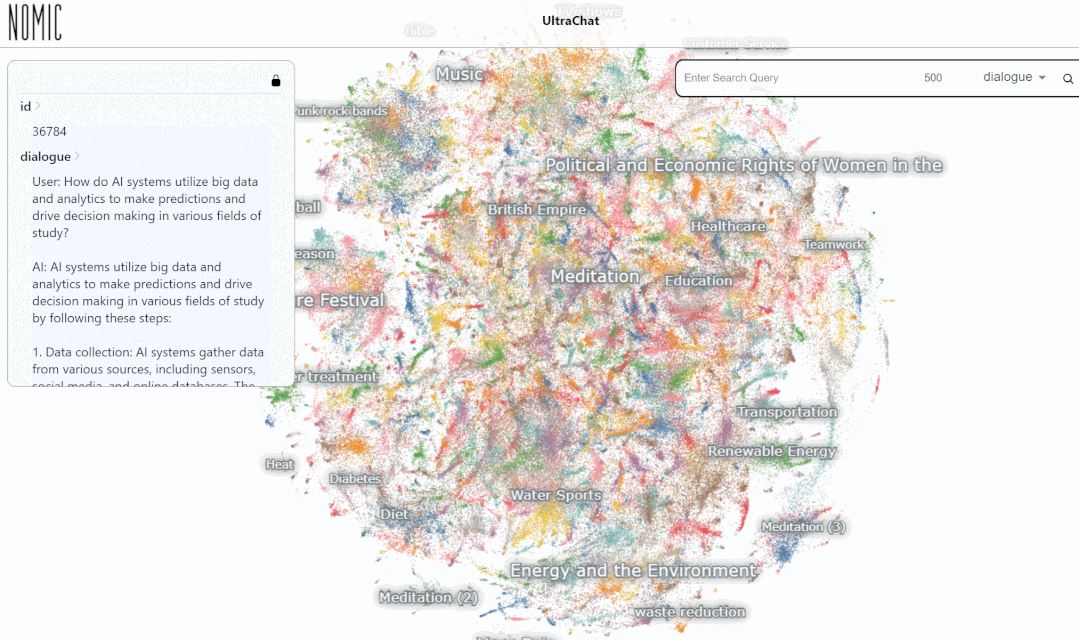
次に、具体的な例を見てみましょう:
UltraChat プラットフォームでデータをテストしました。結果。たとえば、「音楽」と入力すると、システムは音楽関連の ChatGPT 会話データ 10,000 セットを自動的に検索します。各セットは複数ラウンドの会話です。
キーワード「数学(数学)」を入力して検索した結果、複数ラウンドの会話が 3346 件あります: 
# #現在、UltraChat は医療、教育、スポーツ、環境保護などの情報分野をすでにカバーしています。同時に、著者はオープンソース LLaMa-7B モデルを使用して UltraChat 上で教師あり命令の微調整を実行しようとしましたが、わずか 10,000 ステップのトレーニング後に非常に印象的な効果があることがわかりました。いくつかの例は次のとおりです。

##世界の知識: 中国とアメリカの優れた大学をそれぞれ 10 校挙げてください

想像力の質問: 宇宙旅行が可能になった後に考えられる結果は何ですか? 
三段論法: クジラは魚ですか? ##仮定の質問: ジャッキー チェンがブルース リーよりも優れていることを証明してください 全体として、UltraChat は高品質で広範囲にわたる ChatGPT 会話データ セットであり、他のデータ セットと組み合わせてオープンソース会話モデルの品質を大幅に向上させることができます。現在、UltraChat は英語版のみを公開していますが、将来的には中国語版のデータも公開する予定です。興味のある読者はぜひ調べてみてください。 
以上が複数の ChatGPT API を使用した Tsinghua UltraChat マルチラウンド会話の実装の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 トップ10のデジタル通貨取引プラットフォーム:トップ10の安全で信頼できるデジタル通貨交換
Apr 30, 2025 pm 04:30 PM
トップ10のデジタル通貨取引プラットフォーム:トップ10の安全で信頼できるデジタル通貨交換
Apr 30, 2025 pm 04:30 PM
上位10のデジタル仮想通貨取引プラットフォームは次のとおりです。1。Binance、2。Okx、3。Coinbase、4。Kraken、5。HuobiGlobal、6。Bitfinex、7。Kucoin、8。Gemini、9。Bitstamp、10。Bittrex。これらのプラットフォームはすべて、さまざまなユーザーニーズに適した高度なセキュリティとさまざまな取引オプションを提供します。
 定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
交換に組み込まれた量子化ツールには、1。Binance:Binance先物の定量的モジュール、低い取り扱い手数料を提供し、AIアシストトランザクションをサポートします。 2。OKX(OUYI):マルチアカウント管理とインテリジェントな注文ルーティングをサポートし、制度レベルのリスク制御を提供します。独立した定量的戦略プラットフォームには、3。3Commas:ドラッグアンドドロップ戦略ジェネレーター、マルチプラットフォームヘッジアービトラージに適しています。 4。Quadency:カスタマイズされたリスクしきい値をサポートするプロフェッショナルレベルのアルゴリズム戦略ライブラリ。 5。Pionex:組み込み16のプリセット戦略、低い取引手数料。垂直ドメインツールには、6。cryptohopper:クラウドベースの定量的プラットフォーム、150の技術指標をサポートします。 7。BITSGAP:
 EaseProtocol.comは、ISO 20022メッセージ標準をブロックチェーンスマートコントラクトとして直接実装しています
Apr 30, 2025 pm 05:06 PM
EaseProtocol.comは、ISO 20022メッセージ標準をブロックチェーンスマートコントラクトとして直接実装しています
Apr 30, 2025 pm 05:06 PM
この画期的な開発により、金融機関は、グローバルに認識されているISO20022標準を活用して、さまざまなブロックチェーンエコシステム全体の銀行プロセスを自動化できます。簡単なプロトコルは、使いやすい方法を通じて広範な採用を促進するように設計されたエンタープライズレベルのブロックチェーンプラットフォームです。本日、ISO20022メッセージング標準を正常に統合し、ブロックチェーンスマートコントラクトに直接組み込んだことを発表しました。この開発により、金融機関は、Swiftメッセージングシステムを置き換えているグローバルに認識されているISO20022標準を使用して、さまざまなブロックチェーンエコシステムの銀行プロセスを簡単に自動化できます。これらの機能は、「easetestnet」でまもなく試されます。 easeprotocolarchitectdou
 デジタル通貨アプリの将来はありますか? Apple Mobile Digital Currency Trading PlatformアプリダウンロードTop10
Apr 30, 2025 pm 07:00 PM
デジタル通貨アプリの将来はありますか? Apple Mobile Digital Currency Trading PlatformアプリダウンロードTop10
Apr 30, 2025 pm 07:00 PM
デジタル通貨アプリの見通しは幅広く、次のことに特に反映されています。1。テクノロジーイノベーション駆動型機能のアップグレード、DefiおよびNFTおよびAIおよびビッグデータアプリケーションの統合によるユーザーエクスペリエンスの改善。 2。AMLおよびKYCの規制コンプライアンスの傾向、グローバルフレームワークの改善、より厳しい要件。 3。機能の多様化とサービスの拡大、貸付、財務管理、その他のサービスの統合、ユーザーエクスペリエンスの最適化。 4。ユーザーベースとグローバル拡張、および2025年にはユーザースケールが10億を超えると予想されます。
 通貨サークルの3人の巨人は何ですか?トップ10推奨される仮想通貨メイン交換アプリ
Apr 30, 2025 pm 06:27 PM
通貨サークルの3人の巨人は何ですか?トップ10推奨される仮想通貨メイン交換アプリ
Apr 30, 2025 pm 06:27 PM
通貨サークルでは、いわゆるビッグ3は通常、最も影響力があり広く使用されている3つの暗号通貨を指します。これらの暗号通貨は、市場で重要な役割を果たしており、取引量と時価総額の点でうまく機能しています。同時に、主流の仮想通貨交換アプリは、投資家やトレーダーが暗号通貨取引を実施するための重要なツールでもあります。この記事では、通貨サークルの3人の巨人と、推奨されるトップ10の主流の仮想通貨アプリを詳細に紹介します。
 失敗した暗号交換FTXは、最新の試みで特定の発行者に対して法的措置を講じる
Apr 30, 2025 pm 05:24 PM
失敗した暗号交換FTXは、最新の試みで特定の発行者に対して法的措置を講じる
Apr 30, 2025 pm 05:24 PM
最新の試みで、解決されたCrypto Exchange FTXは、債務を回収し、顧客を返済するために法的措置を講じました。債務を回収し、クライアントを返済するための最新の取り組みで、解決された暗号交換FTXは、特定の発行者に対して法的措置を提起しました。 FTX取引およびFTX Recovery Trustは、合意されたコインを交換に送金するという合意を果たさなかった特定のトークン発行者に対して訴訟を起こしました。具体的には、リストラチームは月曜日にコンプライアンスの問題について、NFTStars LimitedとOrosemi Inc.を訴えました。 FTXは、期限切れのコインを回収するためにトークン発行者を訴えています。 FTXは、かつて米国で最も優れた暗号通貨取引プラットフォームの1つでした。銀行は2022年11月に、その創設者SAMが
 信頼できる交換プラットフォームは何ですか?トップ10のデジタル通貨交換
Apr 30, 2025 pm 04:15 PM
信頼できる交換プラットフォームは何ですか?トップ10のデジタル通貨交換
Apr 30, 2025 pm 04:15 PM
上位10のデジタル通貨交換は次のとおりです。1。Binance、2。Okx、3。Coinbase、4。Kraken、5。HuobiGlobal、6。Bitfinex、7。Kucoin、8。Gemini、9。Bitstamp、10。Bittrex。これらのプラットフォームはすべて、さまざまなユーザーニーズに適した高度なセキュリティとさまざまな取引オプションを提供します。
 AIおよび作曲家:コードの品質と開発の強化
May 09, 2025 am 12:20 AM
AIおよび作曲家:コードの品質と開発の強化
May 09, 2025 am 12:20 AM
作曲家では、AIは主に、依存関係の推奨、依存関係の競合解決、コードの品質改善を通じて、開発効率とコードの品質を改善します。 1。AIは、プロジェクトのニーズに応じて適切な依存関係パッケージを推奨できます。 2。AIは、依存関係の競合に対処するためのインテリジェントなソリューションを提供します。 3。AIはコードをレビューし、コードの品質を改善するための最適化の提案を提供します。これらの機能を通じて、開発者はビジネスロジックの実装にもっと集中できます。
